

1 論文摘要
遷移學習需要將預訓練好的模型適應(yīng)新的下游任務(wù)。然而,作者觀察到,當前的遷移學習方法通常無法關(guān)注與任務(wù)相關(guān)的特征。在這項工作中,作者探索了重新聚焦模型注意力以進行遷移學習。作者提出了自上而下的注意力引導(TOAST),這是一種新的遷移學習算法,它可以凍結(jié)預先訓練的骨干模型,選擇與任務(wù)相關(guān)的特征輸出,并將這些特征反饋到模型中,以引導注意力關(guān)注特定任務(wù)的特征。僅通過重新聚焦注意力,TOAST在多個遷移學習基準測試中取得了最先進的結(jié)果,而只需調(diào)整很少的參數(shù)。與完全微調(diào)、LoRA和提示調(diào)優(yōu)相比,TOAST在各種細分類圖像上(例如FGVC上平均準確率81.1% → 86.2%)性能都大大提高。在語言生成方面,TOAST還優(yōu)于完全微調(diào)的Alpaca和Vicuna模型 。
2 模型簡介
首先使用ImageNet預訓練的ViT,并使用不同的遷移學習算法將其轉(zhuǎn)移到下游鳥類分類中。在這里,將這些模型的注意力圖可視化。每個注意力圖在ViT的最后一層中的不同頭部之間進行平均。(a) TOAST方法能夠?qū)㈩A先訓練的骨干的注意力重新集中在特定任務(wù)的特征上,從而大幅提高下游性能。(b) 先前的遷移學習方法,如微調(diào)、LoRA和VPT,未能專注于與任務(wù)相關(guān)的對象,從而實現(xiàn)了次優(yōu)性能。
在這項工作中,作者表明重新聚焦注意力是遷移學習的關(guān)鍵。作者提出了自上而下的注意力引導(TOAST),這是一種新的遷移學習方法,它通過將注意力重新聚焦到任務(wù)相關(guān)特征來學習新任務(wù)。這是通過自上而下的注意力模塊實現(xiàn)的,該模塊允許模型以適應(yīng)任務(wù)的方式調(diào)整其注意力。自上而下的注意力模塊獲取來自骨干網(wǎng)絡(luò)的輸出特征,選擇與任務(wù)相關(guān)的特征,然后將這些特征反饋到骨干網(wǎng)絡(luò)中的每個自注意力層。這些自上而下的信號將增強每層中的任務(wù)相關(guān)特征,并且?guī)в性鰪娞卣鞯那梆伖歉删W(wǎng)絡(luò)再次運行,實現(xiàn)對任務(wù)相關(guān)信號的更強注意力。在遷移到不同的下游任務(wù)時,TOAST簡單地凍結(jié)預訓練骨干網(wǎng)絡(luò),并調(diào)整自上而下的注意力模塊以將注意力引導到特定任務(wù)的信號。
值得注意的是,僅通過重新聚焦注意力,TOAST在各種遷移學習基準測試中取得了最先進的結(jié)果。與完全微調(diào)、LoRA和VPT相比,TOAST顯著提高了FGVC細分類上的性能(例如,在平均準確率上比完全微調(diào)提高了5%)。TOAST還優(yōu)于完全微調(diào)的Alpaca和Vicuna模型,用于指令遵循語言生成。這些觀察加強了作者的觀點,即重新聚焦注意力是遷移學習的關(guān)鍵,并為該領(lǐng)域的未來探索提供了啟發(fā)。
3 算法設(shè)計流程
論文提出了自上而下注意力引導(TOAST),這是一種新的遷移學習方法,它給預訓練模型添加一個自上而下的注意力模塊,并只在遷移到下游任務(wù)時調(diào)整自上而下的注意力。論文首先簡要介紹自上而下注意力(第3.1節(jié)),然后描述TOAST的詳細流程(第3.2節(jié))。注意,盡管TOAST適用于不同的模型體系結(jié)構(gòu),如transformer和Convnets,但在下面的討論中,論文假設(shè)是一個transformer骨干網(wǎng)絡(luò)。
3.1 自上而下注意力transformer的預備知識
