") LSTM的核心構(gòu)成,實際中“門”的效果如何?
LSTM的核心構(gòu)成,實際中“門”的效果如何?
長短時記憶網(wǎng)絡(luò)(LSTM)是序列建模中被廣泛使用的循環(huán)結(jié)構(gòu),LSTM利用門結(jié)構(gòu)來控制模型中信息的傳輸量。但在實際操作中,LSTM中的門通常都處于“半開半關(guān)”的狀態(tài),沒有有效地控制信息的記憶與遺忘。為此,微軟亞洲研究院機器學習組提出了一種新的LSTM訓練方法,讓模型的門接近“二值化”——0或1,可以更準確地去除或者增加信息,進而提高模型的準確性、壓縮比以及可解釋性。
在很多實際場景中,深度學習模型都要面臨輸入長度不固定或者說輸入變長(variable-length input)的問題:例如在文本判別中,我們需要判斷一個句子的語義是積極還是消極的,這里輸入句子的長度是多種多樣的;在時間序列預測問題中,我們需要根據(jù)歷史上信息的變化預測當前的數(shù)值,而歷史信息的長度在不同時間點也是不同的。
普通的神經(jīng)網(wǎng)絡(luò)模型,比如卷積神經(jīng)網(wǎng)絡(luò)(CNN),無法解決此類輸入變長的問題。為此,人們首先提出了循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network),簡稱RNN。循環(huán)神經(jīng)網(wǎng)絡(luò)的核心是通過循環(huán)的方式,將歷史信息和當前信息不斷整合。例如,當你看美劇第N集時,需要通過對前N-1集的劇情的理解(記憶),以及當前這一集的劇情(當前輸入),更新自己對這部劇的理解。
在深度學習早期,RNN結(jié)構(gòu)在很多應用中取得了成功,但同時,這個簡單模型的瓶頸也不斷顯現(xiàn),這不僅涉及到優(yōu)化本身(如梯度爆炸、梯度消失)的問題,還有模型的復雜度的問題。