") IO請(qǐng)求在block layer的來(lái)龍去脈
IO請(qǐng)求在block layer的來(lái)龍去脈
所謂請(qǐng)求合并就是將進(jìn)程內(nèi)或者進(jìn)程間產(chǎn)生的在物理地址上連續(xù)的多個(gè)IO請(qǐng)求合并成單個(gè)IO請(qǐng)求一并處理,從而提升IO請(qǐng)求的處理效率。在前面有關(guān)通用塊層介紹的系列文章當(dāng)中我們或多或少地提及了IO請(qǐng)求合并的概念,本篇我們從頭集中梳理IO請(qǐng)求在block layer的來(lái)龍去脈,以此來(lái)增強(qiáng)對(duì)IO請(qǐng)求合并的理解。首先來(lái)看一張圖,下面的圖展示了IO請(qǐng)求數(shù)據(jù)由用戶進(jìn)程產(chǎn)生,到最終持久化存儲(chǔ)到物理存儲(chǔ)介質(zhì),其間在內(nèi)核空間所經(jīng)歷的數(shù)據(jù)流以及IO請(qǐng)求合并可能的觸發(fā)點(diǎn)。
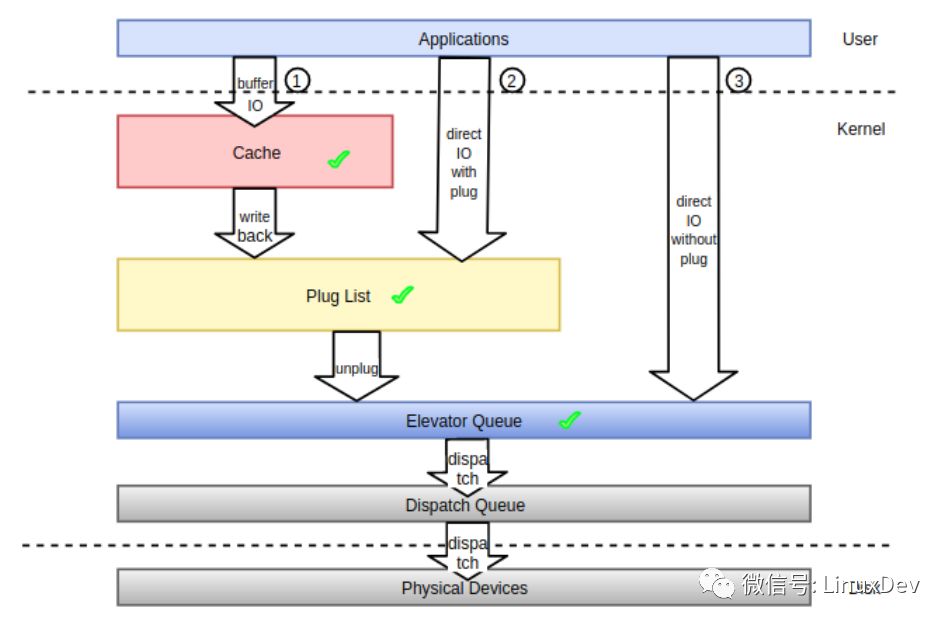
從內(nèi)核的角度而言,進(jìn)程產(chǎn)生的IO路徑主要有圖中①②③所示的三條:
①緩存IO, 對(duì)應(yīng)圖中的路徑①,系統(tǒng)中絕大部分IO走的這種形式,充分利用filesystem 層的page cache所帶來(lái)的優(yōu)勢(shì), 應(yīng)用程序產(chǎn)生的IO經(jīng)系統(tǒng)調(diào)用落入page cache之后便可以直接返回,page cache中的緩存數(shù)據(jù)由內(nèi)核回寫(xiě)線程在適當(dāng)時(shí)機(jī)負(fù)責(zé)同步到底層的存儲(chǔ)介質(zhì)之上,當(dāng)然應(yīng)用程序也可以主動(dòng)發(fā)起回寫(xiě)過(guò)程(如fsync系統(tǒng)調(diào)用)來(lái)確保數(shù)據(jù)盡快同步到存儲(chǔ)介質(zhì)上,從而避免系統(tǒng)崩潰或者掉電帶來(lái)的數(shù)據(jù)不一致性。緩存IO可以帶來(lái)很多好處,首先應(yīng)用程序?qū)O丟給page cache之后就直接返回了,避免了每次IO都將整個(gè)IO協(xié)議棧走一遍,從而減少了IO的延遲。其次,page cache中的緩存最后以頁(yè)或塊為單位進(jìn)行回寫(xiě),并非應(yīng)用程序向page cache中提交了幾次IO, 回寫(xiě)的時(shí)候就需要往通用塊層提交幾次IO, 這樣在提交時(shí)間上不連續(xù)但在空間上連續(xù)的小塊IO請(qǐng)求就可以合并到同一個(gè)緩存頁(yè)中一并處理。再次,如果應(yīng)用程序之前產(chǎn)生的IO已經(jīng)在page cache中,后續(xù)又產(chǎn)生了相同的IO,那么只需要將后到的IO覆蓋page cache中的舊IO,這樣一來(lái)如果應(yīng)用程序頻繁的操作文件的同一個(gè)位置,我們只需要向底層存儲(chǔ)設(shè)備提交最后一次IO就可以了。最后,應(yīng)用程序?qū)懭氲絧age cache中的緩存數(shù)據(jù)可以為后續(xù)的讀操作服務(wù),讀取數(shù)據(jù)的時(shí)候先搜索page cache,如果命中了則直接返回,如果沒(méi)命中則從底層讀取并保存到page cache中,下次再讀的時(shí)候便可以從page cache中命中。
②非緩存IO(帶蓄流),對(duì)應(yīng)圖中的路徑②,這種IO繞過(guò)文件系統(tǒng)層的cache。用戶在打開(kāi)要讀寫(xiě)的文件的時(shí)候需要加上“O_DIRECT”標(biāo)志,意為直接IO,不讓文件系統(tǒng)的page cache介入。從用戶角度而言,應(yīng)用程序能直接控制的IO形式除了上面提到的“緩存IO”,剩下的IO都走的這種形式,就算文件打開(kāi)時(shí)加上了 ”O(jiān)_SYNC” 標(biāo)志,最終產(chǎn)生的IO也會(huì)進(jìn)入蓄流鏈表(圖中的Plug List)。如果應(yīng)用程序在用戶空間自己做了緩存,那么就可以使用這種IO方式,常見(jiàn)的如數(shù)據(jù)庫(kù)應(yīng)用。
