") 不同角度進(jìn)行介紹ML Procesor的一些信息,值得我們仔細(xì)分析
不同角度進(jìn)行介紹ML Procesor的一些信息,值得我們仔細(xì)分析
最近,ARM 進(jìn)一步公開了ML Procesor 的一些信息。本文從不同角度進(jìn)行了介紹,值得我們仔細(xì)分析。
最近,ARM 進(jìn)一步公開了ML Procesor 的一些信息。EETimes 的文章 “Arm Gives Glimpse of AI Core”[1] 和 AnandTech 的文章“ARM Details “Project Trillium” Machine Learning Processor Architecture” 分別從不同角度進(jìn)行了介紹,值得我們仔細(xì)分析。
ARM 公開它的 ML Processor 是在今年春節(jié)前夕,當(dāng)時(shí)公布的信息不多,我也簡(jiǎn)單做了點(diǎn)分析(AI 芯片開年)。
這次 ARM 公開了更多信息,我們一起來看看。首先是關(guān)鍵的 Feature 和一些重要信息,2018 年中會(huì) Release。
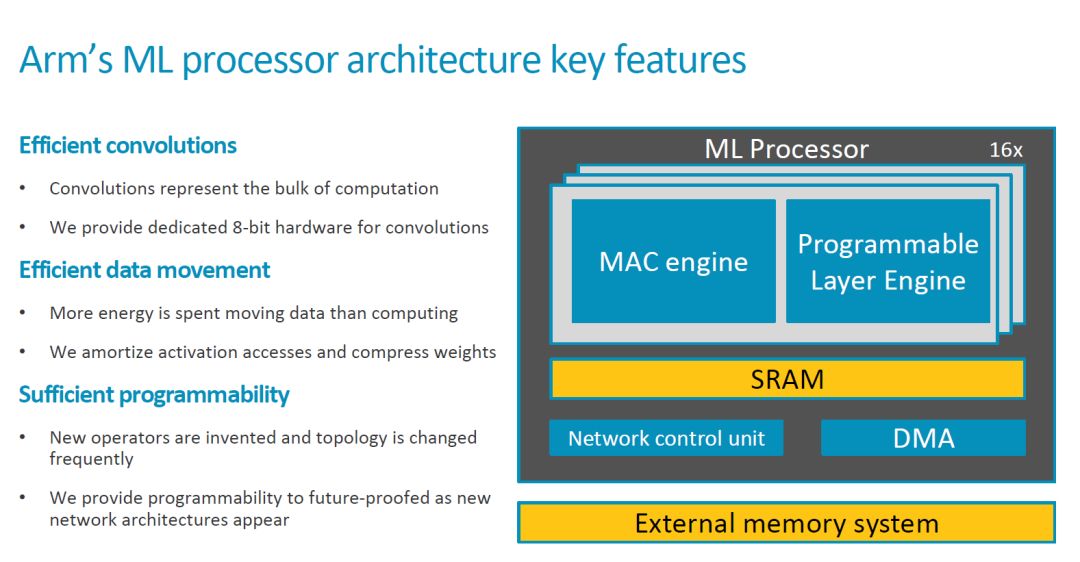
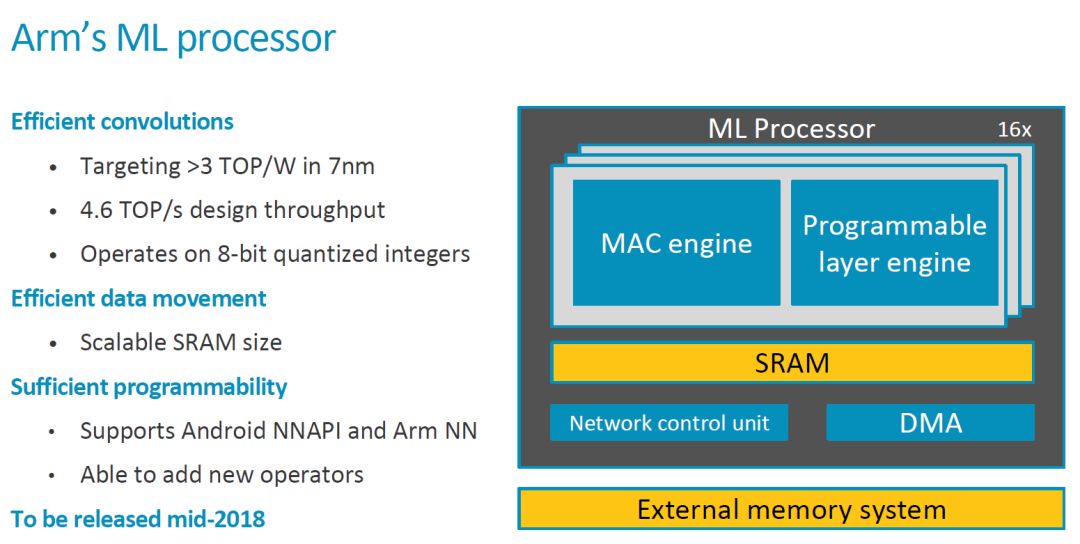
頂層架構(gòu)
與最初公布的基本框圖相比,我們這次看到了更細(xì)化的模塊框圖和連接關(guān)系,如下圖所示。
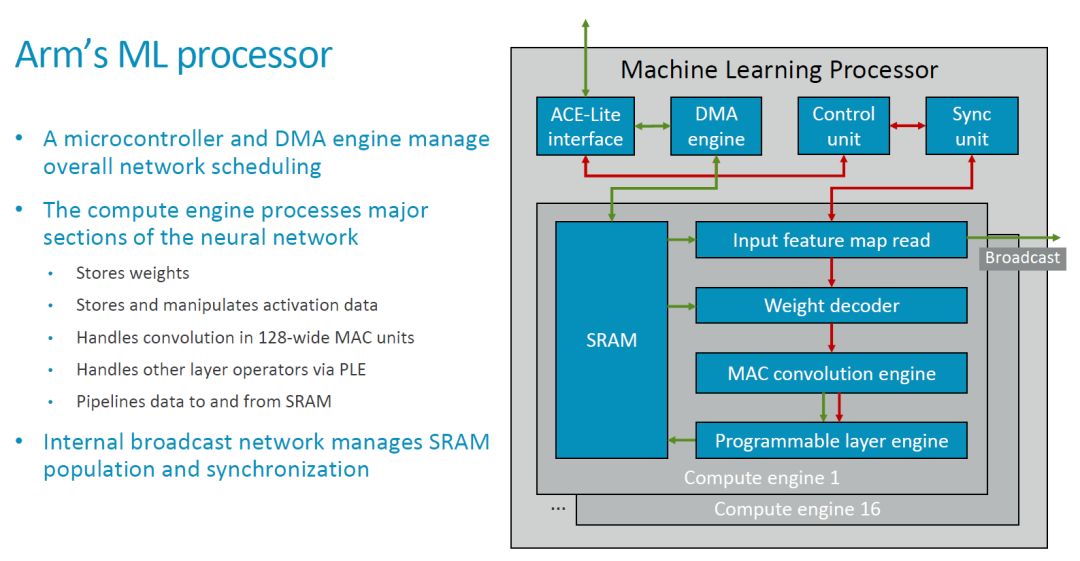
MLP 的頂層對(duì)外來看是個(gè)比較典型的硬件加速器,它有本地的 SRAM,通過一個(gè) ACE-Lite 接口和外部交互數(shù)據(jù)和主要的控制信息(指令)。另外應(yīng)該還有一些控制信號(hào),估計(jì)在這里略去了(可以參考 Nvidia 的 NVDLA)。
