 NeurIPS2018開幕,上海交通大學Acemap團隊分析了NeurIPS2018的所有論文
NeurIPS2018開幕,上海交通大學Acemap團隊分析了NeurIPS2018的所有論文
NeurIPS2018今天開幕,上海交通大學Acemap團隊分析了NeurIPS2018的所有論文,發現前十名的幾乎全是美國機構,清華、中科院、北大是發表NeurIPS論文最多的中國機構,邢波、張潼、周明遠等排名前十。
NeurIPS2018來了!
神經信息處理系統大會(原名 Neural Information Processing Systems,NeurIPS)是人工智能和機器學習領域最重要的盛會,自 1987 年誕生起,這一學術會議已經走過了30余年的歷史。
在中國計算機學會的國際學術會議排名中,NeurIPS為人工智能領域的A類會議。今年的大會在加拿大城市蒙特利爾舉行,12月3日開幕。
上海交通大學Acemap團隊分析了NeurIPS2018的所有論文1010篇,對2018年、近三年、近五年學者、機構和國家分別以第一作者身份以及合作者身份在該會議中發表論文情況進行了統計,有一些比較重要的發現:
今年會議發表論文的前10名中幾乎都是美國機構,可見美國在該領域的絕對領先地位;
NeurIPS十年話題演變反映業界趨勢;
Eric Xing(邢波)在NeurIPS2018會議中發表論文數量排名第二;
清華、中科院、北大是發表NeurIPS論文最多的中國機構。
機構統計:谷歌、MIT、斯坦福連續領跑前三強
NIPS2018 Affiliation Statistics統計了2018年、近三年、近五年各機構在NeurIPS會議中發表論文數量排名,下圖展示了2018年排名前十的機構及論文發表數量(包含第一作者和非第一作者):
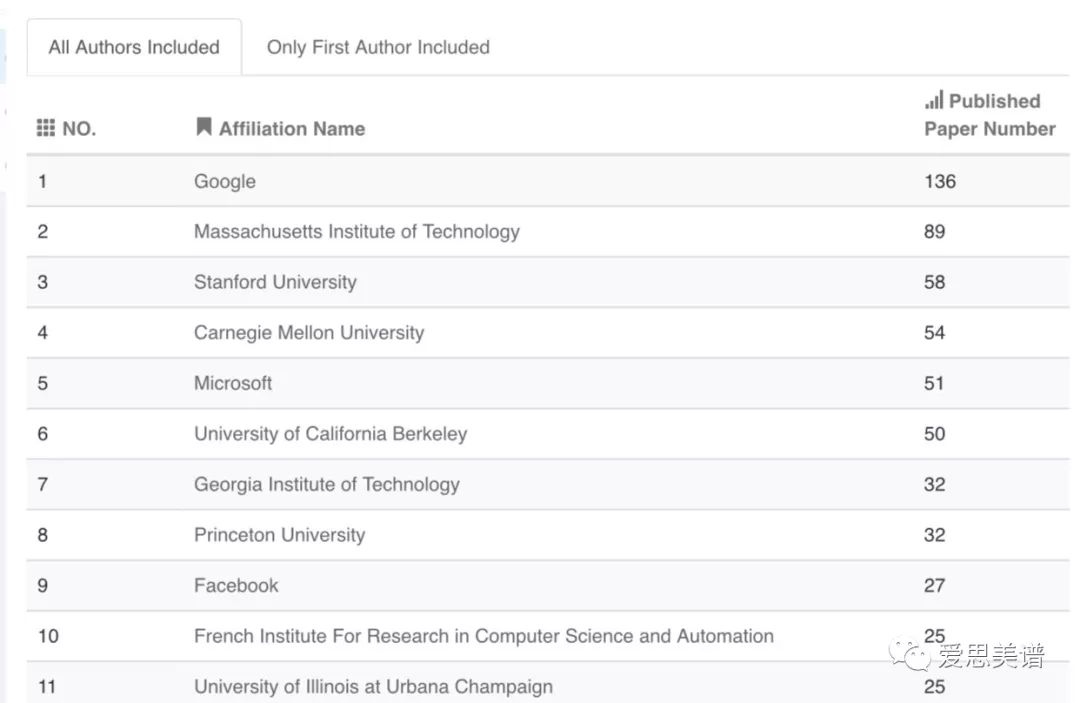
統計顯示,前10名中有Google、Microsoft和Facebook三所來自工業界的機構,尤其是第一名Google發表了136篇論文之多。而且,微軟作為第一作者發表的論文數量也有57篇之多(見Acemap官網)。可見Google在機器學習領域具有巨大的影響力。
同時,我們也看到前10名中幾乎都是美國機構,可見美國在該領域的絕對領先地位。
時間線拉長到三年,前三名依舊是谷歌、MIT和斯坦福:
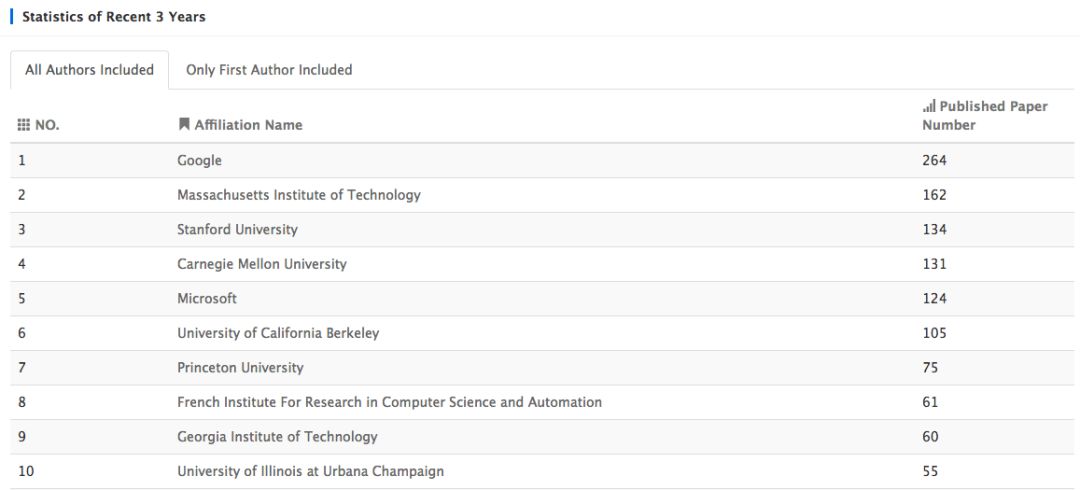
近五年內的前三名仍舊是這三位玩家,在此就不截圖了,欲了解2018年、近三年、近五年僅包含第一作者/所有作者包含在內的機構統計,請至Acemap官網:
https://acemap.info/ConferenceStatistics/AuthorAffiliationRank?conf_name=NIPS&conf_year=2018&type_of_ranking=Affiliation
對于谷歌,Acemap團隊也統計了該機構歷年在NeurIPS論文發表情況,如下圖所示:
其中,縱軸代表年份,橫軸代表該機構發表的論文數。紅色為第一作者身份發表的論文數。黑色位非第一作者身份發表的論文數。
同時,還統計了該機構內以第一作者身份/非第一作者身份發表的論文數最多的作者。
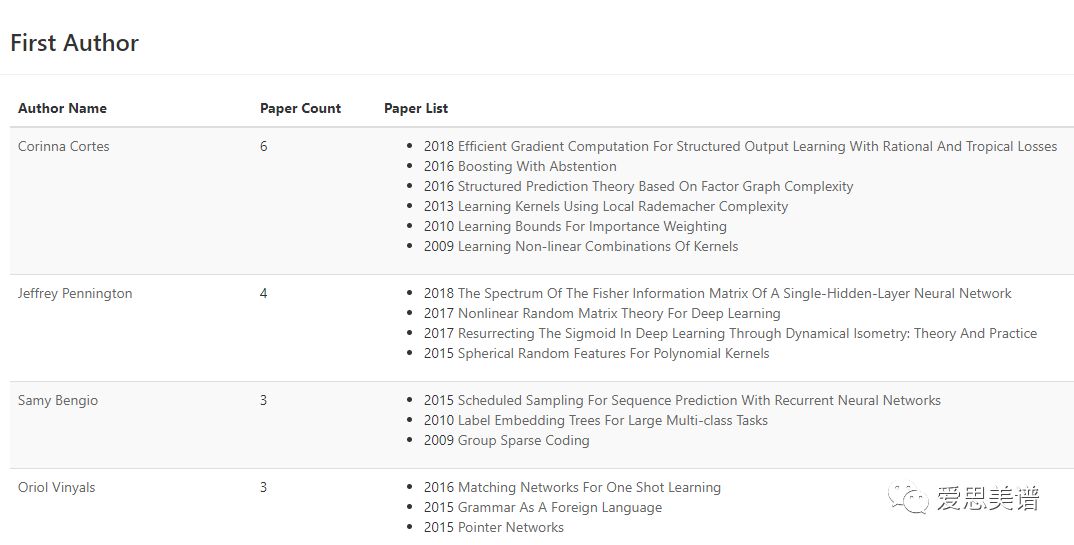
