") 針對(duì)計(jì)算機(jī)生成的假臉假視頻DeepFake較為全面測(cè)評(píng)的論文
針對(duì)計(jì)算機(jī)生成的假臉假視頻DeepFake較為全面測(cè)評(píng)的論文
根據(jù)一篇針對(duì)計(jì)算機(jī)生成的假臉假視頻DeepFake較為全面測(cè)評(píng)的論文,現(xiàn)有的先進(jìn)人臉識(shí)別算法在面對(duì)計(jì)算機(jī)生成的假臉時(shí)基本束手無(wú)策,假臉生成算法和人臉識(shí)別軍備競(jìng)賽已經(jīng)開(kāi)始。不過(guò),目前還有些小技巧,可以幫你用肉眼來(lái)分辨計(jì)算機(jī)生成的假臉。
2015年,現(xiàn)任教皇方濟(jì)各 (Pope Francis) 訪美,他是首次對(duì)美國(guó)進(jìn)行正式訪問(wèn)的教皇,還將主持在美國(guó)領(lǐng)土上的首次封圣,并在國(guó)會(huì)發(fā)表演講。時(shí)任美國(guó)總統(tǒng)和副總統(tǒng)的奧巴馬及拜登,分別攜各自的夫人,一起在美國(guó)安德魯斯空軍基地 (Andrews Air Force Base,也是總統(tǒng)機(jī)隊(duì)“空軍一號(hào)”的駐地) 迎接了教皇專(zhuān)機(jī)的降臨。
訪問(wèn)期間,方濟(jì)各“一個(gè)出人意料之舉”震驚了世界:只見(jiàn)他在向圣壇禮拜后,轉(zhuǎn)身順手將桌布一抽,上演了一出絕妙的“抽桌布”戲法,動(dòng)作之行云流水,令人膜拜。
教皇竟然還會(huì)這一手!相關(guān)視頻很快就火遍了全美乃至全球。
2015年現(xiàn)任教皇訪美,上演絕妙“抽桌布”戲法,美國(guó)主教看后表示不爽。當(dāng)然,這段視頻是假造的,但這并不影響其流行。
世人震驚之余,幾乎都沒(méi)有懷疑——這個(gè)視頻當(dāng)然是假造的。
在“毫無(wú)PS痕跡”的說(shuō)法還十分流行的2015年,這個(gè)“毫無(wú)PS痕跡”的視頻成了后來(lái)被稱(chēng)為DeepFake視頻的始祖。
現(xiàn)如今,DeepFake已被用于指代所有看起來(lái)或聽(tīng)起來(lái)像真的一樣的假視頻或假音頻。
日前,Idiap 生物識(shí)別安全和隱私小組負(fù)責(zé)人 (注:Idiap研究所是瑞士的一家半私人非營(yíng)利性研究機(jī)構(gòu),隸屬于洛桑聯(lián)邦理工學(xué)院和日內(nèi)瓦大學(xué),進(jìn)行語(yǔ)音、計(jì)算機(jī)視覺(jué)、信息檢索、生物認(rèn)證、多模式交互和機(jī)器學(xué)習(xí)等領(lǐng)域的研究)、瑞士生物識(shí)別研究和測(cè)試中心主任 Sébastien Marcel 和他的同事、Idiap 研究所博士后 Pavel Korshunov 共同撰寫(xiě)了論文,首次對(duì)人臉識(shí)別方法檢測(cè) DeepFake 的效果進(jìn)行了較為全面的測(cè)評(píng)。

