") 什么是神經(jīng)架構(gòu)搜索?機器學(xué)習(xí)自動化真能普及大眾嗎?
什么是神經(jīng)架構(gòu)搜索?機器學(xué)習(xí)自動化真能普及大眾嗎?
CMU和DeepMind的研究者最近發(fā)表了一篇有趣的論文——Differentiable Architecture Search (DARTS),提出了一種替代神經(jīng)架構(gòu)搜索的方法,目前是機器學(xué)習(xí)的熱門領(lǐng)域。去年,神經(jīng)架構(gòu)搜索被“捧”得很高,因為谷歌CEO桑德拉·皮查伊和谷歌AI的負責(zé)人杰夫·迪恩提出,神經(jīng)架構(gòu)搜索和大量的計算力對于機器學(xué)習(xí)的普及至關(guān)重要。于是媒體們對谷歌的這一工作進行了全面報道。

在今年3月舉辦的TensorFlow DevSummit大會上,杰夫·迪恩估計在未來,谷歌云可以用比目前高100倍的計算力替代人類機器學(xué)習(xí)專家。他將需要昂貴計算成本的神經(jīng)架構(gòu)搜索作為主要案例,解釋了為什么我們需要100倍計算力才能讓機器學(xué)習(xí)惠及更多人。
那么,到底什么是神經(jīng)架構(gòu)搜索?這是讓機器學(xué)習(xí)普及的關(guān)鍵嗎?這篇文章將重點解決這一問題。而在下篇文章中,我們會詳細了解谷歌的AutoML。神經(jīng)架構(gòu)搜索是AutoML的一部分,在其剛剛出現(xiàn)時同樣受到了熱烈的追捧。
目錄
什么是AutoML?
AutoML有多有用?
什么是神經(jīng)架構(gòu)搜索?
什么是DARTS?
神經(jīng)架構(gòu)搜索有什么用處?
除此之外還有什么方法能提高機器學(xué)習(xí)從業(yè)者的效率?
什么是AutoML?
AutoML這個術(shù)語曾被用來描述選擇機器學(xué)習(xí)模型或參數(shù)優(yōu)化的自動化方法。這些方法的所用的算法有很多種,例如隨機森林、梯度提升、神經(jīng)網(wǎng)絡(luò)等等。AutoML包括開源的AutoML庫、研討會、研究項目和比賽。初學(xué)者可能會感覺他們只是在為模型測試不同的參數(shù),將這一過程自動化可能會讓機器學(xué)習(xí)的過程更容易,同時還能提升有經(jīng)驗的從業(yè)者的速度。
AutoML庫有很多種,最“古老”的是AutoWEKA,于2013年發(fā)布,它可以自動選擇模型和參數(shù)。其他的庫包括auto-sklearn、H2O AutoML和TPOT。
AutoML有多有用?
AutoML提供了一種可以選擇模型、優(yōu)化超參數(shù)的方法。它同樣能用來評估某一問題所處的水平如何。那么這意味著數(shù)據(jù)科學(xué)家可以被替代嗎?目前還不行,因為我們需要考慮機器學(xué)習(xí)從業(yè)者實際的工作是什么。
對很多機器學(xué)習(xí)項目來說,選擇一個合適的模型只是搭建機器學(xué)習(xí)產(chǎn)品中的一部分。在上一篇文章中,我們說過如果參與者并不理解機器學(xué)習(xí)模型各部分之間是如何連接的,這一項目可能會失敗。我認為這一過程需要30多種不同的步驟,其中兩個非常費時,即數(shù)據(jù)清洗和模型訓(xùn)練。雖然AutoML可以幫助選擇模型和超參數(shù),但是仍需要關(guān)注其他數(shù)據(jù)專家的需要和現(xiàn)存的問題。
在下一篇文章中,我會提出一些AutoML的替代方法,能讓機器學(xué)習(xí)從業(yè)者工作得更高效。
什么是神經(jīng)架構(gòu)搜索?
