 探析自然語言處理中的深度遷移學習
探析自然語言處理中的深度遷移學習
如何讓文本也像圖片一樣經過預訓練?這是一份通用句子編碼器的神秘指南。
簡介
遷移學習是一個令人興奮的概念,我們試圖利用先驗知識從一個領域和任務到另一個領域和任務。靈感來自我們人類本身,我們有一種與生俱來的能力,即不從零開始學習所有東西。我們從過去學到的知識中轉移和利用我們的知識來處理各種各樣的任務。有了計算機視覺,我們就有了優秀的大型數據集,比如ImageNet,在它之上我們可以獲得一套世界級的、最先進的預訓練模型來利用遷移學習。但是自然語言處理呢?考慮到文本數據是如此的多樣化、充斥著噪音以及非結構化的特點,這是一個嚴峻的挑戰。我們最近在文本嵌入方面取得了一些成功,包括Word2vec、GloVe 和 FastText 等方法,我在關于“文本數據的特征工程”[1]的文章中介紹了所有這些方法。
在這篇文章中,我們將展示幾種最先進的通用句子嵌入編碼器,特別是在遷移學習任務的少量數據上與 Word embedding 模型相比的情況下,它們往往會給出令人驚訝的良好性能。
我們將嘗試涵蓋基本概念,并展示一些利用python和TensorFlow的手工操作示例,在文本分類問題中側重于情感分析的案例。
為什么我們對嵌入(embedding)如此瘋狂?
嵌入是一個固定長度的向量,通常用于編碼和表示一個實體(文檔、句子、單詞、圖形)
我在前一篇文章[2]中談到了在文本數據和NLP上下文中嵌入的必要性。但為了方便起見,我將在這里簡短地重復一下。在語音或圖像識別系統方面,我們已經以豐富的密集特征向量的形式獲得信息,這些特征向量嵌入在高維數據集中,如音頻譜圖和圖像像素強度。然而,當涉及到原始文本數據時,特別是基于計數的模型,比如詞袋模型(Bag of words),我們處理的是單個單詞,它們可能有自己的標識符,并且不捕獲單詞之間的語義關系。這就導致了文本數據的大量稀疏詞向量,因此如果我們沒有足夠的數據,我們可能會因為維度詛咒而得到很糟糕的模型,甚至過擬合數據。
對比圖片、音頻、文本的特征表示
預測方法(predictive methods),比如基于神經網絡的語言模型,試圖從其相鄰的單詞中預測單詞,觀察語料庫中的單詞序列,在學習分布式表示的過程中,給我們提供稠密的單詞嵌入表示。
現在你可能在想,我們從文本中得到了一堆向量,現在怎么辦?如果我們有一個很好的文本數據的數字表示,它甚至捕捉到上下文和語義,我們可以將它用于各種各樣的下游現實世界任務,比如情感分析、文本分類、聚類、摘要、翻譯等等。事實上,機器學習或深度學習模型能在這些數字和嵌入表示上運行,是編碼這些模型使用的文本數據的關鍵。
文本嵌入
這里的一個大趨勢是找出所謂的“通用嵌入(universal embeddings)”,它基本上是通過在一個龐大的語料庫上訓練深度學習模型而獲得的預訓練的嵌入表示。這使我們能夠在各種各樣的任務中使用這些經過預訓練的(一般的)嵌入表示,包括缺乏足夠數據等約束的場景。這是遷移學習的一個完美例子,利用預訓練嵌入表示的先驗知識來解決一個全新的任務!下圖顯示了通用詞嵌入(word embedding)和句子嵌入(sentence embedding)的一些最新趨勢。
最近在通用詞&句子嵌入的趨勢
來源:https://medium.com/huggingface/universal-word-sentence-embeddings-ce48ddc8fc3a)
上圖中有一些有趣的趨勢,包括谷歌的通用句子編碼器,我們將在本文中詳細探討。現在,讓我們在深入研究通用句子編碼器之前,簡要介紹單詞和句子嵌入模型的趨勢和發展。
詞嵌入模型的發展趨勢
詞嵌入模型(Word Embedding Models)是一些比較成熟的模型,這些模型是從2013年的Word2vec開始發展的。基于語義和上下文相似性的連續向量空間嵌入詞向量的三種最常見的利用深度學習(無監督方法)的模型是:
Word2Vec
GloVe
FastText
這些模型是基于分布語義學領域中的分布假設原理而建立的,它告訴我們,在相同的語境中發生和使用的詞在語義上是相似的,具有相似的意義。
最近發展起來的這一領域的另一個有趣的模型是由Allen人工智能研究所(Allen Institute for Artificial Intelligence)開發的ELMo(Embeddings from Language Models)模型。
基本上,ELMo給我們提供了從深度雙向語言模型(biLM)中學習的單詞嵌入,該模型通常是在大型文本語料庫上進行預訓練,從而使遷移學習和這些嵌入能夠跨不同的NLP任務使用。Allen AI告訴我們,ELMo表示是上下文感知的、深度的和基于字符的,它使用形態學線索來形成表示,甚至對于OOV(out-of-vocabulary)標記也是如此。
通用句子嵌入模型的發展趨勢
句子嵌入(Sentence Embedding)的概念并不是一個非常新的概念,因為在構建詞嵌入時,最簡單的方法之一就是用平均法構建baseline句子嵌入模型。
一個baseline句子嵌入模型可以通過平均每個句子的單個詞嵌入(有點類似于我們失去了句子中固有的語境和單詞序列的bag of words)來建立。下圖顯示了實現此功能的方法。

