 如何在Python中進行Elasticsearch操作?
如何在Python中進行Elasticsearch操作?
什么是ElasticSearch?
ElasticSearch(ES)是一個建立在Apache Lucene之上的高度可用的分布式開源搜索引擎。它基于Java構建的,因此可用于許多平臺。數據以JSON格式非結構化存儲,這也使其成為一種NoSQL數據庫。與其他NoSQL數據庫不同,ES還提供搜索引擎功能和其他相關功能。
ElasticSearch用例
ES可用于多種目的,下面給出了其中的幾個:
你運營著提供大量動態內容的網站,比如電子商務網站或者博客。通過實施ES,你不僅可以為Web應用程序提供強大的搜索引擎,還可以在應用程序中提供原生自動補全功能。
你可以獲取不同類型的日志數據,然后可以使用它來查找趨勢和統計信息。
設置和運行
安裝ElasticSearch最簡單的方法就是下載并運行可執行文件。必須確保使用的是Java 7或更高版本。
下載后解壓縮并運行它的二進制文件。

滾動窗口中會出現很多文字。如果你看到像下面這樣的,那么它應該是完成了。

但是,由于眼見為實,通過cURL 查看類似于這樣的歡迎界面以便你知道確實成功安裝了:
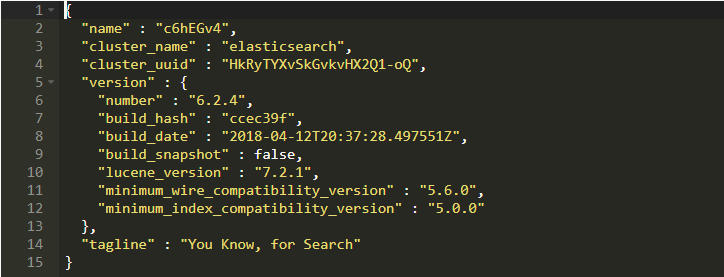
在我開始訪問Python中的Elastic Search之前,我們來做一些基本的東西。 正如我提到ES提供了一個REST API接口,我們將使用它來執行不同的任務。
基本示例
你要做的第一件事就是創建索引。一切都以索引形式存儲。RDBMS概念中索引相當于一個數據庫,因此不要將它與你在RDBMS中學習的典型索引概念混淆。使用PostMan來運行REST API。

如果它成功運行,你會看到如下所示的回應:
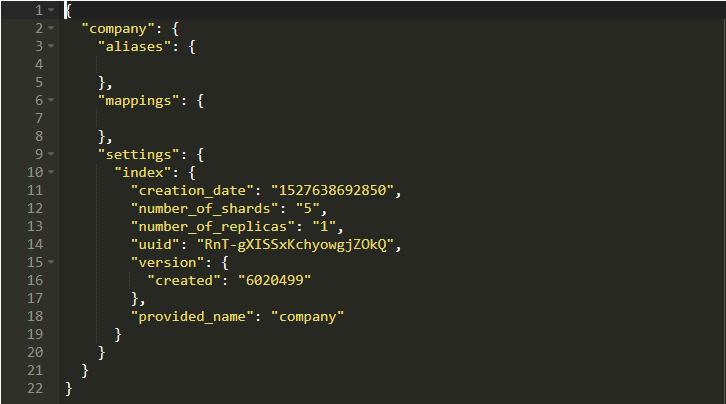
所以我們使用company為名創建了一個數據庫。換句話說,我們創建了一個名為“company”的索引。你將看到如下所示的內容:
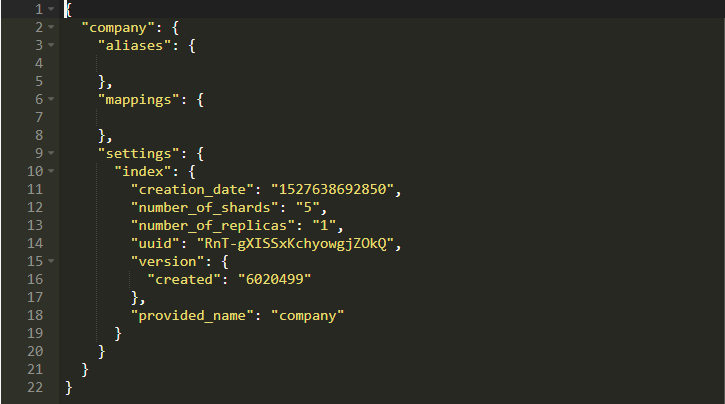
暫時不用管mappings是什么,我們會在后面討論它。它實際上做的只是創建一個你自己的Schema文檔。creation_date是不言自明的。number_of_shards表示將保留此索引數據的分區數量。將整個數據保存在單個磁盤上毫無意義。如果你運行的是多個Elastic節點的集群,那么整個數據都會被分割。簡而言之,如果有5個分片,則整個數據可以在5個分片中使用,并且ElasticSearch集群可以服務來自其任何節點的請求。
副本討論的是你的數據的鏡像。如果你熟悉主從概念,那么這對你來說不應該是新事物。你可以了解更多關于基本ES概念。
創建索引的cURL版本是單線程的。

