 Transformer一統江湖:自然語言處理三大特征抽取器比較
Transformer一統江湖:自然語言處理三大特征抽取器比較
自然語言處理中的三大特征處理器:RNN、CNN、Transformer,它們目前誰各方面占據優勢?未來誰又更有前途呢?這篇文章用目前的各種實驗數據給出了說明,結論是:放棄幻想,全面擁抱Transformer。
在辭舊迎新的時刻,大家都在忙著回顧過去一年的成績(或者在灶臺前含淚數鍋),并對 2019 做著規劃,當然也有不少朋友執行力和工作效率比較高,直接把 2018 年初制定的計劃拷貝一下,就能在 3 秒鐘內完成 2019 年計劃的制定,在此表示祝賀。2018 年從經濟角度講,對于所有人可能都是比較難過的一年,而對于自然語言處理領域來說,2018 年無疑是個收獲頗豐的年頭,而諸多技術進展如果只能選擇一項來講的話,那么當之無愧的應該就是Bert 模型了。
在上一篇介紹 Bert 的文章 “從 Word Embedding 到 Bert 模型—自然語言處理中的預訓練技術發展史”[1]里,我曾大言不慚地宣稱如下兩個個人判斷:一個是Bert 這種兩階段的模式(預訓練 + Finetuning)必將成為 NLP 領域研究和工業應用的流行方法;第二個是從 NLP 領域的特征抽取器角度來說,Transformer 會逐步取代 RNN 成為最主流的的特征抽取器。關于特征抽取器方面的判斷,上面文章限于篇幅,只是給了一個結論,并未給出具備誘惑力的說明,看過我文章的人都知道我不是一個隨便下結論的人(那位正在補充下一句:“你隨便起來不是……” 的同學請住口,請不要泄露國家機密,你可以繼續睡覺,吵到其它同學也沒有關系,哈哈),但是為什么當時我會下這個結論呢?本文可以看做是上文的一個外傳,會給出比較詳實的證據來支撐之前給出的結論。
如果對目前NLP 里的三大特征抽取器的未來走向趨勢做個宏觀判斷的話,我的判斷是這樣的:
RNN人老珠黃,已經基本完成它的歷史使命,將來會逐步退出歷史舞臺;
CNN如果改造得當,將來還是有希望有自己在 NLP 領域的一席之地,如果改造成功程度超出期望,那么還有一絲可能作為割據一方的軍閥,繼續生存壯大,當然我認為這個希望不大,可能跟宋小寶打籃球把姚明打哭的概率相當;
而新歡Transformer明顯會很快成為 NLP 里擔當大任的最主流的特征抽取器。
至于將來是否會出現新的特征抽取器,一槍將 Tranformer 挑落馬下,繼而取而代之成為新的特征抽取山大王?這種擔憂其實是挺有必要的,畢竟李商隱在一千年前就告誡過我們說:“君恩如水向東流,得寵憂移失寵愁。 莫向樽前奏花落,涼風只在殿西頭。” 當然這首詩看樣子目前送給 RNN 是比較貼切的,至于未來 Transformer 是否會失寵?這個問題的答案基本可以是肯定的,無非這個時刻的來臨是 3 年之后,還是 1 年之后出現而已。當然,我希望如果是在讀這篇文章的你,或者是我,在未來的某一天,從街頭拉來一位長相普通的淑女,送到韓國整容,一不小心偏離流水線整容工業的美女模板,整出一位天香國色的絕色,來把 Transformer 打入冷宮,那是最好不過。但是在目前的狀態下,即使是打著望遠鏡,貌似還沒有看到有這種資質的候選人出現在我們的視野之內。
我知道如果是一位嚴謹的研發人員,不應該在目前局勢還沒那么明朗的時候做出如上看似有些武斷的明確結論,所以這種說法可能會引起爭議。但是這確實就是我目前的真實想法,至于根據什么得出的上述判斷?這種判斷是否有依據?依據是否充分?相信你在看完這篇文章可以有個屬于自己的結論。
可能談到這里,有些平常吃虧吃的少所以喜歡挑刺的同學會質疑說:你憑什么說 NLP 的典型特征抽取器就這三種呢?你置其它知名的特征抽取器比如 Recursive NN 于何地? 嗯,是,很多介紹 NLP 重要進展的文章里甚至把 Recursive NN 當做一項 NLP 里的重大進展,除了它,還有其它的比如 Memory Network 也享受這種部局級尊貴待遇。但是我一直都不太看好這兩個技術,而且不看好很多年了,目前情形更堅定了這個看法。而且我免費奉勸你一句,沒必要在這兩個技術上浪費時間,至于為什么,因為跟本文主題無關,以后有機會再詳細說。
上面是結論,下面,我們正式進入舉證階段。
戰場偵查:NLP 任務的特點及任務類型

NLP 任務的特點和圖像有極大的不同,上圖展示了一個例子,NLP 的輸入往往是一句話或者一篇文章,所以它有幾個特點:首先,輸入是個一維線性序列,這個好理解;其次,輸入是不定長的,有的長有的短,而這點其實對于模型處理起來也會增加一些小麻煩;再次,單詞或者子句的相對位置關系很重要,兩個單詞位置互換可能導致完全不同的意思。如果你聽到我對你說:“你欠我那一千萬不用還了” 和 “我欠你那一千萬不用還了”,你聽到后分別是什么心情?兩者區別了解一下;另外,句子中的長距離特征對于理解語義也非常關鍵,例子參考上圖標紅的單詞,特征抽取器能否具備長距離特征捕獲能力這一點對于解決 NLP 任務來說也是很關鍵的。
上面這幾個特點請記清,一個特征抽取器是否適配問題領域的特點,有時候決定了它的成敗,而很多模型改進的方向,其實就是改造得使得它更匹配領域問題的特性。這也是為何我在介紹 RNN、CNN、Transformer 等特征抽取器之前,先說明這些內容的原因。
NLP 是個很寬泛的領域,包含了幾十個子領域,理論上只要跟語言處理相關,都可以納入這個范圍。但是如果我們對大量 NLP 任務進行抽象的話,會發現絕大多數 NLP 任務可以歸結為幾大類任務。兩個看似差異很大的任務,在解決任務的模型角度,可能完全是一樣的。

通常而言,絕大部分 NLP 問題可以歸入上圖所示的四類任務中:
一類是序列標注,這是最典型的 NLP 任務,比如中文分詞,詞性標注,命名實體識別,語義角色標注等都可以歸入這一類問題,它的特點是句子中每個單詞要求模型根據上下文都要給出一個分類類別。
第二類是分類任務,比如我們常見的文本分類,情感計算等都可以歸入這一類。它的特點是不管文章有多長,總體給出一個分類類別即可。
第三類任務是句子關系判斷,比如 Entailment,QA,語義改寫,自然語言推理等任務都是這個模式,它的特點是給定兩個句子,模型判斷出兩個句子是否具備某種語義關系;
第四類是生成式任務,比如機器翻譯,文本摘要,寫詩造句,看圖說話等都屬于這一類。它的特點是輸入文本內容后,需要自主生成另外一段文字。
解決這些不同的任務,從模型角度來講什么最重要?是特征抽取器的能力。尤其是深度學習流行開來后,這一點更凸顯出來。因為深度學習最大的優點是 “端到端(end to end)”,當然這里不是指的從客戶端到云端,意思是以前研發人員得考慮設計抽取哪些特征,而端到端時代后,這些你完全不用管,把原始輸入扔給好的特征抽取器,它自己會把有用的特征抽取出來。