神經(jīng)架構(gòu)搜索是AutoML最受人關(guān)注的部分,谷歌CEO桑德拉·皮查伊曾寫道:“設(shè)計神經(jīng)網(wǎng)絡(luò)非常耗費時間,并且需要一名專家將它限制在更小的科學(xué)和工程社區(qū)里。這就是我們創(chuàng)建AutoML的原因,證明了我們可以讓神經(jīng)網(wǎng)絡(luò)設(shè)計神經(jīng)網(wǎng)絡(luò)。”
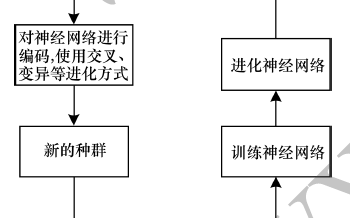
他提到的“神經(jīng)網(wǎng)絡(luò)設(shè)計神經(jīng)網(wǎng)絡(luò)”是指神經(jīng)架構(gòu)搜索;通常強化學(xué)習(xí)或演化算法使用來設(shè)計新的神經(jīng)網(wǎng)絡(luò)架構(gòu)的。這非常有用,因為它能讓我們發(fā)現(xiàn)更復(fù)雜的架構(gòu),同時還能根據(jù)具體目標進行優(yōu)化調(diào)整。神經(jīng)架構(gòu)搜索通常需要大量計算力。
準確的說,神經(jīng)架構(gòu)搜索經(jīng)常包括學(xué)習(xí)類似圖層的東西,可以組合成重復(fù)的單元以創(chuàng)建一個神經(jīng)網(wǎng)絡(luò):
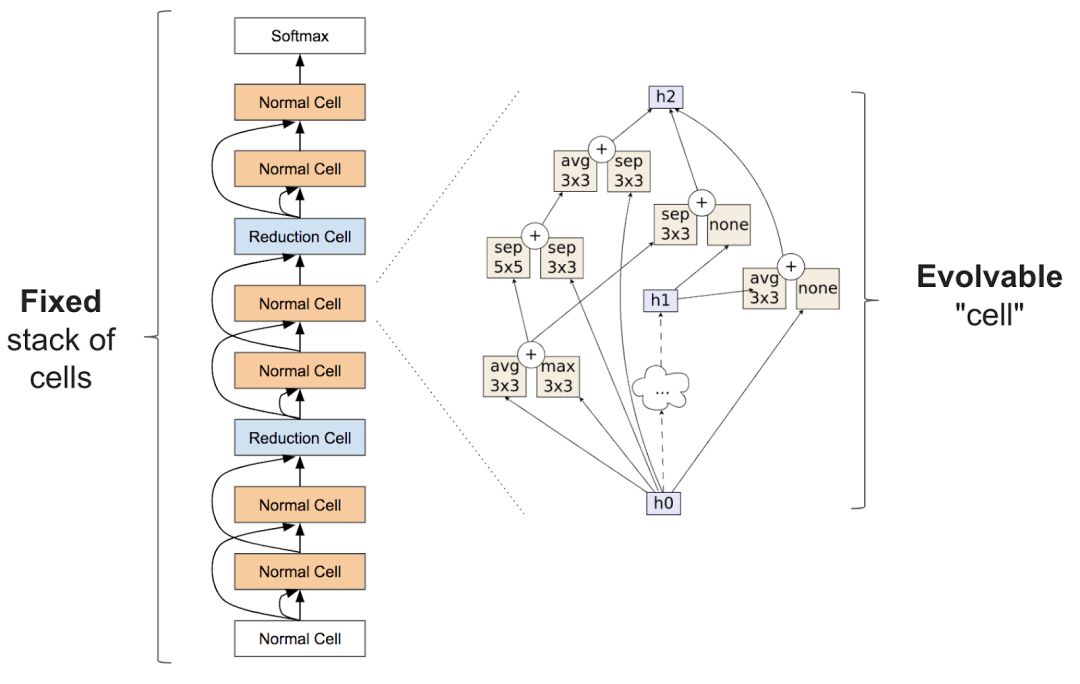
有關(guān)神經(jīng)架構(gòu)搜索的論文非常多,這里我們著重分析最近的幾篇:
AutoML開始進入人們的視野就是由于谷歌AI的研究者Quoc Le和Barret Zoph于2017年5月在谷歌I/O大會上發(fā)表的論文:Neural Architecture Search With Reinforcement Learning。該論文使用強化學(xué)習(xí)為CV領(lǐng)域CIFAR10和NLP中的Penn Tree Bank問題尋找新的結(jié)構(gòu),并達到了與現(xiàn)有架構(gòu)相似的結(jié)果。
地址:arxiv.org/pdf/1611.01578.pdf
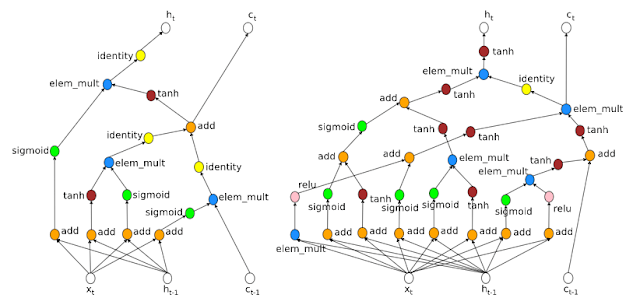