在上圖中綠色箭頭應(yīng)該表示的是數(shù)據(jù)流,紅色表示控制流。MLP 中的 CE 共享一套 DMA,Control Unit 和 Sync Unit,它的基本處理流程大概是這樣的:1. 配置 Control Unit 和 DMA Engine;2. DMA Engine 從外部(如 DDR)讀入數(shù)據(jù)存在本地的 SRAM 中;3. Input Feature Map Read 模塊和 Weight Read 模塊分別讀入待運(yùn)算的 feature map 和 weight,處理(比如 Weight 的解壓縮),并發(fā)送到 MAC Convolution Engine(后面簡(jiǎn)稱為 MCE);4. MCE 執(zhí)行卷積等操作,并把結(jié)果傳輸給 Programmable Layer Engine(后面簡(jiǎn)稱為 PLE);5. PLE 執(zhí)行其它處理,并將結(jié)果寫回本地 SRAM;6. DMA Engine 把結(jié)果傳輸?shù)酵獠看鎯?chǔ)空間(如 DDR)。
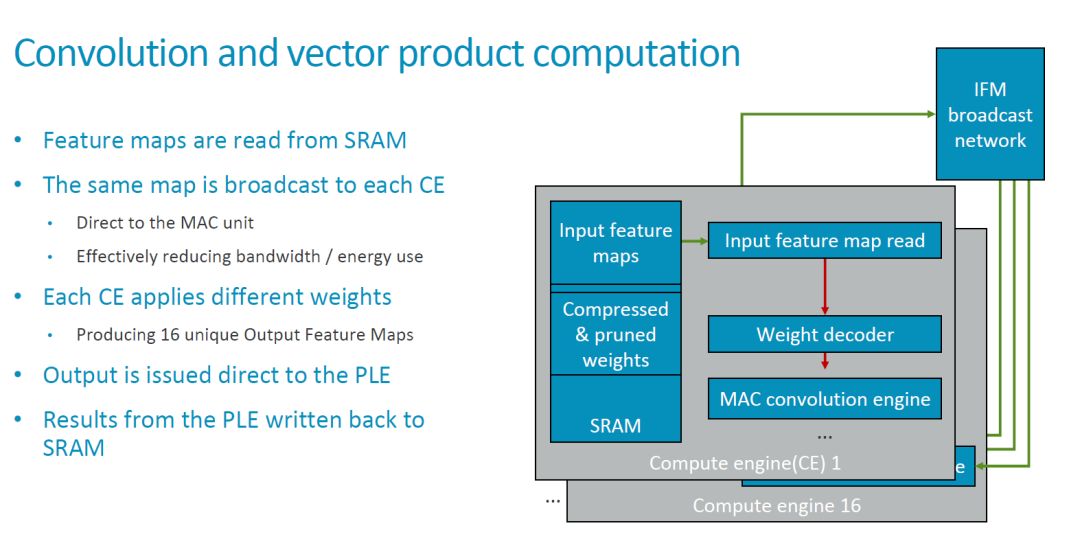
在頂層標(biāo)出的 Broadcast 接口,實(shí)現(xiàn)在多個(gè) Compute Engine(后面簡(jiǎn)稱為 CE)之間廣播 feature map 數(shù)據(jù)的功能。因此,基本的卷積運(yùn)算模式是,相同的 feature map 廣播到多個(gè) CE,不同的 CE 使用不同的 weight 來和這些feature map 進(jìn)行運(yùn)算。