身為資深 Bug 制造者和算法工程師,你現在需要做的事情就是:選擇一個好的特征抽取器,選擇一個好的特征抽取器,選擇一個好的特征抽取器,喂給它大量的訓練數據,設定好優化目標(loss function),告訴它你想讓它干嘛…….. 然后你覺得你啥也不用干等結果就行了是吧?那你是我見過的整個宇宙中最樂觀的人……. 你大量時間其實是用在調參上…….。從這個過程可以看出,如果我們有個強大的特征抽取器,那么中初級算法工程師淪為調參俠也就是個必然了,在 AutoML(自動那啥)流行的年代,也許以后你想當調參俠而不得,李斯說的 “吾欲與若復牽黃犬,俱出上蔡東門逐狡兔,豈可得乎!” 請了解一下。所以請珍惜你半夜兩點還在調整超參的日子吧,因為對于你來說有一個好消息一個壞消息,好消息是:對于你來說可能這樣辛苦的日子不多了!壞消息是:對于你來說可能這樣辛苦的日子不多了!!!那么怎么才能成為算法高手?你去設計一個更強大的特征抽取器呀。
下面開始分敘三大特征抽取器。
沙場老將 RNN:廉頗老矣,尚能飯否
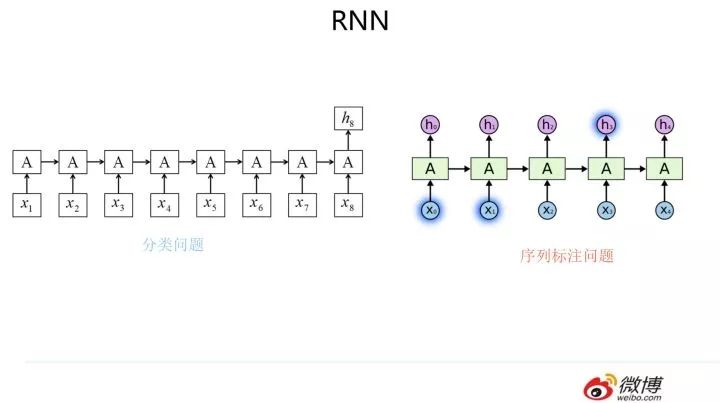
RNN 模型我估計大家都熟悉,就不詳細介紹了,模型結構參考上圖,核心是每個輸入對應隱層節點,而隱層節點之間形成了線性序列,信息由前向后在隱層之間逐步向后傳遞。我們下面直接進入我想講的內容。
為何 RNN 能夠成為解決 NLP 問題的主流特征抽取器
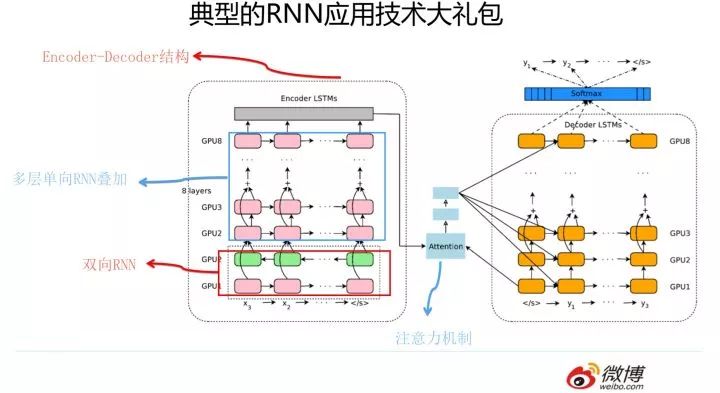
我們知道,RNN 自從引入 NLP 界后,很快就成為吸引眼球的明星模型,在 NLP 各種任務中被廣泛使用。但是原始的 RNN 也存在問題,它采取線性序列結構不斷從前往后收集輸入信息,但這種線性序列結構在反向傳播的時候存在優化困難問題,因為反向傳播路徑太長,容易導致嚴重的梯度消失或梯度爆炸問題。為了解決這個問題,后來引入了 LSTM 和 GRU 模型,通過增加中間狀態信息直接向后傳播,以此緩解梯度消失問題,獲得了很好的效果,于是很快 LSTM 和 GRU 成為 RNN 的標準模型。其實圖像領域最早由 HighwayNet/Resnet 等導致模型革命的 skip connection 的原始思路就是從 LSTM 的隱層傳遞機制借鑒來的。經過不斷優化,后來 NLP 又從圖像領域借鑒并引入了 attention 機制(從這兩個過程可以看到不同領域的相互技術借鑒與促進作用),疊加網絡把層深作深,以及引入 Encoder-Decoder 框架,這些技術進展極大拓展了 RNN 的能力以及應用效果。下圖展示的模型就是非常典型的使用 RNN 來解決 NLP 任務的通用框架技術大禮包,在更新的技術出現前,你可以在 NLP 各種領域見到這個技術大禮包的身影。
上述內容簡單介紹了 RNN 在 NLP 領域的大致技術演進過程。那么為什么 RNN 能夠這么快在 NLP 流行并且占據了主導地位呢?主要原因還是因為 RNN 的結構天然適配解決 NLP 的問題,NLP 的輸入往往是個不定長的線性序列句子,而 RNN 本身結構就是個可以接納不定長輸入的由前向后進行信息線性傳導的網絡結構,而在 LSTM 引入三個門后,對于捕獲長距離特征也是非常有效的。所以 RNN 特別適合 NLP 這種線形序列應用場景,這是 RNN 為何在 NLP 界如此流行的根本原因。
RNN 在新時代面臨的兩個嚴重問題
RNN 在 NLP 界一直紅了很多年(2014-2018?),在 2018 年之前,大部分各個子領域的 State of Art 的結果都是 RNN 獲得的。但是最近一年來,眼看著 RNN 的領袖群倫的地位正在被動搖,所謂各領風騷 3-5 年,看來網紅模型也不例外。
那這又是因為什么呢?主要有兩個原因。
第一個原因在于一些后起之秀新模型的崛起,比如經過特殊改造的 CNN 模型,以及最近特別流行的 Transformer,這些后起之秀尤其是 Transformer 的應用效果相比 RNN 來說,目前看具有明顯的優勢。這是個主要原因,老人如果干不過新人,又沒有脫胎換骨自我革命的能力,自然要自覺或不自愿地退出歷史舞臺,這是自然規律。至于 RNN 能力偏弱的具體證據,本文后面會專門談,這里不展開講。當然,技術人員里的 RNN 保皇派們,這個群體規模應該還是相當大的,他們不會輕易放棄曾經這么熱門過的流量明星的,所以也想了或者正在想一些改進方法,試圖給 RNN 延年益壽。至于這些方法是什么,有沒有作用,后面也陸續會談。
另外一個嚴重阻礙 RNN 將來繼續走紅的問題是:RNN 本身的序列依賴結構對于大規模并行計算來說相當之不友好。通俗點說,就是 RNN 很難具備高效的并行計算能力,這個乍一看好像不是太大的問題,其實問題很嚴重。如果你僅僅滿足于通過改 RNN 發一篇論文,那么這確實不是大問題,但是如果工業界進行技術選型的時候,在有快得多的模型可用的前提下,是不太可能選擇那么慢的模型的。一個沒有實際落地應用支撐其存在價值的模型,其前景如何這個問題,估計用小腦思考也能得出答案。
那問題來了:為什么 RNN 并行計算能力比較差?是什么原因造成的?
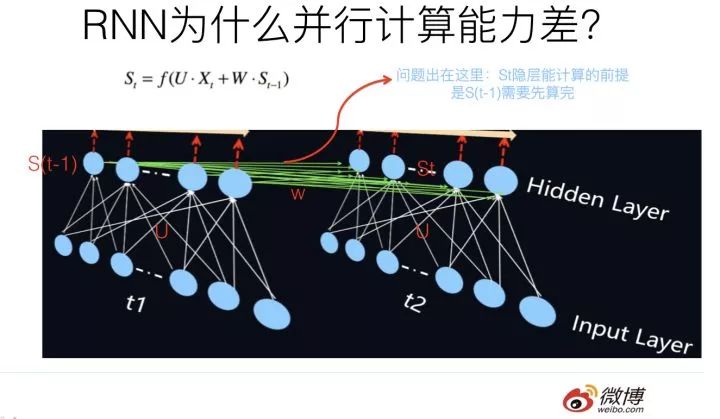
我們知道,RNN 之所以是 RNN,能將其和其它模型區分開的最典型標志是:T 時刻隱層狀態的計算,依賴兩個輸入,一個是 T 時刻的句子輸入單詞 Xt,這個不算特點,所有模型都要接收這個原始輸入;關鍵的是另外一個輸入,T 時刻的隱層狀態 St 還依賴 T-1 時刻的隱層狀態 S(t-1) 的輸出,這是最能體現 RNN 本質特征的一點,RNN 的歷史信息是通過這個信息傳輸渠道往后傳輸的,示意參考上圖。那么為什么 RNN 的并行計算能力不行呢?問題就出在這里。因為 T 時刻的計算依賴 T-1 時刻的隱層計算結果,而 T-1 時刻的計算依賴 T-2 時刻的隱層計算結果…….. 這樣就形成了所謂的序列依賴關系。就是說只能先把第 1 時間步的算完,才能算第 2 時間步的結果,這就造成了 RNN 在這個角度上是無法并行計算的,只能老老實實地按著時間步一個單詞一個單詞往后走。
而 CNN 和 Transformer 就不存在這種序列依賴問題,所以對于這兩者來說并行計算能力就不是問題,每個時間步的操作可以并行一起計算。
那么能否針對性地對 RNN 改造一下,提升它的并行計算能力呢?如果可以的話,效果如何呢?下面我們討論一下這個問題。
如何改造 RNN 使其具備并行計算能力?