他們經(jīng)過(guò)一系列實(shí)驗(yàn)發(fā)現(xiàn),當(dāng)前已有的先進(jìn)人臉識(shí)別模型和檢測(cè)方法,在面對(duì) DeepFake 時(shí)基本可以說(shuō)是束手無(wú)策——性能最優(yōu)的圖像分類(lèi)模型 VGG 和基于 Facenet 的算法,分辨真假視頻錯(cuò)誤率高達(dá) 95%;基于唇形的檢測(cè)方法,也基本檢測(cè)不出視頻中人物說(shuō)話和口型是否一致。
Pavel Korshunov 和 Sébastien Marcel 指出,隨著換臉技術(shù)的不斷發(fā)展,更加逼真的 DeepFake 視頻,將對(duì)人臉識(shí)別技術(shù)構(gòu)成更大的挑戰(zhàn)。
“在 DeepFake 方法和檢測(cè)算法之間的一場(chǎng)新的軍備競(jìng)賽可能已經(jīng)開(kāi)始了。”
面對(duì)假臉生成算法,現(xiàn)有人臉識(shí)別系統(tǒng)幾乎束手無(wú)策
針對(duì) Deepfake 視頻中人臉識(shí)別的漏洞,兩人在論文中對(duì)基于VGG和Facenet的人臉識(shí)別系統(tǒng)做了漏洞分析,還使用SVM方法評(píng)估了 DeepFake 的幾種檢測(cè)方法,包括嘴唇動(dòng)作同步法和圖像質(zhì)量指標(biāo)檢測(cè)等。
結(jié)果令人遺憾——
無(wú)論是基于VGG還是基于Facenet的系統(tǒng),都不能有效區(qū)分GAN生成假臉與原始人臉。而且,越先進(jìn)的Facenet系統(tǒng)越容易受到攻擊。
VGG模型是2014年ILSVRC競(jìng)賽的第二名,第一名是GoogLeNet。但是VGG模型在多個(gè)遷移學(xué)習(xí)任務(wù)中的表現(xiàn)要優(yōu)于googLeNet。而且,從圖像中提取CNN特征,VGG模型是首選算法。它的缺點(diǎn)在于,參數(shù)量有140M之多,需要更大的存儲(chǔ)空間。但是這個(gè)模型很有研究?jī)r(jià)值。
Facenet該模型沒(méi)有用傳統(tǒng)的softmax的方式去進(jìn)行分類(lèi)學(xué)習(xí),而是抽取其中某一層作為特征,學(xué)習(xí)一個(gè)從圖像到歐式空間的編碼方法,然后基于這個(gè)編碼再做人臉識(shí)別、人臉驗(yàn)證和人臉聚類(lèi)等。
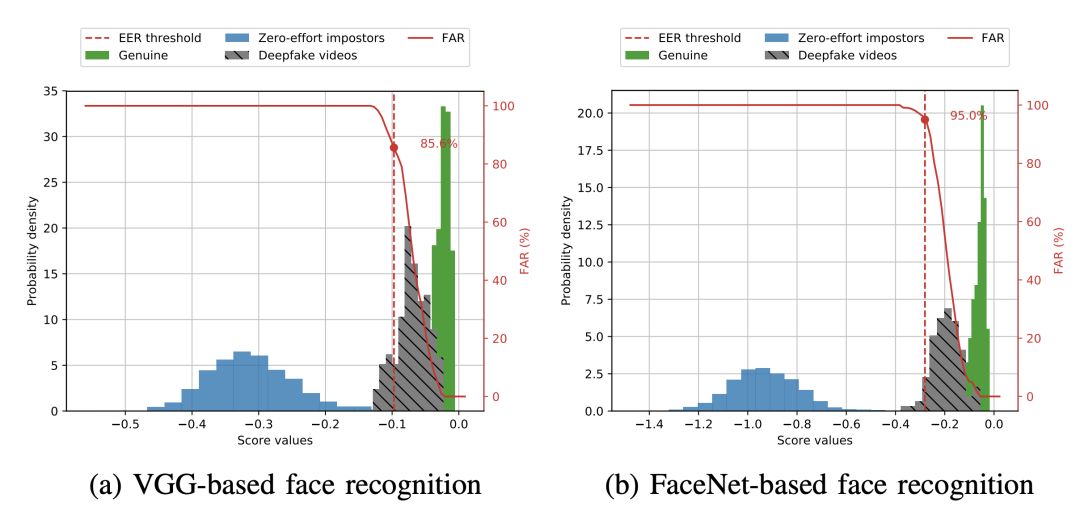
直方圖顯示了基于VGG和Facenet的人臉識(shí)別在高質(zhì)量人臉交換中的漏洞。
