 數據集,網絡架構和剪枝方法
數據集,網絡架構和剪枝方法
模型剪枝被認為是一種有效的模型壓縮方法。然而,剪枝方法真的有文獻中聲稱的那么有效嗎?最近UC Berkeley、清華大學的研究人員提交給ICLR 2019的論文《重新思考剪枝》質疑了六種剪枝方法,引起關注。
網絡剪枝(Network Pruning)是常用的模型壓縮方法之一,被廣泛用于降低深度模型的繁重計算量。
一個典型的剪枝算法通常有三個階段,即訓練(大型模型),剪枝和微調。在剪枝過程中,根據一定的標準,對冗余權重進行修剪并保留重要權重,以最大限度地保持精確性。
剪枝通常能大幅減少參數數量,壓縮空間,從而降低計算量。
然而,剪枝方法真的有它們聲稱的那么有效嗎?
最近一篇提交給ICLR 2019的論文似乎與最近所有network pruning相關的論文結果相矛盾,這篇論文質疑了幾個常用的模型剪枝方法的結果,包括韓松(Song Han)獲得ICLR2016最佳論文的“Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding”。
這篇論文迅速引起關注,有人認為它甚至可能改變我們在工業中訓練和部署模型的workflow。論文作者來自UC Berkeley和清華大學,他們在OpenReview上與被他們質疑的模型作者有一些有意思的反饋,感興趣的讀者可以去看看。地址:
https://openreview.net/forum?id=rJlnB3C5Ym
論文地址:
https://arxiv.org/pdf/1810.05270.pdf
在這篇論文里,作者發現了幾個與普遍觀念相矛盾的的觀察。他們檢查了6種最先進的剪枝算法,發現對剪枝后的模型進行fine-tuning,只比使用隨機初始化權重訓練的網絡的性能好一點點,甚至性能更差。
作者說:“對于采用預定義目標網絡架構的剪枝算法,可以擺脫整個pipeline并直接從頭開始訓練目標網絡。我們的觀察結果對于具有多種網絡架構,數據集和任務的各種剪枝算法是一致的。”
作者總結認為,這一發現有幾個意義:
1)訓練一個大型、over-parameterized的模型對于最終得到一個efficient的小模型不是必需的;
2)為了得到剪枝后的小模型,求取大模型的“important” weights不一定有用;
3)剪枝得到的結構本身,而不是一組“important” weights,是導致最終模型效果提升的原因。這表明一些剪枝算法可以被視為執行了“網絡結構搜索”(network architecture search)。
推翻網絡剪枝背后的兩個共同信念
過度參數化(over-parameterization)是深度神經網絡的一個普遍屬性,這會導致高計算成本和高內存占用。作為一種補救措施,網絡剪枝(network pruning)已被證實是一種有效的改進技術,可以在計算預算有限的情況下提高深度網絡的效率。
網絡剪枝的過程一般包括三個階段:1)訓練一個大型,過度參數化的模型,2)根據特定標準修剪訓練好的大模型,以及3)微調(fine-tune)剪枝后的模型以重新獲得丟失的性能。
網絡剪枝的三個階段
通常,這種剪枝程序背后有兩個共同的信念。
首先,人們認為從訓練一個大型的、過度參數化的網絡開始是很重要的,因為它提供了一個高性能的模型,從中可以安全地刪除一組冗余參數而不會顯著損害準確性。因此,這通常被認為是比直接從頭開始訓練較小的網絡更好的方法,也是一種常用的baseline方法。
其次,修剪后得到的結構及其相關權重被認為是獲得最終的有效模型所必需的。
因此,大多數現有的剪枝技術選擇fine-tune剪枝模型,而不是從頭開始訓練。剪枝后保留的權重通常被認為是關鍵的,因此如何準確地選擇重要權重集是一個非常活躍的研究課題。
在這項工作中,我們發現上面提到的兩種信念都不一定正確。