當然,還有一些更復雜的方法,比如對句子中的詞嵌入表示進行線性加權組合。
Doc2Vec也是 mikolov 等人提出的一種非常流行的方法。他們提出了段落向量,這是一種無監督的算法,它從可變長度的文本 (如句子、段落和文檔) 中學習固定長度的特征嵌入。
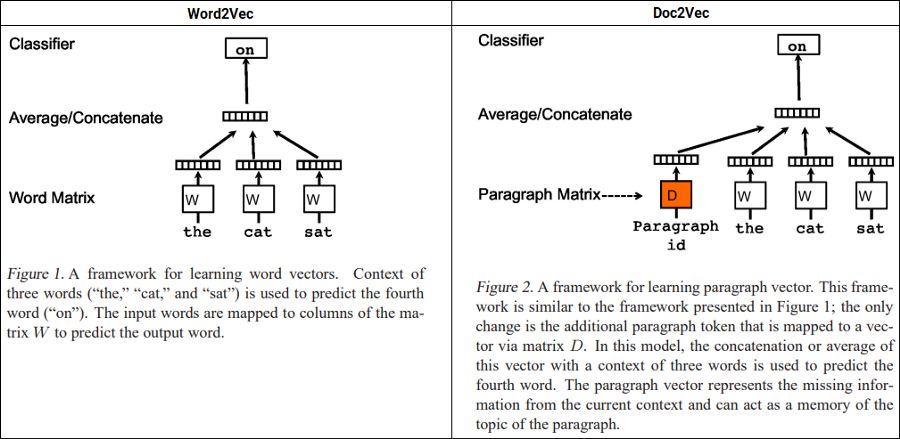
Word2Vec vs. Doc2Vec (Source:https://arxiv.org/abs/1405.4053)
在上述描述的基礎上,該模型用一個稠密向量表示每個文檔,該向量訓練用于預測文檔中的單詞,唯一的區別是使用段落或文檔id與常規單詞tokens一起構建嵌入表示。這樣的設計使這種模型克服了詞袋模型的缺點。
神經網絡語言模型(NNLM)是 Bengio 等人在2003年提出的。他們討論學習單詞的分布式表示,允許每個訓練句子向模型提供關于語義相鄰句子的信息。該模型同時學習每個單詞的分布式表示,同時學習詞序列的概率函數,并以這些形式表示出來。泛化是因為一個以前從未見過的單詞序列,如果它是由類似于構成一個已經出現過的句子的單詞構成的詞構成的,那么它就具有很高的概率。
Google已經建立了一個通用的句子嵌入模型nnlm-en-dim128[3],這是一種基于標記的文本嵌入,使用三層前饋神經網絡語言模型在英語google新聞200B語料庫上進行訓練。該模型將任意文本映射為128維嵌入。我們很快就會在接下來演示中用到這個。
Skip-Thought Vectors也是基于非監督學習的句子編碼器領域中最早的模型之一。在他們提議的論文中,利用文本的連續性,他們訓練了一個編碼器-解碼器模型,試圖重建編碼段落的周圍句子。共享語義和句法屬性的句子被映射到類似的向量表示。
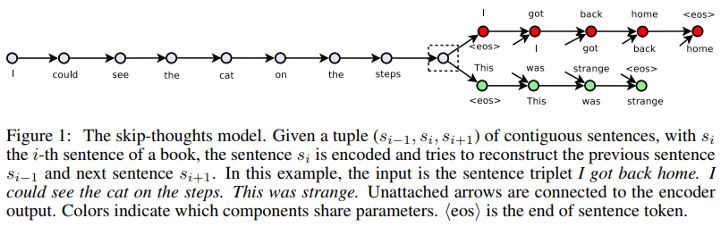
Skip-Thought Vectors (Source:https://arxiv.org/abs/1506.06726)
這就像skip-gram模型,但是是針對于句子而言的,即我們試圖預測給定源句子的周圍句子。
Quick Thought Vectors是最近用來學習句子表達的一種較新的方法。原論文中詳細介紹了學習句子表示的有效框架。有趣的是,他們通過在常規的編解碼結構中用分類器替換解碼器,把預測句子出現的上下文的問題重新定義為分類問題。
Quick Thought Vectors (Source:https://openreview.net/forum?id=rJvJXZb0W)
