 深入淺出地介紹了牛頓法、動量法、RMSProp、Adam優化算法
深入淺出地介紹了牛頓法、動量法、RMSProp、Adam優化算法
編者按:DRDO研究人員Ayoosh Kathuria深入淺出地介紹了牛頓法、動量法、RMSProp、Adam優化算法。
本系列的上一篇文章介紹了隨機梯度下降,以及如何應對陷入局部極小值或鞍點的問題。在這篇文章中,我們將查看另一個困擾神經網絡訓練的問題,病態曲率。
局部極小值和鞍點會使訓練停滯,而病態曲率則會減慢訓練速度,以至于機器學習從業者可能會覺得搜索收斂到了一個次優極小值。讓我們深入了解下什么是病態曲率。
病態曲率
考慮下面的損失曲面。
如你所見,我們從隨機點開始,漸漸進入藍色的溝壑區。(顏色表示損失函數在特定點的值是高是低,紅色表示高值,藍色表示低值。)
在到達最小值之前,我們需要首先穿過溝壑區,也就是病態曲率。讓我們放大一下這一區域,看看為什么稱病態?
紅線為梯度下降的路徑;藍線為理想路徑
如上圖所示,梯度下降在溝壑區的脊間反復振蕩,極其緩慢地向最小值處移動。這是因為w1方向要陡峭得多。
考慮下圖中A點的梯度,可以分解為w1、w2方向的兩個分量。w1方向的梯度要大很多,因此梯度的方向大為偏向w1,而不是w2(但w2才是能夠更快到達最小值處的梯度方向)。
通常情況下,我們使用低學習率來應對這樣的反復振蕩,但在病態曲率區域使用低學習率,可能要花很多時間才能達到最小值處。事實上,有論文報告,防止反復振蕩的足夠小的學習率,也許會導致從業者相信損失完全沒有改善,干脆放棄訓練。
大概,我們需要找到一種方法,首先緩慢地進入病態曲率的平坦底部,然后加速往最小值方向移動。二階導數可以幫助我們做到這一點。
牛頓法
梯度下降是一階優化方法。它只考慮損失函數的一階導數,不考慮高階函數。基本上這意味著它對損失函數的曲率一無所知。梯度下降可以告訴我們損失是否下降,下降得有多快,但無法區分曲線的的彎曲程度。
上圖三條曲線,紅點處的梯度都是一樣的,但曲率大不一樣。解決方案?考慮二階導數,或者說梯度改變得有多快。
使用二階導數解決這一問題的一個非常流行的技術是牛頓法(Newton's Method)。為了避免偏離本文的主題,我不會過多探究牛頓法的數學。相反,我將嘗試構建牛頓法的直覺。
牛頓法可以提供向梯度方向移動的理想步幅。由于我們現在具備了損失曲面的曲率信息,步幅可以據此確定,避免越過病態曲率的底部。
牛頓法通過計算Hessian矩陣做到這一點。Hessian矩陣是損失函數在所有權重組合上的二階導數的矩陣。

Hessian提供了損失曲面每一點上的曲率估計。正曲率意味著隨著我們的移動,損失曲面變得不那么陡峭了。負曲率則意味著,損失曲面變得越來越陡峭了。
注意,如果這一步的計算結果是負的,那就意味著我們可以切換回原本的算法。這對應于下面梯度變得越來越陡峭的情形。

然而,如果梯度變得越來越不陡峭,那么我們也許正向病態曲率的底部移動。這時牛頓算法提供了一個修正過的學習步幅,和曲率成反比。換句話說,如果損失曲面變得不那么陡峭,學習步幅就下降。
為何我們不常使用牛頓法?
你已經看到公式中的Hessian矩陣了。Hessian矩陣需要我們計算損失函數在所有權重組合上的梯度。也就是說,需要做的計算的數量級是神經網絡所有權重數量的平方。
現代神經網絡架構的參數量可能是數億,計算數億的平方的梯度在算力上不可行。
雖然高階優化方法在算力上不太可行,但二階優化關于納入梯度自身如何改變的想法是可以借鑒的。雖然我們無法準確計算這一信息,但我們可以基于之前梯度的信息使用啟發式算法引導優化過程。
動量
搭配SGD使用的一個非常流行的技術是動量(Momentum)。動量法不僅使用當前的梯度,同時還利用之前的梯度提供的信息。