③非緩存IO(不帶蓄流),對(duì)應(yīng)圖中的路徑③,內(nèi)核通用塊層的蓄流機(jī)制只給內(nèi)核空間提供了接口來(lái)控制IO請(qǐng)求是否蓄流,用戶空間進(jìn)程沒(méi)有辦法控制提交的IO請(qǐng)求進(jìn)入通用塊層的時(shí)候是否蓄流。嚴(yán)格的說(shuō)用戶空間直接產(chǎn)生的IO都會(huì)走蓄流路徑,哪怕是IO的時(shí)候附上了“O_DIRECT” 和 ”O(jiān)_SYNC”標(biāo)志(可以參考《Linux通用塊層介紹(part1: bio層)》中的蓄流章節(jié)),用戶間接產(chǎn)生的IO,如文件系統(tǒng)日志數(shù)據(jù)、元數(shù)據(jù),有的不會(huì)走蓄流路徑而是直接進(jìn)入調(diào)度隊(duì)列盡快得到調(diào)度。注意一點(diǎn),通用塊層的蓄流只提供機(jī)制和接口而不提供策略,至于需不需要蓄流、何時(shí)蓄流完全由內(nèi)核中的IO派發(fā)者決定。
應(yīng)用程序不管使用圖中哪條IO路徑,內(nèi)核都會(huì)想方設(shè)法對(duì)IO進(jìn)行合并。內(nèi)核為促進(jìn)這種合并,在IO協(xié)議棧上設(shè)置了三個(gè)最佳狙擊點(diǎn):
lCache (頁(yè)高速緩存)
lPlug List (蓄流鏈表)
lElevator Queue (調(diào)度隊(duì)列)
cache 合并
IO處在文件系統(tǒng)層的page cache中時(shí)只有IO數(shù)據(jù),還沒(méi)有IO請(qǐng)求(bio 或 request),只有page cache 在讀寫(xiě)的時(shí)候才會(huì)產(chǎn)生IO請(qǐng)求。本文主要介紹IO請(qǐng)求在通用塊層的合并,因此對(duì)于IO 在cache 層的合并只做現(xiàn)象分析,不深入到內(nèi)部邏輯和代碼細(xì)節(jié)。如果是緩存IO,用戶進(jìn)程提交的寫(xiě)數(shù)據(jù)會(huì)積聚在page cache 中。cache 保存IO數(shù)據(jù)的基本單位為page,大小一般為4K, 因此cache 又叫“頁(yè)高速緩存”, 用戶進(jìn)程提交的小塊數(shù)據(jù)可以緩存到cache中的同一個(gè)page中,最后回寫(xiě)線程將一個(gè)page中的數(shù)據(jù)一次性提交給通用塊層處理。以dd程序?qū)懸粋€(gè)裸設(shè)備為例,每次寫(xiě)1K數(shù)據(jù),連續(xù)寫(xiě)16次:
dd if=/dev/zero of=/dev/sdb bs=1k count=16
通過(guò)blktrace觀測(cè)的結(jié)果為:
blktrace -d /dev/sdb -o - | blkparse -i -
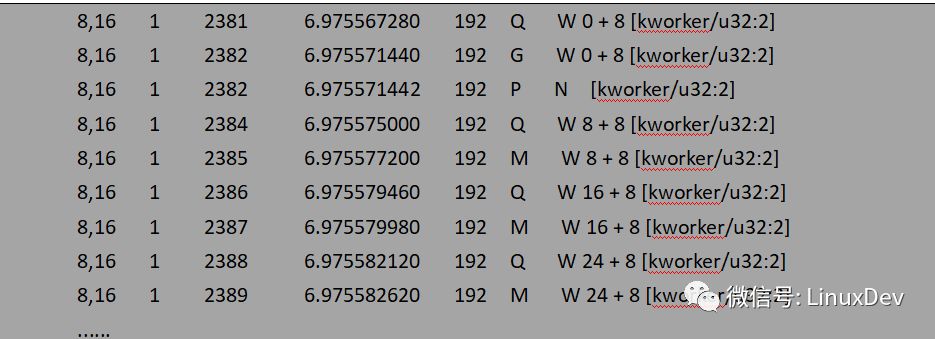
bio請(qǐng)求在通用塊層的處理情況主要是通過(guò)第六列反映出來(lái)的,如果對(duì)blkparse的輸出不太了解,可以 man 一下blktrace。對(duì)照每一行的輸出來(lái)看看應(yīng)用程序產(chǎn)生的寫(xiě)IO經(jīng)由page cache之后是如何派發(fā)到通用塊層的:
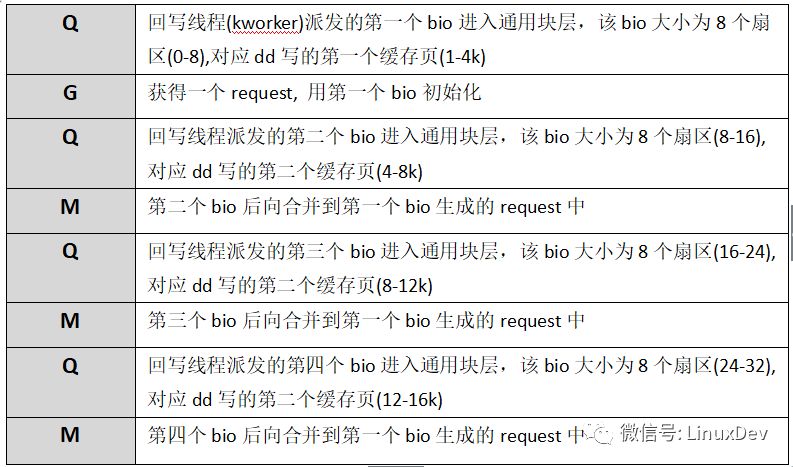