因此,給定一個句子及其出現的上下文,分類器根據它們的嵌入表示來區分上下文句子和其他對比句子。給定一個輸入語句,它首先使用某種函數進行編碼,但是模型沒有生成目標句子,而是從一組候選句子中選擇正確的目標句子。將生成看作是從所有可能的句子中選擇一個句子,這可以看作是對生成問題的一種判別近似。
InferSet是一種基于自然語言推理數據學習通用句子嵌入的有監督學習方法。這是硬核監督遷移學習,就像我們在ImageNet數據集上接受計算機視覺訓練一樣,他們使用斯坦福自然語言推理數據集的監督數據來訓練通用句子表示。該模型使用的數據集是由570 k人工生成的英語句子對組成的SNLI數據集,它捕捉到了理解句子語義的自然語言推理。
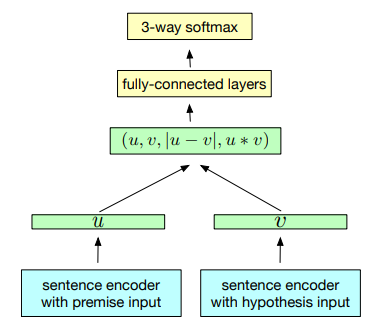
InferSent training scheme (Source:https://arxiv.org/abs/1705.02364)
基于上圖所描述的體系結構,我們可以看到,它使用了一個共享語句編碼器,它為前提u和假設V輸出一個表示。一旦生成句子向量,就可以使用3種匹配方法來提取u和v之間的關系:
Concatenation (u, v)
Element-wise product u ? v
Absolute element-wise difference |u ? v|
生成的向量隨后被輸入由多個全連接的層組成的三分類器。
Google的通用句子編碼器Universal Sentence Encoder是最新的、最好的通用句子嵌入模型之一,于2018年初發布。通用句子編碼器將任意文本編碼成512維嵌入,可用于各種NLP任務,包括文本分類、語義相似性和聚類。它針對各種數據源和各種任務進行訓練,目的是動態地容納各種各樣的自然語言理解任務,這些任務需要對單詞序列的含義進行建模,而不僅僅是單個單詞。他們的主要發現是,使用句子嵌入的遷移學習往往優于詞嵌入級別的遷移學習。
理解我們的文本分類問題
現在是時候把這些通用的句子編碼器付諸行動了,接下來我們進行演示。我們今天演示集中于一個非常流行的NLP任務,即在情感分析的背景下對文本進行分類。下文演示中所用的數據集可以在[4]或[5]中下載。
這個數據集共有50000部電影評論,其中25k有正面情緒,25k有負面情緒。我們將在總共30000次評論上訓練我們的模型,在5000個評論上進行交叉驗證,并使用15000次評論作為我們的測試數據集。主要目的是正確預測每一次評價的積極或消極情緒。
通用句子嵌入in action
現在我們已經明確了我們的主要目標,讓我們把通用的句子編碼器付諸行動!我的設置是一個8CPU,30 GB,250 GB的SSD和一個Nvidia Quadro P4000。
加載包
我們從安裝tensorflow-hub開始,它使我們能夠輕松地使用這些句子編碼器。