transformer模型通常是自下而上的,即它的注意力僅取決于輸入,因此,它通常會突出輸入信號中的所有顯著特征。與自下而上注意力相反,自上而下注意力具有根據(jù)高層目標或任務(wù)調(diào)整注意力的能力,即它只關(guān)注與任務(wù)相關(guān)的特征,同時忽略其他特征。
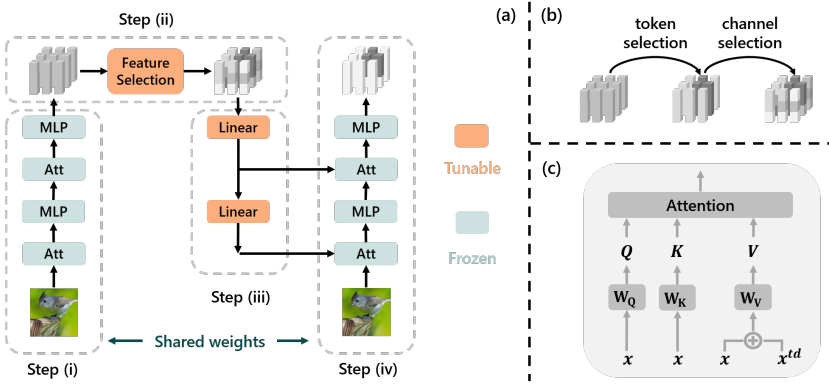
圖2
本設(shè)計遵循圖2(a)所示的自上而下注意力設(shè)計。具體來說,對于一個純前饋transformer,論文添加一個特征選擇模塊和一個反饋路徑用于自上而下注意力。網(wǎng)絡(luò)推理包含四個步驟:(i)輸入經(jīng)過前饋路徑獲得初始輸出,(ii)選擇輸出中的對當前工作有用的特征,(iii)選擇的特征通過反饋路徑發(fā)送回每個自注意力模塊,(iv)再次運行前饋傳遞,但每個自注意力都接收附加的自上而下輸入。通過這種方式,任務(wù)相關(guān)信息在每個層中被增強,實現(xiàn)自上而下注意力。
在網(wǎng)絡(luò)中,前饋路徑是一個常規(guī)transformer,其余部分如下所述:
特征選擇(步驟(ii))。從前饋骨干網(wǎng)絡(luò)的輸出中,該模塊選擇對當前任務(wù)有用的特征。這包括選擇與任務(wù)相關(guān)的標記和通道。圖2(b)說明了該過程。具體來說,表示前饋傳遞的第一個輸出為,其中是第i個輸出標記,特征選擇對每個標記運算,并輸出,其中和是特定于任務(wù)的參數(shù),sim(·,·)是限制在[0,1]之間的余弦相似度。這里,作為任務(wù)嵌入,編碼對任務(wù)重要的標記類型,每個標記由其與任務(wù)嵌入的相關(guān)性(用余弦相似度測量)重新加權(quán),模擬標記選擇。然后,通過的線性變換執(zhí)行每個標記的通道選擇。
反饋路徑(步驟(iii))。在特征選擇之后,輸出標記通過反饋路徑發(fā)送回網(wǎng)絡(luò)。反饋路徑包含與前饋路徑相同數(shù)量的層,每層是一個簡單的線性變換。每層的輸出經(jīng)過另一個線性變換,作為第二次前饋中的自上而下輸入發(fā)送到自注意力模塊。
帶自上而下輸入的自注意力(步驟(iv))。在第二次前饋傳遞中,每個自注意力模塊接收一個額外的自上而下輸入。如圖2(c)所示,論文簡單地將其添加到值矩陣中,同時保持查詢和鍵不變,即,其中是自注意力模塊的常規(guī)自下而上輸入,是自上而下輸入。然后是對的常規(guī)自注意力。
3.2 自上而下注意力引導
給定一個預訓練transformer,TOAST隨機初始化一個自上而下的注意力模塊,并遵循兩階段流程:(i)在通用公共數(shù)據(jù)集(例如視覺的ImageNet或語言的OpenWebText)上預調(diào)整自上而下的注意力以獲得更好的初始化,(ii)在下游任務(wù)上調(diào)整自上而下的注意力。在兩階段中,論文凍結(jié)預訓練骨干網(wǎng)絡(luò),僅調(diào)整自上而下的注意力模塊(圖2(a))。
預調(diào)整階段。由于自上而下的注意力模塊是隨機初始化的,因此直接在下游任務(wù)上調(diào)整可能會導致次優(yōu)性能。為此,論文提出先在通用公共數(shù)據(jù)集(如ImageNet或OpenWebText)上預調(diào)整自上而下的注意力以獲得更好的初始化。在預調(diào)整過程中,除了常規(guī)的有監(jiān)督或無監(jiān)督損失之外,論文還添加了的變分損失,它鼓勵反饋路徑從輸出重構(gòu)輸入,作為反饋權(quán)重的正則化。