上面說過,RNN 不能并行計算的癥結所在,在于 T 時刻對 T-1 時刻計算結果的依賴,而這體現在隱層之間的全連接網絡上。既然癥結在這里,那么要想解決問題,也得在這個環節下手才行。在這個環節多做點什么事情能夠增加 RNN 的并行計算能力呢?你可以想一想。
其實留給你的選項并不多,你可以有兩個大的思路來改進:一種是仍然保留任意連續時間步(T-1 到 T 時刻)之間的隱層連接;而另外一種是部分地打斷連續時間步(T-1 到 T 時刻)之間的隱層連接 。
我們先來看第一種方法,現在我們的問題轉化成了:我們仍然要保留任意連續時間步(T-1 到 T 時刻)之間的隱層連接,但是在這個前提下,我們還要能夠做到并行計算,這怎么處理呢?因為只要保留連續兩個時間步的隱層連接,則意味著要計算 T 時刻的隱層結果,就需要 T-1 時刻隱層結果先算完,這不又落入了序列依賴的陷阱里了嗎?嗯,確實是這樣,但是為什么一定要在不同時間步的輸入之間并行呢?沒有人說 RNN 的并行計算一定發生在不同時間步上啊,你想想,隱層是不是也是包含很多神經元?那么在隱層神經元之間并行計算行嗎?如果你要是還沒理解這是什么意思,那請看下圖。

上面的圖只顯示了各個時間步的隱層節點,每個時間步的隱層包含 3 個神經元,這是個俯視圖,是從上往下看 RNN 的隱層節點的。另外,連續兩個時間步的隱層神經元之間仍然有連接,上圖沒有畫出來是為了看著簡潔一些。這下應該明白了吧,假設隱層神經元有 3 個,那么我們可以形成 3 路并行計算(紅色箭頭分隔開成了三路),而每一路因為仍然存在序列依賴問題,所以每一路內仍然是串行的。大思路應該明白了是吧?但是了解 RNN 結構的同學會發現這樣還遺留一個問題:隱層神經元之間的連接是全連接,就是說 T 時刻某個隱層神經元與 T-1 時刻所有隱層神經元都有連接,如果是這樣,是無法做到在神經元之間并行計算的,你可以想想為什么,這個簡單,我假設你有能力想明白。那么怎么辦呢?很簡單,T 時刻和 T-1 時刻的隱層神經元之間的連接關系需要改造,從之前的全連接,改造成對應位置的神經元(就是上圖被紅箭頭分隔到同一行的神經元之間)有連接,和其它神經元沒有連接。這樣就可以解決這個問題,在不同路的隱層神經元之間可以并行計算了。
第一種改造 RNN 并行計算能力的方法思路大致如上所述,這種方法的代表就是論文 “Simple Recurrent Units for Highly Parallelizable Recurrence” 中提出的SRU 方法,它最本質的改進是把隱層之間的神經元依賴由全連接改成了哈達馬乘積,這樣 T 時刻隱層單元本來對 T-1 時刻所有隱層單元的依賴,改成了只是對 T-1 時刻對應單元的依賴,于是可以在隱層單元之間進行并行計算,但是收集信息仍然是按照時間序列來進行的。所以其并行性是在隱層單元之間發生的,而不是在不同時間步之間發生的。
這其實是比較巧妙的一種方法,但是它的問題在于其并行程度上限是有限的,并行程度取決于隱層神經元個數,而一般這個數值往往不會太大,再增加并行性已經不太可能。另外每一路并行線路仍然需要序列計算,這也會拖慢整體速度。SRU 的測試速度為:在文本分類上和原始 CNN(Kim 2014)的速度相當,論文沒有說 CNN 是否采取了并行訓練方法。 其它在復雜任務閱讀理解及 MT 任務上只做了效果評估,沒有和 CNN 進行速度比較,我估計這是有原因的,因為復雜任務往往需要深層網絡,其它的就不妄作猜測了。

第二種改進典型的思路是:為了能夠在不同時間步輸入之間進行并行計算,那么只有一種做法,那就是打斷隱層之間的連接,但是又不能全打斷,因為這樣基本就無法捕獲組合特征了,所以唯一能選的策略就是部分打斷,比如每隔 2 個時間步打斷一次,但是距離稍微遠點的特征如何捕獲呢?只能加深層深,通過層深來建立遠距離特征之間的聯系。代表性模型比如上圖展示的 Sliced RNN。我當初看到這個模型的時候,心里忍不住發出杠鈴般的笑聲,情不自禁地走上前跟他打了個招呼:你好呀,CNN 模型,想不到你這個糙漢子有一天也會穿上粉色裙裝,裝扮成 RNN 的樣子出現在我面前啊,哈哈。了解 CNN 模型的同學看到我上面這句話估計會莞爾會心一笑:這不就是簡化版本的 CNN 嗎?不了解 CNN 的同學建議看完后面 CNN 部分再回頭來看看是不是這個意思。
那經過這種改造的 RNN 速度改進如何呢?論文給出了速度對比實驗,歸納起來,SRNN 速度比 GRU 模型快 5 到 15 倍,嗯,效果不錯,但是跟對比模型 DC-CNN 模型速度比較起來,比 CNN 模型仍然平均慢了大約 3 倍。這很正常但是又有點說不太過去,說正常是因為本來這就是把 RNN 改頭換面成類似 CNN 的結構,而片段里仍然采取 RNN 序列模型,所以必然會拉慢速度,比 CNN 慢再正常不過了。說 “說不過去” 是指的是:既然本質上是 CNN,速度又比 CNN 慢,那么這么改的意義在哪里?為什么不直接用 CNN 呢?是不是?前面那位因為吃虧吃的少所以愛抬杠的同學又會說了:也許人家效果特別好呢。嗯,從這個結構的作用機制上看,可能性不太大。你說論文實驗部分證明了這一點呀,我認為實驗部分對比試驗做的不充分,需要補充除了 DC-CNN 外的其他 CNN 模型進行對比。當然這點純屬個人意見,別當真,因為我講起話來的時候經常搖頭晃腦,此時一般會有人驚奇地跟我反饋說:為什么你一講話我就聽到了水聲?
上面列舉了兩種大的改進 RNN 并行計算能力的思路,我個人對于 RNN 的并行計算能力持悲觀態度,主要因為 RNN 本質特性決定了我們能做的選擇太少。無非就是選擇打斷還是不打斷隱層連接的問題。如果選擇打斷,就會面臨上面的問題,你會發現它可能已經不是 RNN 模型了,為了讓它看上去還像是 RNN,所以在打斷片段里仍然采取 RNN 結構,這樣無疑會拉慢速度,所以這是個兩難的選擇,與其這樣不如直接換成其它模型;如果我們選擇不打斷,貌似只能在隱層神經元之間進行并行,而這樣做的缺點是:一方面并行能力上限很低;另外一方面里面依然存在的序列依賴估計仍然是個問題。這是為何悲觀的原因,主要是看不到大的希望。
偏師之將 CNN:刺激戰場絕地求生
在一年多前,CNN 是自然語言處理中除了 RNN 外最常見的深度學習模型,這里介紹下 CNN 特征抽取器,會比 RNN 說得詳細些,主要考慮到大家對它的熟悉程度可能沒有 RNN 那么高。
NLP 中早期的懷舊版 CNN 模型
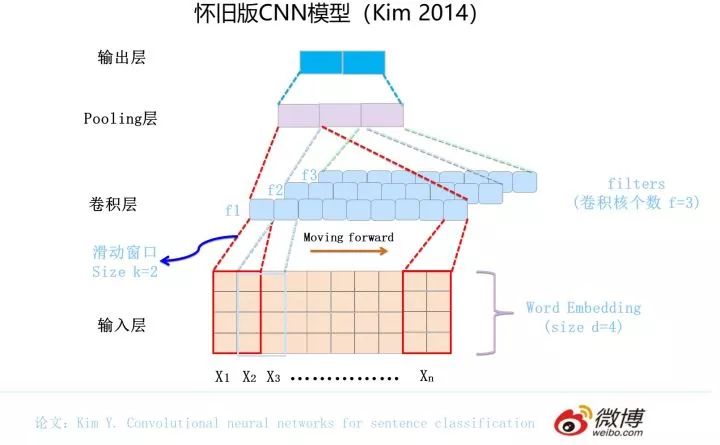
最早將 CNN 引入 NLP 的是 Kim 在 2014 年做的工作,論文和網絡結構參考上圖。一般而言,輸入的字或者詞用Word Embedding的方式表達,這樣本來一維的文本信息輸入就轉換成了二維的輸入結構,假設輸入 X 包含 n 個字符,而每個字符的 Word Embedding 的長度為 d,那么輸入就是 d*n 的二維向量。
卷積層本質上是個特征抽取層,可以設定超參數 F 來指定卷積層包含多少個卷積核(Filter)。對于某個 Filter 來說,可以想象有一個 d*k 大小的移動窗口從輸入矩陣的第一個字開始不斷往后移動,其中 k 是 Filter 指定的窗口大小,d 是 Word Embedding 長度。對于某個時刻的窗口,通過神經網絡的非線性變換,將這個窗口內的輸入值轉換為某個特征值,隨著窗口不斷往后移動,這個 Filter 對應的特征值不斷產生,形成這個 Filter 的特征向量。這就是卷積核抽取特征的過程。卷積層內每個 Filter 都如此操作,就形成了不同的特征序列。Pooling 層則對 Filter 的特征進行降維操作,形成最終的特征。一般在 Pooling 層之后連接全聯接層神經網絡,形成最后的分類過程。
這就是最早應用在 NLP 領域 CNN 模型的工作機制,用來解決 NLP 中的句子分類任務,看起來還是很簡潔的,之后陸續出現了在此基礎上的改進模型。這些懷舊版 CNN 模型在一些任務上也能和當時懷舊版本的 RNN 模型效果相當,所以在 NLP 若干領域也能野蠻生長,但是在更多的 NLP 領域,還是處于被 RNN 模型壓制到抑郁癥早期的尷尬局面。那為什么在圖像領域打遍天下無敵手的 CNN,一旦跑到 NLP 的地盤,就被 RNN 這個地頭蛇壓制得無顏見圖像領域江東父老呢?這說明這個版本的 CNN 還是有很多問題的,其實最根本的癥結所在還是老革命遇到了新問題,主要是到了新環境沒有針對新環境的特性做出針對性的改變,所以面臨水土不服的問題。
CNN 能在 RNN 縱橫的各種 NLP 任務環境下生存下來嗎?謎底即將揭曉。
CNN 的進化:物競天擇的模型斗獸場
下面我們先看看懷舊版 CNN 存在哪些問題,然后看看我們的 NLP 專家們是如何改造 CNN,一直改到目前看上去還算效果不錯的現代版本 CNN 的。
首先,我們先要明確一點:CNN 捕獲到的是什么特征呢?從上述懷舊版本 CNN 卷積層的運作機制你大概看出來了,關鍵在于卷積核覆蓋的那個滑動窗口,CNN 能捕獲到的特征基本都體現在這個滑動窗口里了。大小為 k 的滑動窗口輕輕的穿過句子的一個個單詞,蕩起陣陣漣漪,那么它捕獲了什么? 其實它捕獲到的是單詞的 k-gram 片段信息,這些 k-gram 片段就是 CNN 捕獲到的特征,k 的大小決定了能捕獲多遠距離的特征。