上圖可以看到,谷歌公司以第一作者身份發表論文數最多的幾個作者是:
Corinna Cortes
Jeffrey Pennington
Samy Bengio
Oriol Vinyals
作者統計:邢波、張潼、周明遠等進入前十
NeurIPS2018 Author Statistics統計了2018年、近三年、近五年各作者在NeurIPS會議中發表論文數量排名(包含所有作者/僅包含第一作者),下圖展示了2018年排名前十的作者及論文發表數量(包含所有作者):
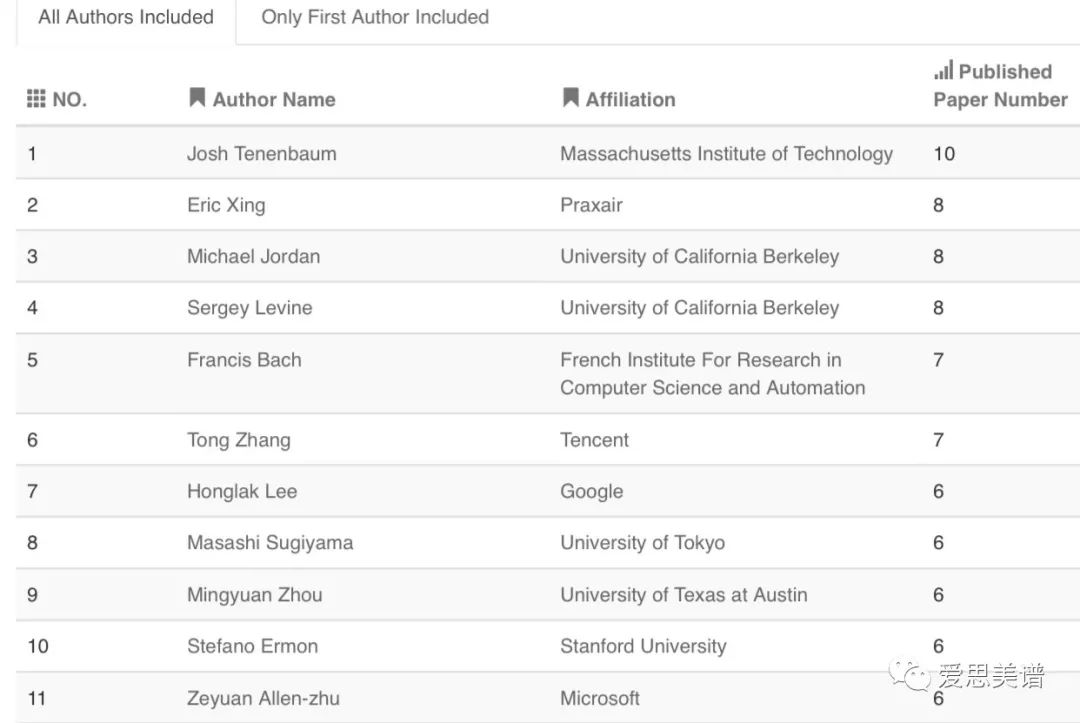
從上圖可以看到,前三名分別是Josh Tenenbaum、Eric Xing(邢波)、Michael Jordan。
前十名中,華人學者有Eric Xing(邢波)、Tong Zhang(張潼)、Honglak Lee、Mingyuan Zhou(周明遠)。
以上僅展示2018年排名前十的作者(包含所有作者),2018年、近三年、近五年詳細排名(包含所有作者/僅包含第一作者)請瀏覽網址:
https://acemap.info/ConferenceStatistics/AuthorAffiliationRank?conf_name=NIPS&conf_year=2018&type_of_ranking=Author
另外,NeurIPS十年的接受率、投稿量、中稿量也進行了統計,如下圖所示:
其中,綠色為投稿量,紫色為中稿量,曲線代表接受率。我們可以看到,2018年投稿量為4856,遠大于2017年的3240和2016年的2403。
詳細請查看:
https://acemap.info/ConferenceStatistics/acceptance_rate?conf_name=NIPS&conf_year=2018
我們提取了NeurIPS 2009-2018十年的摘要信息,利用word embedding算法將關鍵詞映射到向量空間,然后進行聚類。對每一個聚類賦予相應的話題,總體上分為圖中六大類。圖中橫軸代表年份,縱軸代表話題所占比例,從圖中可以看到六大話題十年間的演變趨勢。
我們從五個維度對每篇論文進行了相似論文推薦,形成論文推薦矩陣。這些維度包括最新、同會議、最相關、被引用數最多和導讀類論文,這種多維度推薦能夠滿足不同用戶的不同需求。AceMap針對NeurIPS 2018各篇論文的相似論文推薦頁面如下如所示:
詳細頁面可通過點擊閱讀原文訪問官方主頁,并點擊論文標題訪問。
國家分布統計:中國第二;清華、中科院、北大排前三
NeurIPS 2018 Affiliation Distribution統計了2018年發表NeurIPS論文的機構所在國家的分布情況,目前只統計了發表論文數量前十位的國家,以及每個國家所發表論文的數量和比例分布情況。
前十名的國家:美國、中國、法國、英國、加拿大、瑞士、德國、韓國、澳大利亞、日本。
中國出現的機構排名:
清華、中科院、北大、南京大學、華為、北京郵電大學、天津大學、西安電子科技大學、浙江大學。
作者關系圖
Acemap團隊分別對2018年在NeurIPS發過論文的作者、以及所有在NeurIPS發過論文的作者畫了關系圖。2018年在NeurIPS發過論文的作者如下所示(截圖部分)。其中,點的大小代表2018年在NeurIPS發的論文數多少。點之間的連線代表coauthor關系。