調(diào)整階段。遷移到下游任務(wù)時,TOAST僅調(diào)整自上而下注意力模塊中的參數(shù)。在這種情況下,更新了大約15%的參數(shù)。論文注意到大多數(shù)可調(diào)參數(shù)來自反饋層,每個反饋層都包含一個矩陣,當特征維度d很高時,這個矩陣很大。為進一步提高參數(shù)效率,論文還提出了TOAST-Lite,它對反饋層應(yīng)用LoRA。通過這種方式,調(diào)整的參數(shù)不到1%。論文通過經(jīng)驗證明,盡管TOAST-Lite調(diào)整的參數(shù)比TOAST少得多,但在某些任務(wù)上的性能與TOAST相當,而在其他任務(wù)上略差。
4 TOAST中的注意力重新聚焦分析
從相似的角度,我們來解釋來為什么TOAST比其他基準模型性能優(yōu)越。如圖3所示,對于鳥類分類,TOAST明確關(guān)注前景鳥,而其他方法要么具有關(guān)注噪聲,要么完全忽略前景對象。在汽車分類中,TOAST傾向于集中在車頭燈和徽標上,這有助于區(qū)分不同品牌的汽車,而其他方法具有更少可解釋性并且容易被噪聲干擾。
5 效果展示
語言生成效果展示:


6 結(jié)論
這項工作的靈感來自于經(jīng)驗性觀察到以前的遷移學習方法通常無法關(guān)注與任務(wù)相關(guān)的信號,這可能導致下游任務(wù)的次優(yōu)性能。論文展示了重新聚焦注意力方法是實現(xiàn)更好遷移學習性能的關(guān)鍵。論文提出了自上而下的注意力引導(TOAST),它通過將注意力引導到特定任務(wù)的特征來遷移到新任務(wù)。具體來說,TOAST凍結(jié)預訓練骨干網(wǎng)絡(luò),并在下游任務(wù)上調(diào)整附加的自上而下注意力模塊以引導注意力。與以前的基線相比,TOAST能夠在細分類視覺分類以及指令遵循語言生成上實現(xiàn)最先進的結(jié)果,同時僅調(diào)整很小一部分參數(shù)。
前言
最近閱讀了一篇名為《TOAST:Transfer Learning via Attention Steering》的論文,論文中,作者使用了一個遷移學習模型,既可以實現(xiàn)圖像分類算法的遷移,又可以實現(xiàn)文本生成算法的遷移,令人振奮的是:這兩種遷移都展示了驚艷的效果。
1.遷移學習的概念
遷移學習是指在一個領(lǐng)域(源領(lǐng)域)學習到的知識,用來幫助另一個領(lǐng)域(目標領(lǐng)域)的學習,從而減少目標領(lǐng)域所需的數(shù)據(jù)量和訓練時間。
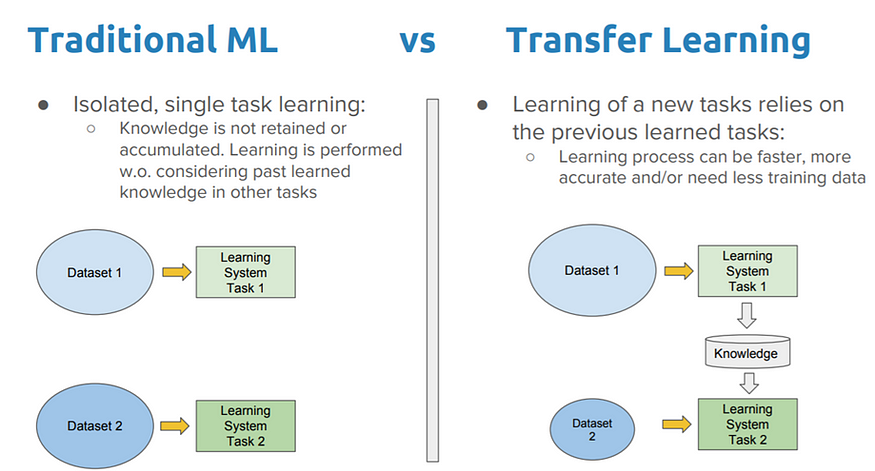
傳統(tǒng)的機器學習方法往往需要大量的數(shù)據(jù)和時間來從零開始學習,這樣既不高效也不靈活。相反,遷移學習可以借鑒已經(jīng)存在的模型的能力,利用已有的相關(guān)知識,加速和優(yōu)化新問題的解決。傳統(tǒng)機器學習方法和遷移學習方法對比如下圖所示。
 img
img
(圖片來源:A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning,Dipanjan (DJ) Sarkar)
2.遷移學習的分類
(1)根據(jù)源領(lǐng)域和目標領(lǐng)域之間的關(guān)系,分為同構(gòu)遷移學習和異構(gòu)遷移學習。
同構(gòu)遷移學習是指源領(lǐng)域和目標領(lǐng)域具有相同的特征空間和標簽空間,只是數(shù)據(jù)分布不同。也就是說,它們的數(shù)據(jù)具有相同的屬性和類別,只是數(shù)據(jù)分布不同。例如,從一個圖像分類任務(wù)遷移到另一個圖像分類任務(wù),如果它們都使用相同的像素值作為特征,且都有相同的類別標簽,那么就是同構(gòu)遷移學習。同構(gòu)遷移學習的主要挑戰(zhàn)是如何處理源領(lǐng)域和目標領(lǐng)域之間的概率分布差異,即如何處理數(shù)據(jù)之間分布的差異。