你也可以一次執行索引創建和記錄插入任務。你所要做的就是以JSON格式傳遞你的記錄。你可以在PostMan中使用下面的東西:
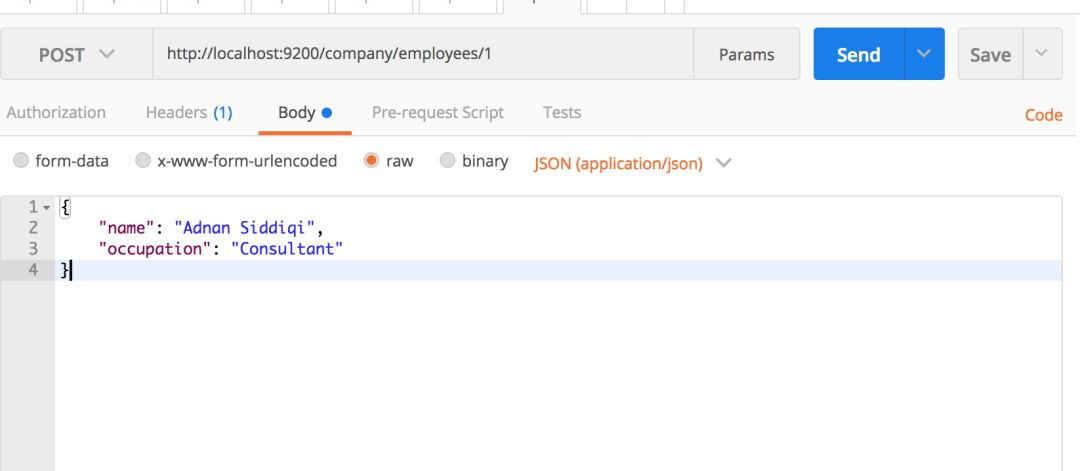
請確保你將Content-Type設置為application/json.
一個名為company的索引會被創建如果它原本不存在的話,然后在這里創建一個名為employees的新類型。Type實際上是RDBMS中的表的ES版本。
上述請求將輸出以下JSON結構:
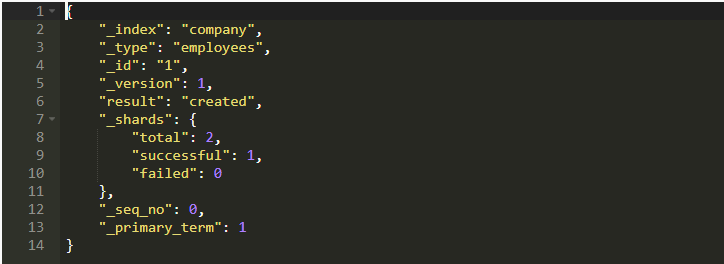
你傳遞/1作為你的記錄的ID,但這是不必要的。它所做的只是將_id字段設置為值1,然后數據以JSON格式傳遞,最終作為新記錄或文檔插入。