例如一句話“小張已經(jīng)吃過飯了,小李呢?”,這句話是在詢問“小李是否吃過飯”,但在RNN看來,信息是從左到右不斷流入的,所以最后很難分清到底是在問小張是否過飯,還是在問小李是否吃過飯。于是帶有遺忘機制的新結(jié)構(gòu)就誕生了——長短時記憶網(wǎng)絡(luò)(Long Short Term Memory Network,LSTM)。
LSTM是由Hochreiter & Schmidhuber在1997年提出的RNN的一種特殊類型,可以學習長期依賴(long-term dependency)信息。在很多自然語言處理問題以及增強學習問題中,LSTM都取得相當巨大的成功,并得到了廣泛的使用。
LSTM的核心構(gòu)成
LSTM的關(guān)鍵構(gòu)成是一種被稱作“門”的結(jié)構(gòu),LSTM通過精心設(shè)計的門結(jié)構(gòu)去除或者增加信息。門是一種讓信息選擇通過的方法。一般情況下,在一個維度上,一個門是一個輸出范圍在0到1之間的數(shù)值,用來描述這個維度上的信息有多少量可以通過這個門——0代表“不許任何量通過”,1代表“全部通過”。
LSTM擁有三類門,分別是輸入門、輸出門、和遺忘門。
首先,LSTM需要通過遺忘門決定應該從歷史中丟棄什么信息。在每一維度,遺忘門會讀取歷史信息和當前信息,輸出一個在0到1之間的數(shù)值,1表示該維度所攜帶的歷史信息“完全保留”,0表示該維度所攜帶的歷史信息“完全舍棄”。例如在前面的例子中,當我們讀到“小張已經(jīng)吃過飯了,小李呢?”時,我們會把“主語”信息中的小張忘掉,這個操作就是通過遺忘門實現(xiàn)的。
然后,要確定需要把什么新信息存放在當前內(nèi)容中,例如前面的例子中,我們把小張“忘掉”后,需要把主語信息換成小李,這個“增加”操作是通過輸入門實現(xiàn)的。而對于不同任務而言,我們需要將當前信息整理輸出以方便做決策,這個整理輸出信息的過程,是通過輸出門實現(xiàn)的。LSTM如下圖右所示。
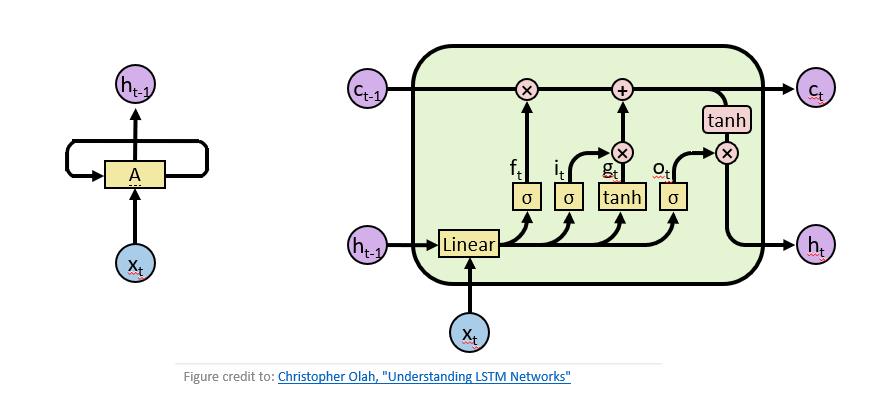