異構(gòu)遷移學習是指源領(lǐng)域和目標領(lǐng)域具有不同的特征空間或標簽空間,或者兩者都不同。也就是說,它們的數(shù)據(jù)具有不同的屬性或類別。例如,從一個文本分類任務(wù)遷移到一個圖像分類任務(wù),如果它們使用不同的特征表示方法,如詞向量和像素值,且有不同的類別標簽,那么就是異構(gòu)遷移學習。異構(gòu)遷移學習的主要挑戰(zhàn)是如何建立源領(lǐng)域和目標領(lǐng)域之間的特征映射或標簽對應(yīng)關(guān)系,即處理不同數(shù)據(jù)之間的語義的差異。
(2)根據(jù)所要遷移的知識類型,分為基于實例的遷移學習、基于特征的遷移學習、基于模型的遷移學習、基于關(guān)系的遷移學習和基于對抗的遷移學習。
基于實例的遷移學習是指利用特定的權(quán)重調(diào)整策略,從源領(lǐng)域中選擇部分實例作為目標領(lǐng)域訓練集的補充的方法。這種方法的假設(shè)是源領(lǐng)域和目標領(lǐng)域中存在一部分相似或相關(guān)的實例,在這部分實例上,源領(lǐng)域和目標領(lǐng)域的數(shù)據(jù)分布是一致或接近的。這種方法通常適用于獨立同分布的數(shù)據(jù),即每個數(shù)據(jù)點都是獨立生成的。這種方法的優(yōu)點是方法簡單,容易實現(xiàn);缺點是權(quán)重選擇與相似度的度量過于依賴經(jīng)驗,且源域與目標域的數(shù)據(jù)分布往往不同。因此對差異稍大的數(shù)據(jù)集泛化能力較差。
基于特征的遷移學習是指尋找或構(gòu)造一個共享的特征空間,使得源領(lǐng)域和目標領(lǐng)域在該空間中具有相似的數(shù)據(jù)分布,從而減少數(shù)據(jù)分布不匹配帶來的負面影響的方法。這種方法的假設(shè)是源領(lǐng)域和目標領(lǐng)域存在一部分公共的特征,在這部分公共特征上,源領(lǐng)域和目標領(lǐng)域的數(shù)據(jù)分布是一致或相近的。這種方法通常適用于領(lǐng)域適應(yīng),也就是源領(lǐng)域和目標領(lǐng)域具有相同的標簽空間,但是不同的特征空間或特征分布。例如,在文本分類中,可以利用詞嵌入或主題模型等方法,將不同語言或不同風格的文本映射到一個共享的語義空間中,從而進行跨語言或跨風格的文本分類。這種方法的優(yōu)點是對大多數(shù)方法適用,效果好;缺點是難以求解,容易發(fā)生過擬合。
基于模型的遷移學習是指利用源領(lǐng)域已經(jīng)訓練好的模型或參數(shù)來初始化或約束目標領(lǐng)域的模型,從而提高目標領(lǐng)域?qū)W習效果的方法。這種方法的假設(shè)是源領(lǐng)域和目標領(lǐng)域在模型層面有共同的知識,可以通過共享模型或參數(shù)來實現(xiàn)知識轉(zhuǎn)移。這種方法通常適用于任務(wù)遷移學習,也就是源領(lǐng)域和目標領(lǐng)域具有相同的特征空間和標簽空間,但是不同的任務(wù)。例如,在圖像分類中,可以利用在大規(guī)模數(shù)據(jù)集上預訓練好的卷積神經(jīng)網(wǎng)絡(luò)模型,通過微調(diào)或剪枝等方法來適應(yīng)新的圖像分類任務(wù) 。這種方法優(yōu)點是可以充分利用模型之間存在的相似性;缺點是模型參數(shù)不易收斂。
