") 了解遷移學習,哪種情況適合做遷移學習?
了解遷移學習,哪種情況適合做遷移學習?
▌一. 了解遷移學習
遷移學習(Transfer Learning)目標是將從一個環(huán)境中學到的知識用來幫助新環(huán)境中的學習任務。
> The ability of a system to recognize and apply knowledge and skills learned in previous tasks to novel tasks。
入門推薦一篇公認的比較好的 【Survey】:A Survey on Transfer Learning,Sinno JialinPan, Qiang Yang,IEEE Trans
http://www.cse.ust.hk/faculty/qyang/Docs/2009/tkde_transfer_learning.pdf
另外,戴文淵的碩士學位論文也可以看一下:基于實例和特征的遷移學習算法研究
https://download.csdn.net/download/linolzhang/9872535
Survey 作者歸納了 Transfer Learning 相關的知識域,有必要了解一下這些名詞:
● Learning學習 - learning to learn
●終身學習 - life-long learning
●知識轉移 -knowledge transfer
●歸納遷移 - inductive transfer
●多任務學習 -multi-task learning
●知識的鞏固 -knowledge consolidation
●上下文相關學習 -context sensitive learning
●基于知識的歸納偏差 -knowledge-based inductive bias
●元學習 -meta learning
●增量學習 -and incremental/cumulative learning
另外,進展及 Open Source Toolkit 可以參考:
http://www.cse.ust.hk/TL/index.html
▌二. 遷移學習分類
遷移學習(Transfer Learning)根據領域 和 任務的相似性,可以這樣劃分:
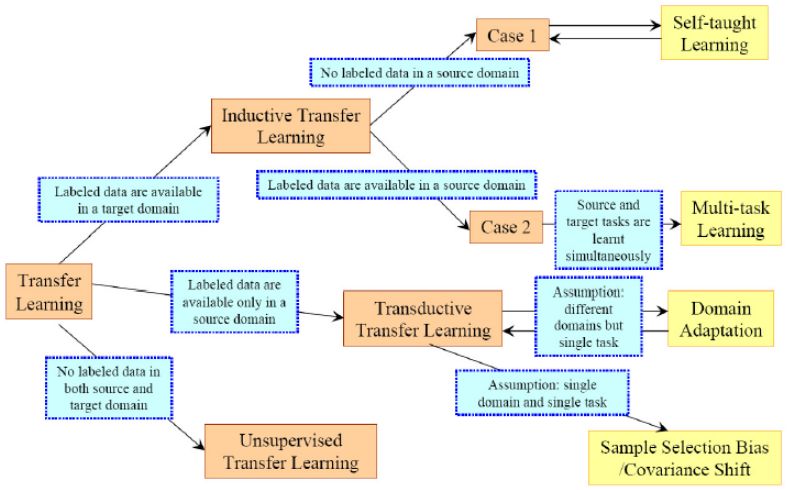
我們根據 源Domain和目前Domain 之間的關系,源Task 和 目標Task之間的關系,以及任務方法更詳細的整理為下表:
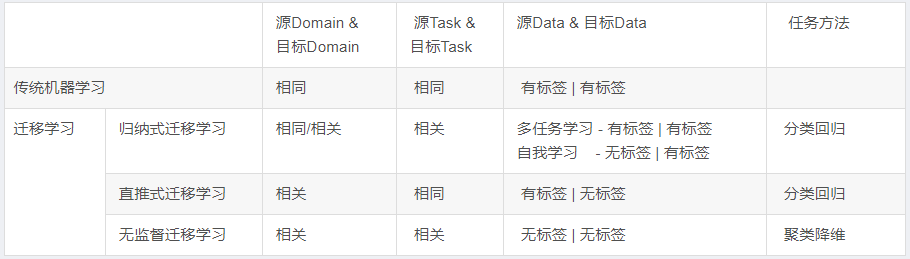
實際上,歸納式遷移學習 是應用最廣泛的一種方法,從這點上看,遷移學習更適合 有標簽的應用域。
根據技術方法,我們將遷移學習的方法劃分為:

遷移學習方法雖然在學術有很多研究工作,實際上在應用領域并不算成熟,這本身就是一個很大的命題,關于遷移學習的條件 和 本質也并未形成一套正統(tǒng)的體系來引領研究方向,更多的也是在實驗摸索。
遷移學習 目前面臨如下幾個問題:
1. 哪種情況適合做遷移學習? - What
這里先給個自己的理解:分類和回歸問題是比較適合做遷移學習的場景,有標簽的源數據是最好的輔助。
2. 該選擇哪種方法? - Which
簡單而行之有效的方法是首選,領域在快速發(fā)展,也不必拘泥算法本身,改善結果才是硬道理。
3. 如何避免負遷移? - How
遷移學習的目標是改善目標域的 Task效果,這里面負遷移(Negative Transfer)是很多研究者面臨的一個問題,如何得到行之有效的改進,避免負遷移是需要大家去評估和權衡的。
▌三. 經典算法 TrAdaBoost
TrAdaBoost 算法是基于 樣本遷移的 開山之作,由戴文淵提出,有著足夠的影響力放在第一位來進行講解。
論文下載:Boosting for Transfer Learning
http://home.cse.ust.hk/~qyang/Docs/2007/tradaboost.pdf
算法的基本思想是從源 Domain 數據中篩選有效數據,過濾掉與目標 Domain 不match的數據,通過 Boosting方法建立一種權重調整機制,增加有效數據權重,降低無效數據權重,下圖是 TrAdaBoost 算法的示意圖(截圖來自于 莊福振 -遷移學習研究進展):
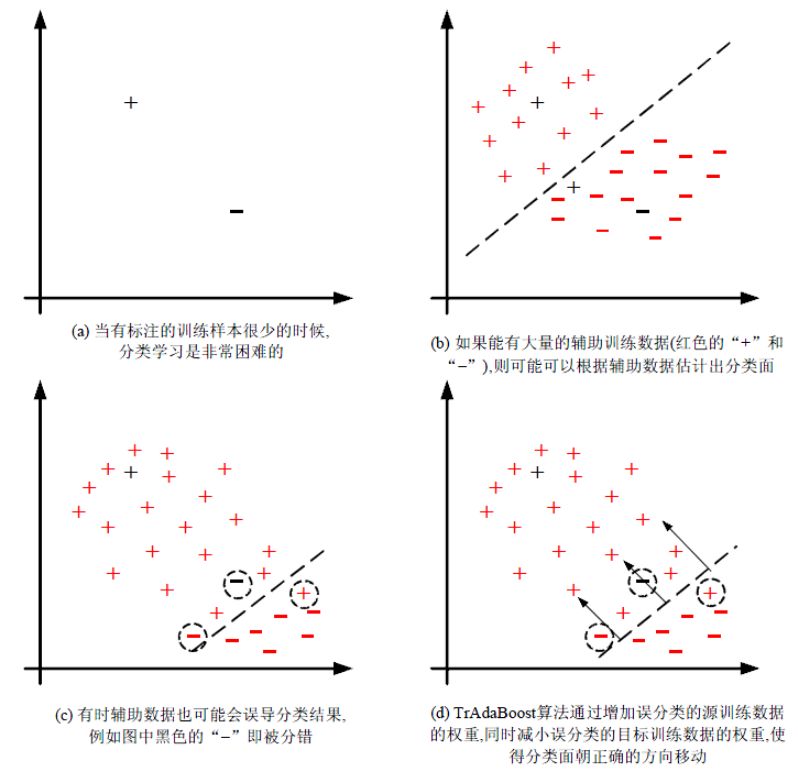
TrAdaBoost 算法比較簡單,用一句話概括就是 從過期數據里面 找出和目標數據最接近的樣本數據。
來看 TrAdaBoost 的算法步驟:

這里需要說明的一點就是 權重的更新方式,對于輔助樣本來講,預測值和標簽越接近,權重越大;而對于目標數據則是相反,預測值和標簽差異越大,權重越大。這種策略狠容易理解,我們想找到輔助樣本中 和 目標數據分布最接近的樣本,同時放大目標樣本Loss的影響,那么理想的結果就是:
目標樣本預測值與標簽盡量匹配(不放過一個沒匹配好的數據),輔助樣本在前面的基礎上篩選出最 match(權重大的) 的部分。
作者在后面給出了理論證明,這里有兩個公式(來證明算法收斂):
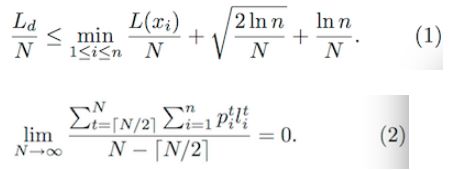
因篇幅問題,這里就不再展開了(和作者說的一樣),有興趣可以參考原Paper,看下實驗結果:
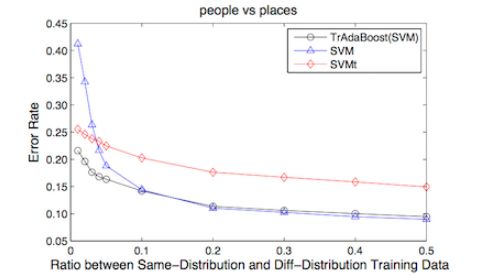
實驗發(fā)現,當 同分布數據(目標數據)占比當低于0.1時,算法效果明顯,當比例超過 0.1時,TrBoost 退化為 SVM 的效果。
這又是一個顯而易見的結論,我們認為大于0.1時,僅僅依靠 目前數據就足夠完成樣本訓練,這種情況下,輔助樣本的貢獻可以忽略。
另外,當 目標數據 和 輔助數據 差別比較大時,該方法是不 Work的,印證了最初的假設,這里不再展開證明。
最后,給出網友提供的C代碼:【下載地址】
https://download.csdn.net/download/linolzhang/9880438
▌四. 多任務學習
多任務學習(Multi-Task Learning, MTL)是一種同時學習多個任務的機器學習方法,該方法由來已久,和深度學習沒什么關系。
如果非要把它 和深度學習加上一個 link,我們可以這樣來表示:
input1->Hidden1->H1->Out1input1->Out1input2->Hidden2->H2->Out2==>input2->Hidden123->H123->Out2input3->Hidden3->H3->Out3input3->Out3
也比較好理解,相當于把多個 Task網絡進行合并,同時訓練多個任務,這種情況并不鮮見,比如以下2個方向:
1)目標檢測 - 復合多任務
目標檢測是 分類問題+回歸問題的組合,這是一個典型的 Multi-Task,比如:
Detection=Classification+Location
Mask RCNN =Classification+Location+Segmentation
檢測問題前面描述的比較多了,這里就不再貼圖了。
2)特征提取
多任務特征提取,多個輸出,這一類問題代表就是 數據結構化,特征識別。
下圖是香港中文大學湯曉鷗組發(fā)表的TCDCN(Facial Landmark Detection by Deep Multi-task Learning),很多講 Multi-Task的軟文都拿出來說,我們也借用一下。
在這里 Multi-Task 被同時用作 人臉關鍵點定位、姿態(tài)估計和屬性預測(比如性別、年齡、人種、微笑?戴眼鏡?)
多任務學習適用于這樣的情況:
1)多個任務之間存在關聯(lián),比如行人和車輛檢測,對于深度網絡也可以理解為有部分共同的網絡結構;
2)每個獨立任務的訓練數據比較少,單獨訓練無法有效收斂;
3)多個任務之間存在相關性信息,單獨訓練時無法有效挖掘;
可以看一下這篇 Tutorial:
www.public.asu.edu/~jye02/Software/MALSAR/MTL-SDM12.pdf
關于多任務學習的應用,比如分類任務下的二級分類、人臉識別等,大家可以更進一步了解。
-
數據
+關注
關注
8文章
7081瀏覽量
89190 -
算法
+關注
關注
23文章
4622瀏覽量
93057 -
遷移學習
+關注
關注
0文章
74瀏覽量
5570
原文標題:一文了解遷移學習經典算法
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
遷移學習的原理,基于Keras實現遷移學習

什么是遷移學習?遷移學習的實現方法與工具分析
使用哪種運放比較適合做衰減用,且不會失真很嚴重?
【木棉花】學習筆記--分布式遷移
基于局部分類精度的多源在線遷移學習算法
機器學習方法遷移學習的發(fā)展和研究資料說明

基于脈沖神經網絡的遷移學習算法
基于遷移深度學習的雷達信號分選識別
一文詳解遷移學習
視覺深度學習遷移學習訓練框架Torchvision介紹






 工商網監(jiān)
工商網監(jiān)
評論