 捷豹路虎第一個使用820A做座艙域控制器
捷豹路虎第一個使用820A做座艙域控制器
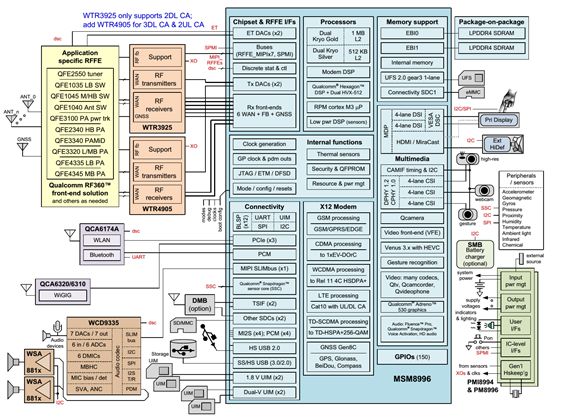
2013年初,高通開始進軍車載處理器市場,首款產品是2013年底的602A,在2014年初正式推出,不過推出后反應平平。車載系統開發周期遠比手機開發周期長,芯片至少要考慮5年后的市場,高通在2016年初推出820A(兩款芯片,一款為820A,不帶Modem,另一款為820Am,帶Modem),超前性能立刻獲得好評。
捷豹路虎第一個使用820A做座艙域控制器,在2017年下半年就有路虎星脈和捷豹I-PACE兩款量產車使用820A,隨后大眾、本田、吉利、PSA、比亞迪、瑪莎拉蒂也紛紛采用820A做座艙域控制器。本田的10代雅閣美版也采用820A,已正式上市,國內則因為1.5T發動機機油增多問題,10代雅閣推遲上市。
上圖為路虎攬勝星脈的座艙,采用4塊屏幕,其中全液晶儀表為12.3英寸,Infotainment為10英寸,車載信息顯示也為10英寸,屏上有兩個碩大的鋁合金旋鈕,還有一塊HUD使用的3.1英寸顯示屏。可能由日本松下或哈曼打造。Infotainment屏幕在啟動后會自動前傾,方便駕駛者觀看。Infotainment屏下方的車載信息顯示屏可以對車輛的空調、座椅和車輛設定進行控制,除了空調溫度旋鈕和音量旋鈕,其余都用觸控操作。儀表系統采用QNX,Infotainment用Linux+安卓界面。未來可能用Android Auto。
捷豹的第一款純電動車I-Pace采用了類似星脈的設計,只是把車載信息顯示屏換成了5.5英寸。這套系統中規中矩,唯一的出彩之處是激光HUD。捷豹路虎是第一個使用激光HUD的車廠,激光HUD顯示對比度極高,色彩艷麗。
雖然不能算嚴格意義上的AR HUD,但是已經很不錯了,能與ADAS和導航地圖系統通信。
820A相比NXP的i.mx8或者瑞薩的R-CAR H3,亦或者德州儀器的Jacinto EX,優勢有幾點:
820A的絕大部分開發成本已經由手機廠家分攤完畢,有充足的降價空間
820本來就是針對移動設備的,低功耗不言而喻
820A最大優勢,內含了4G Modem,無需再添加通訊模塊
820A的劣勢在于它最初不是針對車載市場的,不是按照ISO26262標準的開發流程得來的,安全等級連ASIL A級都達不到,只有AEC-Q100 3級。R-CAR H3是達到了ASIL B級,i.mx8暫時還未申請ASIL級別,但以NXP的能力,也能達到ASIL B級。當然可以通過添加其他元件讓整體系統達到ISO 26262標準,但畢竟是個麻煩。
和奔馳MBUX相比,820Am做域控制器的座艙并未給人帶來多少驚喜,820Am又多了一個強勁的對手,那就是英偉達的Parker。Parker一開始就是瞄準車載市場的,采用ASIL B級安全架構,內含鎖步的R5內核,有內存糾正功能。Parker的另一優勢是深度學習能力。820A的硬件也具備深度學習能力,但是高通的起步稍微晚了點,高通在2017年7月才發布了NPE的SDK。所以這方面應用還未看到,估計要等到下一代820座艙系統了。未來820域控制器可能接管部分ADAS功能,如360環視,車道線與行人識別,前撞報警,車道線偏離報警,不過應該只用于報警系統,不會用于主動執行系統,畢竟它沒有考慮功能安全,用起來還是讓人略微不放心。