從目前的配置來看,MLP 包括 16 個(gè) compute engine,每個(gè)有 128 個(gè) MAC,即一共有 16x128=2048 個(gè) MAC,每個(gè) cycle 可以執(zhí)行 4096 個(gè)操作。如果要實(shí)現(xiàn) ARM 所說的 4.6TOPS 的總的處理能力,則需要時(shí)鐘周期達(dá)到 1.12GHz 左右。由于這個(gè)指標(biāo)是針對(duì) 7nm 工藝,實(shí)現(xiàn)問題不大。
MCE 實(shí)現(xiàn)高效卷積
在 MLP 的架構(gòu)中,MCE 和 PLE 是最重要的功能模塊。MCE 提供主要的運(yùn)算能力(處理 90% 的運(yùn)算),應(yīng)該也是 MLP 中面積和功耗最大的部分。因此,MCE 設(shè)計(jì)優(yōu)化的一個(gè)主要目標(biāo)就是實(shí)現(xiàn)高效的卷積操作。具體來講,MLP 的設(shè)計(jì)主要考慮了以下一些方法,這些方法大部分我們之前也都討論過。
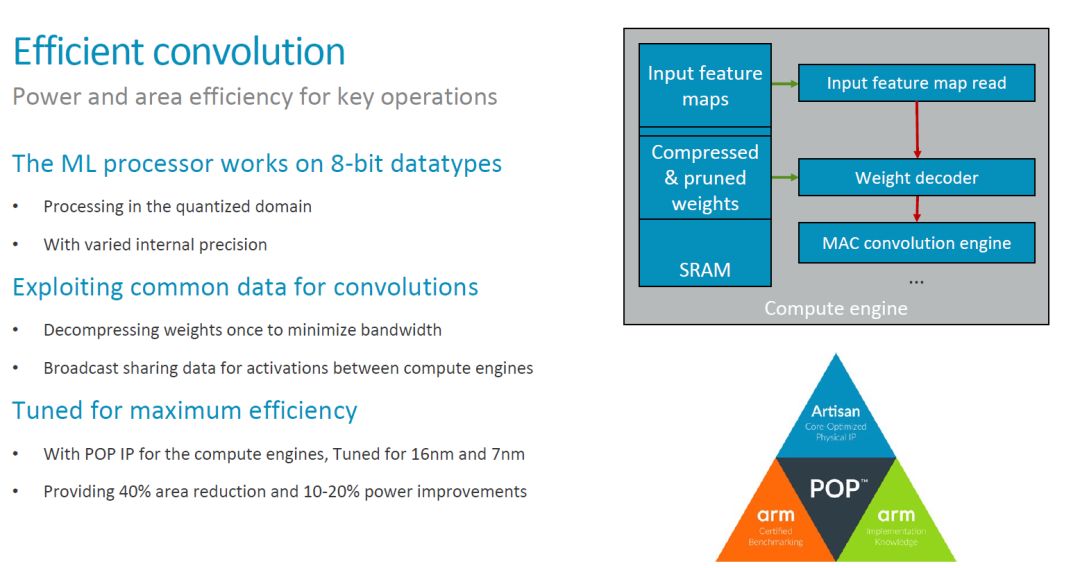
一個(gè)比較有趣的點(diǎn)是上面提到的 “varied internal precision”。目前還不太清楚其具體的含義。不過對(duì)應(yīng)用來說看到的應(yīng)該是固定的 8bit 數(shù)據(jù)類型。至于對(duì)低精度 Inference 的支持,[1] 中提供的信息是,“The team is tracking research on data types down to 1-bit precision, including a novel 8-bit proposal from Microsoft. So far, the alternatives lack support in tools to make them commercially viable, said Laudick.”因此在第一版的 MLP 中,應(yīng)該也不會(huì)看到低精度或者 Bit-serial MAC 了(參考AI 芯片開年中對(duì) ISSCC2018 出現(xiàn)的 Bit-serial Processing 的介紹)。
