 利用人工智能定時方案簡化高性能計算加速
利用人工智能定時方案簡化高性能計算加速
云計算和人工智能(AI)將會是解決一些世界上最大的挑戰的關鍵,如加速科學發現、加快醫學研究、能源、醫療保健和其他行業創新步伐。數據科學家現在有能力利用人工智能和高性能計算(HPC)來分析海量數據,比以往更快地了解數據并解決問題。
隨著對HPC需求的增加,數據中心正在越來越多地針對高性能計算工作進行優化。這反過來又刺激了對低延遲,高吞吐量數據處理和網絡連接性進行優化的專用計算,網絡和存儲硬件的需求。這種市場趨勢同樣增加了對高性能定時解決方案的需求,以優化HPC工作負載加速器的運行。
服務器加速
硬件加速器用于加速數據中心應用中的HPC工作負載。雖然圖形處理單元(GPU)歷來被用于此目的,但現場可編程門陣列(FPGA)正日益成為另一種可行的選擇。兩種解決方案都能將并行處理、快速I / O和高速存儲器接口結合起來,以擴展處理性能,使服務器能夠高效地運行神經網絡,為搜索引擎、語音識別、自然語言翻譯和圖像處理提供動力。 GPU和FPGA正在向更高速度的25 Gbps I / O接口轉變,以便更輕松地擴展多個IC之間的協同處理。
如圖1所示,這些高速I / O接口需要低抖動定時參考,以最大限度地降低誤碼率并提高整體系統性能。低抖動晶振(XOs)和時鐘發生器非常適合GPU / FPGA I / O時鐘。 Silicon Labs的Si510 XO和Si5332時鐘發生器等高性能定時器件非常適合此應用,因為它們結合了低抖動參考定時,小尺寸和內置電源噪聲抑制功能,最大限度地降低了開關電源對高速I / O性能的電源噪聲的影響。
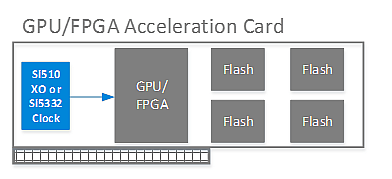
FPGA/GPU加速卡的參考定時
網絡接口卡
網絡接口卡(NIC)用于連接數據中心網絡內的服務器和存儲資源。隨著對帶寬需求的增加,數據中心正在從使用傳統10GbE / 40GbE光纖網絡轉向使用更高速度的25GbE / 50GbE / 100GbE網絡。這些網卡不僅需要協調大量數據的傳輸,還可以使用網卡將特定工作負載和應用程序從軟件移動到硬件中,幫助數據中心更高效地運行。網卡將數據從PCIe傳輸到以太網,并為網絡提供高速接口。諸如Silicon Labs的Si53204 PCIe緩沖器等定時器件可用于PCIe時鐘分配,Si510 XO可用于為以太網MAC / PHY提供低抖動參考時鐘。
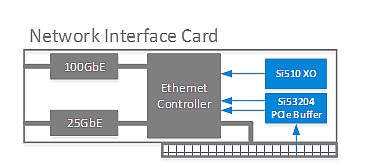
網絡接口卡的參考定時
存儲
在存儲應用中,業界正在迅速從使用基于低速SATA(6 Gbps)和SAS(12 Gbps)CPU /內存互連解決方案的硬盤驅動器轉向使用基于NVMExpress?接口規范的固態存儲設備。 NVM Express(NVMe)的一個主要優點是可以縮短延遲時間并提高內存訪問速度,使其成為閃存數據傳輸的理想解決方案。 NVMe的另一個好處是它使用流行的PCI Express(PCIe)串行接口將SSD與服務器/ CPU互連,后者已經支持用于高速串行數據傳輸的嵌入式PCIe接口。
如下圖所示,SSD控制器需要一個高性能PCIe時鐘發生器來提供參考定時。該時鐘必須支持展頻時鐘生成,以減少EMI并確保符合輻射標準。此外,選擇符合最新批準的PCIe Gen 4標準的面向未來的時鐘源,并保持與PCIe Gen 1/2/3兼容至關重要。 Si52204緩沖器是展頻時鐘發生器的一個例子,符合PCIe Gen 1/2/3/4規范,并具有顯著的余量。
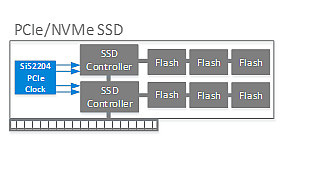
PCIe/NVMe SSD的定時
快速到達市場時間