此外深度學習這東西,沒有太多理論依據,更多的像蠻力的搜索——非常深的層數,幾千萬甚至上億參數,然后調整參數擬合輸入與輸出。這是一個不可解釋的黑盒子,用在汽車以外的手機上沒什么問題,但汽車領域要有充足的可解釋性,這樣才能評估安全風險。不過要想實現語義級的識別,深度學習幾乎是最好的方法,盡管汽車行業不喜歡這種黑盒子,但還是不得不高度重視深度學習。
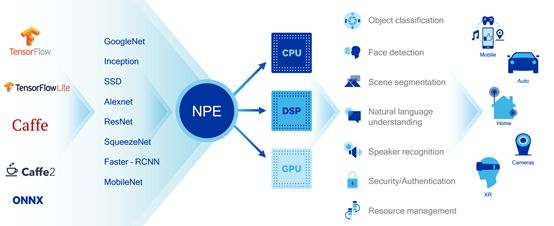
高通的NPE主要在Caffe2和Tensor Flow上運行,Caffe2主要是圖形類,Tensor Flow還可以處理語音類。820內部采用異構架構,有三個運算單元,包括CPU、GPU、DSP分別針對不同類型的應用。

820內部的Hexagon 680 DSP內置了一個1024bit的SMID矢量數據寄存器,高通稱之為Hexagon Vector Extensions—Hexagon矢量擴展,簡寫為HVX。HVX每次可以處理四條VLIW向量指令,每個循環可以處理多達4096bit數據,需要注意的是,一般實際應用中的指令比DSP支持的最大指令寬度要小很多,不過借助于SIMD和系統的特性,單個指令可以一次操作多個數據,因此在計算中很多數據可以被一次性填充進入處理過程,實現效能的最大化。
另外,HVX為了實現上下文切換功能,還設計了32個向量寄存器。規格方面,HVX支持32位的定點十進制數的操作,一般為INT8位,但不支持浮點計算,畢竟成本還是要考慮的。VX內部擁有L1數據和指令緩存,4個并行的VLIW標量處理單元,單元的運行頻率為500MHz,還有共享的L2緩存。
此外,HVX中還有兩組獨立的矢量單元,這樣設計實際上是為了執行多線程任務,比如同時處理音頻和圖像處理,矢量單元可以獨立進行計算。ADAS中的視覺處理如360度環視,車道線識別,也就是量化的8比特數據交給DSP比較合適。DSP的能耗比差不多是最優秀的。非量化的32比特數據交給CPU或GPU處理。
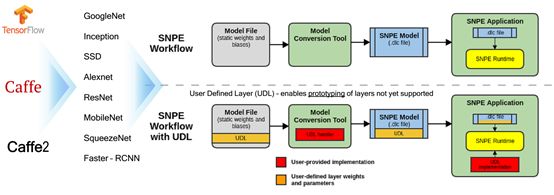
上圖為NPE工作流程
座艙領域的深度學習可能會以語音識別或NLP自然語音處理為主要任務,并且是本地化離線與云端結合的NLP。離線NLP對目前高端CPU或者GPU來說處理能力問題不大,關鍵是存儲語音庫模型,消耗成本較高,存儲器價格持續上漲令人頭痛。再有可能就是知識產權的問題,離線的數據包有可能被人破解。
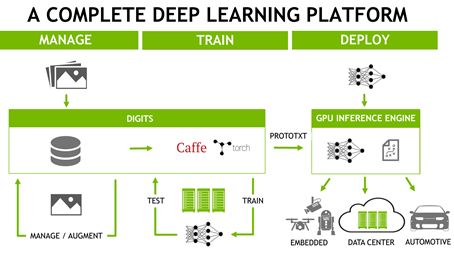
上圖為完整的深度學習平臺,可以說深度學習就是靠英偉達的GPU發展起來的,沒有英偉達的GPU,深度學習不會走到今天這等地步,今天大部分深度學習的訓練部分加速都是GPU完成的。而英偉達在一開始就布局長遠,早在2007年推出CUDA的時候,就想到用CUDA建立了類似英特爾的生態圈。雖然官方發布的 CUDA Toolkit 并不總是最高效的實現,而是存在一定認知“黑洞”,一般用戶無論如何優化CUDA C程序都無法逾越性能瓶頸。