把圖片放大了,可以看到Josh Tenenbaum的關系圖:
此外,對NeurIPS 2018的每篇論文,Acemap團隊都提供簡短的內容解讀。解讀的方式是用機器閱讀理解的方法自動提取出關鍵信息,包括提出什么方法解決了什么問題等,相比于一長段論文,這種導讀能幫助讀者在短時間內獲取論文最關鍵的信息。
以下為解讀示例:
Acemap團隊對1010篇論文都做了解讀。詳細解讀請瀏覽網址:
https://acemap.info/ConferenceStatistics/MainPage?conf_name=NIPS&conf_year=2018#authorstatistics
最后,Acemap對NeuIPS近年H-Index、Top30論文的平均引用量、所有論文的平均引用量進行了統計。會議H-index變化如下:
會議所有論文和Top30論文的citation變化如下:
一些大廠的NeurIPS 2018論文
前文提到2018年排名前十的機構及論文發表數量,目前,已經有一些大廠放出了NeuraIPS上的論文,新智元做了簡單統計:
谷歌共計錄取文章136篇。
其中第一作者來自谷歌的文章,共計57篇;谷歌參與,但并非第一作者的文章數量共計79篇。
Efficient Gradient Computation For Structured Output Learning With Rational And Tropical Losses
具有Rational、Tropical損失的結構化輸出學習的有效梯度計算
Corinna Cortes,Vitaly Kuznetsov,Mehryar Mohri,Dmitry Storcheus,Scott Yang
The Spectrum Of The Fisher Information Matrix Of A Single-Hidden-Layer Neural Network
單隱層神經網絡Fisher信息矩陣的譜
Jeffrey Pennington,Pratik Worah
Tangent: Automatic Differentiation Using Source-code Transformation For Dynamically Typed Array Programming
Tangent:使用源代碼轉換進行動態類型數組編程的自動微分
Bart van Merri?nboer,Dan Moldovan,Alexander B Wiltschko
To Trust Or Not To Trust A Classifier
是否該信任一個分類器
Heinrich Jiang,Been Kim,Melody Y. Guan,Maya Gupta
Relational Recurrent Neural Networks
關系遞歸神經網絡
Adam Santoro,Ryan Faulkner,David Raposo,Jack Rae,Mike Chrzanowski,Théophane Weber,Daan Wierstra,Oriol Vinyals,Razvan Pascanu,Timothy Lillicrap