檢測(cè)Deepfake視頻
他們還考慮了幾種基線Deepfake檢測(cè)系統(tǒng),包括使用視聽(tīng)數(shù)據(jù)檢測(cè)唇動(dòng)和語(yǔ)音之間不一致的系統(tǒng),以及幾種單獨(dú)基于圖像的系統(tǒng)變體。這種系統(tǒng)的各個(gè)階段包括從視頻和音頻模態(tài)中提取特征,處理這些特征,然后訓(xùn)練兩個(gè)分類(lèi)器,將篡改的視頻與真實(shí)視頻分開(kāi)。
所有檢測(cè)系統(tǒng)的檢測(cè)結(jié)果如下表所示。
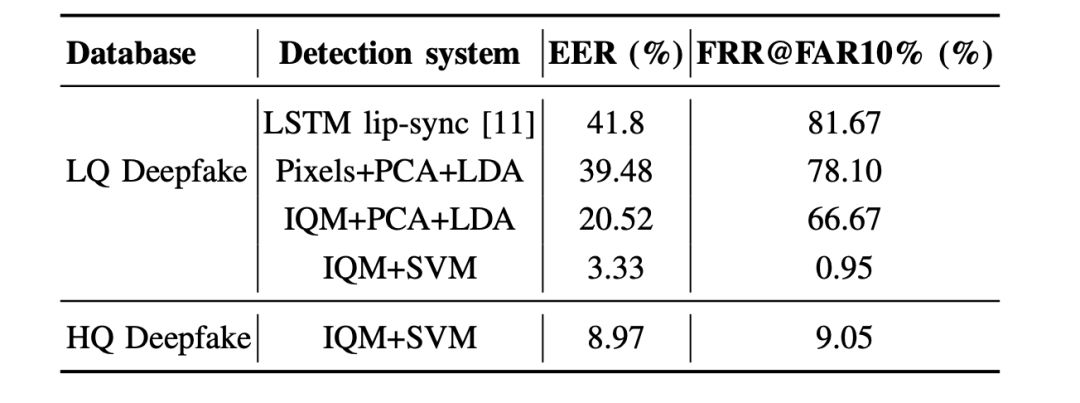
說(shuō)明一下表格中各種“符號(hào)”和數(shù)字的意思,你也可以直接跳過(guò)看本節(jié)最后結(jié)論:
在本系統(tǒng)中,使用MFCCs作為語(yǔ)音特征,以mouth landmarks之間的距離作為視覺(jué)特征。將主成分分析(PCA)應(yīng)用于聯(lián)合音視頻特征,降低特征塊的維數(shù),訓(xùn)練長(zhǎng)短期記憶(long short-term memory, LSTM)網(wǎng)絡(luò),將篡改和非篡改視頻進(jìn)行分離。
作為基于圖像的系統(tǒng),實(shí)現(xiàn)了以下功能:
Pixels+PCA+LDA:使用PCA-LDA分類(lèi)器將原始人臉作為特征,保留99%的方差,得到446維變換矩陣。
IQM+PCA+LDA:IQM特征與PCA-LDA分類(lèi)器結(jié)合,具有95%保留方差,導(dǎo)致2維變換矩陣。
IQM + SVM:具有SVM分類(lèi)器的IQM功能,每個(gè)視頻具有20幀的平均分?jǐn)?shù)。
基于圖像質(zhì)量測(cè)度(IQM)的系統(tǒng)借鑒了表示域(domain of presentation)的攻擊檢測(cè),表現(xiàn)出了較好的性能。作為IQM特征向量,使用129個(gè)圖像質(zhì)量度量,其中包括信噪比,鏡面反射率,模糊度等測(cè)量。
下圖為兩種不同換臉版本中性能最好的IQM+SVM系統(tǒng)的檢測(cè)誤差權(quán)衡(DET)曲線。
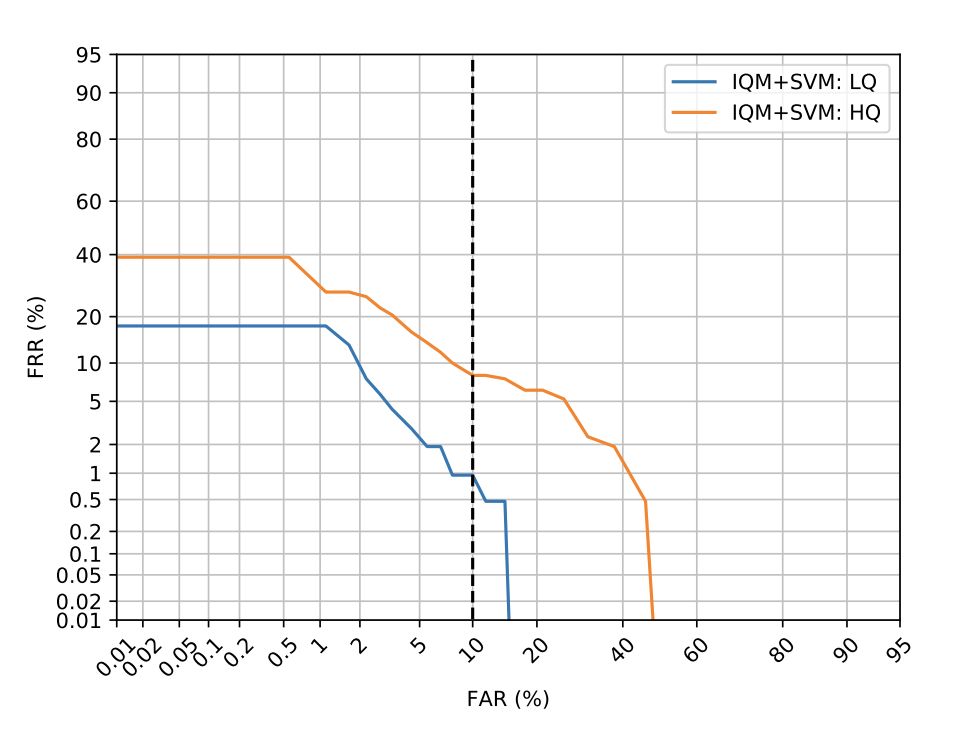
IQM + SVM Deepfake檢測(cè)
結(jié)果表明:
首先,基于唇部同步的算法不能檢測(cè)人臉交換,因?yàn)镚AN能夠生成與語(yǔ)音匹配的高質(zhì)量面部表情;因此,目前只有基于圖像的方法才能有效檢測(cè)Deepfake視頻。
其次,IQM+SVM系統(tǒng)對(duì)Deepfake視頻的檢測(cè)準(zhǔn)確率較高,但使用HQ模型生成的視頻具有更大的挑戰(zhàn)性,這意味著越先進(jìn)的人臉交換技術(shù)將愈發(fā)難以檢測(cè)。