說完這個,我們來看 Kim 版 CNN 的第一個問題:它只有一個卷積層。表面看上去好像是深度不夠的問題是吧?我會反問你說:為什么要把 CNN 作深呢?其實把深度做起來是手段,不是目的。只有一個卷積層帶來的問題是:對于遠距離特征,單層 CNN 是無法捕獲到的,如果滑動窗口 k 最大為 2,而如果有個遠距離特征距離是 5,那么無論上多少個卷積核,都無法覆蓋到長度為 5 的距離的輸入,所以它是無法捕獲長距離特征的。
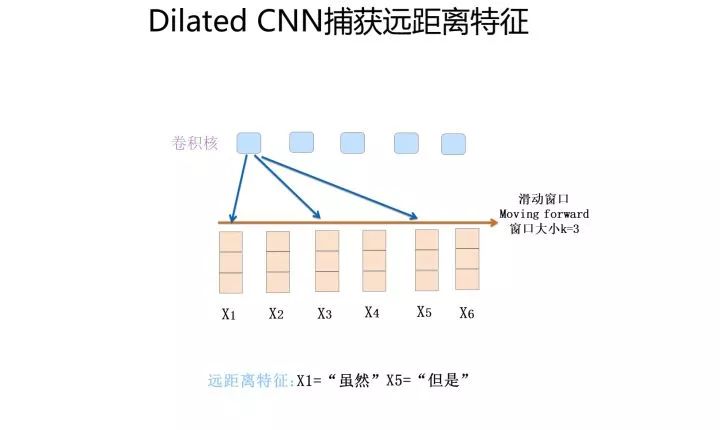
那么怎樣才能捕獲到長距離的特征呢?有兩種典型的改進方法:一種是假設我們仍然用單個卷積層,滑動窗口大小 k 假設為 3,就是只接收三個輸入單詞,但是我們想捕獲距離為 5 的特征,怎么做才行?顯然,如果卷積核窗口仍然覆蓋連續區域,這肯定是完不成任務的。提示一下:你玩過跳一跳是吧?能采取類似策略嗎?對,你可以跳著覆蓋呀,是吧?這就是Dilated 卷積的基本思想,確實也是一種解決方法。
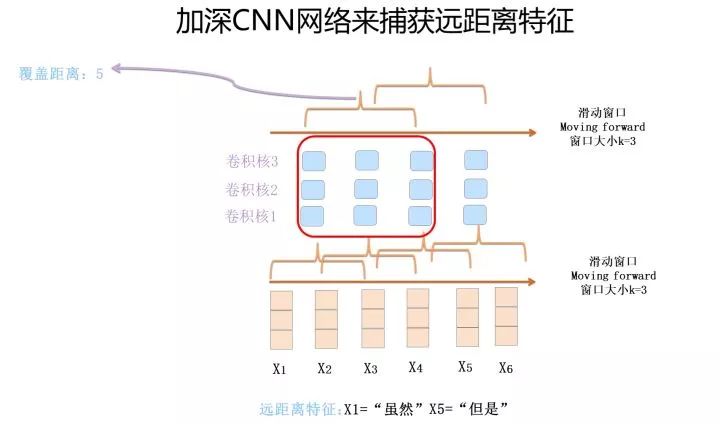
第二種方法是把深度做起來。第一層卷積層,假設滑動窗口大小 k 是 3,如果再往上疊一層卷積層,假設滑動窗口大小也是 3,但是第二層窗口覆蓋的是第一層窗口的輸出特征,所以它其實能覆蓋輸入的距離達到了 5。如果繼續往上疊加卷積層,可以繼續增大卷積核覆蓋輸入的長度。
上面是兩種典型的解決 CNN 遠距離特征捕獲能力的方案,Dilated CNN 偏技巧一些,而且疊加卷積層時超參如何設置有些學問,因為連續跳接可能會錯過一些特征組合,所以需要精心調節參數搭配,保證所有可能組合都被覆蓋到。相對而言,把 CNN 作深是主流發展方向。上面這個道理好理解,其實自從 CNN 一出現,人們就想各種辦法試圖把 CNN 的深度做起來,但是現實往往是無情的,發現怎么折騰,CNN 做 NLP 問題就是做不深,做到 2 到 3 層卷積層就做不上去了,網絡更深對任務效果沒什么幫助(請不要拿 CharCNN 來做反例,后來研究表明使用單詞的 2 層 CNN 效果超過 CharCNN)。目前看來,還是深層網絡參數優化手段不足導致的這個問題,而不是層深沒有用。后來 Resnet 等圖像領域的新技術出現后,很自然地,人們會考慮把 Skip Connection 及各種 Norm 等參數優化技術引入,這才能慢慢把 CNN 的網絡深度做起來。
上面說的是 Kim 版本 CNN 的第一個問題,無法捕獲遠距離特征的問題,以及后面科研人員提出的主要解決方案。回頭看 Kim 版本 CNN 還有一個問題,就是那個 Max Pooling 層,這塊其實與 CNN 能否保持輸入句子中單詞的位置信息有關系。首先我想問個問題:RNN 因為是線性序列結構,所以很自然它天然就會把位置信息編碼進去;那么,CNN 是否能夠保留原始輸入的相對位置信息呢?我們前面說過對于 NLP 問題來說,位置信息是很有用的。其實 CNN 的卷積核是能保留特征之間的相對位置的,道理很簡單,滑動窗口從左到右滑動,捕獲到的特征也是如此順序排列,所以它在結構上已經記錄了相對位置信息了。但是如果卷積層后面立即接上 Pooling 層的話,Max Pooling 的操作邏輯是:從一個卷積核獲得的特征向量里只選中并保留最強的那一個特征,所以到了 Pooling 層,位置信息就被扔掉了,這在 NLP 里其實是有信息損失的。所以在 NLP 領域里,目前 CNN 的一個發展趨勢是拋棄 Pooling 層,靠全卷積層來疊加網絡深度,這背后是有原因的(當然圖像領域也是這個趨勢)。
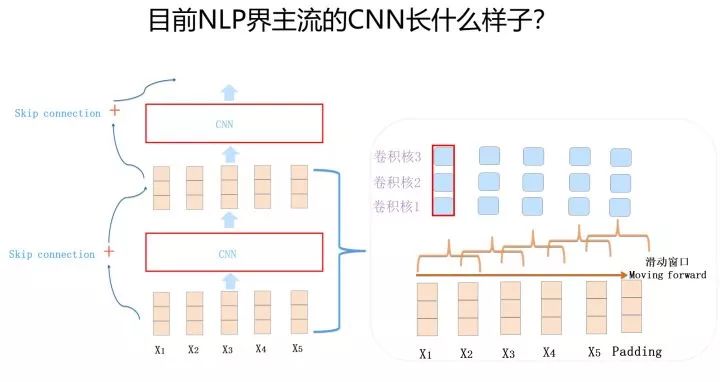
上圖展示了在 NLP 領域能夠施展身手的摩登 CNN 的主體結構,通常由 1-D 卷積層來疊加深度,使用 Skip Connection 來輔助優化,也可以引入 Dilated CNN 等手段。比如 ConvS2S 主體就是上圖所示結構,Encoder 包含 15 個卷積層,卷積核 kernel size=3,覆蓋輸入長度為 25。當然對于 ConvS2S 來說,卷積核里引入 GLU 門控非線性函數也有重要幫助,限于篇幅,這里不展開說了,GLU 貌似是 NLP 里 CNN 模型必備的構件,值得掌握。再比如 TCN(論文:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling),集成了幾項技術:利用 Dilated CNN 拓展單層卷積層的輸入覆蓋長度,利用全卷積層堆疊層深,使用 Skip Connection 輔助優化,引入 Casual CNN 讓網絡結構看不到 T 時間步后的數據。不過 TCN 的實驗做得有兩個明顯問題:一個問題是任務除了語言模型外都不是典型的 NLP 任務,而是合成數據任務,所以論文結論很難直接說就適合 NLP 領域;另外一點,它用來進行效果比較的對比方法,沒有用當時效果很好的模型來對比,比較基準低。所以 TCN 的模型效果說服力不太夠。其實它該引入的元素也基本引入了,實驗說服力不夠,我覺得可能是它命中缺 GLU 吧。
除此外,簡單談一下 CNN 的位置編碼問題和并行計算能力問題。上面說了,CNN 的卷積層其實是保留了相對位置信息的,只要你在設計模型的時候別手賤,中間層不要隨手瞎插入 Pooling 層,問題就不大,不專門在輸入部分對 position 進行編碼也行。但是也可以類似 ConvS2S 那樣,專門在輸入部分給每個單詞增加一個 position embedding,將單詞的 position embedding 和詞向量 embedding 疊加起來形成單詞輸入,這樣也可以,也是常規做法。
至于 CNN 的并行計算能力,那是非常強的,這其實很好理解。我們考慮單層卷積層,首先對于某個卷積核來說,每個滑動窗口位置之間沒有依賴關系,所以完全可以并行計算;另外,不同的卷積核之間也沒什么相互影響,所以也可以并行計算。CNN 的并行度是非常自由也非常高的,這是 CNN 的一個非常好的優點。
以上內容介紹了懷舊版 CNN 是如何在 NLP 修羅場一步步通過自我進化生存到今天的。CNN 的進化方向,如果千言萬語一句話歸納的話,那就是:想方設法把 CNN 的深度做起來,隨著深度的增加,很多看似無關的問題就隨之解決了。就跟我們國家最近 40 年的主旋律是發展經濟一樣,經濟發展好了,很多問題就不是問題了。最近幾年之所以大家感到各方面很困難,癥結就在于經濟不行了,所以很多問題無法通過經濟帶動來解決,于是看似各種花樣的困難就冒出來,這是一個道理。
那么介紹了這么多,摩登版 CNN 效果如何呢?與 RNN 及 Transforme 比起來怎樣?別著急,后面會專門談這個問題。
白衣騎士 Transformer:蓋世英雄站上舞臺
Transformer 是谷歌在 17 年做機器翻譯任務的 “Attention is all you need” 的論文中提出的,引起了相當大的反響。 每一位從事 NLP 研發的同仁都應該透徹搞明白 Transformer,它的重要性毫無疑問,尤其是你在看完我這篇文章之后,我相信你的緊迫感會更迫切,我就是這么一位善于制造焦慮的能手。不過這里沒打算重點介紹它,想要入門 Transformer 的可以參考以下三篇文章:一個是 Jay Alammar 可視化地介紹 Transformer 的博客文章The Illustrated Transformer,非常容易理解整個機制,建議先從這篇看起,這是中文翻譯版本;第二篇是 Calvo 的博客:Dissecting BERT Part 1: The Encoder,盡管說是解析 Bert,但是因為 Bert 的 Encoder 就是 Transformer,所以其實它是在解析 Transformer,里面舉的例子很好;再然后可以進階一下,參考哈佛大學 NLP 研究組寫的 “The Annotated Transformer.”,代碼原理雙管齊下,講得也很清楚。
下面只說跟本文主題有關的內容。
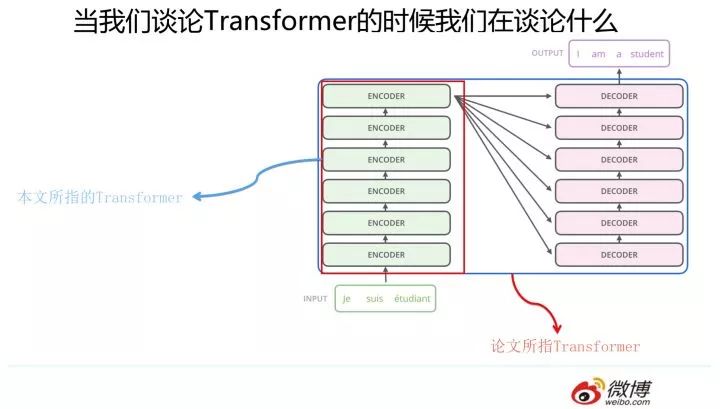
這里要澄清一下,本文所說的 Transformer 特征抽取器并非原始論文所指。我們知道,“Attention is all you need” 論文中說的的 Transformer 指的是完整的 Encoder-Decoder 框架,而我這里是從特征提取器角度來說的,你可以簡單理解為論文中的 Encoder 部分。因為 Encoder 部分目的比較單純,就是從原始句子中提取特征,而 Decoder 部分則功能相對比較多,除了特征提取功能外,還包含語言模型功能,以及用 attention 機制表達的翻譯模型功能。所以這里請注意,避免后續理解概念產生混淆。
Transformer 的 Encoder 部分(不是上圖一個一個的標為 encoder 的模塊,而是紅框內的整體,上圖來自 The Illustrated Transformer,Jay Alammar 把每個 Block 稱為 Encoder 不太符合常規叫法)是由若干個相同的 Transformer Block 堆疊成的。 這個 Transformer Block 其實才是 Transformer 最關鍵的地方,核心配方就在這里。那么它長什么樣子呢?

