 使用tensorflow構建一個簡單神經網絡
使用tensorflow構建一個簡單神經網絡
給大家分享一個案例,如何使用tensorflow 構建一個簡單神經網絡。首先我們需要創建我們的樣本,由于是監督學習,所以還是需要label的。為了簡單起見,我們只創建一個樣本進行訓練, 可以當做是在模擬隨機梯度下降的過程
。 代碼如下:
x = tf.constant([[0.7,0.9]])
y_ = tf.constant([[1.0]])
我們使用tf中的常量來創建樣本和label。 這是一個有兩個特征的樣本。
然后定義每一層的權重和偏差變量
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1, seed=1))
b1 = tf.Variable(tf.zeros([3]))
b2 = tf.Variable(tf.zeros([1]))
根據上一節講的內容,我們使用tf的變量來生成權重和偏差。
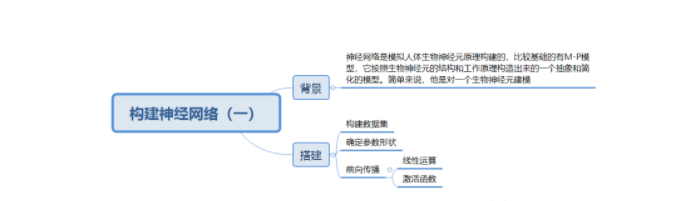
神經網絡模型
我們的神經網絡模型大概如下圖:
上面我們嘗試創建一個只有兩個特征的輸入層, 只有一層,3個神經元的隱藏層,以及最后的輸出層。 由于我們要做的是二分類,所以輸出層只有一個神經元。
前向傳播算法
好了現在我們可以來看看前向傳播了,如果對前向傳播還不太了解的話,請復習一下深度學習的基礎概念~ 這里只做簡單的介紹。 首先在輸入層我們有兩個特征輸入就是x1和x2,他們都會傳遞給隱藏層的3個神經元中進行訓練。
每一個神經元都是輸入層取值的加權和,就像圖出計算的一樣,分別計算出a11,a12和a13. 同樣的輸出層的計算是上一層的每一個神經元的取值的加權和,也正如上圖計算的一樣。這就是整個的前向傳播算法,上一層的計算結果是下一層的輸入,以此類推。對數學比較熟悉的同學一定猜到了,權重(w)的計算過程就是一個矩陣乘法。 首先是由x1和x2組成1*2的矩陣, 以及隱藏層的每一個神經元上對應的權重(w) 組合的2*3的矩陣(2個輸入特征的w,3個神經元),他們兩個做矩陣乘法就是這一層的前向傳播算法,結果是一個1*3的矩陣。再接著跟輸出層的3*1的矩陣(3個輸入特征的w和1個神經元)繼續做矩陣乘法。就是最后的結果。 很幸運的是tf為我們實現了做矩陣乘法的函數就是matmul。 那么上面這個前向傳播的過程就是如下的代碼:
a = tf.nn.relu(tf.matmul(x,w1) + b1)
y = tf.matmul(a, w2) + b2
我們在早期的帖子中說過神經網絡的每一層都有一個激活函數,我們分類問題的時候都會加入激活函數來增加非線性效果。那么上面可以看到我們使用tf.nn.relu這個tf為我們實現好的激活函數來給我們的隱藏層前向傳播算法增加非線性。 輸出層y沒有用到激活函數,我們之后會說明。
損失函數
我們需要一個損失函數來計算我們預測的結果與真實值的差距。 tf為我們實現了眾多的損失函數。由于這我們要做二分類問題,那么我們就需要sigmoid作為激活函數,所以我們也要使用tf為sigmoid實現的損失函數。
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=y_, name=None)
sigmoid_cross_entropy_with_logits的第一個參數是我們的預測值,第二個參數是真實的值,也就是我們的labels。 剛才我們計算前向傳播的時候再輸出層并沒有使用任何激活函數,是因為我們tf的損失函數中會給輸出層加入相應的激活函數。 也就是sigmoid_cross_entropy_with_logits已經給輸出層加入了sigmoid激活函數了。
反向傳播與梯度下降
為了實現梯度下降算法,我們需要進行反向傳播計算來求得每一個參數對應損失函數的導數。所幸的是tf同樣為我們提供了各種優化的反向傳播算法。 這里我們使用專門的梯度下降。如下:
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
GradientDescentOptimizer是梯度下降的優化算法,參數是學習率,這里我們設置為0.01。 同時優化目標是最小化損失函數。 所以是minimize函數,并且把損失函數作為參數傳遞過去。
開始訓練
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
for i in range(100):
sess.run(train_op)
print(sess.run(w1))
print(sess.run(w2))
之前的帖子說過tf是圖計算。 我們之前做的所有的操作都不會產生實際的計算效果。而是在tf中維護一個默認的圖, 當我們顯示的使用tf的session.run的時候才會去計算整個圖中的每一個幾點。 上面我們聲明一個Session,并在一開始初始化所有的變量, 循環100次代表訓練100輪迭代。 最后輸出訓練處的所有的w。
完整的代碼
import tensorflow as tf
import numpy as np
x = np.arange(4, dtype=np.float32).reshape(2,2) # 使用np來創造兩個樣本
y_ = np.array([0,1], dtype=np.float32).reshape(2,1) # 使用np來創造兩個label
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1, seed=1))
b1 = tf.Variable(tf.zeros([3]))
b2 = tf.Variable(tf.zeros([1]))
a = tf.nn.relu(tf.matmul(x,w1) + b1)
y = tf.matmul(a, w2) + b2
cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=y, labels=y_, name=None)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
for i in range(100):
sess.run(train_op)
print(sess.run(w1))
print(sess.run(w2))
以上就是使用tensorflow 構建一個簡單神經網絡的方法.
-
神經網絡
+關注
關注
42文章
4778瀏覽量
101014 -
tensorflow
+關注
關注
13文章
329瀏覽量
60583
發布評論請先 登錄
相關推薦
【案例分享】ART神經網絡與SOM神經網絡
【AI學習】第3篇--人工神經網絡
如何移植一個CNN神經網絡到FPGA中?
如何使用TensorFlow將神經網絡模型部署到移動或嵌入式設備上
一步一步學用Tensorflow構建卷積神經網絡
用TensorFlow寫個簡單的神經網絡






 工商網監
工商網監
評論