現(xiàn)階段只關(guān)注IO是如何從page cache中派發(fā)到通用塊層的,所以后面的瀉流、派發(fā)過(guò)程沒(méi)有貼出來(lái)。回寫(xiě)線程–kworker以8個(gè)扇區(qū)(扇區(qū)大小為512B, 8個(gè)扇區(qū)為4K對(duì)應(yīng)一個(gè)page大小)為單位將dd程序讀寫(xiě)的1K數(shù)據(jù)塊派發(fā)給通用塊層處理。dd程序?qū)懥?6次,回寫(xiě)線程只寫(xiě)了4次(對(duì)應(yīng)四次Q),page cache的緩存功能有效的合并了應(yīng)用程序直接產(chǎn)生的IO數(shù)據(jù)。文件系統(tǒng)層的page cache對(duì)讀IO也有一定的作用,帶緩存的讀IO會(huì)觸發(fā)文件系統(tǒng)層的預(yù)讀機(jī)制,所謂預(yù)讀有專門的預(yù)讀算法,通過(guò)判斷用戶進(jìn)程IO趨勢(shì),提前將存儲(chǔ)介質(zhì)上的數(shù)據(jù)塊讀入page cache中,下次讀操作來(lái)時(shí)可以直接從page cache中命中,而不需要每次都發(fā)起對(duì)塊設(shè)備的讀請(qǐng)求。還是以dd程序讀一個(gè)裸設(shè)備為例,每次讀1K數(shù)據(jù),連續(xù)讀16次:
dd if=/dev/sdb of=/dev/zero bs=1K count=16
通過(guò)blktrace觀測(cè)的結(jié)果為:
blktrace -d /dev/sdb -o - | blkparse -i -
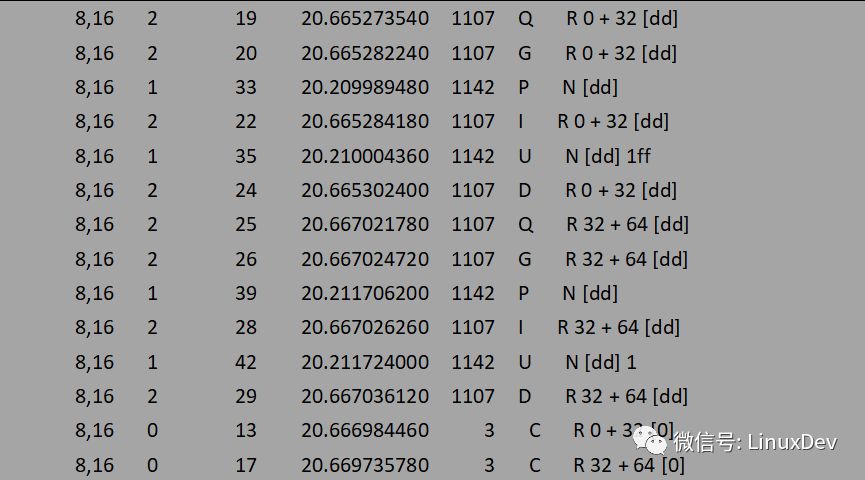
同樣只關(guān)注IO是如何從上層派發(fā)到通用塊層的,不關(guān)注IO在通用塊層的具體情況,先不考慮P,I,U,D,C等操作,那么上面的輸出可以簡(jiǎn)單解析為:
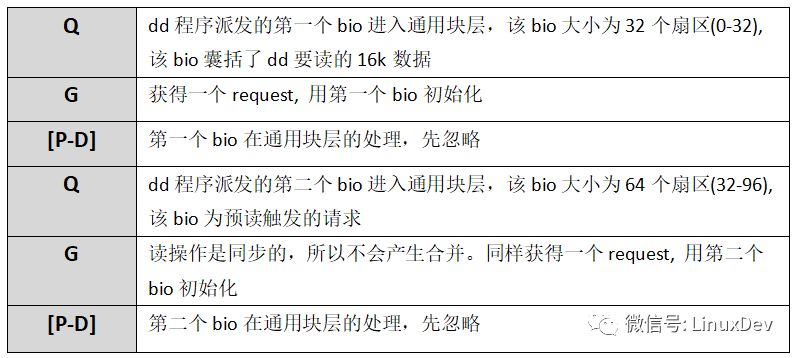
讀操作是同步的,所以觸發(fā)讀請(qǐng)求的是dd進(jìn)程本身。dd進(jìn)程發(fā)起了16次讀操作,總共讀取16K數(shù)據(jù),但是預(yù)讀機(jī)制只向底層發(fā)送了兩次讀請(qǐng)求,分別為0+32(16K), 32+64(32K),總共預(yù)讀了16 + 32 = 48K數(shù)據(jù),并保存到cache中,多預(yù)讀的數(shù)據(jù)可以為后續(xù)的讀操作服務(wù)。
plug 合并
在閱讀本節(jié)之前可以先回顧下linuxer公眾號(hào)中介紹bio和request的系列文章,熟悉IO請(qǐng)求在通用塊層的處理,以及蓄流(plug)機(jī)制的原理和接口。特別推薦宋寶華老師寫(xiě)的《文件讀寫(xiě)(BIO)波瀾壯闊的一生》,通俗易懂地介紹了一個(gè)文件io的生命周期。
每個(gè)進(jìn)程都有一個(gè)私有的蓄流鏈表,進(jìn)程在往通用塊層派發(fā)IO之前如果開(kāi)啟了蓄流功能,那么IO請(qǐng)求在被發(fā)送給IO調(diào)度器之前都保存在蓄流鏈表中,直到泄流(unplug)的時(shí)候才批量交給調(diào)度器。蓄流的主要目的就是為了增加請(qǐng)求合并的機(jī)會(huì),bio在進(jìn)入蓄流鏈表之前會(huì)嘗試與蓄流鏈表中保存的request進(jìn)行合并,使用的接口為blk_attempt_plug_merge(). 本文是基于內(nèi)核4.17分析的,源碼來(lái)源于4.17-rc1。

代碼遍歷蓄流鏈表中的request,使用blk_try_merge找到一個(gè)能與bio合并的request并判斷合并類型,蓄流鏈表中的合并類型有三種:ELEVATOR_BACK_MERGE,ELEVATOR_FRONT_MERGE,ELEVATOR_DISCARD_MERGE。普通文件IO操作只會(huì)進(jìn)行前兩種合并,第三種是丟棄操作的合并,不是普通的IO的合并,故不討論。
bio后向合并 (ELEVATOR_BACK_MERGE)
為了驗(yàn)證IO請(qǐng)求在通用塊層的各種合并形式,準(zhǔn)備了以下測(cè)試程序,該測(cè)試程序使用內(nèi)核原生支持的異步IO引擎,可異步地向內(nèi)核一次提交多個(gè)IO請(qǐng)求。為了減少page cache和文件系統(tǒng)的干擾,使用O_DIRECT的方式直接向裸設(shè)備派發(fā)IO。
iotc.c
...