圖1 左:經(jīng)典循環(huán)神經(jīng)網(wǎng)絡(luò),右:長短時記憶網(wǎng)絡(luò)
在實際操作中,門是通過激活函數(shù)實現(xiàn)的:給定一個輸入值x,通過sigmoid變換,可以的到一個值域在[0,1]之間的值,若x大于0,則輸出值大于0.5,若x小于0,則輸出值小于0.5。
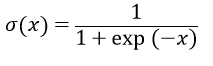
實際中“門”的效果如何?
門是否真的具有我們上述描述的意義呢?這也是我們這篇論文的出發(fā)點。為了探究這個問題,我們分析了IWSLT14德語-英語的翻譯任務,這個翻譯任務的模型是基于LSTM的端到端(sequence-to-sequence)結(jié)構(gòu)。
我們在訓練集中隨機抽取10000對平行語料,畫出在這些語料上LSTM輸入門與遺忘門的取值分布直方圖,如下圖所示。
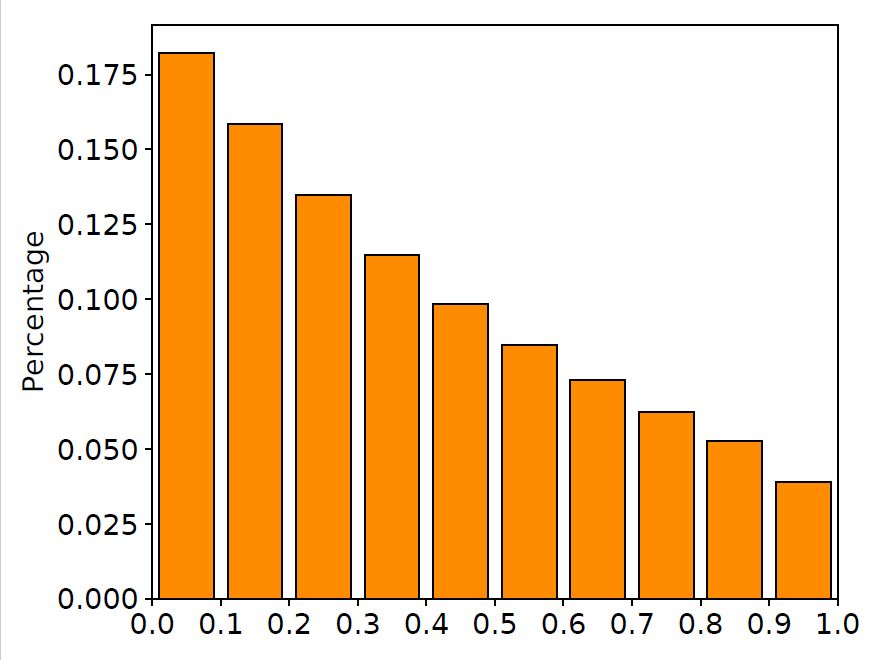
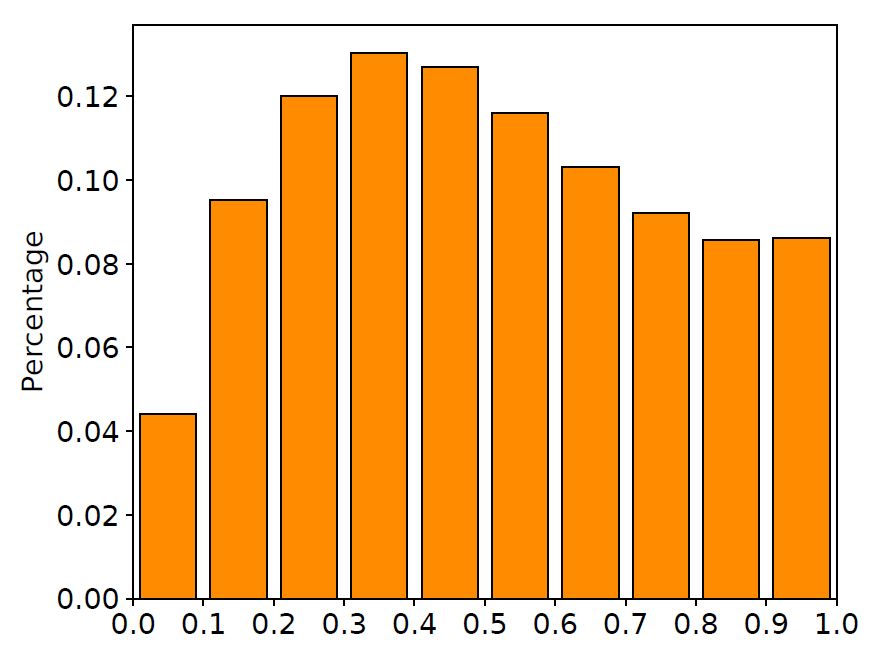
圖2 輸入門與遺忘門取值分布
從圖中可以清晰地看到,很大一部分門的取值都在0.5附近。換句話說,LSTM中的門都處于一種模棱兩可的“半開半關(guān)”的狀態(tài)。這種現(xiàn)象與LSTM網(wǎng)絡(luò)的設(shè)計有所出入:這些門并沒有顯式地控制信息的記憶與遺忘,而是以某種方式“記住”了所有的信息。與此同時,許多工作也指出LSTM中的大部分門都很難找到實際意義,這也進一步印證了我們的發(fā)現(xiàn)(相關(guān)討論詳見文末論文)。
“二值化”的門結(jié)構(gòu)