Adversarial Examples That Fool Both Computer Vision And Time-Limited Humans
愚弄計算機視覺以及人類的對抗性的例子
Gamaleldin F. Elsayed,Shreya Shankar,Brian Cheung,Nicolas Papernot,Alex Kurakin,Ian Goodfellow,Jascha Sohl-Dickstein
Large Margin Deep Networks For Classification
用于分類的Large Margin深度網絡
Gamaleldin F. Elsayed,Dilip Krishnan,Hossein Mobahi,Kevin Regan,Samy Bengio
Data-Efficient Hierarchical Reinforcement Learning
數據高效的分層強化學習
Ofir Nachum,Shixiang Gu,Honglak Lee,Sergey Levine
TopRank: A Practical Algorithm For Online Stochastic Ranking
TopRank:在線隨機排名的實用算法
Tor Lattimore,Branislav Kveton,Shuai Li,Csaba Szepesvari
Meta-Gradient Reinforcement Learning
元梯度強化學習
Zhongwen Xu,Hado van Hasselt,David Silver
Trading Robust Representations For Sample Complexity Through Self-supervised Visual Experience
通過自我監督的視覺體驗,用魯棒的表現形式換取樣本的復雜性
Andrea Tacchetti
Re-evaluating Evaluation
Re-evaluating評估
David Balduzzi,Karl Tuyls,Julien Perolat,Thore Graepel
A Lyapunov-based Approach To Safe Reinforcement Learning
基于Lyapunov的安全強化學習方法
Yinlam Chow,Ofir Nachum,Edgar Duenez-Guzman,Mohammad Ghavamzadeh
Assessing The Scalability Of Biologically-Motivated Deep Learning Algorithms And Architectures
評估生物激勵的深度學習算法和體系結構的可擴展性
Sergey Bartunov,Adam Santoro,Blake A. Richards,Luke Marris,Geoffrey E. Hinton,Timothy Lillicrap
Provable Variational Inference For Constrained Log-Submodular Models
約束Log-Submodular模型的可證變分推理