數據中心硬件通常每兩到三年更新一次。 HPC加速器和基于NVMe的SSD的主要優勢在于,它們可以快速部署,以幫助數據中心運營商應對市場需求轉變以及更快地推出新應用程序和Web服務。另一個好處是可擴展性。附加卡使用PCIe連接器插入標準服務器主板,立即為現有服務器提供擴展功能。附加卡的設計時間可以短至六個月,使數據中心操作員能夠快速添加新功能并部署新的Web服務,而無需在數據中心內更換設備。
上市時間也是用于HPC加速器和基于NVMe的SSD的時鐘器件的關鍵考慮因素。硬件設計人員應該考慮可編程定時解決方案,這些解決方案可以單獨定制和優化以滿足其特定的性能,功耗和空間要求。
高性能計算加速的未來
在過去幾年中,定制硬件解決方案的重要性不斷增加,以解決HPC和工作負載處理問題。隨著新型GPU,FPGA和ASIC產品面市,這種趨勢預計會加速,這些產品支持更低的延遲,更高的IO速度,更高容量的存儲器接口以及更快的CPU,內存和加速器卡之間的數據傳輸。
最近,PCI-SIG工作組批準了PCIe Gen 4標準,該標準支持16 Gbps速率的CPU存儲器I / O加速器互連。符合第四代標準的解決方案目前正在開發中,預計將于2019年開始大規模部署。此外,PCI-SIG剛剛啟動了PCIe Gen 5的工作,這將支持32 Gbps速率的CPU內存I / O加速器互連。
不是靜止不動,已經定義了三個競爭標準來為PCIe提供備用解決方案。這些新的總線/互連標準之一是CCIX(用于加速器的高速緩存一致互連)。 CCIX利用PCIe物理層,但將數據速率擴展到25 Gbps。它還指定處理器和加速器之間的高速緩存一致性。另一個競爭標準是OpenCAPI(相干加速器處理器接口)。
該擴展總線標準基于IBM Power9 BlueLink 25 Gbps I / O進行互連,并支持Nvidia的NVLink 2.0協議,以實現處理器之間的連貫存儲器共享。第三個標準是Gen-Z,這是一種內存結構,使任何設備都能夠與其他設備進行通信,就好像它正在與自己的本地內存進行通信一樣,從而使應用程序能夠直接訪問任何類型的DRAM和NVM。
雖然很難預測哪些標準將在未來的CPU-內存-I / O互連中占上風,但一個趨勢是明確的。未來的加速器互連技術將越來越依賴于高性能定時解決方案來優化高速I / O性能。未來的定時解決方案必須具有出色的抖動性能,以最大限度地降低系統級誤碼率。與標準兼容性和與FPGA / GPU供應商的經過驗證的互操作性也將至關重要,從而可簡化多種標準和設備之間的互操作性。由于不斷增加的空間和功耗限制,未來的定時解決方案也必須高度集成,使單個組件能夠提供所有board-level的定時。
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605177 -
cpu
+關注
關注
68文章
10901瀏覽量
212666 -
云計算
+關注
關注
39文章
7855瀏覽量
137699 -
人工智能
+關注
關注
1794文章
47642瀏覽量
239626
原文標題:【技術干貨】創新的定時方案簡化高性能計算加速
文章出處:【微信號:SiliconLabs,微信公眾號:Silicon Labs】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Banana Pi 攜手 ArmSoM 推出人工智能加速 RK3576 CM5 計算模塊
嵌入式和人工智能究竟是什么關系?
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
Samtec AI 應用詳述 | 人工智能加速器所需的連接器

risc-v在人工智能圖像處理應用前景分析
人工智能ai4s試讀申請
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
利用人工智能改變 PCB 設計







 工商網監
工商網監
評論