它的照片見上圖,看上去是不是很可愛,有點像安卓機器人是吧?這里需要強調一下,盡管 Transformer 原始論文一直重點在說 Self Attention,但是目前來看,能讓 Transformer 效果好的,不僅僅是 Self attention,這個 Block 里所有元素,包括 Multi-head self attention,Skip connection,LayerNorm,FF 一起在發揮作用。為什么這么說?你看到后面會體會到這一點。
我們針對 NLP 任務的特點來說下 Transformer 的對應解決方案。首先,自然語言一般是個不定長的句子,那么這個不定長問題怎么解決呢?Transformer 做法跟 CNN 是類似的,一般設定輸入的最大長度,如果句子沒那么長,則用 Padding 填充,這樣整個模型輸入起碼看起來是定長的了。另外,NLP 句子中單詞之間的相對位置是包含很多信息的,上面提過,RNN 因為結構就是線性序列的,所以天然會將位置信息編碼進模型;而 CNN 的卷積層其實也是保留了位置相對信息的,所以什么也不做問題也不大。但是對于 Transformer 來說,為了能夠保留輸入句子單詞之間的相對位置信息,必須要做點什么。為啥它必須要做點什么呢?因為輸入的第一層網絡是 Muli-head self attention 層,我們知道,Self attention 會讓當前輸入單詞和句子中任意單詞發生關系,然后集成到一個 embedding 向量里,但是當所有信息到了 embedding 后,位置信息并沒有被編碼進去。所以,Transformer 不像 RNN 或 CNN,必須明確的在輸入端將 Positon 信息編碼,Transformer 是用位置函數來進行位置編碼的,而 Bert 等模型則給每個單詞一個 Position embedding,將單詞 embedding 和單詞對應的 position embedding 加起來形成單詞的輸入 embedding,類似上文講的 ConvS2S 的做法。而關于 NLP 句子中長距離依賴特征的問題,Self attention 天然就能解決這個問題,因為在集成信息的時候,當前單詞和句子中任意單詞都發生了聯系,所以一步到位就把這個事情做掉了。不像 RNN 需要通過隱層節點序列往后傳,也不像 CNN 需要通過增加網絡深度來捕獲遠距離特征,Transformer 在這點上明顯方案是相對簡單直觀的。說這些是為了單獨介紹下 Transformer 是怎樣解決 NLP 任務幾個關鍵點的。
Transformer 有兩個版本:Transformer base和Transformer Big。兩者結構其實是一樣的,主要區別是包含的 Transformer Block 數量不同,Transformer base 包含 12 個 Block 疊加,而 Transformer Big 則擴張一倍,包含 24 個 Block。無疑 Transformer Big 在網絡深度,參數量以及計算量相對 Transformer base 翻倍,所以是相對重的一個模型,但是效果也最好。
華山論劍:三大特征抽取器比較
結合 NLP 領域自身的特點,上面幾個部分分別介紹了 RNN/CNN/Transformer 各自的特性。從上面的介紹,看上去好像三大特征抽取器在 NLP 領域里各有所長,推想起來要是把它們拉到 NLP 任務競技場角斗,一定是互有勝負,各擅勝場吧?
事實究竟如何呢?是三個特征抽取器三花齊放還是某一個一枝獨秀呢?我們通過一些實驗來說明這個問題。
為了更細致和公平地做對三者進行比較,我準備從幾個不同的角度來分別進行對比,我原先打算從以下幾個維度來進行分析判斷:句法特征提取能力;語義特征提取能力;長距離特征捕獲能力;任務綜合特征抽取能力。上面四個角度是從 NLP 的特征抽取器能力強弱角度來評判的,另外再加入并行計算能力及運行效率,這是從是否方便大規模實用化的角度來看的。
因為目前關于特征抽取器句法特征抽取能力方面進行比較的文獻很少,好像只看到一篇文章,結論是 CNN 在句法特征提取能力要強于 RNN,但是因為是比較早的文章,而且沒有對比 transformer 在句法特征抽取方面的能力,所以這塊很難單獨比較,于是我就簡化為對以下幾項能力的對比:
語義特征提取能力;
長距離特征捕獲能力;
任務綜合特征抽取能力;
并行計算能力及運行效率
三者在這些維度各自表現如何呢?下面我們分頭進行說明。
語義特征提取能力
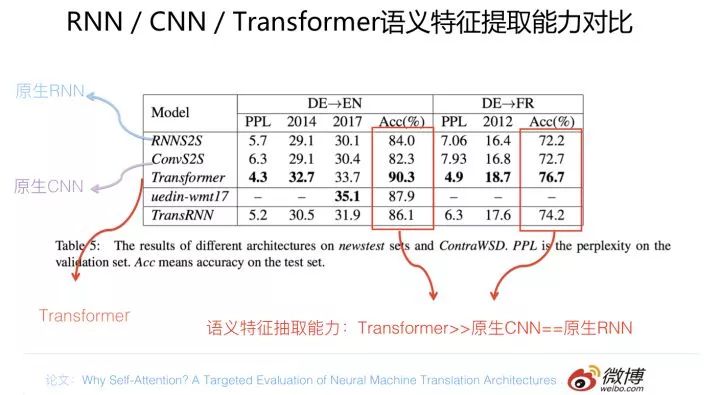
從語義特征提取能力來說,目前實驗支持如下結論:Transformer 在這方面的能力非常顯著地超過 RNN 和 CNN(在考察語義類能力的任務 WSD 中,Transformer 超過 RNN 和 CNN 大約 4-8 個絕對百分點),RNN 和 CNN 兩者能力差不太多。
長距離特征捕獲能力

在長距離特征捕獲能力方面,目前在特定的長距離特征捕獲能力測試任務中(主語 - 謂語一致性檢測,比如 we……..are…),實驗支持如下結論:原生 CNN 特征抽取器在這方面極為顯著地弱于 RNN 和 Transformer,Transformer 微弱優于 RNN 模型 (尤其在主語謂語距離小于 13 時),能力由強到弱排序為 Transformer>RNN>>CNN; 但在比較遠的距離上(主語謂語距離大于 13),RNN 微弱優于 Transformer,所以綜合看,可以認為Transformer 和 RNN 在這方面能力差不太多,而 CNN 則顯著弱于前兩者。
那么為什么 CNN 在捕獲長距離特征方面這么弱呢?這個我們在前文講述 CNN 的時候就說過,CNN 解決這個問題是靠堆積深度來獲得覆蓋更長的輸入長度的,所以 CNN 在這方面的表現與卷積核能夠覆蓋的輸入距離最大長度有關系。如果通過增大卷積核的 kernel size,同時加深網絡深度,以此來增加輸入的長度覆蓋。實驗證明這能夠明顯提升 CNN 的 long-range 特征捕獲能力。但是盡管如此,CNN 在這方面仍然顯著弱于 RNN 和 Transformer。這個問題背后的原因是什么呢(因為上述主語 - 謂語一致性任務中,CNN 的深度肯定可以覆蓋 13-25 這個長度了,但是表現還是很弱)?其實這是一個很好的值得探索的點。
對于 Transformer 來說,Multi-head attention 的 head 數量嚴重影響 NLP 任務中 Long-range 特征捕獲能力:結論是 head 越多越有利于捕獲 long-range 特征。在上頁 PPT 里寫明的論文出來之前,有個工作(論文:Tran. The Importance of Being Recurrent for Modeling Hierarchical Structure)的結論和上述結論不一致:它的結論是在” 主語 - 謂語一致性” 任務上,Transformer 表現是弱于 LSTM 的。如果綜合這兩篇論文,我們看似得到了相互矛盾的結論,那么到底誰是正確的呢?Why Self-attention 的論文對此進行了探索,它的結論是:這個差異是由于兩個論文中的實驗中 Transformer 的超參設置不同導致的,其中尤其是 multi-head 的數量,對結果影響嚴重,而如果正確設置一些超參,那么之前 Trans 的論文結論是不成立的。也就是說,我們目前仍然可以維持下面結論:在遠距離特征捕獲能力方面,Transformer 和 RNN 能力相近,而 CNN 在這方面則顯著弱于前兩者。
任務綜合特征抽取能力
上面兩項對比是從特征抽取的兩個比較重要的單項能力角度來評估的,其實更重要的是在具體任務中引入不同特征抽取器,然后比較效果差異,以此來綜合評定三者的綜合能力。那么這樣就引出一個問題:NLP 中的任務很多,哪些任務是最具有代表性的呢?答案是機器翻譯。你會看到很多 NLP 的重要的創新模型都是在機器翻譯任務上提出來的,這背后是有道理的,因為機器翻譯基本上是對 NLP 各項處理能力綜合要求最高的任務之一,要想獲得高質量的翻譯結果,對于兩種語言的詞法,句法,語義,上下文處理能力,長距離特征捕獲等等更方面都需要考慮進來才行。這是為何看到很多比較工作是在機器翻譯上作出的,這里給個背后原因的解釋,以避免被質疑任務單一,沒有說服力的問題。當然,我預料到那位 “因為吃虧少…. 愛挑刺” 的同學會這么質問我,沒關系,即使你對此提出質疑,我依然能夠拿出證據,為什么這么講,請往后看。
那么在以機器翻譯為代表的綜合特征抽取能力方面,三個特征抽取器哪個更好些呢?