Josip Djolonga,Stefanie Jegelka,Andreas Krause
Playing Hard Exploration Games By Watching YouTube
通過觀看YouTube玩硬探索游戲
Yusuf Aytar,Tobias Pfaff,David Budden,Tom Le Paine,Ziyu Wang,Nando de Freitas
Transfer Learning From Speaker Verification To Multispeaker Text-To-Speech Synthesis
從說話人驗證遷移學習到多語言文本、語音合成
Ye Jia,Yu Zhang,Ron J. Weiss,Quan Wang,Jonathan Shen,Fei Ren,Zhifeng Chen,Patrick Nguyen,Ruoming Pang,Ignacio Lopez Moreno,Yonghui Wu
更多與谷歌相關錄取文章可點擊下方鏈接查看:
https://acemap.info/ConferenceStatistics/affiliationpage?affID=4CF99586&conf_name=NIPS&conf_year=2018
Facebook(未包含workshop):
A^2-Nets: Double Attention Networks
A^2-Nets: 雙重注意網絡
Yunpeng Chen,Yannis Kalantidis, Jianshu Li, Shuicheng Yan and Jiashi Feng
學習捕捉長期關系是圖像/視頻識別的基礎。現有的CNN模型一般依賴于增加深度來模擬這種關系,效率非常低。在這項工作中,我們提出“double attention block”,這是一個新的構建塊,能夠匯集并傳播來自輸入圖像/視頻的整個時空空間的全局信息特征,使后續的卷積層能夠有效地訪問來自整個空間的特征。
A Block Coordinate Ascent Algorithm for Mean-Variance Optimization
均值 - 方差優化的塊坐標上升算法
Tengyang Xie,Bo Liu, Yangyang Xu,Mohammad Ghavamzadeh, Yinlam Chow, Daoming Lyu and Daesub Yoon
均值-方差函數是風險管理中應用最廣泛的目標函數之一,具有簡單易行、易于解釋等優點。現有的均值-方差優化算法是基于多時間尺度隨機逼近的,其學習速率表往往難以優化,且只有漸近收斂證明。在這篇論文中,我們提出一種無模型均值方差優化策略搜索框架,基于有限樣本誤差約束分析。我們在幾個基準域上證明了它們的適用性。
A Lyapunov-based Approach to Safe Reinforcement Learning基于Lyapunov的安全強化學習方法
Yinlam Chow, Ofir Nachum, Edgar Duenez-Guzman andMohammad Ghavamzadeh
在許多現實世界的強化學習(RL)問題中,除了優化主要目標函數外,智能體還必須同時避免違反各種約束。特別是,除了優化性能外,在訓練和部署過程中,保證agent的“安全性”也是至關重要的。為了將安全性納入RL,我們在約束馬爾可夫決策過程(CMDPs)的框架下推導算法。結果表明,該方法在平衡約束滿意度和性能方面明顯優于現有基線。