此外,數(shù)據(jù)的壓縮和對(duì)工藝的優(yōu)化也是提高整體效率的主要手段。特別是工藝的優(yōu)化,結(jié)合 ARM 的工藝庫,應(yīng)該有比較好的效果,這也是 ARM 有優(yōu)勢(shì)的地方。
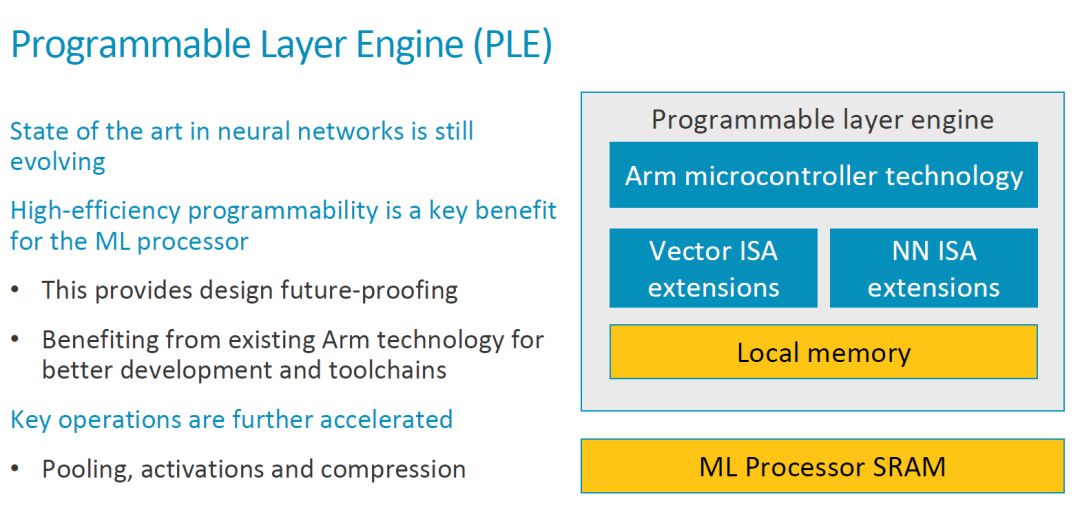
PLE 實(shí)現(xiàn)高效的可編程性
如下圖所示,PLE 的結(jié)構(gòu)基本是在一個(gè) ARM MCU 基礎(chǔ)上擴(kuò)展了 Vector 處理和 NN 處理的指令。在討論可編程性的時(shí)候,其出發(fā)點(diǎn)主要是 NN 算法和架構(gòu)目前還在不斷演進(jìn)。
我們前面已經(jīng)分析了整個(gè) MLP 的基本工作流程,MCE 在完成了運(yùn)算之后把結(jié)果傳輸給 PLE。從這里可以看出,MCE 應(yīng)該是把結(jié)果發(fā)送到 Vector Register File(VRF),然后產(chǎn)生中斷通知 CPU。之后,CPU 啟動(dòng) Vector Engine 對(duì)數(shù)據(jù)進(jìn)行處理。具體如下圖所示。
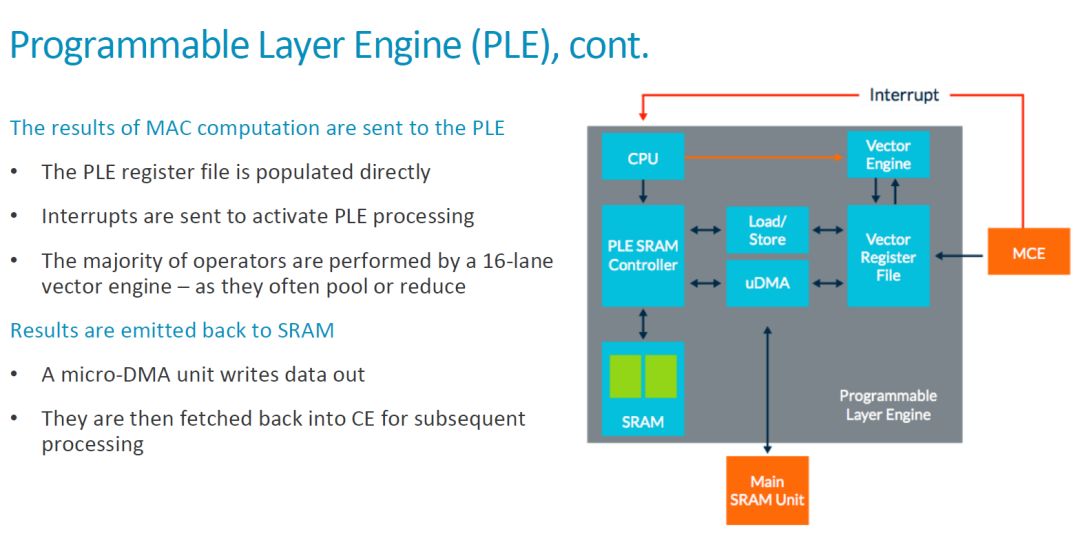
對(duì)于做專用處理器的同學(xué)來說,這種 scalar CPU+vector engine 的架構(gòu)并不陌生。這里,本地 SRAM,VRF 和 PLE 之外的 Maing SRAM Unit(CE 中的 SRAM)之間有 Load/Store 單元和 uDMA 實(shí)現(xiàn)數(shù)據(jù)的傳輸,數(shù)據(jù)流也是比較靈活的。