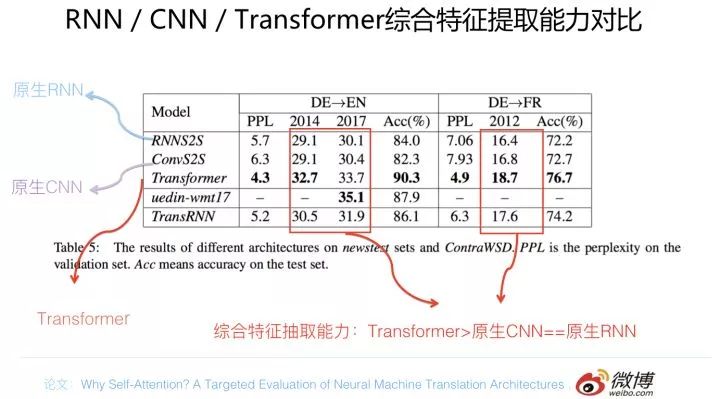
先給出一個機器翻譯任務方面的證據,仍然是 why Self attention 論文的結論,對比實驗結果數據參考上圖。在兩個機器翻譯任務中,可以看到,翻譯質量指標 BLEU 證明了如下結論:Transformer 綜合能力要明顯強于 RNN 和 CNN(你要知道,技術發展到現在階段,BLEU 絕對值提升 1 個點是很難的事情),而 RNN 和 CNN 看上去表現基本相當,貌似 CNN 表現略好一些。
你可能覺得一個論文的結論不太能說明問題,那么我再給出一個證據,不過這個證據只對比了 Transformer 和 RNN,沒帶 CNN 玩,不過關于說服力我相信你不會質疑,實驗對比數據如下:

上面是 GPT 論文的實驗結論,在 8 個不同的 NLP 任務上,在其它條件相同的情況下,只是把特征抽取器從 Transformer 換成 LSTM,平均下來 8 個任務得分掉了 5 個點以上。這具備足夠說服力嗎?
其實還有其它機器翻譯方面的實驗數據,篇幅原因,不一一列舉了。如果你是個較真的人,實在還想看,那請看下一節,里面有另外一個例子的數據讓來你服氣。如果歸納一下的話,現在能得出的結論是這樣的:從綜合特征抽取能力角度衡量,Transformer 顯著強于 RNN 和 CNN,而 RNN 和 CNN 的表現差不太多,如果一定要在這兩者之間比較的話,通常 CNN 的表現要稍微好于 RNN 的效果。
當然,需要強調一點,本部分所說的 RNN 和 CNN 指的是原生的 RNN 和 CNN 模型,就是說你可以在經典的結構上增加 attention,堆疊層次等各種改進,但是不包含對本身結構特別大的變動,就是說支持整容,但是不支持變性。這里說的原生版本指的是整容版本,我知道你肯定很關心有沒有變性版本的 RNN 和 CNN,我負責任地跟你說,有。你想知道它變性之后是啥樣子?等會你就看到了,有它們的照片給你。
并行計算能力及運算效率
關于三個特征抽取器的并行計算能力,其實我們在前文分述三個模型的時候都大致提過,在此僅做個歸納,結論如下:
RNN 在并行計算方面有嚴重缺陷,這是它本身的序列依賴特性導致的,所謂成也蕭何敗也蕭何,它的這個線形序列依賴性非常符合解決 NLP 任務,這也是為何 RNN 一引入到 NLP 就很快流行起來的原因,但是也正是這個線形序列依賴特性,導致它在并行計算方面要想獲得質的飛躍,看起來困難重重,近乎是不太可能完成的任務。
而對于 CNN 和 Transformer 來說,因為它們不存在網絡中間狀態不同時間步輸入的依賴關系,所以可以非常方便及自由地做并行計算改造,這個也好理解。
所以歸納一下的話,可以認為并行計算能力由高到低排序如下:Transformer 和 CNN 差不多,都遠遠遠遠強于 RNN。
我們從另外一個角度來看,先拋開并行計算能力的問題,單純地比較一下三個模型的計算效率。可能大家的直觀印象是 Transformer 比較重,比較復雜,計算效率比較低,事實是這樣的嗎?

上圖列出了單層的 Self attention/RNN/CNN 的計算效率,首先要注意:上面列的是 Self attention, 不是 Transformer 的 Block,因為 Transformer Block 里其實包含了好幾層,而不是單層。我們先說 self attention,等會說 Transformer Block 的計算量。
從上圖可以看出,如果是 self attention/CNN/RNN 單層比較計算量的話,三者都包含一個平方項,區別主要是:self attention 的平方項是句子長度,因為每一個單詞都需要和任意一個單詞發生關系來計算 attention,所以包含一個 n 的平方項。而 RNN 和 CNN 的平方項則是 embedding size。那么既然都包含平方項,怎么比較三個模型單層的計算量呢?首先容易看出 CNN 計算量是大于 RNN 的,那么 self attention 如何與其它兩者比較呢。可以這么考慮:如果句子平均長度 n 大于 embedding size,那么意味著 Self attention 的計算量要大于 RNN 和 CNN;而如果反過來,就是說如果 embedding size 大于句子平均長度,那么明顯 RNN 和 CNN 的計算量要大于 self attention 操作。而事實上是怎樣?我們可以想一想,一般正常的句子長度,平均起來也就幾十個單詞吧。而當前常用的 embedding size 從 128 到 512 都常見,所以在大多數任務里面其實 self attention 計算效率是要高于 RNN 和 CNN 的。
但是,那位因為吃虧吃的少所以喜歡挑刺的同學會繼續質問我:“哥,我想知道的是 Transformer 和 RNN 及 CNN 的計算效率對比,不是 self attention。另外,你能降低你腦袋里發出的水聲音量嗎?”。嗯,這個質問很合理,我來粗略估算一下,因為 Transformer 包含多層,其中的 skip connection 后的 Add 操作及 LayerNorm 操作不太耗費計算量,我先把它忽略掉,后面的 FFN 操作相對比較耗時,它的時間復雜度應該是 n 乘以 d 的平方。所以如果把 Transformer Block 多層當作一個整體和 RNN 及 CNN 單層對比的話,Transformer Block 計算量肯定是要多于 RNN 和 CNN 的,因為它本身也包含一個 n 乘以 d 的平方,上面列出的 self attention 的時間復雜度就是多出來的計算量。這么說起來,單個 Transformer Block 計算量大于單層 RNN 和 CNN,沒毛病。
上面考慮的是三者單層的計算量,可以看出結論是:Transformer Block >CNN >RNN。如果是考慮不同的具體模型,會與模型的網絡層深有很大關系,另外還有常見的 attention 操作,所以問題會比較復雜,這里不具體討論了。
說完非并行情況的三者單層計算量,再說回并行計算的問題。很明顯,對于 Transformer 和 CNN 來說,那個句子長度 n 是可以通過并行計算消掉的,而 RNN 因為序列依賴的問題,那個 n 就消不掉,所以很明顯,把并行計算能力考慮進來,RNN 消不掉的那個 n 就很要命。這只是理論分析,實際中三者計算效率到底如何呢?我們給出一些三者計算效率對比的實驗結論。
論文 “Convolutional Sequence to Sequence Learning” 比較了 ConvS2S 與 RNN 的計算效率, 證明了跟 RNN 相比,CNN 明顯速度具有優勢,在訓練和在線推理方面,CNN 比 RNN 快 9.3 倍到 21 倍。論文 “Dissecting Contextual Word Embeddings: Architecture and Representation” 提到了 Transformer 和 CNN 訓練速度比雙向 LSTM 快 3 到 5 倍。論文 “The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation” 給出了 RNN/CNN/Transformer 速度對比實驗,結論是:Transformer Base 速度最快;CNN 速度次之,但是比 Transformer Base 比慢了將近一倍;Transformer Big 速度再次,主要因為它的參數量最大,而吊在車尾最慢的是 RNN 結構。
總而言之,關于三者速度對比方面,目前的主流經驗結論基本如上所述:Transformer Base 最快,CNN 次之,再次 Transformer Big,最慢的是 RNN。RNN 比前兩者慢了 3 倍到幾十倍之間。
綜合排名情況
以上介紹內容是從幾個不同角度來對 RNN/CNN/Transformer 進行對比,綜合這幾個方面的實驗數據,我自己得出的結論是這樣的:單從任務綜合效果方面來說,Transformer 明顯優于 CNN,CNN 略微優于 RNN。速度方面 Transformer 和 CNN 明顯占優,RNN 在這方面劣勢非常明顯。這兩者再綜合起來,如果我給的排序結果是Transformer>CNN>RNN,估計沒有什么問題吧?那位吃虧….. 愛挑刺的同學,你說呢?