而官方發布的庫,從早期的CUBLAS,CUFFT到后來面向深度學習的CUDNN,都不是用CUDA C寫的,而是NVIDIA內部的編譯器完成的(這個是沒有公開的版本),這樣對NVIDIA好處顯而易見,既能賣硬件,又能在軟件上保持領先,增加用戶粘度。從用戶角度而言,使用高度封裝的庫可以降低開發、調試的門檻,直接調用C API就可以實現自己的算法,無需了解CUDA C的設計細節。即使是谷歌,也是選擇CUDA而不是OpenCL作為TensorFlow的后端。
問題來了,高通的GPU自然不可能用CUDA,只能用OpenCL。CUDA則有強大的生態體系,尤其是深度學習訓練領域,遠比OpenCL易用。OpenCL雖然句法上與CUDA接近,但是它更加強調底層操作,因此難度較高,但正因為如此,OpenCL才能跨平臺運行。基于C語言的CUDA被包裝成一種容易編寫的代碼,因此即使是不熟悉芯片構造的科研人員,也可能利用CUDA工具編寫出實用的程序,程序員更喜歡CUDA。
當然OpenCL與CUDA不是嚴格意義上的競爭關系,CUDA是一個并行計算的架構,包含有一個指令集架構和相應的硬件引擎。OpenCL是一個并行計算的應用程序編程接口(API)。CUDA C是一種高級語言,那些對硬件了解不多的非專業人士也能輕松上手;而OpenCL則是針對硬件的應用程序開發接口,它能給程序員更多對硬件的控制權,相應的上手及開發會比較難一些。所以用高通的GPU做深度學習,難度頗高,好在高通還有個DSP,雖然這個DSP只能做定點運算,但是還是有點用處的,比如語音處理時消除背景噪音。
英偉達的Parker在性能方面優勢比較明顯,在深度學習領域優勢更明顯,但是在功耗方面很可能不如高通820Am,雖然高通未給出準確的TDP數字,英偉達也未給出準確數值,有說7.5瓦,也有說最高21瓦。TDP這個指標已經有點過時了,很難準確評價芯片的功耗,但手機對功耗要求肯定比車載更加苛刻,尤其是高通810被人投訴發熱嚴重,820肯定不會掉以輕心,車載的估計也適當降低CPU性能來降低功耗。
中美貿易爭端的大背景下,高通收購NXP很有可能得不到批準。未來高通的820A,英偉達的Paker會對老牌廠家NXP的i.mx8 (i.mx8QM、 i.mx8QP要到2018年3季度才有量產樣片,且還是28納米的FD-SOI工藝),瑞薩的R-CAR H3、德州儀器的Jacinto 6 Plus構成強大的威脅。820A可能會擠占i.mx8的中端市場,Parker則可能會主打高端市場,擠壓R-CAR H3的市場。
-
高通
+關注
關注
76文章
7487瀏覽量
190826 -
英偉達
+關注
關注
22文章
3800瀏覽量
91385 -
深度學習
+關注
關注
73文章
5508瀏覽量
121311
原文標題:高通和英偉達座艙域控制器之戰
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
奇瑞·捷豹路虎工廠初體驗:揭秘捷豹路虎如何領跑各普通品牌
捷豹路虎與Connected Energy合作,推進電池再利用計劃
捷豹路虎成負擔,塔塔集團為其尋找合作伙伴
捷豹路虎測試自動駕駛與網聯汽車
究竟是什么原因讓捷豹路虎削減1/4的產能呢?
高通以驍龍汽車智聯平臺為捷豹路虎下一代現代豪華主義車型帶來5G功能






 工商網監
工商網監
評論