 CMU、谷歌大腦的研究者最新提出萬用NLP模型Transformer的升級版
CMU、谷歌大腦的研究者最新提出萬用NLP模型Transformer的升級版
CMU、谷歌大腦的研究者最新提出萬用NLP模型Transformer的升級版——Transformer-XL。這個新架構在5個數據集上都獲得了強大的結果,在評估中甚至比原始Transformer快1800+倍。研究人員公開了代碼、預訓練模型和超參數。
Transformer是谷歌在2017年提出的一個革新性的NLP框架,相信大家對那篇經典論文吸睛的標題仍印象深刻:Attention Is All You Need。
自那以來,業內人士表示,在機器翻譯領域,Transformer 已經幾乎全面取代 RNN。總之 Transformer 確實是一個非常有效且應用廣泛的結構,應該可以算是自 seq2seq 之后又一次 “革命”。
最近,CMU的Zihang Dai,Yiming Yang,Jaime Carbonell,Ruslan Salakhutdinov,以及谷歌的Zhilin Yang(楊值麟),William W. Cohen和Quoc V. Le等人提出了Transformer的升級版——Transformer-XL。這篇論文最初投給ICLR 2019,最新放在arXiv的版本更新了更好的結果,并公開了代碼、預訓練模型和超參數。
論文地址:
https://arxiv.org/pdf/1901.02860.pdf
Transformer網絡具有學習較長期依賴關系的潛力,但是在語言建模的設置中受到固定長度上下文(fixed-length context)的限制。
作為一種解決方案,這篇論文提出一種新的神經網絡結構——Transformer-XL,它使Transformer能夠在不破壞時間一致性的情況下學習固定長度以外的依賴性。
具體來說,Transformer-XL由一個segment-level的遞歸機制和一種新的位置編碼方案組成。這一方法不僅能夠捕獲長期依賴關系,而且解決了上下文碎片的問題。
實驗結果表明, Transformer-XL學習的依賴關系比RNN長80%,比vanilla Transformer長450%,在短序列和長序列上都獲得了更好的性能,并且在評估中比vanilla Transformer快1800+倍。
此外,Transformer-XL在5個數據集上都獲得了強大的結果。研究人員在enwiki8上將bpc/perplexity的最新 state-of-the-art(SoTA)結果從1.06提高到0.99,在text8上從1.13提高到1.08,在WikiText-103上從20.5提高到18.3,在One Billion Word, 上從23.7提高到21.8,在Penn Treebank上從55.3提高到54.5。
他們公布了代碼、預訓練模型和超參數,在Tensorflow和PyTorch中都可用。
Transformer-XL模型架構
為了解決前面提到的固定長度上下文的限制,Transformer-XL這個新架構(其中XL表示extra long)將遞歸(recurrence)的概念引入到self-attention網絡中。
具體來說,我們不再從頭開始計算每個新的段(segment)的隱藏狀態,而是重用(reuse)在前一段中獲得的隱藏狀態。被重用的隱藏狀態用作當前段的memory,這就在段之間建立一個循環連接。