綜合來看,在 MLP 中,每個(gè) CE 中都有一個(gè) PLE 和 MCE 配合,即每個(gè) MCE(128 個(gè) MAC)就對(duì)應(yīng)一個(gè)可編程架構(gòu)。因此,ARM MLP 的可編程性和靈活性是要遠(yuǎn)高于 Google TPU1 和 Nvidia 的 NVDLA 的。當(dāng)然,靈活性也意味著更多額外的開銷,如 [1] 中指出的,“The programmable layer engine (PLE) on each slice of the core offers “just enough programmability to perform [neural-net] manipulations””。High-efficient Programmability 是 MLP 的一個(gè)主要賣點(diǎn)之一,而 ARM 的 “just enough” 是否真是最合適的選擇,還有待進(jìn)一步觀察。
其它信息
在這次發(fā)布中信息中,ARM 還強(qiáng)調(diào)了他們?cè)跀?shù)據(jù)壓縮方面的考慮,包括對(duì) lossless compression 的硬件支持。這部分內(nèi)容我在之前的文章中也有比較多的討論,就不再贅述了,貼幾張比較有意思的圖,大家看看。
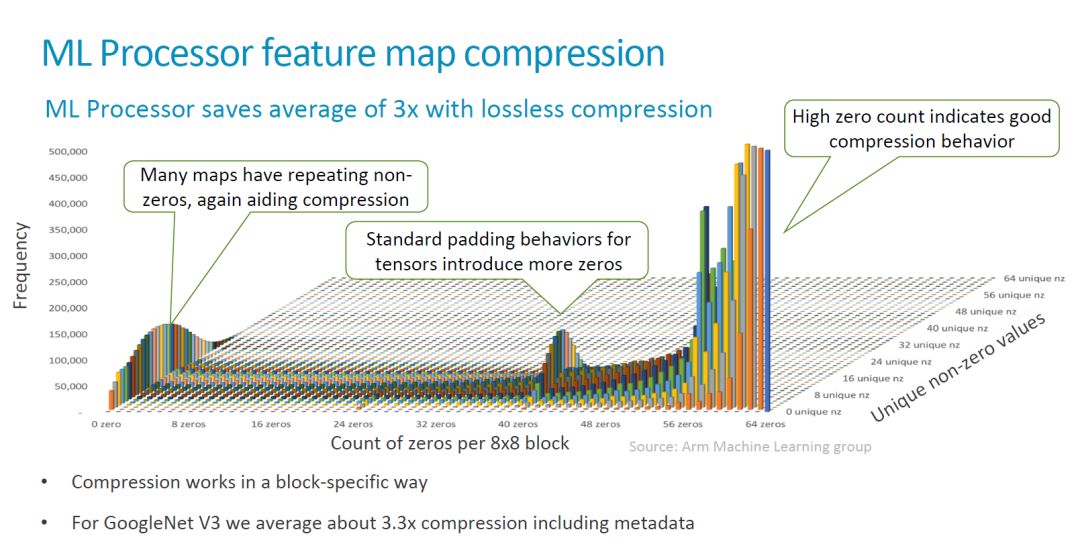

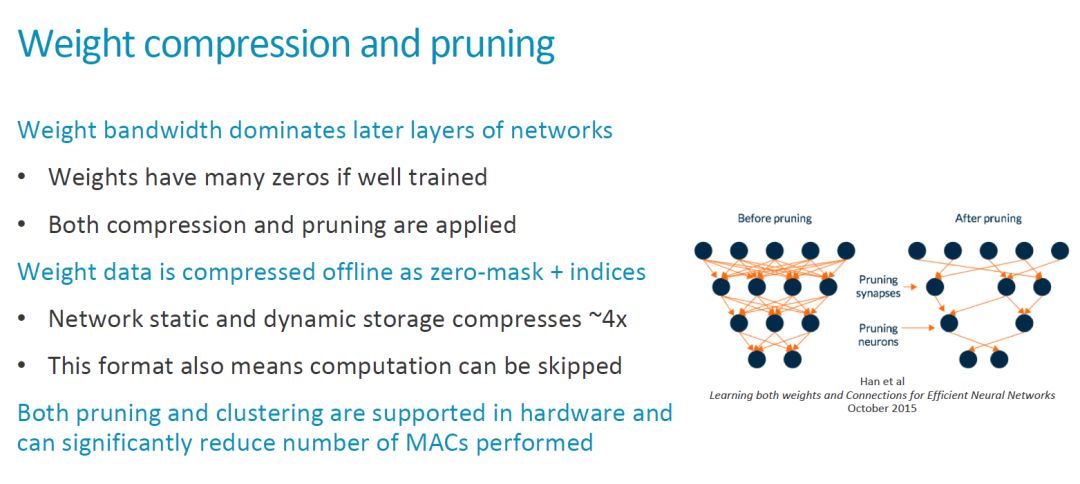
作為一個(gè) IP 核,可配置性(configurability)是一個(gè)重要的特征。目前還不知道 MLP 有哪些硬件參數(shù)可以支持靈活配置。Compute Engine 的數(shù)量,MAC 數(shù)量,SRAM 大小,這些比較大的參數(shù)應(yīng)該有可能是支持配置的。其它更細(xì)致的內(nèi)容還要看最終發(fā)布的情況。