你可以看到元和實際記錄。
cURL版本將是:
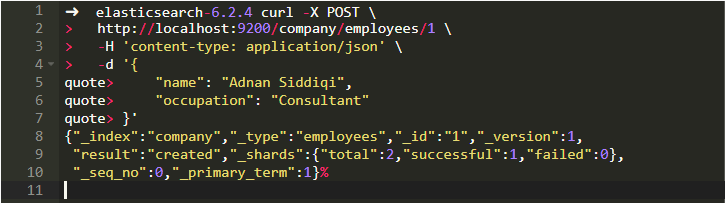
如果你想更新該記錄怎么辦?這很簡單。你所要做的就是改變你的JSON記錄。如下所示:
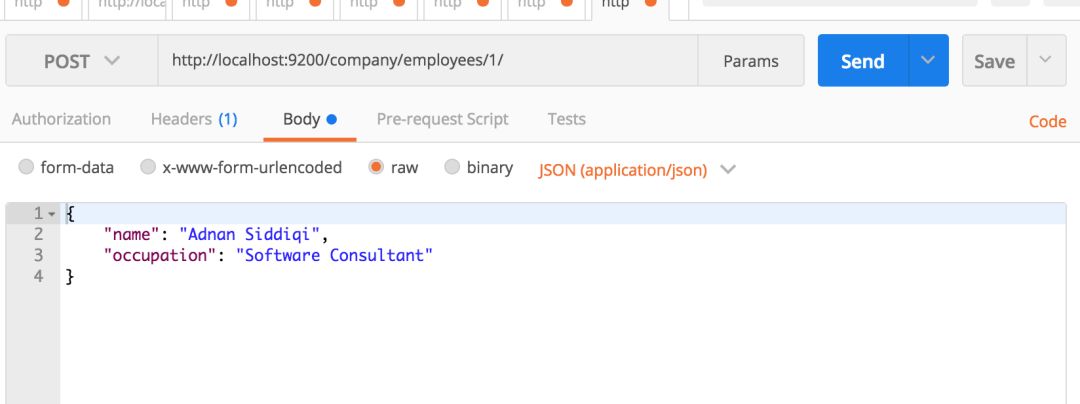
它會生成以下輸出:
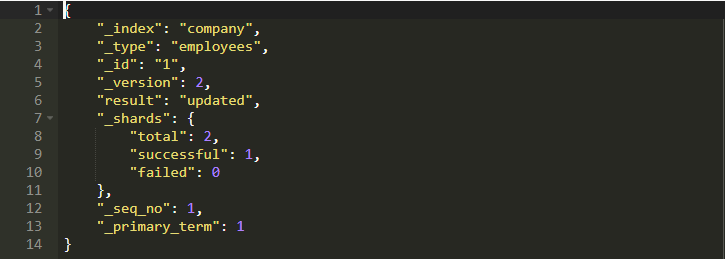
注意現在_result字段設置為updated而不是created。
當然,你也可以刪除某些記錄。
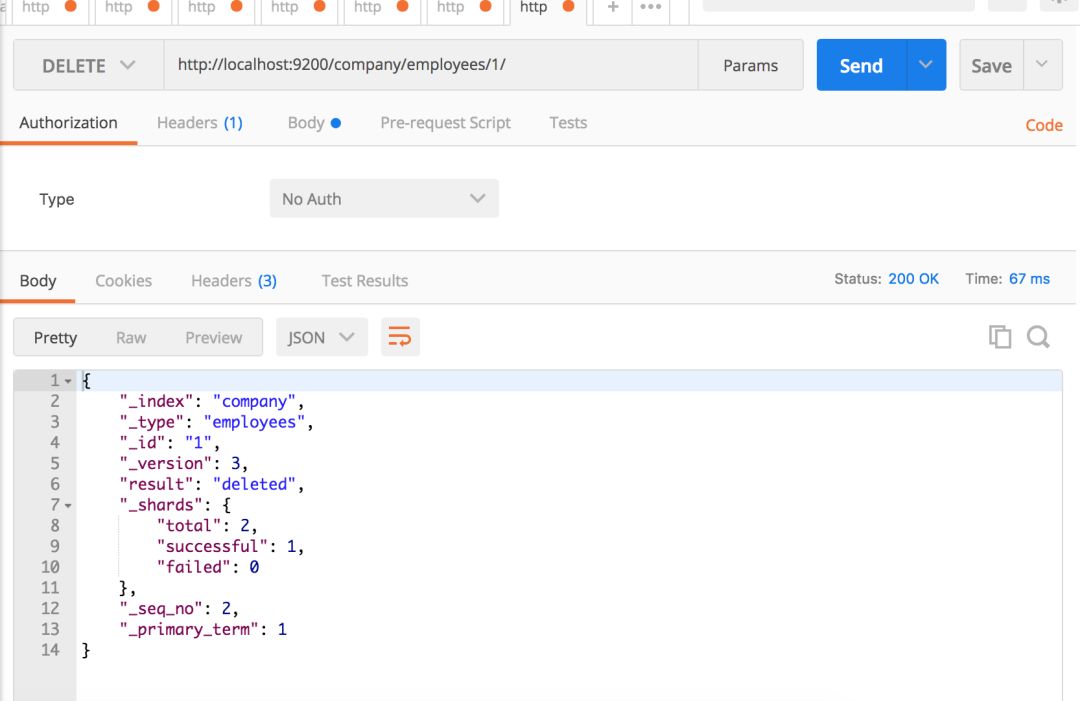
如果你瘋了,或者你的女朋友甩了你,你可以通過從命令行運行curl -XDELETE localhost:9200/_all來毀掉整個世界。
讓我們做一些基本的搜索。 它將搜索employees類型下的所有字段并返回相關記錄。