因此,建模非常長期的依賴關系成為可能,因為信息可以通過循環連接傳播。同時,從上一段傳遞信息也可以解決上下文碎片(context fragmentation)的問題。
更重要的是,我們展示了使用相對位置編碼而不是絕對位置編碼的必要性,以便在不造成時間混亂的情況下實現狀態重用。因此,我們提出了一個簡單但更有效的相對位置編碼公式,該公式可以推廣到比訓練中觀察到的更長的attention lengths。
原始Transformer模型
為了將Transformer或self-attention應用到語言建模中,核心問題是如何訓練Transformer有效地將任意長的上下文編碼為固定大小的表示。給定無限內存和計算,一個簡單的解決方案是使用無條件Transformer解碼器處理整個上下文序列,類似于前饋神經網絡。然而,在實踐中,由于資源有限,這通常是不可行的。
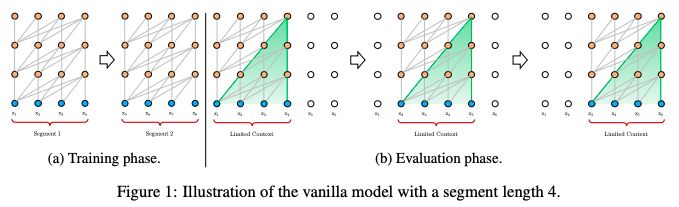
圖1:一個segment長度為4的vanilla model的圖示
一種可行但比較粗略的近似方法是將整個語料庫分割成可管理大小的更短的片段,只在每個片段中訓練模型,忽略來自前一段的所有上下文信息。這是Al-Rfou et al(2018)提出的想法,我們稱之為原始模型(vanilla model),它的圖示如圖1a。
在評估過程中,vanilla 模型在每個步驟都消耗與訓練期間相同長度的一個segment,但是在最后一個位置只是進行一次預測。然后,在下一步中,這個segment只向右移動一個位置,新的segment必須從頭開始處理。
如圖1b所示,該過程保證了每個預測在訓練過程中利用的上下文盡可能長,同時也緩解了訓練過程中遇到的上下文碎片問題。然而,這個評估過程成本是非常高的。
接下來,我們將展示我們所提出的架構能夠大大提高評估速度。
Transformer-XL
為了解決固定長度上下文的局限性,我們建議在Transformer架構中引入一種遞歸機制(recurrence mechanism)。
在訓練過程中,對上一個segment計算的隱藏狀態序列進行修復,并在模型處理下一個新的segment時將其緩存為可重用的擴展上下文,如圖2a所示。
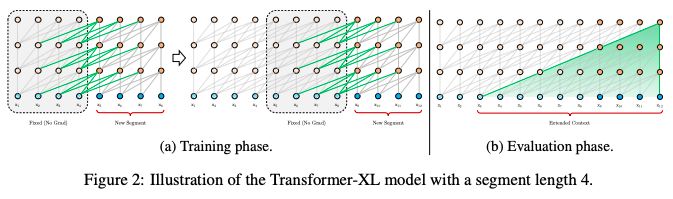
圖2:一個segment長度為4的Transformer-XL模型
這種遞歸機制應用于整個語料庫的每兩個連續的segment,它本質上是在隱藏狀態中創建一個segment-level 的遞歸。因此,所使用的有效上下文可以遠遠超出兩個segments。
除了實現超長的上下文和解決碎片問題外,這種遞歸方案的另一個好處是顯著加快了評估速度。
具體地說,在評估期間,可以重用前面部分的表示,而不是像普通模型那樣從頭開始計算。在enwiki8數據集的實驗中,Transformer-XL在評估過程比普通模型快1800倍以上。
實驗和結果
我們將Transformer-XL應用于單詞級和字符級語言建模的各種數據集,與state-of-the-art 的系統進行了比較,包括WikiText-103 (Merity et al., 2016), enwiki8 (LLC, 2009), text8 (LLC, 2009), One Billion Word (Chelba et al., 2013), 以及 Penn Treebank (Mikolov & Zweig, 2012).
實驗結果表明, Transformer-XL學習的依賴關系比RNN長80%,比vanilla Transformer長450%,在短序列和長序列上都獲得了更好的性能,并且在評估中比vanilla Transformer快1800+倍。