假臉生成和真臉識(shí)別算法軍備競(jìng)賽已經(jīng)開(kāi)始
之前,大多數(shù)研究都集中在如何提高“換臉”技術(shù)上,為了響應(yīng)公眾對(duì)檢測(cè)”換臉“技術(shù)的需求,越來(lái)越多的研究人員開(kāi)始研究數(shù)據(jù)庫(kù)和檢測(cè)方法,包括使用較舊的換臉?lè)椒‵ace2Face 生成的圖像和視頻數(shù)據(jù),或使用Snapchat應(yīng)用程序收集的視頻。
在Pavel Korshunov和Sébastien Marcel寫(xiě)的這篇最新論文中,作者提供了首個(gè)使用基于開(kāi)源GAN方法進(jìn)行換臉的開(kāi)源視頻數(shù)據(jù)庫(kù)。
他們從公開(kāi)的VidTIMIT數(shù)據(jù)庫(kù)中,手動(dòng)選擇了16對(duì)長(zhǎng)相類(lèi)似的人,將這32個(gè)目標(biāo)都訓(xùn)練兩種不同的模型,分別為低質(zhì)量 (LQ) 模型,輸入/輸出大小為64×64,以及高質(zhì)量 (HQ) 模型,輸入/輸出大小為128×128尺寸的模型(參見(jiàn)圖1)。
圖1:來(lái)自VidTIMIT數(shù)據(jù)庫(kù)原始視頻,以及低質(zhì)量(LQ)和高質(zhì)量(HQ)Deepfake視頻的屏幕截圖
為了讓其他研究人員能夠?qū)ζ涑晒M(jìn)行驗(yàn)證、復(fù)制和擴(kuò)展,作者還提供了他們?cè)谘芯恐惺褂玫腄eepfake視頻數(shù)據(jù)庫(kù)、人臉識(shí)別系統(tǒng)和Deepfake檢測(cè)系統(tǒng),并將相應(yīng)的分?jǐn)?shù)一起以Python開(kāi)源包的形式放出。
肉眼分辨計(jì)算機(jī)生成假臉的一些技巧
就在不久前,英偉達(dá)發(fā)表論文,展示了計(jì)算機(jī)生成的逼真到恐怖的人臉圖像。對(duì)于虛假視頻泛濫的網(wǎng)絡(luò)來(lái)說(shuō),這可能導(dǎo)致一場(chǎng)迫在眉睫的“真相危機(jī)”。
英偉達(dá)新一代GAN生成的人臉,全都是不存在的人
以下圖片是從Nvidia的最新論文中獲取的截圖。看看這份指南里是怎么說(shuō)的吧。
不對(duì)稱(chēng)的面部特征、配飾
上面的圖片有一堆可疑的線索。最簡(jiǎn)單的就是,此人頭頂位置出現(xiàn)的大塊的怪異斑點(diǎn)。這種現(xiàn)象或像差在AI生成的圖像中很常見(jiàn),與幾年前谷歌的DeepDream實(shí)驗(yàn)的表現(xiàn)一致。
但是,當(dāng)你環(huán)顧這個(gè)人的耳朵時(shí),會(huì)發(fā)現(xiàn)圖像略微不對(duì)稱(chēng)。一側(cè)頭發(fā)顯得模糊而且看上去很奇怪,且一只耳朵上沒(méi)有耳環(huán)。