Learning Transferable Architecture for Scalable Image Recognition中的NASNet。這一項目從較小數(shù)據(jù)集(CIFAR10)中尋找建造模塊,之后在大數(shù)據(jù)集(ImageNet)上搭建結(jié)構(gòu)。不過這一項目也需要大量計算,需要1800個GPU(相當(dāng)于用1個GPU訓(xùn)練5年的時間)才能學(xué)會架構(gòu)。
地址:ai.googleblog.com/2017/11/automl-for-large-scale-image.html
Regularized Evolution for Image Classifier Architecture Search中的AmoebaNet。這一研究比上一個NASNet更耗費計算力,需要3150個GPU(相當(dāng)于用1個GPU訓(xùn)練9年的時間)。AmoebaNet中包含從演化算法中訓(xùn)練來的單元,說明經(jīng)過進化的結(jié)構(gòu)可以達到甚至超越人類水平和強化學(xué)習(xí)圖像分類器。fast.ai對此進行了改進,學(xué)習(xí)進程加快同時改變了訓(xùn)練過程中圖像的尺寸后,AmoebaNet目前是在單一機器上訓(xùn)練ImageNet最便宜的方法。
地址:arxiv.org/abs/1802.01548
Efficient Neural Architecture Search(ENAS):該方法比之前提到的兩種方法都更節(jié)省計算力,重要的是,它比標準的神經(jīng)架構(gòu)搜索便宜1000倍。在單一GPU上訓(xùn)練只花了16個小時。
地址:arxiv.org/pdf/1802.03268.pdf
什么是DARTS?
可微分的結(jié)構(gòu)搜索(differentiable architecture search)是最近由CMU和DeepMind的研究人員發(fā)布的一種方法,它假設(shè)候選架構(gòu)是連續(xù)而不是離散的,利用基于梯度的方法比黑箱搜索更有效。
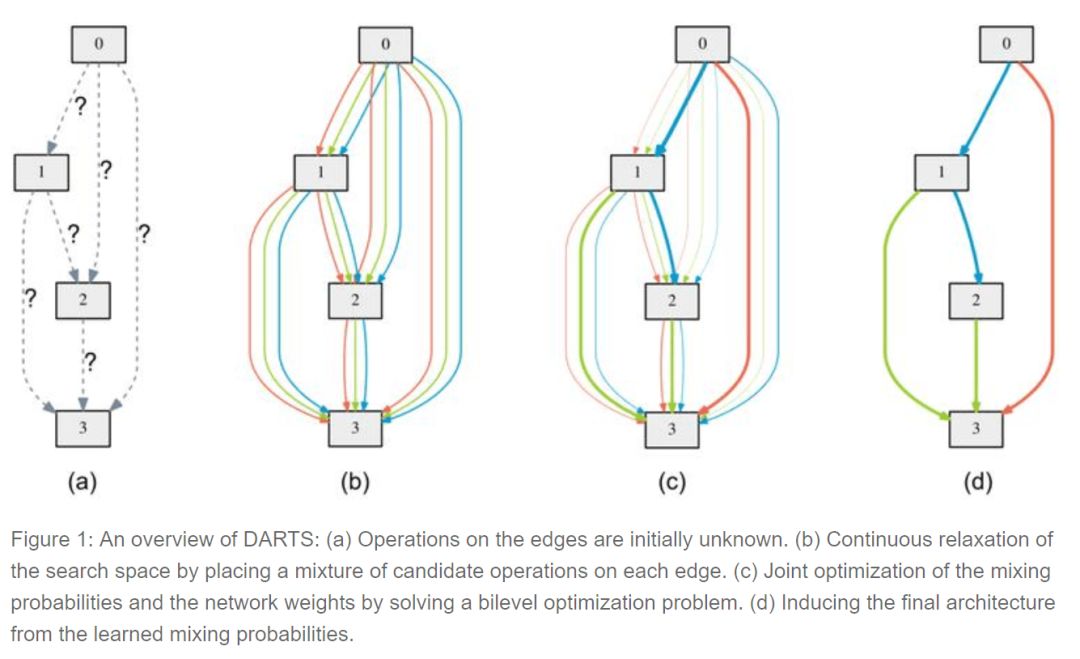
為了學(xué)習(xí)CIFAR10上的結(jié)構(gòu),DARTS只需要4個GPU,大大提升了效率。雖然還需要進一步研究,但這已經(jīng)為今后的研究指明了方向。
神經(jīng)架構(gòu)搜索有多有用?