/* dispatch 3 4k-size ios using the io_type specified by user */
#define NUM_EVENTS 3
#define ALIGN_SIZE 4096
#define WR_SIZE 4096
enum io_type {
SEQUENCE_IO,/* dispatch 3 ios: 0-4k(0+8), 4-8k(8+8), 8-12k(16+8) */
REVERSE_IO,/* dispatch 3 ios: 8-12k(16+8), 4-8k(8+8),0-4k(0+8) */
INTERLEAVE_IO, /* dispatch 3 ios: 8-12k(16+8), 0-4k(0+8),4-8k(8+8) */ ,
IO_TYPE_END
};
int io_units[IO_TYPE_END][NUM_EVENTS] = {
{0, 1, 2},/* corresponding to SEQUENCE_IO */
{2, 1, 0},/* corresponding to REVERSE_IO */
{2, 0, 1}/* corresponding to INTERLEAVE_IO */
};
char *io_opt = "srid:";/* acceptable options */
int main(int argc, char *argv[])
{
int fd;
io_context_t ctx;
struct timespec tms;
struct io_event events[NUM_EVENTS];
struct iocb iocbs[NUM_EVENTS],
*iocbp[NUM_EVENTS];
int i, io_flag = -1;;
void *buf;
bool hit = false;
char *dev = NULL, opt;
/* io_flag and dev got set according the options passedby user , don’t paste the code of parsing here to shrink space */
fd = open(dev, O_RDWR | __O_DIRECT);
/* we can dispatch 32 IOs at 1 systemcall */
ctx = 0;
io_setup(32, &ctx);
posix_memalign(&buf,ALIGN_SIZE,WR_SIZE);
/* prepare IO request according to io_type */
for (i = 0; i < NUM_EVENTS; iocbp[i] = iocbs + i, ++i)
io_prep_pwrite(&iocbs[i], fd, buf, WR_SIZE,io_units[io_flag][i] * WR_SIZE);
/* submit IOs using io_submit systemcall */
io_submit(ctx, NUM_EVENTS, iocbp);
/* get the IO result with a timeout of 1S*/
tms.tv_sec = 1;
tms.tv_nsec = 0;
io_getevents(ctx, 1, NUM_EVENTS, events, &tms);
return 0;
}
測(cè)試程序接收兩個(gè)參數(shù),第一個(gè)為作用的設(shè)備,第二個(gè)為IO類型,定義了三種IO類型:SEQUENCE_IO(順序),REVERSE_IO(逆序),INTERLEAVE_IO(交替)分別用來(lái)驗(yàn)證蓄流階段的bio后向合并、前向合并和泄流階段的request合并。為了減少篇幅,此處貼出的源碼刪除了選項(xiàng)解析和容錯(cuò)處理,只保留主干,原版位于:https://github.com/liuzhengyuan/iotc。
為驗(yàn)證bio在蓄流階段的后向合并,用上面的測(cè)試程序iotc順序派發(fā)三個(gè)寫(xiě)io:
# ./iotc-d/dev/sdb-s
-d 指定作用的設(shè)備sdb, -s 指定IO方式為SEQUENCE_IO(順序),表示順序發(fā)起三個(gè)寫(xiě)請(qǐng)求: bio0(0 + 8), bio1(8 + 8), bio2(16 + 8)。通過(guò)blktrace來(lái)觀察iotc派發(fā)的bio請(qǐng)求在通用塊層蓄流鏈表中的合并情況:
blktrace -d /dev/sdb -o - | blkparse -i -
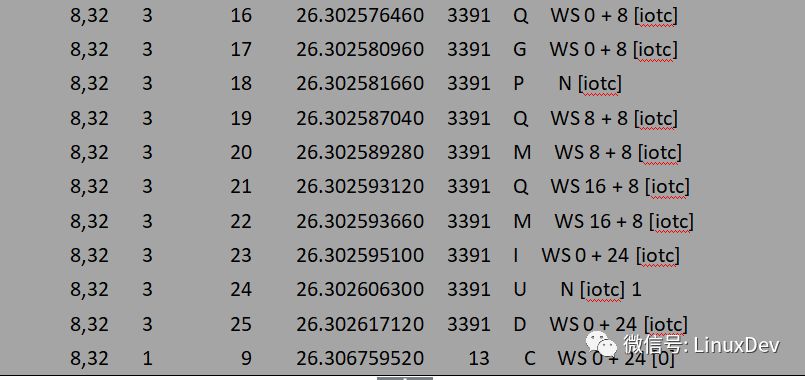
上面的輸出可以簡(jiǎn)單解析為:

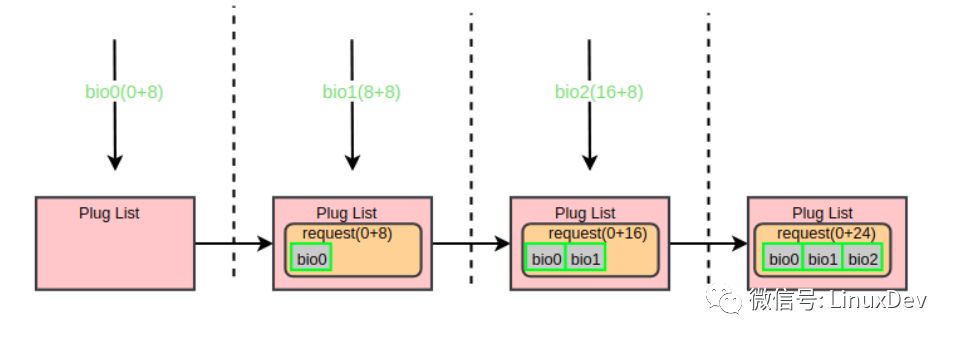