另外,這些參數(shù)的配置和相關(guān)的軟件工具有非常密切的關(guān)系,更多的可配置參數(shù)也意味著軟件工具需要相應(yīng)的支持,難度更大。[2] 對(duì)此的說法:“In terms of scalability the MLP is meant to come with configurable compute engine setups from 1 CE up to 16 CEs and a scalable SRAM buffer up to 1MB. The current active designshoweverare the 16CE and 1MB configurations and smaller scaled down variants will happen later on in the product lifecycle.”
競(jìng)爭(zhēng)態(tài)勢(shì)
除了比較中規(guī)中矩的性能指標(biāo)外,ARM 還沒有公布 MLP 具體的面積,功耗等參數(shù),以及具體發(fā)布的日期(目前的說法是 “production release of the RTL is on track for mid-year”)。
在這個(gè)已經(jīng)比較 “擁擠” 的市場(chǎng),ARM 顯然是動(dòng)作比較慢的。[1] 一開始就提到了,“Analysts generally praised the architecture as a flexible but late response to a market that is already crowded with dozens of rivals.” 并列舉了一些競(jìng)爭(zhēng)對(duì)手的例子。
其實(shí),從 ARM 在處理器 IP 市場(chǎng)和整個(gè)生態(tài)鏈的關(guān)鍵地位來看,晚一點(diǎn)關(guān)系也不大。如 [1] 所說,一方面,ARM 正在和一些智能手機(jī)廠商進(jìn)行深度的合作,“In a sign of Arm’s hunger to unseat its rivals in AI, the company has “gone further than we normally would, letting [potential smartphone customers] look under the hood””。
ARM 的另一個(gè)重要優(yōu)勢(shì)是,ARM 在推出 MLP 之前在軟件工具上還是有一些準(zhǔn)備的,包括 armnn 和開源的計(jì)算庫等等,如下圖。
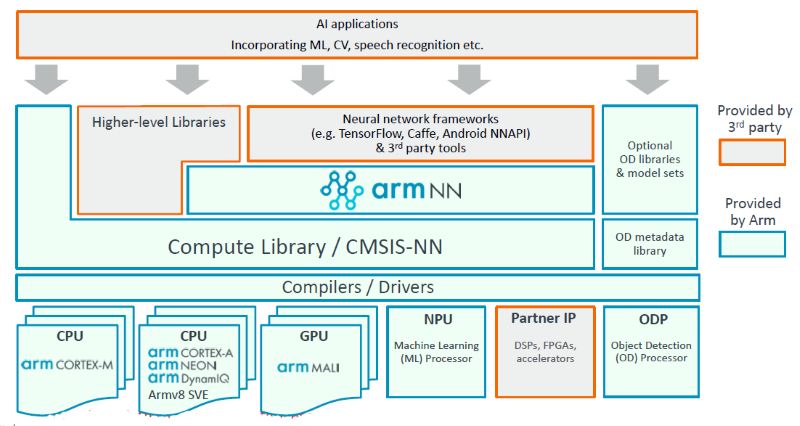
這些工具的廣泛使用都可以幫助 ARM 積累經(jīng)驗(yàn),優(yōu)化硬件和軟件工具。正如 [1] 中引用來自 ARM 的說法,“Winningthe hearts and minds of software developers is increasingly key in getting design wins for hardware sockets...This is kind of the start of software 2.0. For a processor company, that is cool. But it will be a slow shift,there’s a lot of things to be worked out, and the software and hardware will move in steps.”
