") 工業(yè)大數(shù)據(jù)挖掘的利器——Spark MLlib
工業(yè)大數(shù)據(jù)挖掘的利器——Spark MLlib
格物匯之前刊發(fā)的《工業(yè)大數(shù)據(jù)處理領域的“網(wǎng)紅”——Apache Spark》中提到,在“中國制造2025”的技術路線圖中,工業(yè)大數(shù)據(jù)是作為重要突破點來規(guī)劃的,而在未來的十年,以數(shù)據(jù)為核心構建的智能化體系會成為支撐智能制造和工業(yè)互聯(lián)網(wǎng)的核心動力。Apache Spark 作為新一代輕量級大數(shù)據(jù)快速處理平臺,集成了大數(shù)據(jù)相關的各種能力,是理解大數(shù)據(jù)的首選。Spark有一個機器學習組件是專門用于解決海量數(shù)據(jù)如何進行高效數(shù)據(jù)挖掘的問題,那就是SparkMLlib組件。今天的格物匯就給大家詳細介紹一下Spark MLlib。
Spark MLlip 天生適合迭代計算
在介紹Spark MLlib 這個組件前,我們先了解一下機器學習的定義。在維基百科中對機器學習給出如下定義:
機器學習是一門人工智能的科學,該領域的主要研究對象是人工智能,特別是如何在經驗學習中改善具體算法的性能。
機器學習是對能通過經驗自動改進的計算機算法的研究。
機器學習是用數(shù)據(jù)或以往的經驗,以此優(yōu)化計算機程序的性能標準。
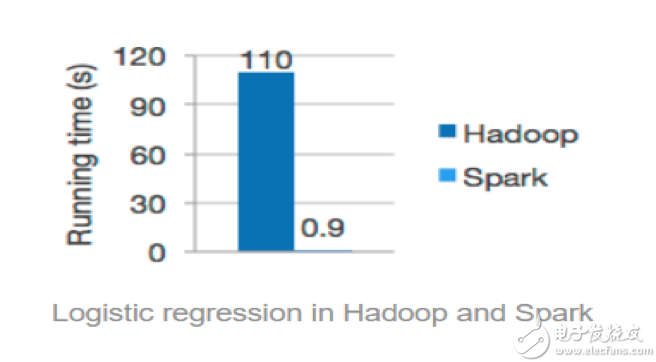
很明顯,機器學習的重點之一就是“經驗”,對于計算機而言,經驗就是需要進行多次迭代計算得到的,Spark 的基于內存的計算模式天生就擅長迭代計算,多個步驟計算直接在內存中完成,只有在必要時才會操作磁盤和網(wǎng)絡,所以說Spark正是機器學習的理想的平臺。在Spark官方首頁中展示了Logistic Regression算法在Spark和Hadoop中運行的性能比較,如圖下圖所示。
Spark MLlib 算法以及功能
MLlib由一些通用的學習算法以及工具組成,其中包括分類、回歸、聚類、協(xié)同過濾、降維等,同時還包括底層的優(yōu)化原語和高層的管道API。具體主要包含以下內容:
>>>>
回歸(Regression)
線性回歸(Linear)
廣義線性回歸(Generalized Linear)
決策樹(Decision Tree)
隨機森林(Random Forest)
梯度提升樹(Gradient-boosted Tree)
Survival
Isotonic
>>>>
分類(Classification)
邏輯回歸(Logistic,二分類和多酚類)
決策樹(Decision Tree)
隨機森林(Random Forest)
梯度提升樹(Gradient-boosted Tree)
多層反饋(Multilayer Perceptron)
支持向量機(Linear support vector machine)
One-vs-All
樸素貝葉斯(Naive Bayes)
>>>>
聚類(Clustering)
K-means
隱含狄利克雷分布(LDA)
BisectingK-means
高斯混合模型(Gaussian Mixture Model)
協(xié)同過濾(Collaborative Filtering)
>>>>
特征工程(Featurization)
特征工程(Featurization)
特征提取
轉換
降維(Dimensionality reduction)
篩選(Selection)
>>>>
管道(Pipelines)
組合管道(Composing Pipelines)
構建、評估和調優(yōu)(Tuning)機器學習管道
>>>>
持久化(Persistence)
保存算法,模型和管道到持久化存儲器,以備后續(xù)使用
從持久化存儲器載入算法、模型和管道
>>>>
實用工具(Utilities)