基于關(guān)系的遷移學習是指利用源領(lǐng)域和目標領(lǐng)域之間的關(guān)系知識來進行知識遷移的方法。這種方法的假設(shè)是源領(lǐng)域和目標領(lǐng)域中,數(shù)據(jù)之間的聯(lián)系關(guān)系是相同或相似的,可以通過類比或推理等方式來實現(xiàn)知識轉(zhuǎn)移。這種方法通常適用于非獨立同分布的數(shù)據(jù),即每個數(shù)據(jù)點都與其他數(shù)據(jù)點存在關(guān)聯(lián)。例如,在推薦系統(tǒng)中,可以利用用戶和物品之間的評分矩陣,將一個域中的用戶或物品映射到另一個域中,從而進行跨域推薦。這種方法的優(yōu)點是可以處理源域和目標域之間分布差異較大的情況,可以處理類別不平衡的問題,并且對少量標注數(shù)據(jù)也能取得不錯的效果;缺點是需要構(gòu)建類別之間的關(guān)系網(wǎng)絡(luò),關(guān)系提取不準確會對遷移產(chǎn)生負面影響,計算關(guān)系網(wǎng)絡(luò)的空間和時間復雜度較高。
基于對抗的遷移學習是指利用生成對抗網(wǎng)絡(luò)(GAN)或其他對抗性技術(shù)來縮小源域和目標域之間的差異,從而提高目標域?qū)W習效果的方法。這種方法的假設(shè)是“為了有效的遷移,良好的表征應(yīng)該是對主要學習任務(wù)的區(qū)別性,以及對源域和目標域的不加區(qū)分。”基于對抗性的深度遷移學習是指在生成對抗性網(wǎng)絡(luò) (GAN)的啟發(fā)下,引入 對抗性技術(shù) ,尋找既適用于源域又適用于目標域的可遷移表達。它基于這樣的假設(shè):“為了有效的遷移,良好的表征應(yīng)該是對主要學習任務(wù)的區(qū)別性,以及對源域和目標域的不加區(qū)分。”例如,在圖像轉(zhuǎn)換中,可以利用CycleGAN等方法,將一個域中的圖像風格轉(zhuǎn)換為另一個域中的圖像風格。這種方法的優(yōu)點是可自動適應(yīng)不同分布,無需目標域標注;缺點是訓練穩(wěn)定性差,難以收斂,效果不穩(wěn)定。
3.遷移學習的應(yīng)用
為了幫助大家更好地理解遷移學習,這里舉了兩個常見的例子 ^ v ^
圖像分類:圖像分類是指根據(jù)圖像的內(nèi)容,將其分為不同的類別,如貓、狗、飛機等。圖像分類是計算機視覺中的一個基本任務(wù),但是對于一些特定的領(lǐng)域,如醫(yī)學圖像、衛(wèi)星圖像等,可能沒有足夠的標注數(shù)據(jù)來訓練一個有效的分類器。這時,可以利用遷移學習,將一個在大規(guī)模通用數(shù)據(jù)集(如ImageNet)上訓練好的分類器,遷移到目標領(lǐng)域上,通過微調(diào)或者特征提取等方法,來提高目標領(lǐng)域的分類效果。例如,使用遷移學習將在ImageNet上訓練好的ResNet模型遷移到醫(yī)學圖像上,實現(xiàn)肺炎檢測、皮膚癌診斷等工作。
自然語言處理:自然語言處理(NLP)是指讓計算機理解和生成自然語言(如中文、英文等)的技術(shù)。NLP涉及很多子任務(wù),如情感分析、機器翻譯、文本摘要等。由于不同的語言或者不同的領(lǐng)域(如新聞、社交媒體、法律等)有著不同的語法和語義規(guī)則,因此需要大量的數(shù)據(jù)來訓練一個通用的NLP模型。遷移學習可以幫助解決這個問題,通過將一個在大量文本上預訓練好的NLP模型(如BERT、GPT等),遷移到目標語言或者目標領(lǐng)域上,通過微調(diào)或者適配等方法,來提高目標任務(wù)的效果。例如,使用遷移學習將在英文文本上預訓練好的BERT模型遷移到中文文本上,實現(xiàn)命名實體識別、情感分析等任務(wù)。
4.遷移學習的常見模型
基于實例的遷移學習:TrAdaBoost1、BIW2等。
基于特征的遷移學習:TCA3、DAN4等。
基于模型的遷移學習:fine-tuning5、LwF等。
基于模型的遷移學習:GraphMix、MetaMIML等。
基于對抗的遷移學習:DANN、CycleGAN等。
5.遷移學習的優(yōu)勢
遷移學習的主要優(yōu)勢可歸納如下:
提高模型泛化能力:遷移學習通過從相關(guān)任務(wù)中獲取先驗知識,可以提高模型在目標任務(wù)上泛化的能力,避免從頭訓練。