Ok,接下來加載本教程要用到的模塊:
importtensorflowastfimporttensorflow_hubashubimportnumpyasnpimportpandasaspd
下面的命令幫助你檢查TensorFlow是否將使用GPU(如果您已經設置了一個GPU):
In [12]: tf.test.is_gpu_available()Out[12]: TrueIn [13]: tf.test.gpu_device_name()Out[13]: '/device:GPU:0'
加載和查看數據集
我們現在可以加載數據集并使用pandas查看它。


我們將情感表示的列編碼為1和0。


我們的電影評論數據集
構建訓練、驗證和測試數據集
在開始建模之前,我們將創建訓練、驗證和測試數據集。我們將使用30000條評論用于訓練,5000條用于驗證,15000條用于測試。你可以使用train_test_split() from scikit-learn。我只是很懶,用簡單的列表切片對數據集進行了細分。

((30000,), (5000,), (15000,))
基本文本處理
我們有一些基本的文本預處理需要做,以從我們的文本消除一些噪音,如不必要的特殊字符,html標簽的清除等。

下面的代碼幫助我們構建一個簡單而有效的文本系統。
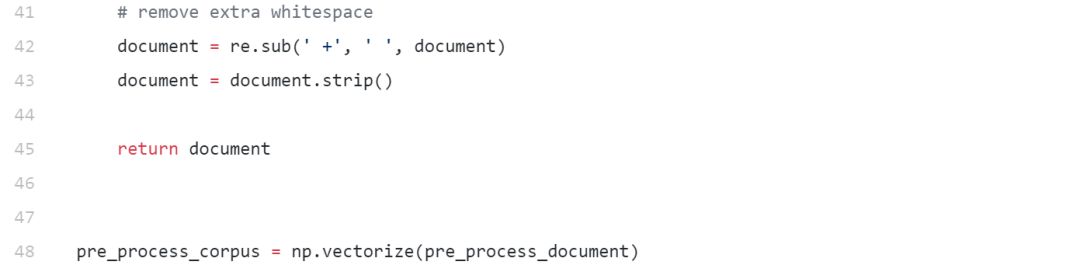
現在讓我們使用上面實現的函數對數據集進行預處理。

構建數據攝取函數
由于我們將使用tf.estimator API在TensorFlow中實現我們的模型,因此我們需要定義一些函數來構建數據和特性工程pipline,以便在訓練期間將數據輸入到我們的模型中。我們利用numpy_put_fn(),這有助于將大量的numpy數組輸入到模型中。

我們現在已經準備好建立我們的模型了!
用通用句子編碼器建立深度學習模型
在建立模型之前,首先要定義利用通用句子編碼器的語句嵌入特征。我們可以使用下面的代碼來實現這一點。