在TensorFlow DevSummit上,杰夫·迪恩表示深度學(xué)習(xí)的一個重要部分正嘗試不同的結(jié)構(gòu)。這是他在演講中提到的唯一一個有關(guān)機器學(xué)習(xí)的觀點。

然而選擇模型只是復(fù)雜過程的一部分。大多數(shù)情況下,結(jié)構(gòu)選擇才是更難、更耗時或更重要的地方。目前,沒有證據(jù)表明每個新問題最好的方法是在自身結(jié)構(gòu)上建模。
像谷歌這樣致力于結(jié)構(gòu)設(shè)計和分享的機構(gòu)為我們提供了很重要的服務(wù)。但是基礎(chǔ)的結(jié)構(gòu)搜索方法只有一小部分研究者在基礎(chǔ)神經(jīng)架構(gòu)的設(shè)計上才需要使用到,我們可以直接用遷移學(xué)習(xí)得來的結(jié)構(gòu)。
除此之外還有什么方法能提高機器學(xué)習(xí)從業(yè)者的效率?
AutoML領(lǐng)域關(guān)注的核心問題即,如何讓模型選擇和超參數(shù)優(yōu)化自動化?然而自動化往往忽視了人類輸入的重要角色。而另一個重要問題是:人類如何與計算機合作,從而讓機器學(xué)習(xí)更有效呢?增強機器學(xué)習(xí)(augmented machine learning)是關(guān)注如何讓人與機器更好合作的話題,其中一個案例是Leslie Smith的leaning rate finder這篇論文,其中提到學(xué)習(xí)率是一個可以決定模型訓(xùn)練速度的超參數(shù),或者可以決定模型能否成功訓(xùn)練。學(xué)習(xí)速率查詢器可以讓人類很容易地找到一個良好的學(xué)習(xí)率,比AutoML更快。
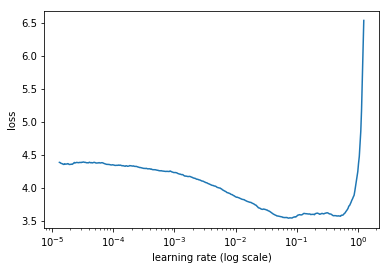
學(xué)習(xí)速率和損失之間的關(guān)系
在對超參數(shù)自動化的方法選擇上還有另一個問題:一些類別的模型運用很廣泛,需要調(diào)整的參數(shù)很少,對超參數(shù)的改變并不敏感,這一點常被忽略。例如,隨機森林優(yōu)于梯度提升機器的地方就在于隨機森林更穩(wěn)定,GBM對超參數(shù)微小的變化就很敏感。結(jié)果自然隨機森林應(yīng)用的更廣泛。所以尋找能高效地改變超參數(shù)的方法將非常有用。
結(jié)語
現(xiàn)在我們對AutoML和神經(jīng)架構(gòu)搜索有了大致了解,在下一篇連載文章中,我們將近距離觀察谷歌的AutoML工具。
-
AI
+關(guān)注
關(guān)注
87文章
31490瀏覽量
269883 -
自動化
+關(guān)注
關(guān)注
29文章
5620瀏覽量
79529 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
132921
原文標題:揭秘AutoML和神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索,機器學(xué)習(xí)自動化真能普及大眾嗎?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何輕松掌握機器學(xué)習(xí)概念和在工業(yè)自動化中的應(yīng)用
機器視覺在工業(yè)自動化領(lǐng)域的前景應(yīng)用解析
物聯(lián)網(wǎng)怎么普及工業(yè)自動化
再牛的自動化車間都不能缺少搬運機器人
【AI學(xué)習(xí)】第3篇--人工神經(jīng)網(wǎng)絡(luò)
機器學(xué)習(xí)的相關(guān)資料下載
PlantStruxure協(xié)同自動化架構(gòu)選型指南
機器學(xué)習(xí)專家們每天都在做什么?如何讓機器學(xué)習(xí)自動化
受機器人普及化和自動化影響 高達70%的工作崗位面臨風(fēng)險
神經(jīng)架構(gòu)搜索詳解

隨著人工智能的落地 自動化機器學(xué)習(xí)方法AutoML應(yīng)運而生
機器流程自動化是什么
談?wù)勅绾螌?b class='flag-5'>機器學(xué)習(xí)引入自動化
以進化算法為搜索策略實現(xiàn)神經(jīng)架構(gòu)搜索的方法
DB4564_用于STM32微控制器的自動化機器學(xué)習(xí)(ML)工具






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論