減少標注數(shù)據(jù)依賴:遷移學習可以在目標任務(wù)標注數(shù)據(jù)不足時,利用源任務(wù)的知識提高模型性能,減少對大規(guī)模標注數(shù)據(jù)的依賴。
加速模型訓練:基于預訓練模型的遷移學習可以跳過模型初始化和預訓練過程,直接進行微調(diào),大大加速模型的訓練。
提高性能上限:遷移學習通過引入外部信息,可以使模型超越僅從目標任務(wù)數(shù)據(jù)中學習的性能上限。
擴展模型應(yīng)用范圍:遷移學習訓練出的模型可以超越源數(shù)據(jù)集和目標數(shù)據(jù)集,應(yīng)用到更廣泛的領(lǐng)域。
更好引導特征學習:遷移學習可以更好地引導模型學習任務(wù)相關(guān)的特征表示,并抑制無關(guān)特征的負面影響。
6.算法實例詳解
下面,我將根據(jù)不同的模型分類,分別提供對應(yīng)的代碼詳解。
6.1實例遷移
直接重用源域數(shù)據(jù),可以對源域樣本進行重新加權(quán),使其分布適應(yīng)目標域。
#源域數(shù)據(jù) source_data=[圖片數(shù)據(jù)] #目標域數(shù)據(jù) target_data=[圖片數(shù)據(jù)] #計算源域數(shù)據(jù)在目標域中的權(quán)重 weights=compute_weight(source_data,target_data) #加權(quán)源域數(shù)據(jù) weighted_source_data=[w*imgforw,imginzip(weights,source_data)] #合并源域和目標域數(shù)據(jù)進行訓練 combined_data=target_data+weighted_source_data
6.2特征遷移
使用源域模型提取特征,轉(zhuǎn)移到目標模型中。
#源域模型 source_model=pretrain_model() #固定源域模型參數(shù) source_model.trainable=False #提取源域模型最后一層前的特征 target_features=source_model(target_data) #目標模型,將源域特征作為輸入 target_model=tf.keras.models.Sequential() target_model.add(tf.keras.layers.InputLayer(input_shape=target_features.shape[1:])) target_model.add(tf.keras.layers.Dense(num_classes)) #訓練 target_model.compile(optimizer='adam',loss='categorical_crossentropy') target_model.fit(target_features,target_labels)
6.3參數(shù)遷移
初始化目標模型的參數(shù)為源模型的參數(shù)。
#源域模型 source_model=pretrain_model() #目標模型,結(jié)構(gòu)與源域模型相同 target_model=Model() #初始化目標模型的參數(shù) target_model.set_weights(source_model.get_weights()) #訓練 target_model.compile(optimizer='adam',loss='categorical_crossentropy') target_model.fit(target_data,target_labels)
6.4關(guān)系遷移
建模源域和目標域之間的相關(guān)性,加入目標模型的損失函數(shù)中。