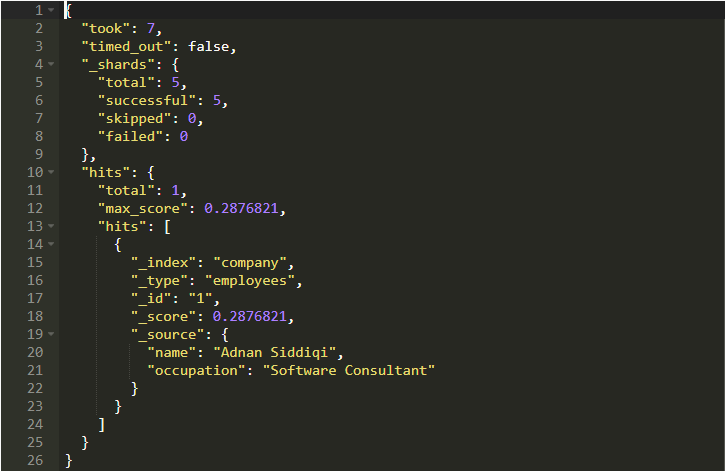
max_score字段表示記錄的相關性,即記錄的最高分數。如果有多個記錄,那么它會是一個不同的數字。
你還可以通過傳遞字段名稱將搜索條件限制到某個字段。
我剛剛介紹了基本的例子。ES可以做很多事情,但是希望你自己通過閱讀文檔來進一步探索它,而我將繼續介紹在Python中使用ES。
在Python中使用ElasticSearch
說實話,ES的REST API已經足夠好了,可以讓你使用requests庫執行所有任務。不過,你可以使用ElasticSearch的Python庫專注于主要任務,而不必擔心如何創建請求。
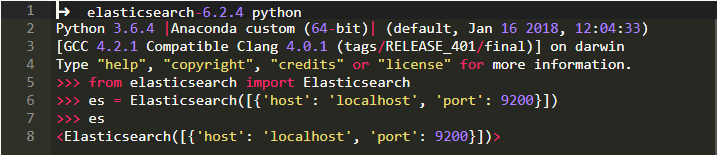
通過pip安裝它,然后你可以在你的Python程序中訪問它。