從速度和效果折衷的角度看,對于工業界實用化應用,我的感覺在特征抽取器選擇方面配置 Transformer base 是個較好的選擇。
三者的合流:向 Transformer 靠攏
上文提到了,Transformer 的效果相對原生 RNN 和 CNN 來說有比較明顯的優勢,那么是否意味著我們可以放棄 RNN 和 CNN 了呢?事實倒也并未如此。我們聰明的科研人員想到了一個巧妙的改造方法,我把它叫做 “寄居蟹” 策略(就是上文說的 “變性” 的一種帶有海洋文明氣息的文雅說法)。什么意思呢?我們知道 Transformer Block 其實不是只有一個構件,而是由 multi-head attention/skip connection/Layer Norm/Feed forward network 等幾個構件組成的一個小系統,如果我們把 RNN 或者 CNN 塞到 Transformer Block 里會發生什么事情呢?這就是寄居蟹策略的基本思路。
那么怎么把 RNN 和 CNN 塞到 Transformer Block 的肚子里,讓它們背上重重的殼,從而能夠實現寄居策略呢?
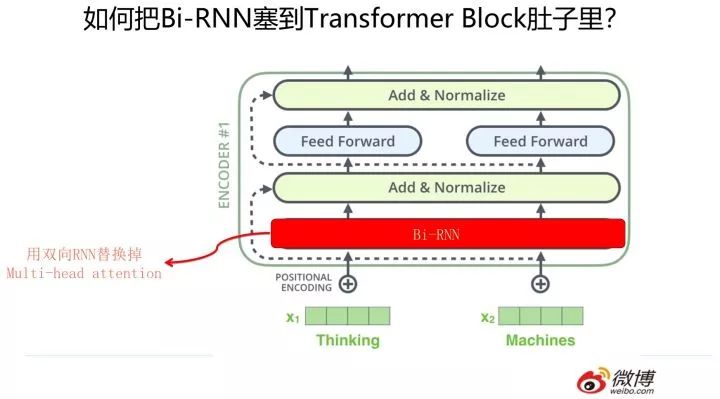
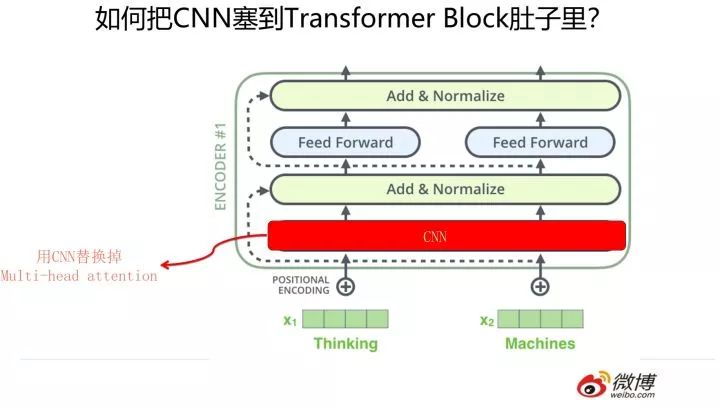
其實很簡單,參考上面兩張 PPT,簡而言之,大的方向就是把 self attention 模塊用雙向 RNN 或者 CNN 替換掉,Transformer Block 的其它構件依然健在。當然這只是說明一個大方向,具體的策略可能有些差異,但是基本思想八九不離十。
那么如果 RNN 和 CNN 采取這種寄居策略,效果如何呢?他們還爬的動嗎?其實這種改造方法有奇效,能夠極大提升 RNN 和 CNN 的效果。而且目前來看,RNN 或者 CNN 想要趕上 Transformer 的效果,可能還真只有這個辦法了。

我們看看 RNN 寄居到 Transformer 后,效果是如何的。上圖展示了對原生 RNN 不斷進行整容手術,逐步加入 Transformer 的各個構件后的效果。我們從上面的逐步變身過程可以看到,原生 RNN 的效果在不斷穩定提升。但是與土生土長的 Transformer 相比,性能仍然有差距。
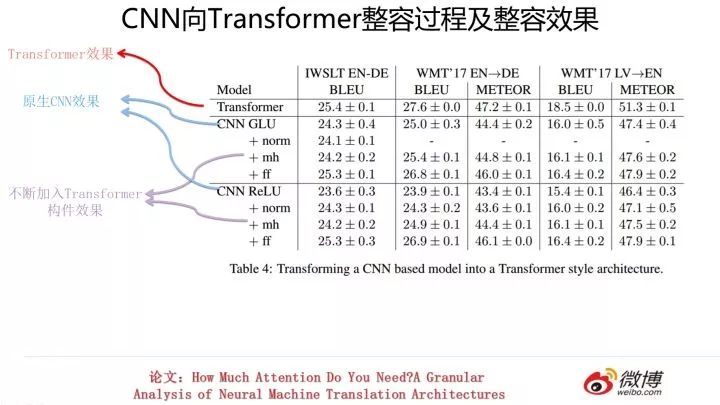
類似的,上圖展示了對 CNN 進行不斷改造的過程以及其對應效果。同樣的,性能也有不同幅度的提升。但是也與土家 Transformer 性能存在一些差距。
這說明什么?我個人意見是:這說明 Transformer 之所以能夠效果這么好,不僅僅 multi-head attention 在發生作用,而是幾乎所有構件都在共同發揮作用,是一個小小的系統工程。
但是從上面結果看,變性版本 CNN 好像距離 Transformer 真身性能還是比不上,有些數據集合差距甚至還很大,那么是否意味著這條路也未必走的通呢?Lightweight convolution 和 Dynamic convolutions 給人們帶來一絲曙光,在論文 “Pay Less Attention With LightweightI and Dynamic Convolutions” 里提出了上面兩種方法,效果方面基本能夠和 Transformer 真身相當。那它做了什么能夠達成這一點呢?也是寄居策略。就是用 Lightweight convolution 和 Dynamic convolutions 替換掉 Transformer 中的 Multi-head attention 模塊,其它構件復用了 Transformer 的東西。和原生 CNN 的最主要區別是采用了 Depth-wise separable CNN 以及 softmax-normalization 等優化的 CNN 模型。
而這又說明了什么呢?我覺得這說明了一點:RNN 和 CNN 的大的出路在于寄生到 Transformer Block 里,這個原則沒問題,看起來也是他倆的唯一出路。但是,要想效果足夠好,在塞進去的 RNN 和 CNN 上值得花些功夫,需要一些新型的 RNN 和 CNN 模型,以此來配合 Transformer 的其它構件,共同發揮作用。如果走這條路,那么 RNN 和 CNN 翻身的一天也許還會到來。
盡管如此,我覺得 RNN 這條路仍然不好走,為什么呢,你要記得 RNN 并行計算能力差這個天生缺陷,即使把它塞到 Transformer Block 里,別說現在效果還不行,就算哪天真改出了一個效果好的,但是因為它的并行能力,會整體拖慢 Transformer 的運行效率。所以我綜合判斷 RNN 這條路將來也走不太通。
2019 來自未來的消息:總結
很多年前的小學語文課本上有句話,是這么說的:“張華考上了北京大學;李萍進了中等技術學校;我在百貨公司當售貨員:我們都有光明的前途”。我們小的時候看到這句話,對此深信不疑,但是走到 2019 的今天,估計已經沒有父母愿意跟他們的孩子說這句話了,畢竟欺騙孩子是個挺不好的事情。如果套用這句話來說明 NLP 的三大特征抽取器的前途的話,應該是這樣的:“Transformer 考上了北京大學;CNN 進了中等技術學校,希望有一天能夠考研考進北京大學;RNN 在百貨公司當售貨員:我們都有看似光明的前途。”
我們把上文的所有證據都收集起來進行邏輯推理,可以模仿曹雪芹老師,分別給三位 NLP 界佳麗未來命運寫一句判詞。當然,再次聲明,這是我個人判斷。
進退維谷的 RNN
為什么說 RNN 進退維谷呢?有幾個原因。
首先,如果靠原生的 RNN(包括 LSTM,GRU 以及引入 Attention 以及堆疊層次等各種你能想到的改進方法,可以一起上),目前很多實驗已經證明效果比起 Transformer 有較大差距,現在看基本沒有迎頭趕上的可能,所以原生的 RNN 從效果來講是處于明顯劣勢的。
其次,原生的 RNN 還有一個致命的問題:并行計算能力受限制太嚴重。想要大規模實用化應用?目前看希望渺茫。我們前面說過,決定了 RNN 本身的根本特質是:T 時刻隱層節點對前向輸入及中間計算結果的序列依賴,因為它要線形序列收集前面的信息,這是 RNN 之所以是 RNN 的最主要特點。正是它的這個根本特質,使得 RNN 的并行計算能力想要獲得根本解決基本陷入了一個兩難的境地:要么仍然保持 RNN 序列依賴的根本特性,這樣不論怎么改造,因為這個根本還在,所以 RNN 依舊是 RNN,所謂 “我就是我,是不一樣的煙火”,但是如果這樣,那么其并行能力基本無法有力發揮,天花板很低;當然除此外,還有另外一條路可走,就是把這種序列依賴關系打掉,如果這樣,那么這種打掉序列依賴關系的模型雖然看上去仍然保留了部分 RNN 整形前的樣貌,其實它骨子里已經是另外一個人了,這已經不是你記憶中的 RNN 了。就是說,對 RNN 來說,要么就認命接受慢的事實,躲進小樓成一統,管他春夏與秋冬,僅僅是學術界用來發表論文的一種載體,不考慮大規模實用化的問題。要么就徹底改頭換面變成另外一個人,如果真走到這一步,我想問的是:你被別人稱為高效版本的 RNN,你自己好意思答應嗎?這就是 RNN 面臨的兩難境地。
再次,假設我們再樂觀一點,把對 RNN 的改造方向定位為將 RNN 改造成類似 Transformer 的結構這種思路算進來:無非就是在 Transformer 的 Block 里,把某些部件,當然最可行的是把 Multi-head self attention 部件換成 RNN。我們就算退一步講,且將這種大幅結構改造的模型也算做是 RNN 模型吧。即使這樣,已經把自己整形成長得很像 Transformer 了,RNN 依然面臨上述原生 RNN 所面臨的同樣兩個困境:一方面即使這種連變性削骨都上的大幅度整容版本的 RNN,效果雖然有明顯提升,但是仍然比不過 Transformer;另外,一旦引入 RNN 構件,同樣會觸發 Transformer 結構的并行計算能力問題。所以,目前 Transformer 發動機看上去有點帶不動 RNN 這個隊友。
綜合以上幾個因素,我們可以看出,RNN 目前處于進退兩難的地步,我覺得它被其它模型替換掉只是時間問題,而且好像留給它的時間不多了。當然,這是我個人意見。我說這番話的時候,你是不是又聽到了水聲?