INFO:tensorflow:Using /tmp/tfhub_modules tocache modules.
我們將建立一個簡單只有兩個隱層的前饋DNN,現在只是一個標準的模型,沒有太復雜,因為我們想看看這些嵌入在一個簡單的模型上執行得有多好。在這里,我們正在利用預訓練嵌入形式的遷移學習方法。
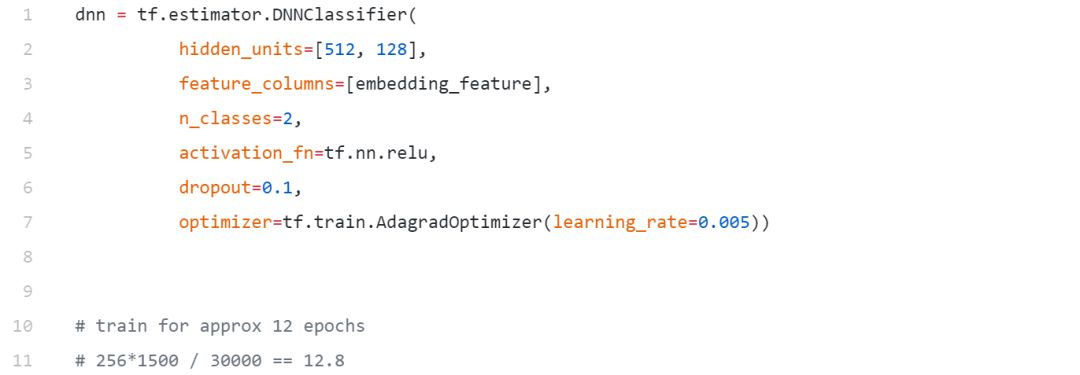
模型訓練
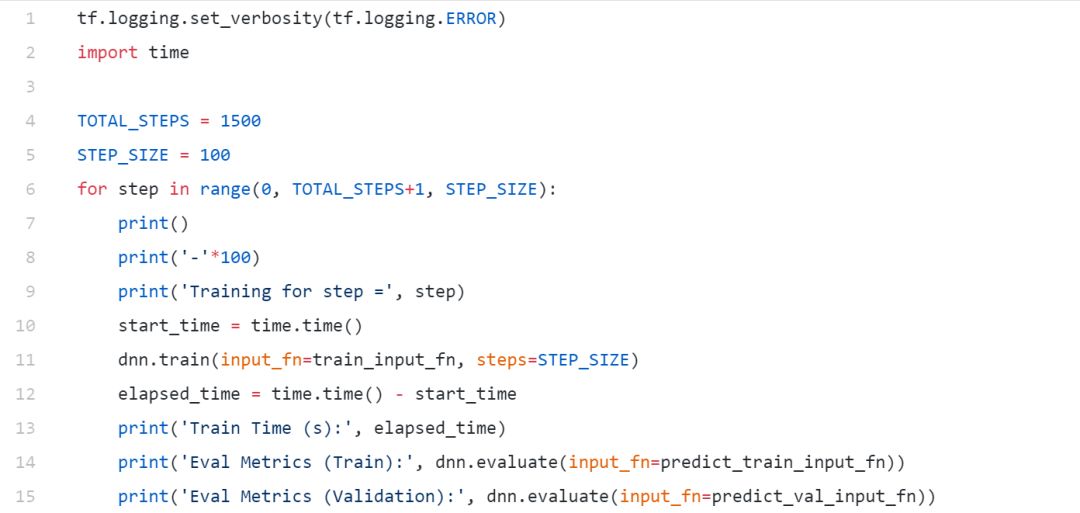




在我們的驗證數據集上,我們獲得了接近87%的總體精度,在這樣一個簡單的模型上,AUC達到了94%,這是相當好的!
模型評估
現在,讓我們評估我們的模型在訓練和測試數據集上的總體性能。
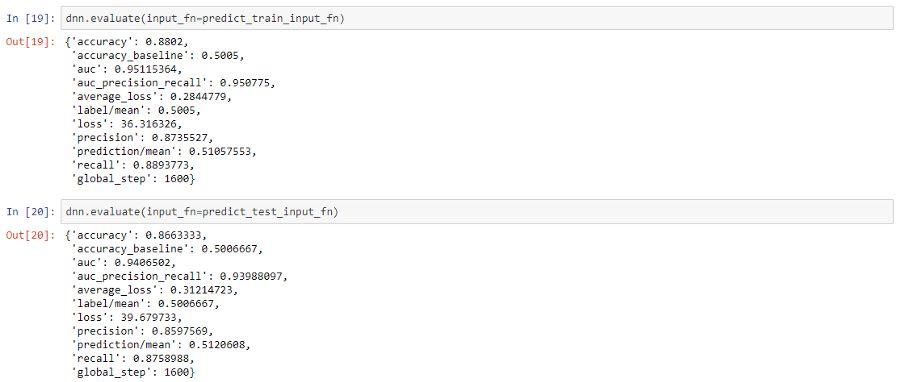
我們在測試數據上獲得了接近87%的總體準確率,與我們之前在驗證數據集上觀察到的結果一致。因此,這應該讓你了解利用經過預訓練的通用語句嵌入是多么容易,而不必擔心特征工程或復雜建模的麻煩。
獎勵:不同通用句子嵌入的遷移學習
現在讓我們嘗試根據不同的句子嵌入構建不同的深度學習分類器。我們將嘗試以下幾點:
NNLM-128
USE-512
我們還將在這里討論兩種最突出的遷移學習方法:
使用freezed預訓練語句嵌入建立模型
建立一個模型,在這個模型中,我們微調并更新訓練期間預先訓練過的句子嵌入