The Description Length of Deep Learning Models深度學習模型的描述長度
Léonard Blier andYann Ollivier
Solomonoff的一般推理理論和最小描述長度原則是奧卡姆剃刀形式化的結果,并認為良好的數據模型必須是擅長無損壓縮數據的模型。考慮到要編碼的大量參數,深度神經網絡似乎違背了這一原則。我們通過實驗證明了深度神經網絡即使在考慮參數編碼時也能夠壓縮訓練數據。
Fast Approximate Natural Gradient Descent in a Kronecker Factored Eigenbasis
Kronecker Factored Eigenbasis的快速近似自然梯度下降
Thomas George, César Laurent, Xavier Bouthillier,Nicolas BallasandPascal Vincent
Fighting Boredom in Recommender Systems with Linear Reinforcement Learning在線性強化學習的推薦系統中對抗無聊
Romain Warlop,Alessandro Lazaricand Jérémie Mary
Forward Modeling for Partial Observation Strategy Games – A StarCraft Defogger部分觀察戰略游戲的正向建模 - 星際爭霸Defogger
Gabriel Synnaeve,Zeming Lin,Jonas Gehring, Dan Gant,Vegard Mella,Vasil Khalidov,Nicolas CarionandNicolas Usunier
GLoMo: Unsupervisedly Learned Relational tGraphs as Transferable RepresentationsGLoMo:非監督學習關系tGraphs作為可轉移的表示
Zhilin Yang,Jake Zhao, Bhuwan Dhingra,Kaiming He, William Cohen, Ruslan Salakhutdinov andYann LeCun
Near Optimal Exploration-Exploitation in Non-Communicating Markov Decision Processes非傳播馬爾可夫決策過程的近似最優探索-開發
Ronan Fruit,Matteo PirottaandAlessandro Lazaric
Non-Adversarial Mapping with VAEs使用VAE進行非對抗性映射
Yedid Hoshen
One-Shot Unsupervised Cross Domain TranslationOne-Shot無監督跨域翻譯
Sagie Benaim andLior Wolf
SING: Symbol-to-Instrument Neural GeneratorSING:從音符到樂器的神經生成器