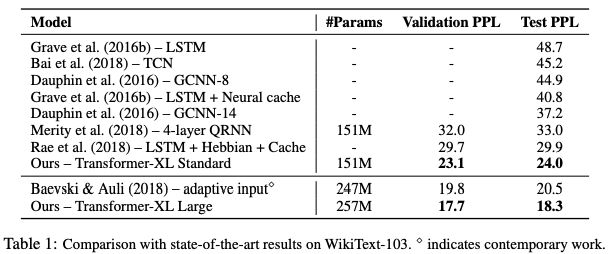
表1:在WikiText-103上與SoTA結果的比較
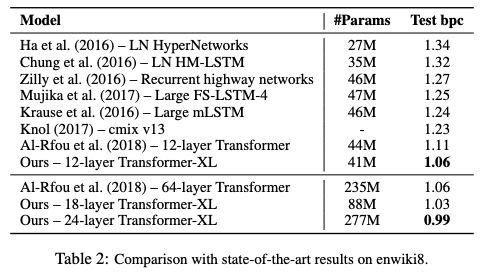
表2:在enwiki8上與SoTA結果的比較
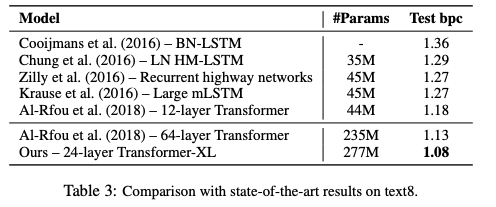
表3:在text8上與SoTA結果的比較
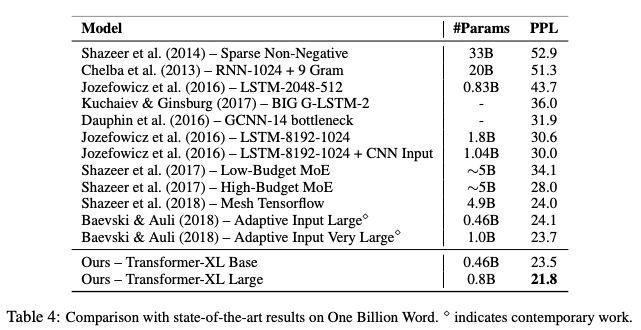
表4:在One Billion Word上與SoTA結果的比較
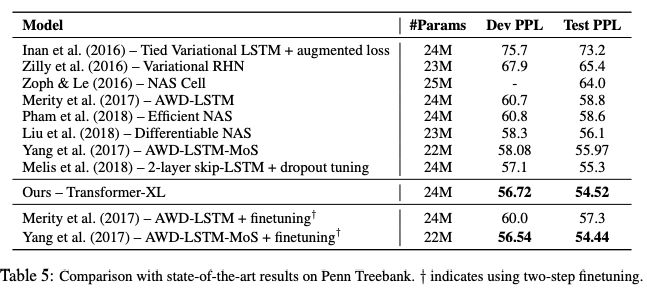
表5:在Penn Treebank上與SoTA結果的比較
Transformer-XL在5個數據集上都獲得了強大的結果。研究人員在enwiki8上將bpc/perplexity的最新 state-of-the-art(SoTA)結果從1.06提高到0.99,在text8上從1.13提高到1.08,在WikiText-103上從20.5提高到18.3,在One Billion Word上從23.7提高到21.8,在Penn Treebank上從55.3提高到54.5。
評估速度
最后,我們將模型的評估速度與vanilla Transformer模型進行了比較。
如表9所示,與Al-Rfou et al. (2018).的架構相比,由于state reuse方案,Transformer-XL的評估速度加快了高達1874倍。
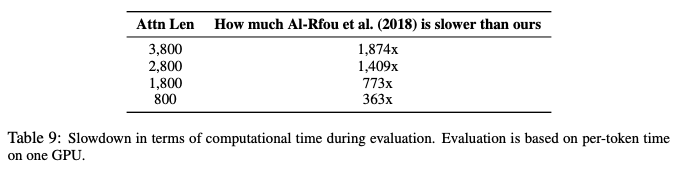
表9:評估時間比較
結論
我們提出了一種新的架構,Transformer-XL,這是一個超出了固定長度的上下文限制的self-attention的語言建模架構。
我們的主要技術貢獻包括在一個純粹的 self-attentive 模型中引入遞歸的概念,并推導出一種新的位置編碼方案。這兩種技術形成了一套完整的解決方案,因為它們中的任何一種單獨都不能解決固定長度上下文的問題。
Transformer-XL是第一個在字符級和單詞級語言建模方面都取得了比RNN更好結果的self-attention模型。Transformer-XL還能夠建模比RNN和Transformer更長期的依賴關系,并且與vanilla Transformers相比在評估過程中取得了顯著的加速。
-
解碼器
+關注
關注
9文章
1144瀏覽量
40855 -
谷歌
+關注
關注
27文章
6180瀏覽量
105768 -
神經網絡
+關注
關注
42文章
4778瀏覽量
101014
原文標題:谷歌、CMU重磅論文:Transformer升級版,評估速度提升超1800倍!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
萬用表的基本使用方法 萬用表使用注意事項
萬用表的工作原理 萬用表校準的方法
萬用表維修與保養技巧
數字萬用表與模擬萬用表的區別
萬用表使用方法 如何選擇萬用表
勝利萬用表的各個型號
勝利萬用表和優利德萬用表哪個好
Transformer語言模型簡介與實現過程
使用PyTorch搭建Transformer模型
指針萬用表和數字萬用表有什么區別?
指針式萬用表與數字式萬用表的區別
基于Transformer模型的壓縮方法






 工商網監
工商網監
評論