基于對具有多個網絡架構的多個數據集的最新剪枝算法的經驗評估,我們得出了兩個令人驚訝的觀察。
圖2:預定義和非預定義目標架構的區別
首先,對于具有預定義目標網絡架構的剪枝算法(圖2),從隨機初始化開始直接訓練小型目標模型可以實現與剪枝方法獲得的模型相同(甚至更好)的性能。在這種情況下,不需要從大型模型開始,而是可以直接從頭開始訓練目標模型。
其次,對于沒有預定義目標網絡的剪枝算法,從頭開始訓練剪枝模型也可以實現與fine-tune相當或甚至更好的性能。這一觀察表明,對于這些剪枝算法,重要的是獲得的模型架構,而不是保留的權重,盡管找到目標結構需要訓練大型模型。
我們的結果主張重新思考現有的網絡剪枝算法。似乎在第一階段的訓練期間的過度參數化并不像以前認為的那樣有益。此外,從大型模型繼承權重不一定是最優的,并且可能將修剪后的模型陷入糟糕的局部最小值,即使權重被剪枝標準視為“重要”。
相反,我們的結果表明,自動剪枝算法的價值在于識別有效的結構和執行隱式架構搜索(implicit architecture search),而不是選擇“important”權重。我們通過精心設計的實驗驗證了這一假設,并展示了剪枝模型中的模式可以為有效的模型架構提供設計指導。
從頭開始訓練小模型的方法
本節描述了從頭開始訓練小型目標模型的方法。
目標剪枝架構(Target Pruned Architectures)
我們首先將網絡剪枝方法分為兩類。在pruning pipeline中,目標剪枝模型的架構可以由人(即預定義的)或剪枝算法(即自動的)來確定(見圖2)。
數據集,網絡架構和剪枝方法
在network pruning 的相關文獻中,CIFAR-10,CIFAR-100和ImageNet數據集是事實上的基準,而VGG,ResNet和DenseNet是常見的網絡架構。
我們評估了三種預定義目標架構的剪枝方法:Li et al. (2017), Luo et al. (2017), He et al. (2017b),以及評估了三種自動發現目標模型的剪枝方法Liu et al. (2017), Huang & Wang (2018), Han et al. (2015)。
訓練預算
一個關鍵問題是,我們應該花多長時間從頭開始訓練這個剪枝后的小模型?用與訓練大型模型同樣的epoch數量來訓練可能是不公平的,因為小模型在一個epoch中需要的計算量要少得多。
在我們的實驗中,我們使用Scratch-E表示訓練相同epoch的小剪枝模型,用Scratch-B表示訓練相同數量的計算預算。
實現(Implementation)
為了使我們的設置盡可能接近原始論文,我們使用了以下協議:
1)如果以前的剪枝方法的訓練設置是公開的,如Liu et al.(2017)和Huang & Wang(2018),就采用原始實現;
2)對于更簡單的剪枝方法,如Li et al.(2017)和Han et al.(2015),我們重新實現了剪枝方法,得到了與原論文相似的結果;
3)其余兩種方法(Luo et al., 2017; He et al., 2017b),剪枝后的模型是公開的,但是沒有訓練設置,因此我們選擇從頭訓練目標模型。
結果和訓練模型的代碼可以在這里中找到:
https://github.com/Eric-mingjie/rethinking-networks-pruning
實驗與結果
在本節中,我們將展示實驗結果,這些實驗結果比較了從頭開始的訓練剪枝模型和基于繼承權重進行微調,以及預定義和自動發現的目標體系結構的方法。此外還包括從圖像分類到物體檢測的轉移學習實驗。
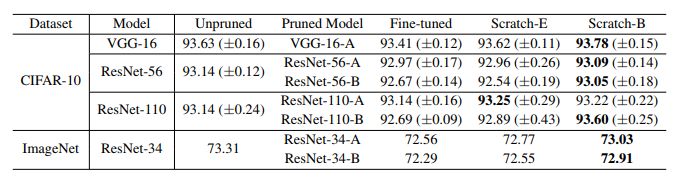
表1:基于L1范數的通道剪枝的結果(準確度)。“剪枝模型”是從大型模型中進行剪枝的模型。原模型和剪枝模型的配置均來自原始論文。
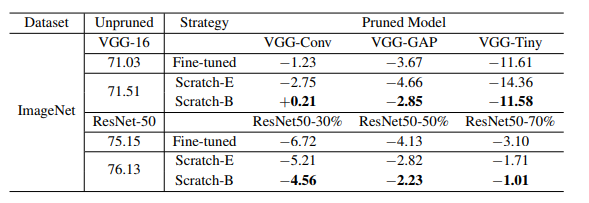