我們現在可以使用上述定義的方法來訓練我們的模型。

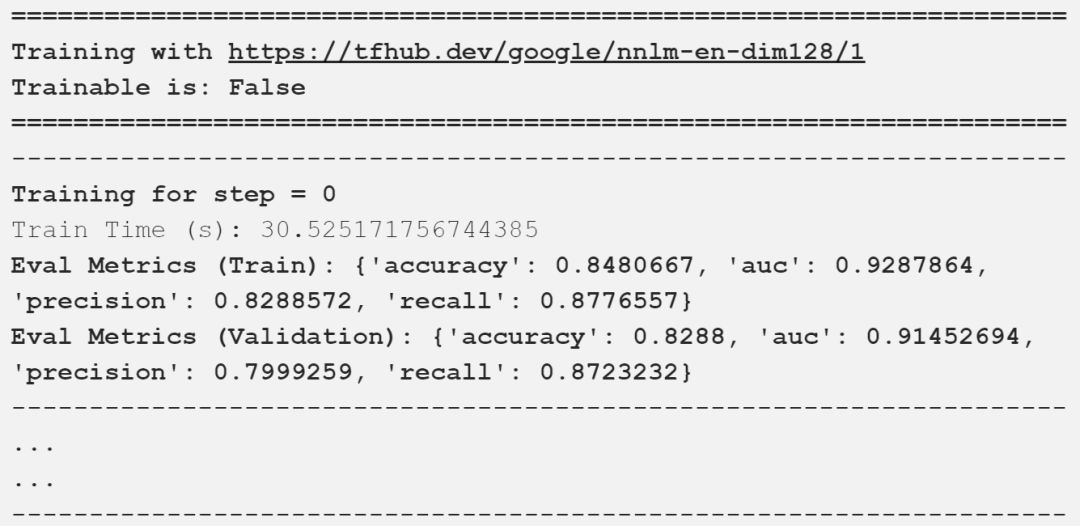
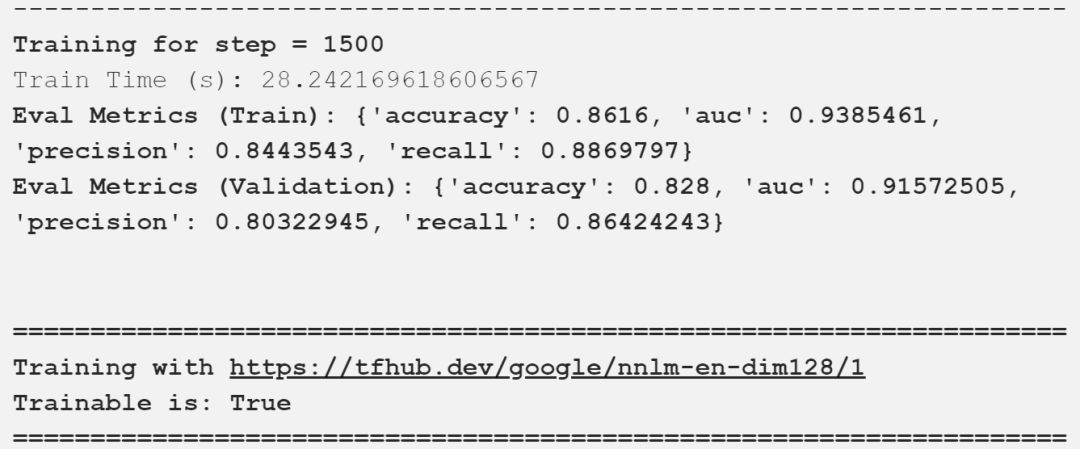
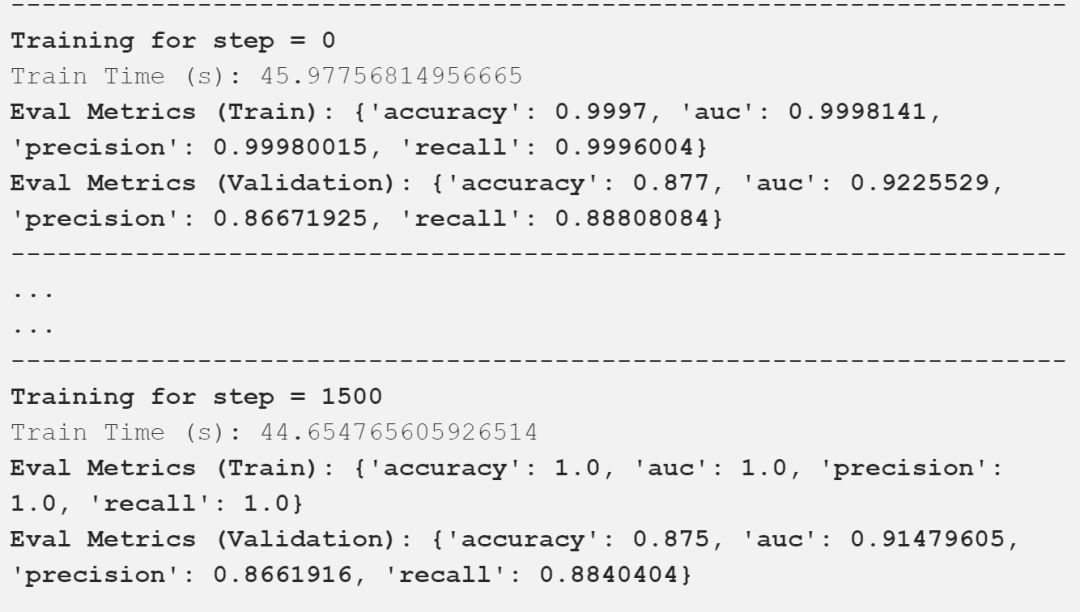