從上面的例子中可以看到,雖然LSTM在翻譯任務中取得了很好的效果,但是門并沒有想象中的明顯作用。同時也有一些前人的工作指出:LSTM的絕大多數(shù)維度并沒有明顯的可解釋信息。那么如何能夠?qū)W到一個更好的LSTM呢?這個問題引領(lǐng)我們?nèi)ネ诰蜷T結(jié)構(gòu)更大的價值:既然門是一個開關(guān)的概念,那么有沒有可能學習出一個接近“二值化”(binary-valued)的LSTM呢?一個接近“二值化”的門(binary-valued gate)有以下幾點好處:
1.門的作用更加符合真實意義下門的概念:通常意義下,門其實更多的是指其“開”、“關(guān)”兩種狀態(tài)。而我們?nèi)W習一個接近“二值化”的門的目的,也與LSTM的核心思想非常一致。
2. “二值化”更適合模型壓縮:如果門的值非常接近0或者1,說明sigmoid函數(shù)的輸入值x是個很大的正數(shù),或者很小的負數(shù)。這時輸入值x的微小改變對輸出值影響甚微,由于輸入值x通常也是參數(shù)化的,所以“二值化”可以方便對于這部分參數(shù)的壓縮。通過實驗我們發(fā)現(xiàn),即使達到很大的壓縮比,我們的模型仍然有很好的效果。
3. “二值化”帶來更好的可解釋性:要求門的輸出值接近0或1,會對模型本身有更高的要求。在信息取舍的過程中,某個節(jié)點保留或者遺忘掉該維度全部信息。我們認為這種學習得到的門更能體現(xiàn)自然語言的結(jié)構(gòu)、內(nèi)容以及內(nèi)部邏輯,如前面提到的關(guān)于吃飯的例子。
如何讓訓練后的模型的門接近二值化?我們借鑒了ICLR17上關(guān)于變分法(variantional method)的一個新進展:Categorical Reparameterization with Gumbel-Softmax。簡單而言,將門的輸出“二值化”的最好辦法是訓練一個隨機神經(jīng)網(wǎng)絡(luò)(stochastic neural network),其中門的輸出是一個概率p,在伯努利分布中得到0/1的隨機采樣,借此去得到不同位置取0/1時的損失,進而優(yōu)化參數(shù)得到最優(yōu)p。而在隱層節(jié)點上進行離散操作時,梯度回傳遇到問題,我們采用的方法就是用Gumbel-Softmax Estimator近似多項分布的概率密度函數(shù),進而達到既可學習又方便優(yōu)化的目的(具體方法見文末論文)。我們將這一方法命名為Gumbel-Gate LSTM,簡稱G2-LSTM。