第一個(gè)bio(bio0)進(jìn)入通用塊層時(shí),此時(shí)蓄流鏈表為空,于是申請(qǐng)一個(gè)request并用bio0初始化,再將request添加進(jìn)蓄流鏈表,同時(shí)告訴blktrace蓄流已正式工作。第二個(gè)bio(bio1)到來(lái)的時(shí)候會(huì)走blk_attempt_plug_merge的邏輯,嘗試調(diào)用bio_attempt_back_merge與蓄流鏈表中的request合并,發(fā)現(xiàn)正好能合并到第一個(gè)bio所在的request尾部,于是直接返回。第三個(gè)bio(bio2)的處理與第二個(gè)同理。通過(guò)蓄流合并之后,三個(gè)IO請(qǐng)求最終合并成了一個(gè)request(0 + 24)。用一副圖來(lái)展示整個(gè)合并過(guò)程:
bio前向合并 (ELEVATOR_FRONT_MERGE)
為驗(yàn)證bio在蓄流階段的前向合并,使用iotc逆序派發(fā)三個(gè)寫(xiě)io:
# ./iotc-d/dev/sdb-r
-r 指定IO方式為REVERSE_IO(逆序),表示逆序發(fā)起三個(gè)寫(xiě)請(qǐng)求: bio0(16 + 8),bio1(8 + 8), bio2(0 + 8)。blktrace的觀察結(jié)果為:
blktrace -d /dev/sdb -o - | blkparse -i -
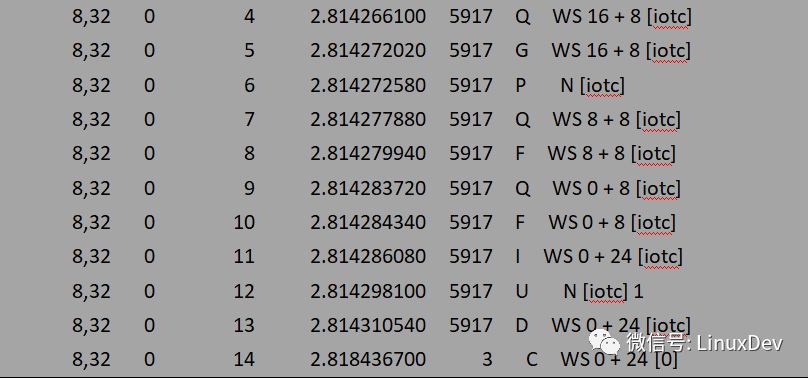
上面的輸出可以簡(jiǎn)單解析為:

與前面的后向合并相比,唯一的區(qū)別是合并方式由之前的”M”變成了現(xiàn)在的”F”,即在blk_attempt_plug_merge中走的是bio_attempt_front_merge分支。通過(guò)下面的圖來(lái)展示前向合并過(guò)程:
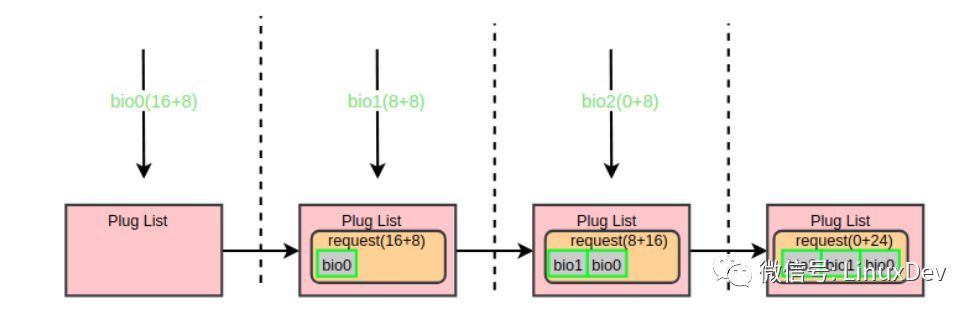
“plug 合并”不會(huì)做request與request的進(jìn)階合并,蓄流鏈表中的request之間的合并會(huì)在泄流的時(shí)候做,即在下面介紹的“elevator 合并”中做。
elevator 合并
上面講到的蓄流鏈表合并是為進(jìn)程內(nèi)的IO請(qǐng)求服務(wù)的,每個(gè)進(jìn)程只往自己的蓄流鏈表中提交IO請(qǐng)求,進(jìn)程間的蓄流鏈表相互獨(dú)立,互不干涉。但是,多個(gè)進(jìn)程可以同時(shí)對(duì)一個(gè)設(shè)備發(fā)起IO請(qǐng)求,那么通用塊層還需要提供一個(gè)節(jié)點(diǎn),讓進(jìn)程間的IO請(qǐng)求有機(jī)會(huì)進(jìn)行合并。一個(gè)塊設(shè)備有且僅有一個(gè)請(qǐng)求隊(duì)列(調(diào)度隊(duì)列),所有對(duì)塊設(shè)備的IO請(qǐng)求都需要經(jīng)過(guò)這個(gè)公共節(jié)點(diǎn),因此調(diào)度隊(duì)列(Elevator Queue)是IO請(qǐng)求合并的另一個(gè)節(jié)點(diǎn)。先回顧一下通用塊層處理IO請(qǐng)求的核心函數(shù):blk_queue_bio(), 上層派發(fā)的bio請(qǐng)求都會(huì)流經(jīng)該函數(shù),或?qū)io蓄流到Plug List,或?qū)io合并到Elevator Queue, 或?qū)io生成request直接插入到Elevator Queue。blk_queue_bio()的主要處理流程為:
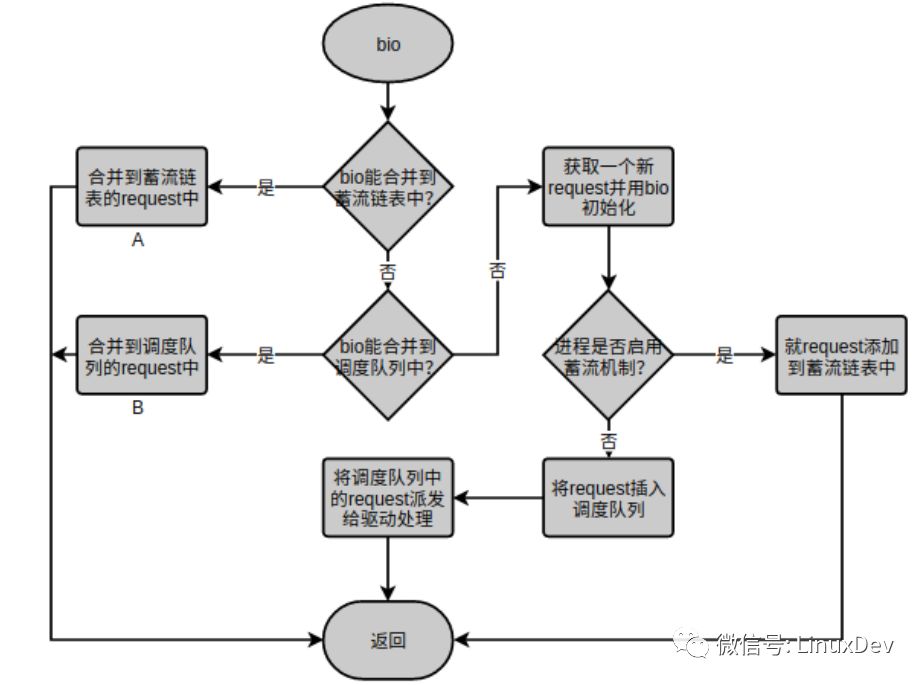
其中”A”標(biāo)識(shí)的“合并到蓄流鏈表的request中”就是上一章介紹的“plug 合并”。bio如果不能合并到蓄流鏈表中接下來(lái)會(huì)嘗試合并到“B”標(biāo)識(shí)的”合并到調(diào)度隊(duì)列的request中”。”合并到調(diào)度隊(duì)列的request中”只是“elevator 合并”的第一個(gè)點(diǎn)。你可能已經(jīng)發(fā)現(xiàn)了blk_queue_bio()將bio合并到蓄流鏈表或者將request添加進(jìn)蓄流鏈表之后就沒(méi)管了,從路徑①可以發(fā)現(xiàn)蓄流鏈表中的request最終都是要交給電梯調(diào)度隊(duì)列的,這正是”elevator 合并”的第二個(gè)點(diǎn),關(guān)于泄流的時(shí)機(jī)請(qǐng)參考我之前寫(xiě)的《Linux通用塊層介紹(part1: bio層)》。下面分別介紹這兩個(gè)合并點(diǎn):
bio合并到elevator
先看B表示的代碼段:
blk_queue_bio:
switch (elv_merge(q, &req, bio)) {