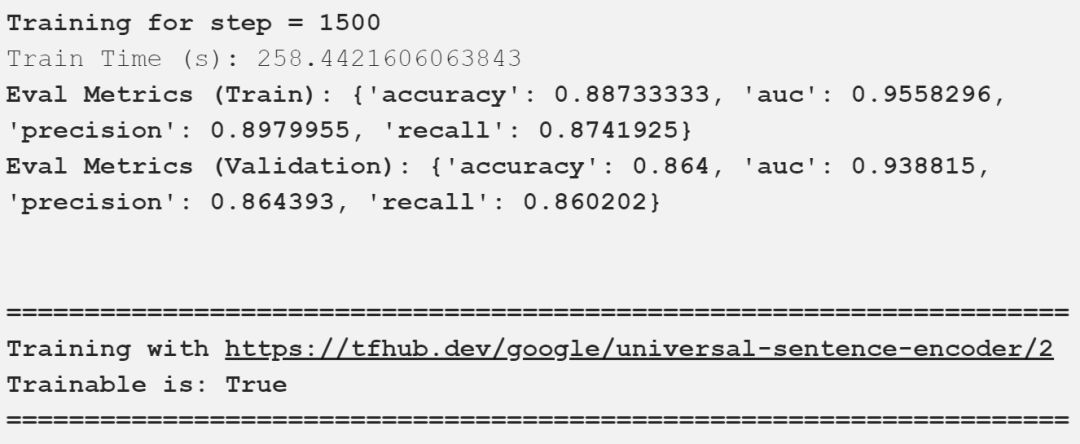
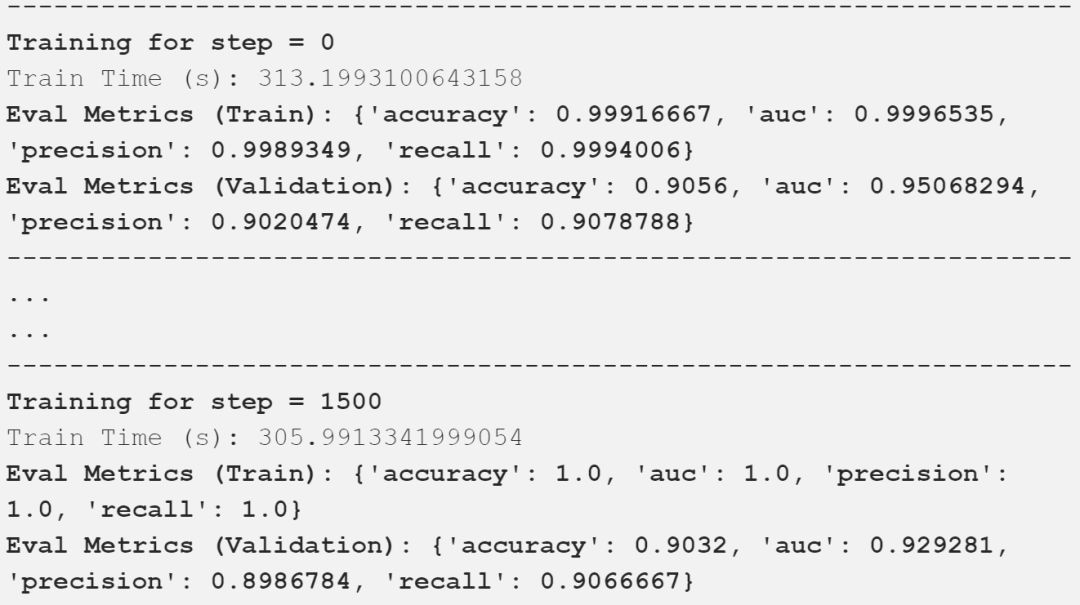
我在上面的輸出中描述了重要的評估指標,可以看到,我們的模型得到了一些好的結果。下表以一種很好的方式總結了這些比較結果。