準確率、可壓縮性與可解釋性
我們在LSTM網(wǎng)絡(luò)的兩個經(jīng)典應用——語言模型和機器翻譯上測試了這一方法,在準確率、可壓縮性與可解釋性三方面與之前的LSTM模型進行比較。
準確率
語言模型是LSTM網(wǎng)絡(luò)最基本的應用之一。語言模型要求LSTM網(wǎng)絡(luò)根據(jù)一句話當中之前已知的詞語準確預測下一個詞的選取。我們使用廣泛使用的Penn Treebank數(shù)據(jù)集作為訓練語料,該訓練集總共包含約一百萬個詞。語言模型一般使用perplexity作為評價指標,perplexity越小說明模型越精準,實驗結(jié)果如下圖所示。
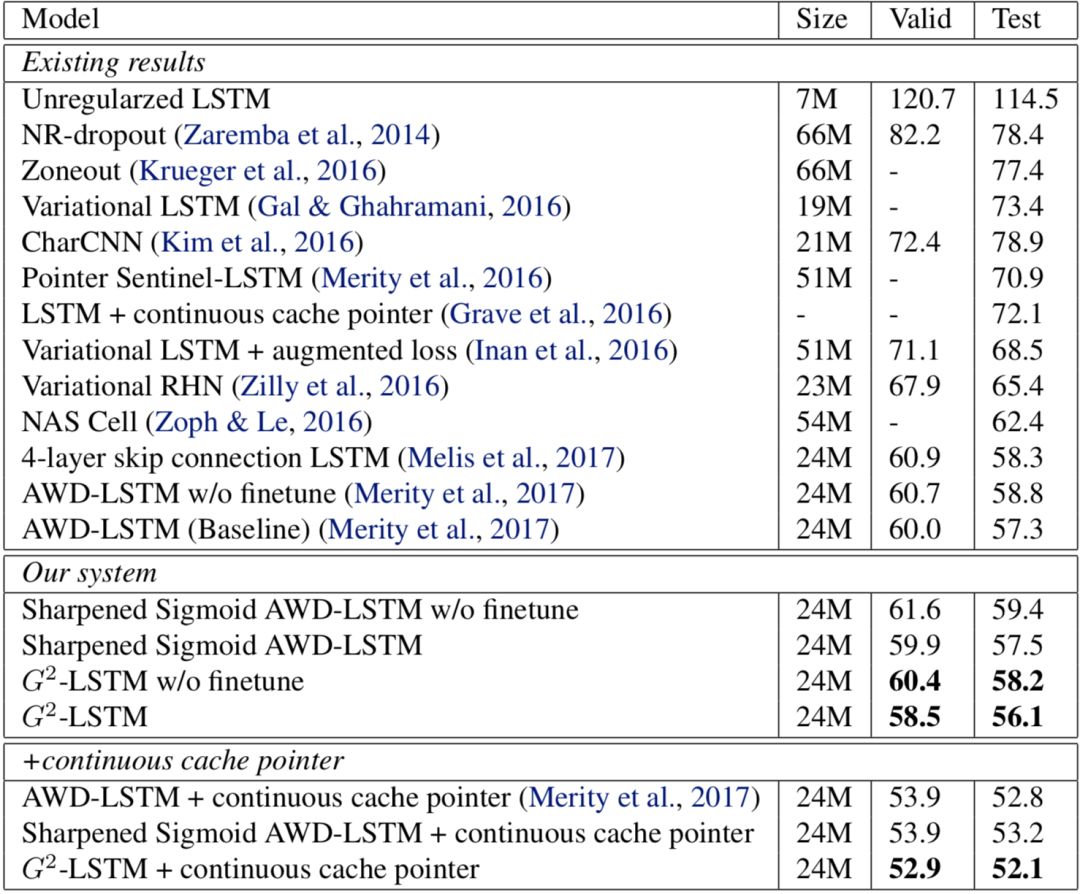
圖3語言模型實驗結(jié)果
從圖中可以看到,通過將LSTM中的門進行“二值化”,模型的表現(xiàn)有所提升:我們模型的perplexity為56.1,與基線模型的perplexity57.3相比,有1.2的提升。而在加入了測試時后處理(continuous cache pointer)的情況下,我們的模型達到了52.1,較基線模型的52.8有0.7的提升。
機器翻譯是目前深度學習應用最為成功的領(lǐng)域之一,而基于LSTM的端到端(sequence-to-sequence)結(jié)構(gòu)是機器翻譯中被廣泛應用的結(jié)構(gòu)。我們在兩個公開數(shù)據(jù)集:IWSLT14德語到英語數(shù)據(jù)集和WMT14英語到德語數(shù)據(jù)集上測試了我們的方法。IWSLT14德英數(shù)據(jù)集包含約15萬句平行語料,WMT14英德數(shù)據(jù)集包含約450萬句平行語料。