算法不具備常識(shí),并且不懂規(guī)則,比如不知道耳環(huán)一般要兩只耳朵都戴。因此,AI算法有時(shí)無(wú)法生成足夠真實(shí)的面部特征或首飾等。
牙齒
AI算法不知道正常人應(yīng)該有多少顆牙以及這些牙齒的朝向。一般AI算法不會(huì)選擇多角度描繪出這些牙齒的樣貌,而是亂來(lái)一氣。圖中的虛假頭像的牙齒就是典型例子。
上面這張圖可能稍微難辨別一點(diǎn),但如果你仔細(xì)看她的牙,會(huì)發(fā)現(xiàn)她中間第三顆牙異常地小,而且耳朵也非常不自然,所以這也是一張生成的假頭像。
衣服和背景
上邊圖中的女性的衣服明顯有問(wèn)題,此外注意這張圖片的背景也很奇怪,此外右側(cè)的頭發(fā)和耳環(huán)部分都很不自然,而且耳環(huán)只有一只。
上圖中,人物的衣服實(shí)在太奇怪了,圖中左側(cè)的耳朵上并未戴耳環(huán)等配飾,但衣服上方卻出現(xiàn)了一個(gè)懸在空中的“不明裝飾物”,這種現(xiàn)象在AI生成的虛假圖像中也不少見(jiàn)。
-
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3845瀏覽量
64590 -
GaN
+關(guān)注
關(guān)注
19文章
1964瀏覽量
73943 -
人臉識(shí)別
+關(guān)注
關(guān)注
76文章
4015瀏覽量
82160
原文標(biāo)題:AI假臉王生成!新一代GAN攻破幾乎所有人臉識(shí)別系統(tǒng),勝率95%
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
量子計(jì)算機(jī)與普通計(jì)算機(jī)工作原理的區(qū)別
計(jì)算機(jī)接口位于什么之間
晶體管計(jì)算機(jī)和電子管計(jì)算機(jī)有什么區(qū)別
計(jì)算機(jī)視覺(jué)有哪些優(yōu)缺點(diǎn)
地平線科研論文入選國(guó)際計(jì)算機(jī)視覺(jué)頂會(huì)ECCV 2024
計(jì)算機(jī)系統(tǒng)的組成和功能
計(jì)算機(jī)視覺(jué)的工作原理和應(yīng)用
計(jì)算機(jī)視覺(jué)和圖像處理的區(qū)別和聯(lián)系
計(jì)算機(jī)視覺(jué)屬于人工智能嗎
計(jì)算機(jī)視覺(jué)的主要研究方向
工業(yè)計(jì)算機(jī)的功能和特點(diǎn)
工業(yè)計(jì)算機(jī)與普通計(jì)算機(jī)的區(qū)別
造成虛焊、假焊的原因有哪些?如何預(yù)防虛焊假焊






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論