我們也看到,目前大量的嵌入 AI 應(yīng)用還是運(yùn)行在 ARM 的各種硬件上的,很多公司在相關(guān)算法和實(shí)現(xiàn)的優(yōu)化上投入了很大的力量,也取得了很好的效果。當(dāng)然這樣帶來另一個(gè)有趣的問題,那就是未來引入 MLP 之后,ML 任務(wù)到底放到哪里跑?不同特點(diǎn)的處理器怎么配合?文章中正好也提到這個(gè)問題,“Arm will release more data on the core’s performance when it is launched, probably in mid-June. But don’t expect detailed guidance onwhen to run what AI jobs on its CPU, GPU, or new machine-learning cores, a complex issue that the company, so far, is leaving to its SoC and OEM customers.” 看來這個(gè) “難題” 短期之內(nèi)還是丟給用戶了。
另外一個(gè)值得關(guān)注細(xì)節(jié)是,[1] 中提到,“Theoretically, the design scales from 20 GOPS to 150 TOPS, but the demand for inference in the Internet of Things will pull it first to the low end.Armis still debating whether it wants to design a core for the very different workloads of the datacenterthat includes training. “We are looking at [a datacentercore], but it’s a jump from here,” and its still early days for thoughts on a design specific for self-driving cars, said Laudick.” 從這里可以看出,至少 MLP 在處理能力上還是具有比較強(qiáng)的伸縮性的,應(yīng)該可以覆蓋從 Edge 到 Cloud 的大部分的 inference 應(yīng)用。如果是最高的 150TOPS,MAC 的規(guī)模應(yīng)該和 Google 第一代 Inference 專用的 TPU 類似,不過相比 Google 的脈動(dòng)陣列架構(gòu),MLP 有更復(fù)雜的控制通道,靈活性還是要高不少。不知道未來,這會(huì)不會(huì)幫助 ARM 打開 data center 的 inference 市場(chǎng)。
-
處理器
+關(guān)注
關(guān)注
68文章
19404瀏覽量
230813 -
ARM
+關(guān)注
關(guān)注
134文章
9164瀏覽量
368659 -
AI
+關(guān)注
關(guān)注
87文章
31490瀏覽量
269918
原文標(biāo)題:一窺 ARM 的 AI 處理器
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【AWorks試用體驗(yàn)】+硬件篇之開膛破腹分析
介紹一些SVA基本的概念和常用的語法
仔細(xì)分析下RSS的邏輯實(shí)現(xiàn)
ARM指令集體系結(jié)構(gòu)(ISA)的一些功能介紹
基于HTML 標(biāo)記的信息隱藏方法
一窺ARM的AI處理器

AI芯片大戰(zhàn)后,ARM的“just enough”是否真是最合適的選擇?
一些開關(guān)電源的拓?fù)浣Y(jié)構(gòu)詳細(xì)分析

恒大造車值得我們多給其一些耐心與期待
介紹一些大功率IGBT模塊應(yīng)用中的一些技術(shù)
一些對(duì)OpenMP進(jìn)行優(yōu)化的方法
我們的微服務(wù)中為什么需要網(wǎng)關(guān)?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論