對于IWSLT14德英數(shù)據(jù)集,我們使用了兩層編碼器-解碼器(encoder-decoder)結(jié)構(gòu);而由于WMT14英德數(shù)據(jù)集大小更大,我們使用了更大的三層編碼器-解碼器結(jié)構(gòu)。機器翻譯任務一般由測試集上的BLEU值作為最后的評價標準,BLEU值越高說明翻譯質(zhì)量越高,機器翻譯的實驗結(jié)果下圖所示。
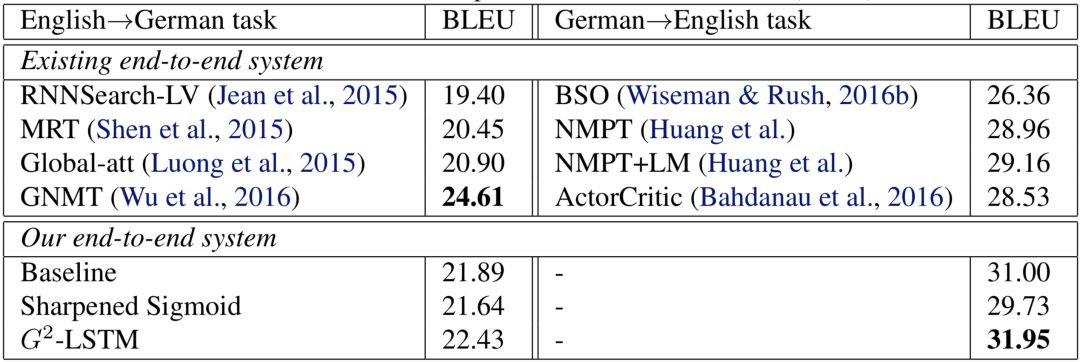
圖4機器翻譯實驗結(jié)果
與語言模型的實驗結(jié)論類似,我們的模型在機器翻譯上的表現(xiàn)同樣有所提升:在IWSLT14德英數(shù)據(jù)集上,我們模型的BLEU值達到了31.95,比基線模型高0.95;而在WMT14德英數(shù)據(jù)集上,我們模型的BLEU值為22.43,比基線模型高0.54。
可壓縮性
將模型進行“二值化”能夠使得我們的模型對于參數(shù)的擾動更加魯棒。因此,我們比較了不同模型在參數(shù)壓縮下的性能。我們采用了兩種方式對與門相關(guān)的參數(shù)進行壓縮:
精度壓縮。我們首先限制了參數(shù)的精度(使用round函數(shù)),例如當公式中的r取0.1時,所有的模型參數(shù)都僅被保留一位小數(shù)精度。在這之后,我們進一步控制了參數(shù)取值的范圍(使用clip函數(shù)),將所有取值大于c的參數(shù)都變?yōu)閏,將所有取值小于-c的參數(shù)都變?yōu)?c。由于兩個任務的參數(shù)取值范圍不太相同,在語言模型上,我們設(shè)置r=0.2,c=0.4;在機器翻譯上,我們設(shè)置r=0.5,c=1.0。這使得所有的參數(shù)最終將只能取5個值
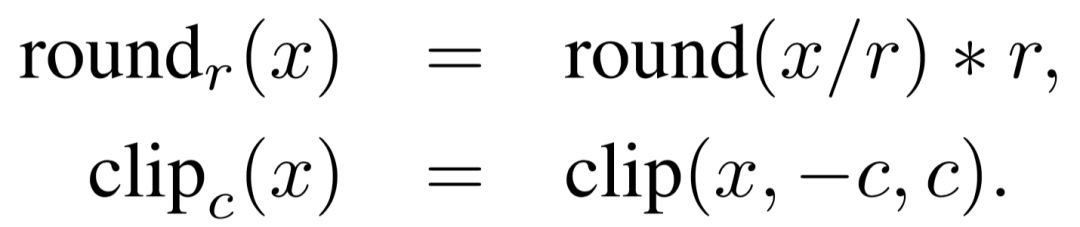