線性代數(shù)(Linear algebra)
統(tǒng)計
數(shù)據(jù)處理
其他
綜上可見,Spark在機器學習上發(fā)展還是比較快的,目前已經支持了主流的統(tǒng)計和機器學習算法。
Spark MLlib API 變遷
Spark MLlib 組件從Spark 1.2版本以后就出現(xiàn)了兩套機器學習API:
spark.mllib基于RDD的機器學習API,是Spark最開始的機器學習API,在Spark1.0以前的版本就已經存在的了。
spark.ml提供了基于DataFrame 高層次的API,引入了PipLine,可以向用戶提供一個基于DataFrame的機器學習流式API套件。
Spark 2.0 版本開始,spark mllib就進入了維護模式,不再進行更新,后續(xù)等spark.ml API 足夠成熟并足以取代spark.mllib 的時候就棄用。
那為什么Spark要將基于RDD的API 切換成基于DataFrame的API呢?原因有以下三點:
首先相比spark.mllib,spark.ml的API更加通用和靈活,對用戶更加友好,并且spark.ml在DataFrame上的抽象級別更高,數(shù)據(jù)與操作的耦合度更低;
spark.ml中無論是什么模型,都提供了統(tǒng)一的算法操作接口,例如模型訓練就調用fit方法,不行spark.mllib中不同模型會有各種各樣的trainXXX;
受scikit-learn 的Pipline概念啟發(fā),spark.ml引入pipeline, 跟sklearn,這樣可以把很多操作(算法/特征提取/特征轉換)以管道的形式串起來,使得工作流變得更加容易。
如今工業(yè)互聯(lián)網(wǎng)飛速發(fā)展,企業(yè)內部往往存儲著TB級別甚至更大的數(shù)據(jù),面對海量數(shù)據(jù)的難以進行有效快速的進行數(shù)據(jù)挖掘等難題,Spark提供了MLlib 這個組件,通過利用了Spark 的內存計算和適合迭代型計算的優(yōu)勢,并且提供用戶友好的API,使用戶能夠輕松快速的應對海量數(shù)據(jù)挖掘的問題,加快工業(yè)大數(shù)據(jù)的價值變現(xiàn)。作為TCL集團孵化的創(chuàng)新型科技公司,格創(chuàng)東智正在致力于深度融合包括Spark在內的大數(shù)據(jù)、人工智能、云計算等前沿技術與制造行業(yè)經驗,打造行業(yè)領先的“制造x”工業(yè)互聯(lián)網(wǎng)平臺。隨著未來Spark社區(qū)在AI領域的不斷發(fā)力,相信Spark MLlib組件的表現(xiàn)會越來越出色。
本文作者:格創(chuàng)東智大數(shù)據(jù)工程師黃歡(轉載請注明作者及來源)
-
智能制造
+關注
關注
48文章
5611瀏覽量
76462 -
工業(yè)互聯(lián)網(wǎng)
關注
28文章
4328瀏覽量
94215 -
SPARK
+關注
關注
1文章
105瀏覽量
19948 -
工業(yè)大數(shù)據(jù)
關注
0文章
72瀏覽量
7867
發(fā)布評論請先 登錄
相關推薦
工業(yè)大數(shù)據(jù)
大數(shù)據(jù)開發(fā)之spark應用場景
工業(yè)大數(shù)據(jù)分析平臺的應用價值探討
工業(yè)大數(shù)據(jù)技術綜述
工業(yè)大數(shù)據(jù)處理領域的“網(wǎng)紅”——Apache Spark
工業(yè)大數(shù)據(jù)的概念
工業(yè)大數(shù)據(jù)和互聯(lián)網(wǎng)大數(shù)據(jù)區(qū)別
工業(yè)大數(shù)據(jù)前景
SparkMLlib GBDT算法工業(yè)大數(shù)據(jù)實戰(zhàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論