為確保它的安裝正確,請從命令行運行以下基本片段:
網頁搜索和Elasticsearch
我們來討論一下使用Elasticsearch的一些實際用例。我們的目標是訪問在線食譜并將它們存儲在Elasticsearch中以用于搜索和分析。我們將首先從Allrecipes中獲取數據并將其存儲在ES中。我們還將創建一個嚴格的模式或映射,以便我們確保數據以正確的格式和類型進行索引。最后只要列出沙拉食譜的清單。我們開始吧!
獲取數據
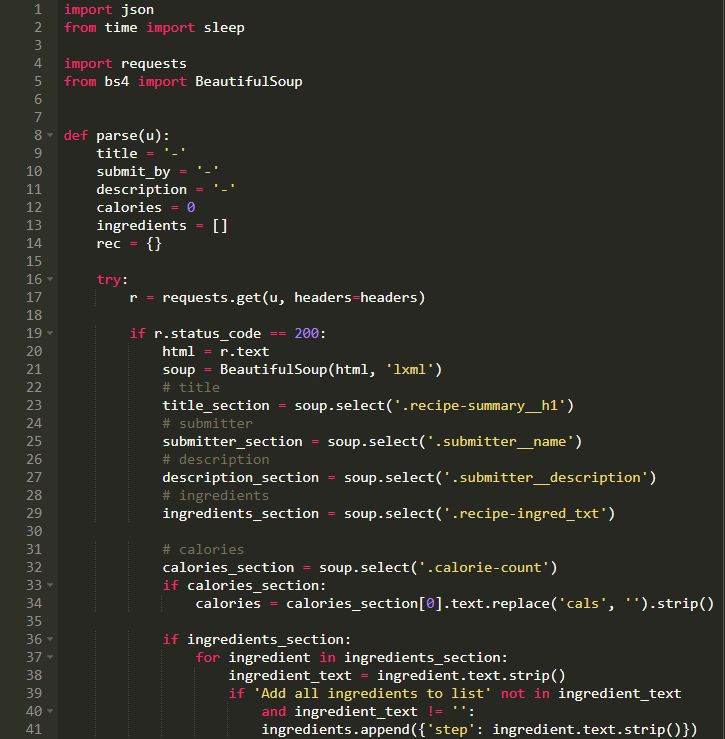
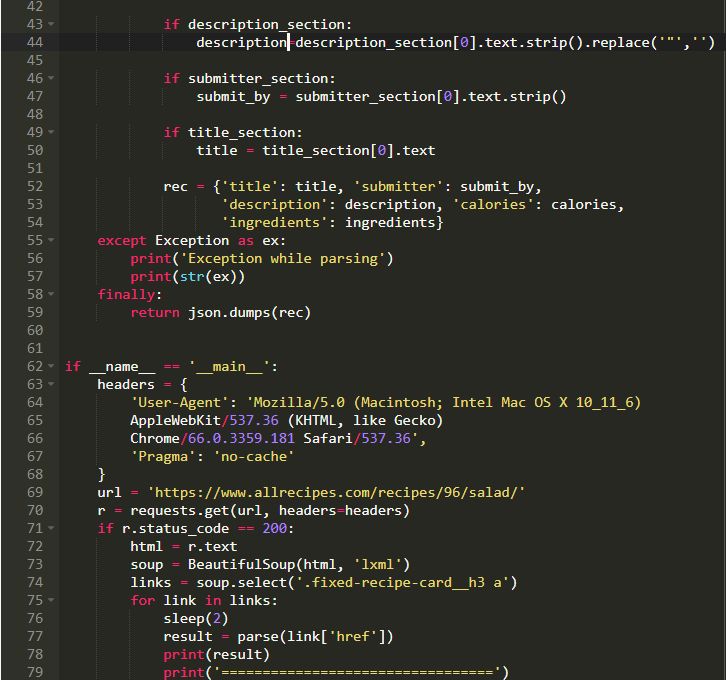
所以這是獲取數據的基本程序。因為我們需要JSON格式的數據,所以我對其進行了相應的轉換。
創建索引
我們得到了所需的數據,接下來我們必須存儲它。我們要做的第一件事就是創建一個索引。讓我們將其命名為recipes。 該類型將被稱為salads。我要做的另一件事是創建我們的文檔結構的映射。
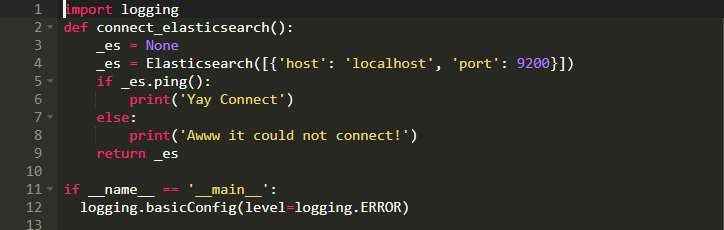