#源域數(shù)據(jù) source_data=[圖片數(shù)據(jù)] #目標域數(shù)據(jù) target_data=[圖片數(shù)據(jù)] #源域模型 source_model=Model() #目標模型 target_model=Model() #相關(guān)性損失 correlation_loss=compute_correlation_loss(source_model,target_model) #目標域損失 target_loss=compute_target_loss(target_model) #總損失 total_loss=target_loss+λ*correlation_loss #訓練 target_model.compile(loss=total_loss) target_model.fit(target_data,target_labels)
6.5模式遷移
在目標模型中加入正則項,使其學習到源模型的部分特征模式。
#源域模型 source_model=pretrain_model() #目標模型 target_model=Model() #定義模式正則項 pattern_reg=compute_pattern_reg(target_model,source_model) #目標域損失 target_loss=compute_target_loss(target_model) #總損失 total_loss=target_loss+λ*pattern_reg #訓練 target_model.compile(loss=total_loss) target_model.fit(target_data)
6.6多任務(wù)遷移
同時優(yōu)化源域任務(wù)和目標域任務(wù)的損失。
#源域模型 source_model=Model() #源域數(shù)據(jù) source_data=[圖片數(shù)據(jù)] #目標模型 target_model=Model() #目標域數(shù)據(jù) target_data=[圖片數(shù)據(jù)] #源域任務(wù)損失 source_loss=compute_source_loss(source_model,source_data) #目標域任務(wù)損失 target_loss=compute_target_loss(target_model,target_data) #多任務(wù)損失 total_loss=source_loss+target_loss #訓練 model.compile(loss=total_loss) model.fit(source_data+target_data)
6.7對抗遷移
使用對抗訓練,使模型適應(yīng)目標域。
#源域數(shù)據(jù) source_data=[圖片數(shù)據(jù)] #目標域數(shù)據(jù) target_data=[圖片數(shù)據(jù)] #特征提取器 feature_extractor=Model() #源域判別器 source_discriminator=Discriminator() #目標域判別器 target_discriminator=Discriminator() #對抗損失 adversarial_loss=compute_adversarial_loss(feature_extractor,source_discriminator)+compute_adversarial_loss(feature_extractor,target_discriminator) #訓練 model.compile(loss=adversarial_loss) model.fit(source_data+target_data)
7. 從圖像分類到目標檢測的實戰(zhàn)