上面的第一個等式就是動量,動量等式由兩部分組成,第一項是上一次迭代的動量,乘以“動量系數”。
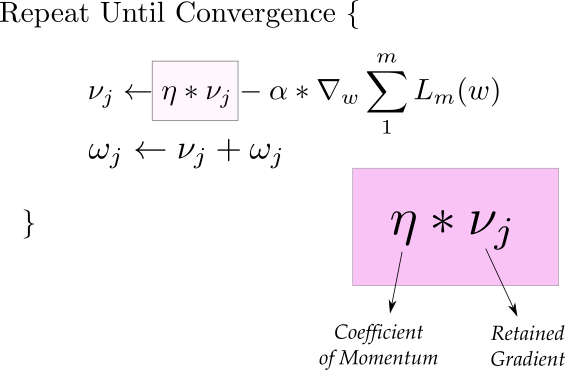
比如,假設我們將初始動量v設為0,系數定為0.9,那么后續的更新等式為:

我們看到,后續的更新保留了之前的梯度,但最近的梯度權重更高。(致喜歡數學的讀者,這是梯度的指數平均。)
下面我們來看看動量法如何幫助我們緩解病態曲率的問題。下圖中,大多數梯度更新發生在之字形方向上,我們將每次更新分解為w1和w2方向上的兩個分量。如果我們分別累加這些梯度的兩個分量,那么w1方向上的分量將互相抵消,而w2方向上的分量得到了加強。
也就是說,基于動量法的更新,積累了w2方向上的分量,清空了w1方向上的分量,從而幫助我們更快地通往最小值。從這個意義上說,動量法也有助于抑制振蕩。
動量法同時提供了加速度,從而加快收斂。但你可能想要搭配模擬退火,以免跳過最小值。
在實踐中,動量系數一般初始化為0.5,并在多個epoch后逐漸退火至0.9.
RMSProp
RMSProp,也就是均方根傳播的歷史很有趣。它是傳奇人物Geoffrey Hinton在Coursera授課時初次提出的。
RMSProp也試圖抑制振蕩,但采取的方法和動量不同。此外,RMSProp可以自動調整學習率。還有,RMSProp為每個參數選定不同的學習率。

在第一個等式中,類似之前的動量法,我們計算了梯度平方的指數平均。由于我們為每個參數單獨計算,這里的梯度gt表示正更新的參數上的梯度投影。
第二個等式根據指數平均決定步幅大小。我們選定一個初始學習率η,接著除以平均數。在我們上面舉的例子中,w1的梯度指數平均比w2大得多,所以w1的學習步幅比w2小得多。這就幫助我們避免了脊間振蕩,更快地向最小值移動。
第三個等式不過是權重更新步驟。
上面的等式中,超參數ρ一般定為0.9,但你可能需要加以調整。等式2中的ε是為了確保除數不為零,一般定為1e-10.
注意RMSProp隱式地應用了模擬退火。在向最小值移動的過程中,RMSProp會自動降低學習步幅,以免跳過最小值。
Adam
Adam,即Adaptive Moment Optimization算法結合了動量和RMSProp的啟發式算法。

這里,我們計算了梯度的指數平均和梯度平方的指數平均(等式1和等式2)。為了得出學習步幅,等式3在學習率上乘以梯度的平均(類似動量),除以梯度平方平均的均方根(類似RMSProp)。等式4是權重更新步驟。
超參數β1一般取0.9,β2一般取0.99. ε一般定為1e-10.
結語
本文介紹了三種應對病態曲率同時加速訓練過程的梯度下降方法。
在這三種方法之中,也許動量法用得更普遍,盡管從論文上看Adam更吸引人。經驗表明這三種算法都能收斂到給定損失曲面的不同的最優局部極小值。然而,動量法看起來要比Adam更容易找到比較平坦的最小值,而自適應方法(自動調整學習率)傾向于迅速地收斂于較尖的最小值。比較平坦的最小值概括性更好。
盡管這些方法有助于我們馴服深度網絡難以控制的損失平面,隨著網絡日益變深,它們開始變得不夠用了。除了選擇更好的優化方法,有相當多的研究試圖尋找能夠生成更平滑的損失曲面的架構。批量歸一化(Batch Normalization)和殘差連接(Residual Connections)正是這方面的兩個例子。我們會在后續的文章中詳細介紹它們。但這篇文章就到此為止了
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101059 -
函數
+關注
關注
3文章
4345瀏覽量
62891
原文標題:深度學習優化算法入門:二、動量、RMSProp、Adam
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺聊深入淺出RISC-V調試
數學建模(2)--TOPSIS法
節點電壓法和回路電流法的選取原則
回路電流法和節點電壓法適用范圍
回路電流法和支路電流法的實質是什么
深入淺出系列之代碼可讀性
開路電壓法和短路電流法的優缺點
節點電壓法的實質是什么
電源紋波平行線法與靠測法的區別
自然語言列舉法描述法各自的特點
基于法動EDA電磁大腦EMOptimizer?獨創快速產生模擬/射頻電路圖及其優化結果
網孔電流法和回路電流法怎么選擇比較好
深入淺出理解三極管






 工商網監
工商網監
評論