在我們創建索引之前,我們必須連接ElasticSearch服務器。
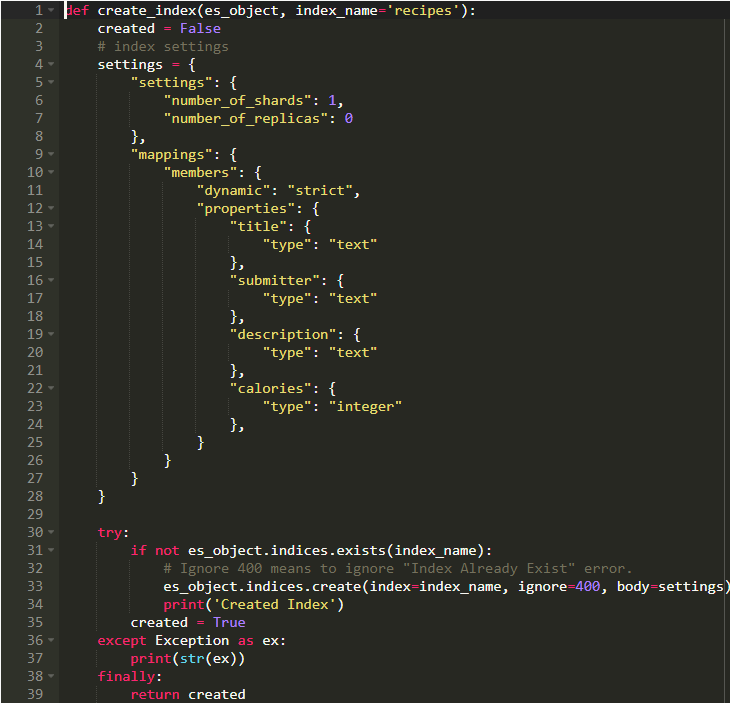
這里有很多要說的事。首先,我們傳遞了一個包含整個文檔結構映射的配置變量。映射是模式這一術語在Elastic的版本。就像我們在表格中設置特定的字段數據類型一樣,我們在這里做類似的事情。檢查文檔,它涵蓋的不僅僅是這些。所有字段都是文本類型,但是calories類型為Integer。
接下來,我確保索引不存在,然后創建它。參數ignore = 400在檢查后不再需要,但存在性證明是必要的,因為這可以防止錯誤地覆蓋現有索引。雖然這很危險。這就像覆蓋數據庫。
如果索引成功創建,你可以驗證它,它會輸出如下所示的內容:
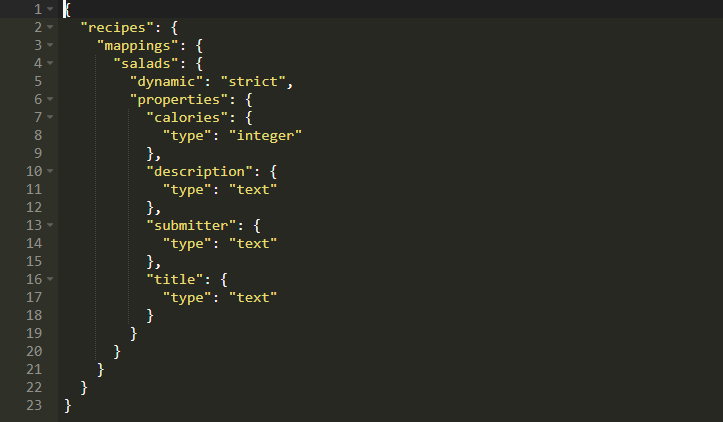
通過傳遞dynamic:strict我們使Elasticsearch嚴格檢查任何傳入的文檔。在這里,salads實際上是文檔類型。Type實際上是Elasticsearch對RDBMS表的回答。
記錄索引
下一步是存儲實際的數據或文檔。