低秩壓縮。我們利用奇異值分解(singular value decomposition),將參數(shù)矩陣分解為兩個低秩矩陣的乘積,這能夠顯著減少模型大小,并且能夠加快矩陣乘法,從而提高模型運行速度。
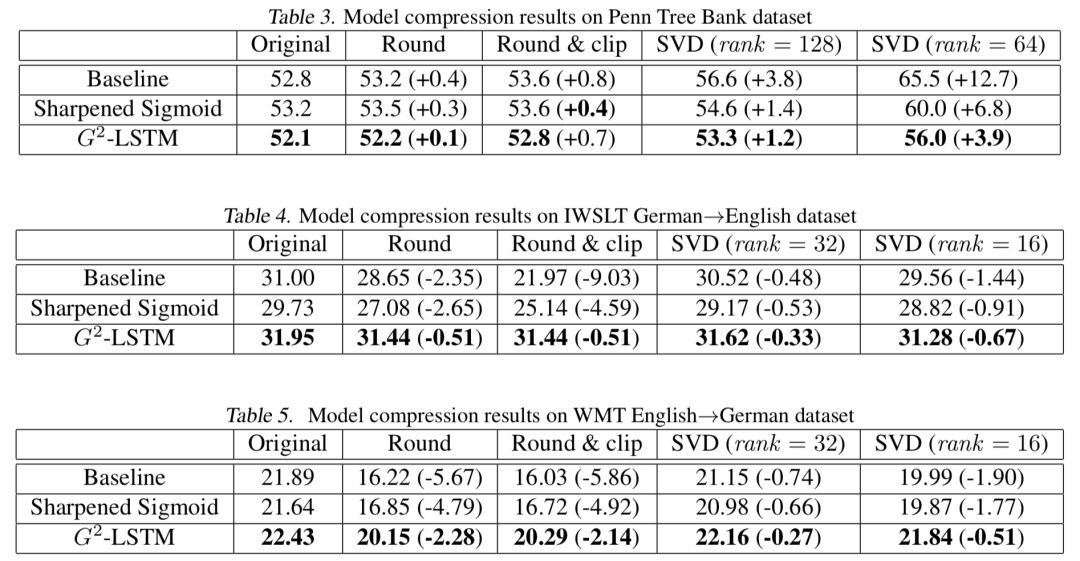
圖5壓縮后實驗結(jié)果
具體的實驗結(jié)果如上圖所示。我們可以看到,不論在哪種情況下,我們的模型都顯著優(yōu)于壓縮后的模型,這說明這一模型的魯棒性較之前的LSTM有大幅度的提升。
可解釋性
除了比較數(shù)值實驗結(jié)果外,我們進一步地觀察了模型中門的取值,用同樣的語料畫出了我們的模型中門的取值分布直方圖,如下圖所示。
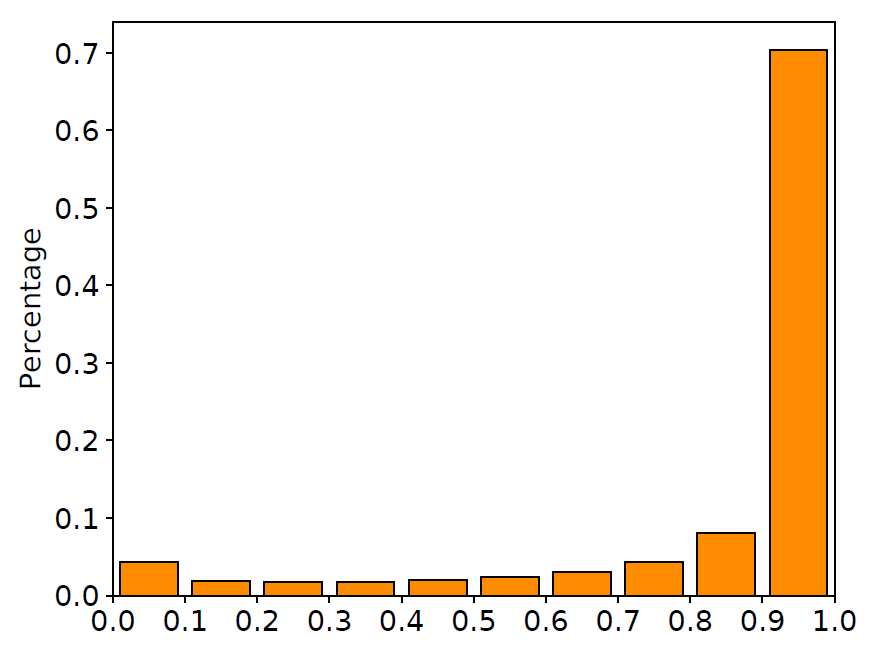
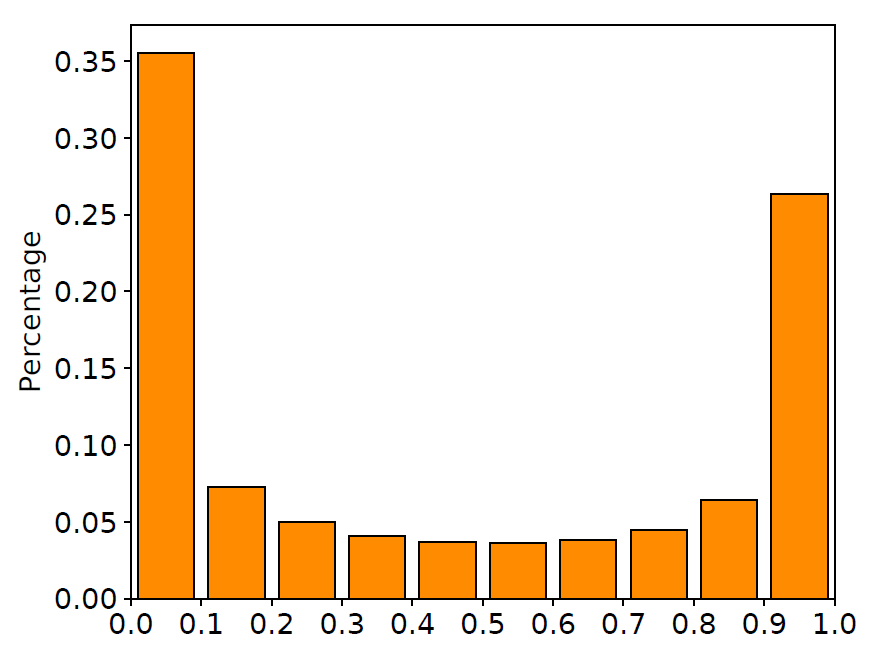
圖6 輸入門與遺忘門取值分布
從圖中我們可以看到,大部分輸入門的取值都在1.0附近,這意味著我們的模型接受了大部分的輸入信息;而遺忘門的取值都集中在0.0或1.0附近,這意味著我們訓練后得到的遺忘門確實做到了選擇性地記憶/遺忘信息。這些觀察都證明了我們的訓練算法確實能夠讓門的取值更加靠近0/1兩端。
除了觀察網(wǎng)絡(luò)中門的取值在數(shù)據(jù)集上的分布情況,我們還在訓練集中隨機抽取的幾條句子上觀察了每個時刻門的平均取值,如下圖所示。
圖7樣例分析
從圖中我們可以看到,傳統(tǒng)LSTM網(wǎng)絡(luò)的輸入門取值較為平均,并且對于一些有意義的詞(例如“wrong”),傳統(tǒng)LSTM的平均輸入門取值都較小,這很不利于模型獲取關(guān)于這個詞的信息,最終將使模型產(chǎn)生不好的翻譯效果。而在我們的模型中,輸入門的取值都很大,這意味著大部分詞的信息都被LSTM網(wǎng)絡(luò)接受。另一方面,在我們提出的模型中,遺忘門取值較小的詞都是一些功能詞,例如連詞(“and”)或標點符號,這說明我們的模型能夠正確判斷句子的邊界,來清空模型的之前的記憶,來獲取新的信息。