表2:ThiNet的結果(準確度)。“VGG-GAP”和“ResNet50-30%”等指ThiNet中配置的剪枝模型。為了適應本文的方法和原論文之間不同框架的影響,我們比較了相對于未剪枝的大型模型的相對精度下降。例如,對于剪枝后的模型VGG-Conv為-1.23,即表示相對左側的71.03的精度下降,后者為原始論文中未剪枝的大型VGG-16的報告精度
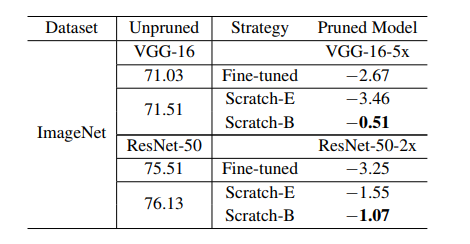
表3:基于回歸的特征重建結果(準確度)。與表2類似,我們比較了相對于未剪枝的大型模型的相對精度下降。
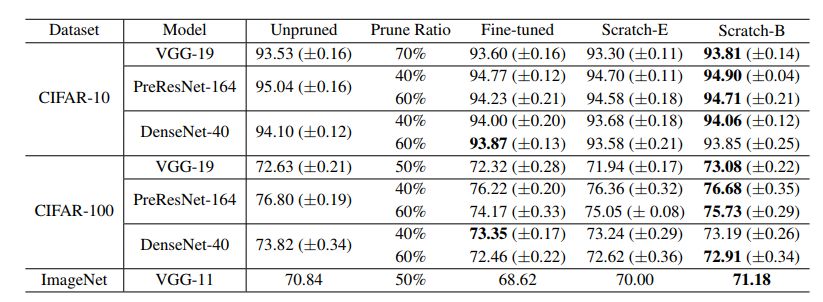
表4:網絡Slimming的結果(準確度)“剪枝比”表示在整個網絡中,剪枝通道所占的總百分比。每種模型使用與原論文的相同比率。

表5:使用稀疏結構選擇的殘余塊剪枝結果(準確度)。在原始論文中不需要微調,因此存在一個“剪枝”列,而不是“微調”列
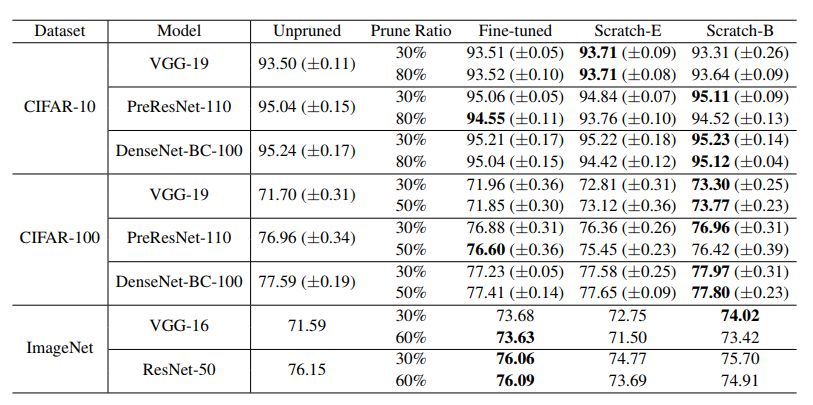
表6:非結構化剪枝的結果(準確度)“剪枝比”表示在所有卷積權重集中,進行剪枝的參數的比例。

表7:用于檢測任務的剪枝結果(mAP)。Prune-C指的是剪枝分類預訓練的權重,Prune-D指的是在權重轉移到檢測任務后剪枝。 Scratch-E / B表示從頭開始訓練分類剪枝模型,移至檢測任務。
總之,對于面向預定義目標架構的剪枝方法而言,使用與大型模型(Scratch-E)數量相同的迭代次數來訓練小模型,通常就足以實現與三步輸出的模型相同的精度。再加上目標架構是預定義的,在實際應用中,人們往往更愿意直接從頭開始訓練小模型。
此外,如果具備與大型模型相當的計算預算(算力)時,從頭訓練的模型的性能甚至可能微調模型更高。
討論與結論
我們建議,未來應采用相對高性能的基線方法來評估剪枝方法,尤其是在預定義目標的體系結構剪枝。除了高精度之外,從頭開始訓練預定義的目標模型與傳統的網絡剪枝相比具有以下優勢:
? 由于模型較小,可以使用更少的GPU資源來訓練模型,而且可能比訓練原始大型模型速度更快。
? 無需實施剪枝的標準和流程,這些流程有時需要逐層微調和/或需要針對不同的網絡架構進行定制。
? 可以避免調整剪枝過程中涉及的其他超參數。
我們的結果可利用剪枝方法來尋找高效的架構或稀疏模式,可以通過自動剪枝方法來完成。此外,在有些情況下,傳統的剪枝方法比從頭開始訓練要快得多,比如:
?已經提供預訓練的大型模型,且訓練預算很少。
? 需要獲得不同大小的多個模型,在這種情況下,可以訓練大型模型,然后以不同的比例剪枝。
總之,我們的實驗表明,從頭開始訓練小修剪模型幾乎總能達到與典型的“訓練-剪枝-微調”流程獲得的模型相當或更高的精度。這改變了我們對過度參數化的必要性的理解,進一步證明了自動剪枝算法的價值,可以用來尋找高效的架構,并為架構設計提供指導。
-
模型
+關注
關注
1文章
3298瀏覽量
49072 -
數據集
+關注
關注
4文章
1209瀏覽量
24793
原文標題:清華&伯克利ICLR論文:重新思考6大剪枝方法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于Vague集的網絡安全態勢評估方法

一種改進的神經網絡相關性剪枝算法
基于影響度剪枝的ELM分類算法
如何使用剪枝優化與索引求交改進Eclat算法
基于深度神經網絡的結構化剪枝算法
嵌入式設備的YOLO網絡剪枝算法
神經網絡模型剪枝后泛化能力的驗證方案
基于LZW編碼的卷積神經網絡壓縮方法綜述
DepGraph:任意架構的結構化剪枝,CNN、Transformer、GNN等都適用!
CVPR 2023:基于可恢復性度量的少樣本剪枝方法





 工商網監
工商網監
評論