我看到網上很多人還在推 RNN 說:其實還是 RNN 好用。我覺得這其實是一種錯覺。之所以會產生這個錯覺,原因來自兩個方面:一方面是因為 RNN 發展歷史長,所以有大量經過優化的 RNN 框架可用,這對技術選型選擇困難癥患者來說是個福音,因為你隨手選一個知名度還可以的估計效果就不錯,包括對一些數據集的前人摸索出的超參數或者調參經驗;而 Transformer 因為歷史太短,所以各種高效的語言版本的優秀框架還少,選擇不多。另外,其實我們對 Transformer 為何有效目前還不是特別清楚,包括相關的各種數據集合上的調參經驗公開的也少,所以會覺得調起來比較費勁。隨著框架越來越多,以及經驗分享越來越充分,這個不再會是問題。這是一方面。另外一方面,很多人反饋對于小數據集 RNN 更好用,這固然跟 Transformer 的參數量比較多有關系,但是也不是沒有解決辦法,一種方式是把 Block 數目降低,減少參數量;第二種辦法是引入 Bert 兩階段訓練模型,那么對于小數據集合來說會極大緩解效果問題。所以綜合這兩方面看,RNN 貌似在某些場合還有優勢,但是這些所謂的優勢是很脆弱的,這其實反映的是我們對 Transformer 整體經驗不足的事實,隨著經驗越來越豐富,RNN 被 Transformer 取代基本不會有什么疑問。
一息尚存的 CNN
CNN 在 14 年左右在 NLP 界剛出道的時候,貌似跟 RNN 比起來表現并不算太好,算是落后生,但是用發展的眼光看,未來的處境反而看上去比 RNN 的狀態還要占優一些。之所以造成這個奇怪現象,最主要的原因有兩個:一個是因為 CNN 的天生自帶的高并行計算能力,這對于延長它的生命力發揮了很大作用。這就決定了與 Transformer 比起來,它并不存在無法克服的困難,所以仍然有希望;第二,早期的 CNN 做不好 NLP 的一個很大原因是網絡深度做不起來,隨著不斷借鑒圖像處理的新型 CNN 模型的構造經驗,以及一些深度網絡的優化 trick,CNN 在 NLP 領域里的深度逐步能做起來了。而既然深度能做起來,那么本來 CNN 做 NLP 天然的一個缺陷:無法有效捕獲長距離特征的問題,就得到了極大緩解。目前看可以靠堆深度或者結合 dilated CNN 來一定程度上解決這個問題,雖然還不夠好,但是仍然是那句話,希望還在。
但是,上面所說只是從道理分析角度來講 CNN 的希望所在,話分兩頭,我們說回來,目前也有很多實驗證明了原生的 CNN 在很多方面仍然是比不過 Transformer 的,典型的還是長距離特征捕獲能力方面,原生的 CNN 版本模型仍然極為顯著地弱于 RNN 和 Transformer,而這點在 NLP 界算是比較嚴重的缺陷。好,你可以說:那我們把 CNN 引到 Transformer 結構里,比如代替掉 Self attention,這樣和 Transformer 還有一戰吧?嗯,是的,目前看貌似只有這條路是能走的通的,引入 depth separate CNN 可以達到和 Transformer 接近的效果。但是,我想問的是:你確認長成這樣的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你確認它的親朋好友還能認出它嗎?
當然,我之所以寫 CNN 一息尚存,是因為我覺得把 CNN 塞到 Transformer 肚子里這種方案,對于篇章級別的 NLP 任務來說,跟采取 self attention 作為發動機的 Transformer 方案對比起來,是具有極大優勢的領域,也是適合它的戰場,后面我估計會出現一些這方面的論文。為什么這么講?原因下面會說。
穩操勝券的 transformer
我們在分析未來 NLP 的三大特征抽取器哪個會勝出,我認為,起碼根據目前的信息來看,其實 Transformer 在很多戰場已經贏了,在這些場地,它未來還會繼續贏。為什么呢?上面不是說了嗎,原生的 RNN 和 CNN,總有一些方面顯著弱于 Transformer(并行計算能力或者效果,或者兩者同時都比 Transformer 弱)。那么他們未來的希望,目前大家都寄托在把 RNN 和 CNN 寄生在 Transformer Block 里。RNN 不用說了,上面說過它的進退維艱的現狀。單說 CNN 吧,還是上一部分的那句話,我想問的是:你確認長成這樣的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你確認它的親朋還能認出它嗎?
目前能夠和 Transformer 一戰的 CNN 模型,基本都已經長成 Transformer 的模樣了。而這又說明了什么呢?難道這是 CNN 要能戰勝 Transformer 的跡象嗎?這是一道留給您的思考題和辯論題。當然,我不參加辯論。
Transformer 作為一個新模型,并不是完美無缺的。它也有明顯的缺點:首先,對于長輸入的任務,典型的比如篇章級別的任務(例如文本摘要),因為任務的輸入太長,Transformer 會有巨大的計算復雜度,導致速度會急劇變慢。所以估計短期內這些領地還能是 RNN 或者長成 Transformer 模樣的 CNN 的天下(其實目前他倆這塊做得也不好),也是目前看兩者的希望所在,尤其是 CNN 模型,希望更大一些。但是是否 Transformer 針對長輸入就束手無策,沒有解決辦法呢?我覺得其實并不是,比如拍腦袋一想,就能想到一些方法,雖然看上去有點丑陋。比如可以把長輸入切斷分成 K 份,強制把長輸入切短,再套上 Transformer 作為特征抽取器,高層可以用 RNN 或者另外一層 Transformer 來接力,形成 Transformer 的層級結構,這樣可以把 n 平方的計算量極大減少。當然,這個方案不優雅,這個我承認。但是我提示你一下:這個方向是個值得投入精力的好方向,你留意一下我這句話,也許有意想不到的收獲。(注:上面這段話是我之前早已寫好的,結果今天(1 月 12 日)看見媒體號在炒作:“Transforme-XL,速度提升 1800 倍”云云。看了新聞,我找來 Transformer-XL 論文看了一下,發現它解決的就是輸入特別長的問題,方法呢其實大思路和上面說的內容差不太多。說這么多的意思是:我并不想刪除上面內容,為避免發出來后,那位 “愛挑刺” 同學說我拷貝別人思路沒引用。我決定還是不改上面的說法,因為這個點子實在是太容易想到的點子,我相信你也能想到。)除了這個缺點,Transformer 整體結構確實顯得復雜了一些,如何更深刻認識它的作用機理,然后進一步簡化它,這也是一個好的探索方向,這句話也請留意。還有,上面在做語義特征抽取能力比較時,結論是對于距離遠于 13 的長距離特征,Transformer 性能弱于 RNN,說實話,這點是比較出乎我意料的,因為 Transformer 通過 Self attention 使得遠距離特征直接發生關系,按理說距離不應該成為它的問題,但是效果竟然不如 RNN,這背后的原因是什么呢?這也是很有價值的一個探索點。
我預感到我可能又講多了,能看到最后不容易,上面幾段話算是送給有耐心的同學的禮物,其它不多講了,就此別過,請忽略你聽到的嘩嘩的水聲。
-
Transformer
+關注
關注
0文章
145瀏覽量
6034 -
自然語言
+關注
關注
1文章
291瀏覽量
13384 -
nlp
+關注
關注
1文章
489瀏覽量
22071
原文標題:Transformer一統江湖:自然語言處理三大特征抽取器比較
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Zigbee是否真的窮途末路?NB-IoT是否能一統江湖?
NLPIR語義分析是對自然語言處理的完美理解
【推薦體驗】騰訊云自然語言處理
什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網監
工商網監
評論