對比不同的通用句子編碼器
看起來像谷歌的通用句子編碼器微調給我們的測試數據最好的結果。讓我們加載這個保存的模型并對測試數據進行評估。

[0, 1, 0, 1, 1, 0, 1, 1, 1, 1]
評估模型性能的最佳方法之一是以混淆矩陣的形式可視化模型預測。

從我們最好的模型預測中的混淆矩陣
我們也可以輸出其他重要的指標包括準確率,召回率和F1。

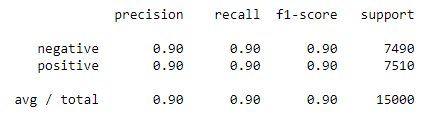
我們獲得了一個整體模型的準確性和F1-分數90%的測試數據,很好。
結論
對于不同的NLP任務,通用句子嵌入無疑是在支持遷移學習方面向前邁出的一大步。事實上,我們已經看到像ELMo這樣的模型,通用句子編碼器,ULMFiT確實成為頭條新聞,因為它展示了預先訓練過的模型可以用來在NLP任務上實現最先進的結果。著名的研究科學家和博客作者塞巴斯蒂安·魯德(SebastianRuder)在推特上提到了同樣的問題。

我對NLP的進一步推廣和使我們能夠輕松地解決復雜任務的未來感到非常興奮!
-
深度學習
+關注
關注
73文章
5512瀏覽量
121415 -
nlp
+關注
關注
1文章
489瀏覽量
22071
原文標題:自然語言處理中的深度遷移學習——文本預訓練
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
語義理解和研究資源是自然語言處理的兩大難題
什么是人工智能、機器學習、深度學習和自然語言處理?
從語言學到深度學習NLP,一文概述自然語言處理
面向自然語言處理的神經網絡遷移學習的答辯PPT
斯坦福AI Lab主任、NLP大師Manning:將深度學習應用于自然語言處理領域的領軍者
基于深度學習的自然語言處理對抗樣本模型





 工商網監
工商網監
評論