運行它,你會看到:

你能猜到為什么會這樣嗎?由于我們沒有在我們的映射中設置ingredients,因此ES不允許我們存儲包含ingredients字段的文檔。現在你知道事先分配映射的優勢了。你可以通過這樣做避免破壞數據。現在,讓我們稍微修改一下映射,現在看起來如下所示:
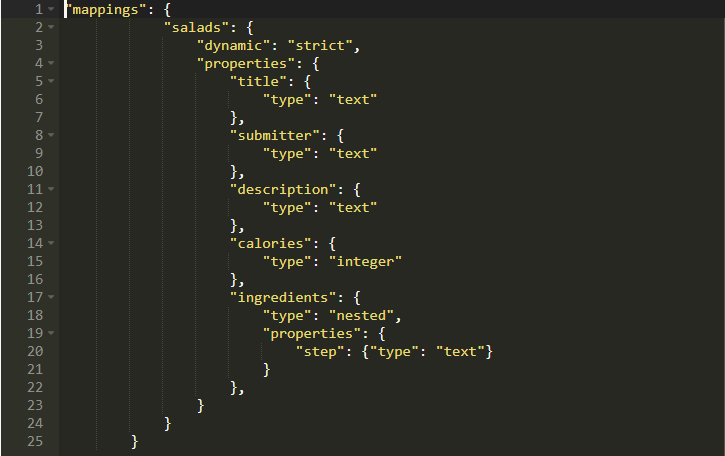
我們添加nested類型的ingrdients,然后分配內部字段的數據類型,即在我們的案例中的text。
nested數據類型允許設置嵌套的JSON對象的類型。再次運行它,你將看到以下輸出:
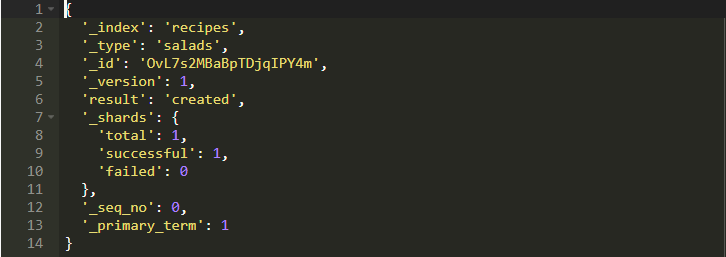
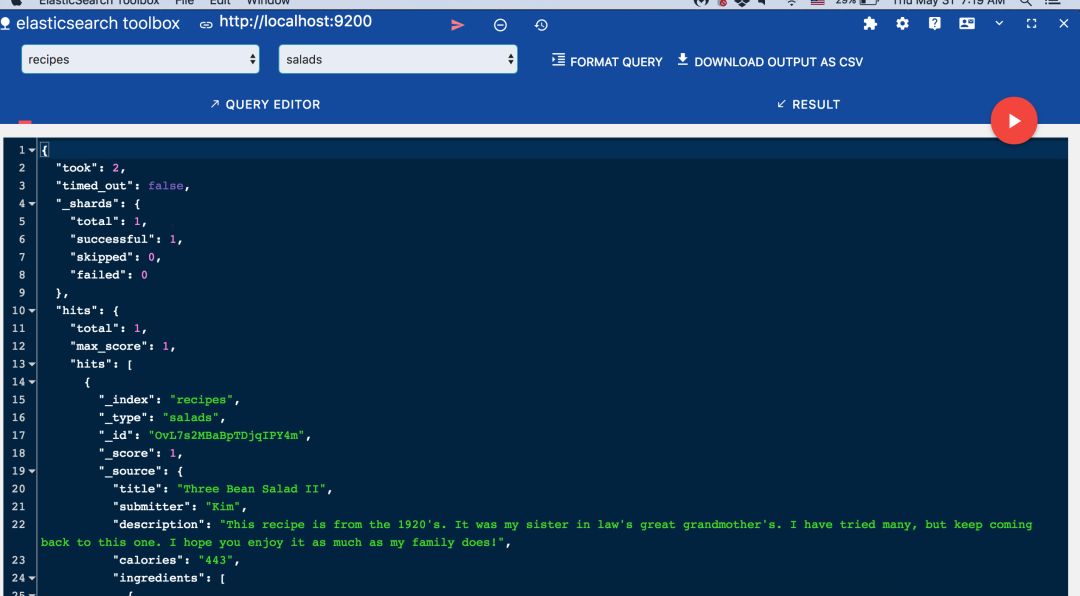
由于你根本沒有傳遞_id,因此ES本身為存儲的文檔分配了一個動態ID。 我使用Chrome,借助名為ElasticSearch Toolbox的工具使用ES數據查看器來查看數據。
在我們繼續之前,讓我們在calories字段中發送一個字符串,看看它是如何發生的。請記住,我們已將其設置為整數。 在編制索引時出現以下錯誤:

所以現在你知道為文檔分配一個映射的好處了。如果你不這樣做,它仍然會工作,因為Elasticsearch將在運行時分配它自己的映射。
查詢記錄
現在,記錄被編入索引,是時候根據我們的需要查詢它們了。我將創建一個名為search()的函數,它將顯示我們的查詢結果。

這是非常基本的。 你在其中傳遞索引和搜索條件。讓我們嘗試一些查詢。

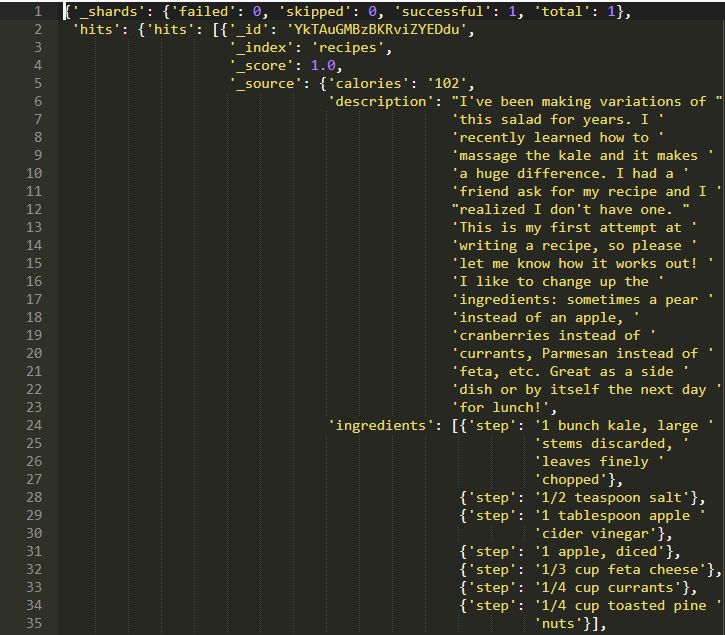

如果你想獲得卡路里超過20的記錄怎么辦?

你也可以指定想要返回的列或字段。上述查詢將返回卡路里大于20的所有記錄。此外,它將僅在_source下顯示title字段。
結論
Elasticsearch是一個功能強大的工具,它可以提供強大的功能幫助你來返回最準確的結果集,從而使你現有的或新的應用程序可搜索。我剛剛講述了它的要點,你可以繼續閱讀文檔并熟悉這個強大的工具。尤其是模糊搜索功能非常棒。如果我有機會,我會在即將發布的帖子中介紹Query DSL。
-
JAVA
+關注
關注
19文章
2974瀏覽量
104984 -
引擎
+關注
關注
1文章
361瀏覽量
22615 -
python
+關注
關注
56文章
4807瀏覽量
84959
原文標題:在Python中使用Elasticsearch
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在ADS中進行EM仿真
如何在Arduino中進行編程
如何在PADS 3D Layout中進行命令操作

如何在環境安裝使用Python操作word
Python 更新 Elasticsearch 的幾種方法






 工商網監
工商網監
評論