最后,我用訓練好的ResNet50作為被遷移源對象,在其基礎(chǔ)上增加目標檢測模塊,之后在PASCAL VOC數(shù)據(jù)集進行訓練,實現(xiàn)目標檢測任務(wù)的遷移學習。
具體代碼如下:
importtensorflowastf fromtensorflow.keras.applicationsimportResNet50 fromtensorflow.keras.layersimportConv2D,F(xiàn)latten,Dense #加載預訓練模型作為特征提取器 feature_extractor=ResNet50(weights='imagenet',include_top=False) #凍結(jié)預訓練模型所有層 forlayerinfeature_extractor.layers: layer.trainable=False #構(gòu)建檢測模型 inputs=tf.keras.Input(shape=(224,224,3)) x=feature_extractor(inputs) x=Conv2D(filters=256,kernel_size=3)(x) x=Flatten()(x) x=Dense(256,activation='relu')(x) predictions=Dense(10,activation='softmax')(x)#10個檢測目標 model=tf.keras.Model(inputs=inputs,outputs=predictions) #編譯模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) #加載PASCALVOC數(shù)據(jù)并訓練 voc_data=#加載PASCALVOC數(shù)據(jù)集 model.fit(voc_data,voc_labels,epochs=5)
這里我們加載了在ImageNet上預訓練的ResNet50作為特征提取器,凍結(jié)了其權(quán)重不更新。然后在它之上構(gòu)建了一個新的卷積和全連接層來進行目標分類。這樣通過遷移ResNet50提取的圖像特征,可以減少目標檢測模型對大量標注數(shù)據(jù)的需求。只需要小量樣本訓練全連接分類層即可。這種做法屬于遷移學習中的特征遷移和Fine Tuning技術(shù),是目標檢測領(lǐng)域中非常常用的遷移學習實踐。
8.遷移學習的前景
多源遷移學習的探索:現(xiàn)有方法主要基于單一源域進行遷移,未來可研究如何有效集成多個源域的信息。
異構(gòu)遷移學習的發(fā)展:研究如何在源域和目標域特征空間、分布差異大的情況下進行有效遷移。
遷移學習理論的完善:加強對遷移學習內(nèi)在機理的理解,建立更統(tǒng)一完備的理論指導框架。
遷移學習算法的優(yōu)化:提出更有效的遷移學習算法,縮小理論和實踐的差距。
9.文章總結(jié)
本文介紹了遷移學習的概念、分類、應(yīng)用、模型、優(yōu)勢、代碼示例、項目示例和發(fā)展前景。目前,遷移學習仍有很多值得探索的方向,未來它將推動人工智能技術(shù)向通用和自動化方向發(fā)展。最后,由于本人知識范圍有限,有疏漏之處,麻煩大家指出。
-
算法
+關(guān)注
關(guān)注
23文章
4681瀏覽量
94323 -
機器學習
+關(guān)注
關(guān)注
66文章
8478瀏覽量
133819 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1220瀏覽量
25183 -
遷移學習
+關(guān)注
關(guān)注
0文章
74瀏覽量
5660
原文標題:(收藏)一文搞定遷移學習!原理+分類+代碼+實戰(zhàn)全都有!
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論