case ELEVATOR_BACK_MERGE:
if (!bio_attempt_back_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_back_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
goto out_unlock;
case ELEVATOR_FRONT_MERGE:
if (!bio_attempt_front_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_front_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
goto out_unlock;
default:
break;
}
合并邏輯基本與”plug 合并”相似,先調(diào)用elv_merge接口判斷合并類型,然后根據(jù)是后向合并或是前向合并分別調(diào)用bio_attempt_back_merge和bio_attempt_front_merge進(jìn)行合并操作,由于操作對(duì)象從蓄流鏈表變成了電梯調(diào)度隊(duì)列,bio合并完了之后還需額外干幾件事:
1.調(diào)用elv_bio_merged, 該函數(shù)會(huì)調(diào)用電梯調(diào)度器注冊(cè)的elevator_bio_merged_fn接口來(lái)通知調(diào)度器做相應(yīng)的處理,對(duì)于deadline調(diào)度器而言該接口為NULL。
2.尋找進(jìn)階合并,參考我之前寫(xiě)的《Linux通用塊層介紹(part2: request層)》中對(duì)進(jìn)階合并的描述,如果bio產(chǎn)生了后向合并,則調(diào)用attempt_back_merge試圖進(jìn)行后向進(jìn)階合并,如果bio產(chǎn)生了前向合并,則調(diào)用attempt_front_merge企圖進(jìn)行前向進(jìn)階合并。deadline的進(jìn)階合并接口為deadline_merged_requests, 被合并的request會(huì)從調(diào)度隊(duì)列中刪除。通過(guò)下面的圖示來(lái)展示后向進(jìn)階合并過(guò)程,前向進(jìn)階合并同理。
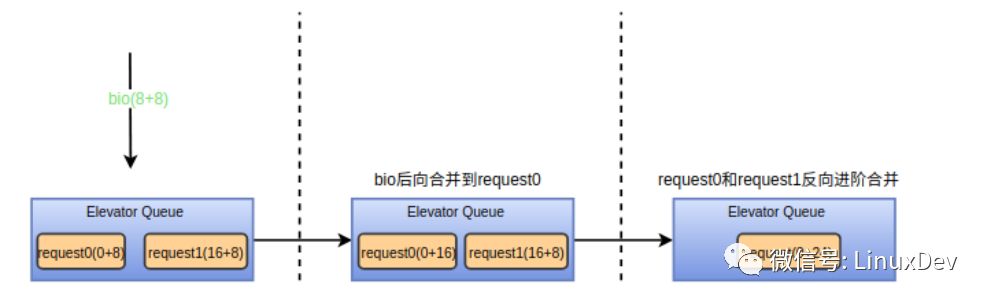
3.如果產(chǎn)生了進(jìn)階合并,則被合并的request可以釋放了,參考上圖,可調(diào)用blk_put_request進(jìn)行回收。如果只產(chǎn)生了bio合并,合并后的request的長(zhǎng)度和扇區(qū)地址都會(huì)發(fā)生變化,需要調(diào)用elv_merged_request->elevator_merged_fn來(lái)更新合并后的請(qǐng)求在調(diào)度隊(duì)列的位置。deadline對(duì)應(yīng)的接口為deadline_merged_request,其相應(yīng)的操作為將合并的request先從調(diào)度隊(duì)列移出再重新插進(jìn)去。
“bio合并到elevator”的合并形式只會(huì)發(fā)生在進(jìn)程間,即只有一個(gè)進(jìn)程在IO的時(shí)候不會(huì)產(chǎn)生這種合并形式,原因在于進(jìn)程在向調(diào)度隊(duì)列派發(fā)IO請(qǐng)求或者試圖與將bio與調(diào)度隊(duì)列中的請(qǐng)求合并的時(shí)候是持有設(shè)備的隊(duì)列鎖得,其他進(jìn)程是不能往調(diào)度隊(duì)列派發(fā)請(qǐng)求,這也是通用塊層單隊(duì)列通道窄需要發(fā)展多隊(duì)列的主要原因之一,只有進(jìn)程在將調(diào)度隊(duì)列中的request逐個(gè)派發(fā)給驅(qū)動(dòng)層的時(shí)候才會(huì)將設(shè)備隊(duì)列鎖重新打開(kāi),即只有當(dāng)一個(gè)進(jìn)程在將調(diào)度隊(duì)列中request派發(fā)給驅(qū)動(dòng)的時(shí)候其他進(jìn)程才有機(jī)會(huì)將bio合并到還未派發(fā)完的request中。所以想通過(guò)簡(jiǎn)單的IO測(cè)試程序來(lái)捕捉這種形式的合并比較困難,這對(duì)兩個(gè)IO進(jìn)程的IO產(chǎn)生時(shí)序有非常高的要求,故不演示。有興趣的可以參考上面的github倉(cāng)庫(kù),里面有patch對(duì)內(nèi)核特定的請(qǐng)求派發(fā)位置加上延時(shí)來(lái)改變IO請(qǐng)求本來(lái)的時(shí)序,從而讓測(cè)試程序人為的達(dá)到這種碰撞效果。