Alexandre Defossez,Neil Zeghidour,Nicolas Usunier,Leon Bottouand Francis Bach
Temporal Regularization for Markov Decision Process
馬爾可夫決策過程的時間正則化
Pierre Thodoroff, Audrey Durand, Joelle Pineau and Doina Precup
一波三折的NeurIPS 2018
NeurIPS只是最近才被官方用到的名稱,通常被稱為NIPS,但就是這個四字縮寫讓今年的會議一波三折。
“NIPS”因為帶有性暗示,已經在今年引起了許多爭議,幾次公眾呼吁改名之后,NIPS 組委會在今年 4 月份宣布,他們正在考慮改名,并很快就此事向社區征詢意見。
不過大家的回應好壞參半。有人支持,有人反對,谷歌大腦研究員 David Ha(Twitter@hardmaru)個人統計結果,結果 50% 投票者認為保留原來的名字更好。
后來,NIPS官網默默地開始使用 NeurIPS 作為會議的縮寫,也增加了新的網址neurips.cc.,這才讓改名風波告一段落。
但是,改名事情剛消停,又被曝出有十幾名研究人員簽證被拒的情況。像NeurIPS這樣的頂級會議往往在歐美國家召開,但其實這對其他非發達國家的研究人員是不公平的,一旦出現外部因素影響(例如簽證),就會給這些非發達國家的研究人員帶來極大不便。
現在,已經有學者呼吁頂會要照顧非發達國家,Yoshua Bengio在最近的一次采訪時表示,另一個機器學習頂會ICLR,將在2020年移師非洲,做出了表率。
最后,對AI從業者來說,最重要是能參會。但是NeurIPS2018的門票比霉霉的演唱會門票還難搶,主辦方于 9 月 4 日 8 點開放注冊,但僅用了11分鐘38秒主會議門票就售罄,半小時后,tutorial和workshop的票也全部顯示Sold Out。
今年的NeurIPS2018,你是選擇看直播還是親臨現場?
-
微軟
+關注
關注
4文章
6627瀏覽量
104350 -
谷歌
+關注
關注
27文章
6192瀏覽量
105852 -
論文
+關注
關注
1文章
103瀏覽量
14973
原文標題:NeurIPS 2018開鑼,中國論文數全球第二!清華、中科院、北大排前三
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于移動自回歸的時序擴散預測模型
西南交通大學采購南京大展的DZ-STA200同步熱分析儀

上海交大團隊發表MEMS視觸覺融合多模態人機交互新進展

經典圖神經網絡(GNNs)的基準分析研究

螞蟻數科與浙大團隊榮獲NeurIPS競賽冠軍
上海交通大學:基于4D心臟波束成形的MIMO毫米波生物雷達生命體征監測系統

第三屆OpenHarmony技術大會在上海成功舉辦
賽昉科技與上海交通大學國家集成電路人才培養基地達成課程合作,推動高校RISC-V人才培育

福祿克公司助力北京交通大學畢業實習活動
阿爾泰科技與西安交通大學陜西省某技術重點實驗室共謀未來!

打造原生創新人才新高地 上海交通大學攜手華為成立鯤鵬昇騰科教創新卓越中心






 工商網監
工商網監
評論