了解更多細節(jié),請訪問下面鏈接或點擊閱讀原文訪問我們的論文:
Zhuohan Li, Di He, Fei Tian, Wei Chen, Tao Qin,Liwei Wang, and Tie-Yan Liu. "Towards Binary-Valued Gates for Robust LSTM Training."ICML 2018.
論文鏈接:https://arxiv.org/abs/1806.02988
作者簡介:
李卓翰,北京大學信息科學技術(shù)學院2015級本科生,在微軟亞洲研究院機器學習組實習。主要研究方向為機器學習。主要關(guān)注深度學習算法設(shè)計,及其在不同任務場景下的應用。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101049 -
機器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14922 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13384
原文標題:ICML 2018 | 訓練可解釋、可壓縮、高準確率的LSTM
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何實現(xiàn)在圖標圖像中實現(xiàn)一個點,效果如下圖
LabVIEW中圖像濾波Vi以及實現(xiàn)效果如何實現(xiàn)
當無凸輪軸發(fā)動機真的裝在車上時,究竟實際效果如何?
i9-9900K開蓋 使用了釬焊散熱后實際效果如何
一種具有強記憶力的 E3D-LSTM網(wǎng)絡(luò),強化了LSTM的長時記憶能力

EE-26:AD184x Sigma Delta轉(zhuǎn)換器:它們使用直流輸入的效果如何?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論