request在泄流的時(shí)候合并到elevator
通用塊層的泄流接口為:blk_flush_plug_list(), 該接口主要的處理邏輯如下圖所示
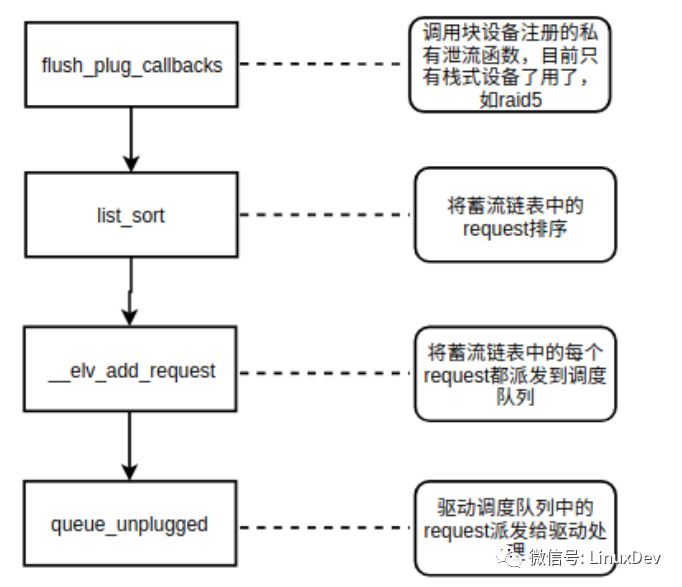
其中請(qǐng)求合并發(fā)生的點(diǎn)在__elv_add_request()。blk_flush_plug_list會(huì)遍歷蓄流鏈表中的每個(gè)request,然后將每個(gè)request通過(guò) _elv_add_request接口添加到調(diào)度隊(duì)列中,添加的過(guò)程中會(huì)嘗試與調(diào)度隊(duì)列中已有的request進(jìn)行合并。
__elv_add_request:
case ELEVATOR_INSERT_SORT_MERGE:
/*
* If we succeed in merging this request with one in the
* queue already, we are done - rq has now been freed,
* so no need to do anything further.
*/
if (elv_attempt_insert_merge(q, rq))
break;
/* fall through */
case ELEVATOR_INSERT_SORT:
BUG_ON(blk_rq_is_passthrough(rq));
rq->rq_flags |= RQF_SORTED;
q->nr_sorted++;
if (rq_mergeable(rq)) {
elv_rqhash_add(q, rq);
if (!q->last_merge)
q->last_merge = rq;
}
q->elevator->type->ops.sq.elevator_add_req_fn(q, rq);
break;
泄流時(shí)走的是ELEVATOR_INSERT_SORT_MERGE分支,正如注釋所說(shuō)的先讓蓄流的request調(diào)用elv_attempt_insert_merge嘗試與調(diào)度隊(duì)列中的request合并,如果不能合并則落入到ELEVATOR_INSERT_SORT分支,該分支直接調(diào)用電梯調(diào)度器注冊(cè)的elevator_add_req_fn接口將新來(lái)的request插入到調(diào)度隊(duì)列合適的位置。其中elv_rqhash_add是將新加入到調(diào)度隊(duì)列的request做hash索引,這樣做的好處是加快從調(diào)度隊(duì)列尋找可合并的request的索引速度。在泄流的時(shí)候調(diào)度隊(duì)列中既有其他進(jìn)程產(chǎn)生的request,也有當(dāng)前進(jìn)程從蓄流鏈表中派發(fā)的request(blk_flush_plug_list是先將所有request派發(fā)到調(diào)度隊(duì)列再一次性queue_unplugged,而不是派發(fā)一個(gè)request就queue_unplugged)。所以“request在泄流的時(shí)候合并到elevator”既是進(jìn)程內(nèi)的,也可以是進(jìn)程間的。elv_attempt_insert_merge的實(shí)現(xiàn)只做request間的后向合并,即只會(huì)將一個(gè)request合并到調(diào)度隊(duì)列中的request的尾部。這對(duì)于單進(jìn)程IO而言足夠了,因?yàn)閎lk_flush_plug_list在泄流的時(shí)候已經(jīng)將蓄流鏈表中的request進(jìn)行了list_sort(按扇區(qū)排序)。筆者曾經(jīng)提交過(guò)促進(jìn)進(jìn)程間request的前向合并的patch(見(jiàn)github),但沒(méi)被接收,maintainer–Jens的解析是這種IO場(chǎng)景很難發(fā)生,如果產(chǎn)生這種IO場(chǎng)景基本是應(yīng)用程序設(shè)計(jì)不合理。通過(guò)增加時(shí)間和空間來(lái)優(yōu)化一個(gè)并不常見(jiàn)的場(chǎng)景并不可取。最后通過(guò)一個(gè)例子來(lái)驗(yàn)證進(jìn)程內(nèi)“request在泄流的時(shí)候合并到elevator”,進(jìn)程間的合并同樣對(duì)請(qǐng)求派發(fā)時(shí)序有很強(qiáng)的要求,在此不演示,github中有相應(yīng)的測(cè)試patch和測(cè)試方法。iotc使用下面的方式派發(fā)三個(gè)寫(xiě)io:
# ./iotc-d/dev/sdb-i
-i指定IO方式為INTERLEAVE_IO(交替),表示按扇區(qū)交替的方式發(fā)起三個(gè)寫(xiě)請(qǐng)求: bio0(16 + 8),bio1(8 + 8), bio2(0 + 8)。blktrace的觀察結(jié)果為:
blktrace -d /dev/sdb -o - | blkparse -i -
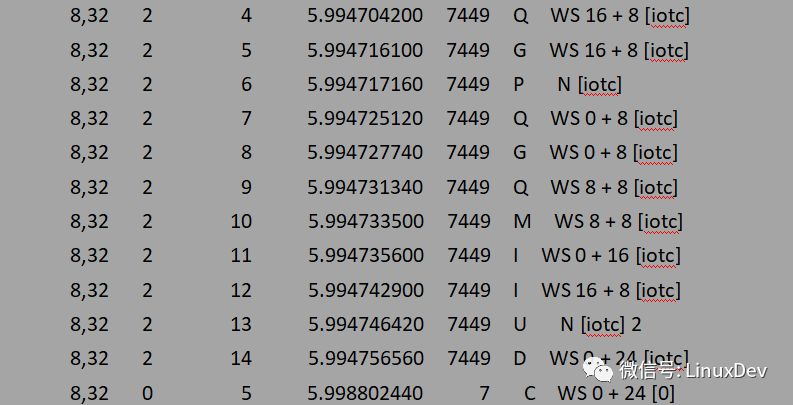
上面的輸出可以簡(jiǎn)單解析為:

bio0(16 + 8)先到達(dá)plug list,bio1(0+8)到達(dá)時(shí)發(fā)現(xiàn)不能與plug list中的request合并,于是申請(qǐng)一個(gè)request添加到plug list。bio2(8+8)到達(dá)時(shí)首先與bio1進(jìn)行后向合并。之后進(jìn)程觸發(fā)泄流,泄流接口函數(shù)會(huì)將plug list中的request排序,因此request(0+16)先派發(fā)到調(diào)度隊(duì)列,此時(shí)調(diào)度隊(duì)列為空不能進(jìn)行合并。然后派發(fā)request(16+8),派發(fā)時(shí)調(diào)用elv_attempt_insert_merge接口嘗試與調(diào)度隊(duì)列中的其他request進(jìn)行合并,發(fā)現(xiàn)可以與request(0+16)進(jìn)行后向合并,于是兩個(gè)request合并成一個(gè),最后向設(shè)備驅(qū)動(dòng)派發(fā)的只有一個(gè)request(0+24)。整個(gè)過(guò)程可以用下面的圖來(lái)展示:
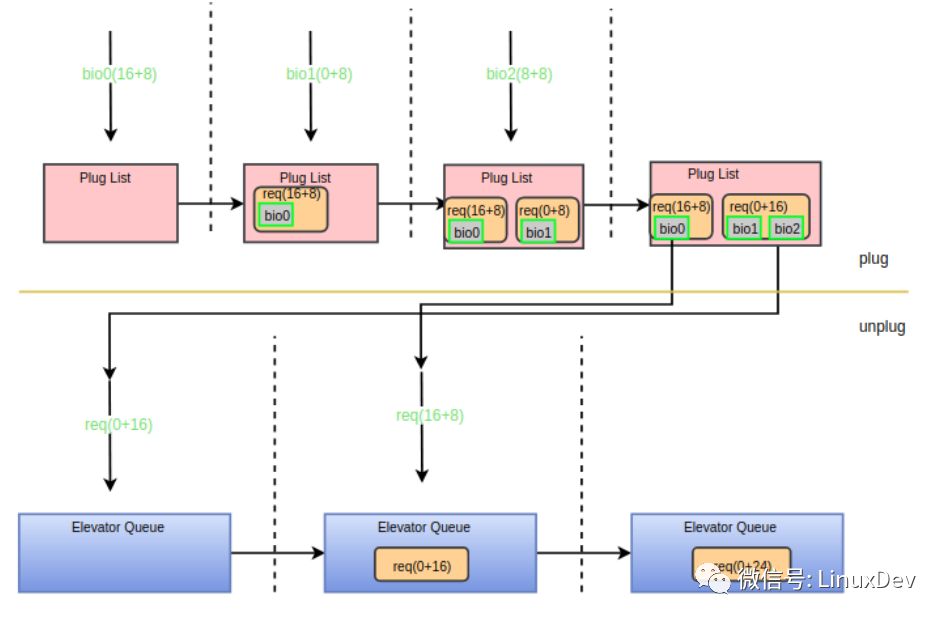
小結(jié)
通過(guò)cache 、plug和elevator自上而下的三層狙擊,應(yīng)用程序產(chǎn)生的IO能最大限度的進(jìn)行合并,從而提升IO帶寬,降低IO延遲,延長(zhǎng)設(shè)備壽命。page cache打頭陣,既做數(shù)據(jù)緩存又做IO合并,主要是針對(duì)小塊IO進(jìn)行合并,因?yàn)槭褂脙?nèi)存頁(yè)做緩存,所以合并后的最大IO單元為頁(yè)大小,當(dāng)然對(duì)于大塊IO,page cache也會(huì)將它拆分成以頁(yè)為單位下發(fā),這不影響最終的效果,因?yàn)楹竺孢€有plug 和 elevator補(bǔ)刀。plug list竭盡全力合并進(jìn)程內(nèi)產(chǎn)生的IO, 從設(shè)備的角度而言進(jìn)程內(nèi)產(chǎn)生的IO相關(guān)性更強(qiáng),合并的可能性更大,plug list設(shè)計(jì)位于elevator queue之上而且又是每個(gè)進(jìn)程私有的,因此plug list既有利于IO合并,又減輕了elevator queue的負(fù)擔(dān)。elevator queue更多的是承擔(dān)進(jìn)程間IO的合并,用來(lái)彌補(bǔ)plug list對(duì)進(jìn)程間合并的不足,如果是帶緩存的IO,這種IO合并基本上不會(huì)出現(xiàn)。從實(shí)際應(yīng)用角度出發(fā),IO合并更多的是發(fā)生在page cache和plug list中。
-
IO
+關(guān)注
關(guān)注
0文章
475瀏覽量
39668 -
Cache
+關(guān)注
關(guān)注
0文章
129瀏覽量
28558
原文標(biāo)題:劉正元: Linux 通用塊層之IO合并
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
for always可以在block中合成的嗎?
在Vivado 2015.2塊設(shè)計(jì)上打開(kāi)子層次結(jié)構(gòu)彈出一個(gè)新的Block Design窗口
請(qǐng)問(wèn)AD09如何為top layer 和bottom layer單獨(dú)設(shè)置keep out layer的大小?
CAN Physical Layer for Industr
A CAN Physical Layer Discussio
什么是Transport Layer Security
MAX14820 IO-Link設(shè)備收發(fā)器

http請(qǐng)求 get post
PCIe的Spec中明確規(guī)定只有Root有權(quán)限發(fā)起配置請(qǐng)求

layer是什么?解析ad9中的plane與layer
ACIS內(nèi)核和parasolid內(nèi)核的來(lái)龍去脈與比較






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論