 深度學習的典型應用是圖像分類問題
深度學習的典型應用是圖像分類問題
深度學習的典型應用是圖像分類問題。用深度學習技術進行圖像分類,表現出眾,甚至超過了人類的水平。然而,天下沒有免費的午餐。深度學習對算力資源的要求也十分苛刻。偏偏在某些資源受限的場景下,仍然需要應用深度學習進行圖像分類。這是一個巨大的技術挑戰。
資源受限場景
資源受限的場景有不少,其中最主要的兩種:
設備本身的性能限制,比如移動設備。
海量數據。許多大公司有海量圖像需要處理,亟需在維持分類精確度的前提下,優化性能。
前者常用的設定是anytime classification(隨時分類)。比如,用手機拍一朵花,深度學習模型可能會先返回“花”這一粗糙的分類結果,識別出這是在拍攝花卉,調用相應的場景模式(比如,微距花卉)。如果用戶拍攝后在當前界面停留較久,那么模型再進一步返回具體的花的種類(用戶可能想知道剛拍了什么花)。如果直接返回具體類別,可能需要很長時間,這時用戶可能早已按下快門,來不及調用相應的場景模式。
除了以上場景外,另一個anytime classification的典型應用場景是適配不同設備。移動設備多種多樣,性能各異。anytime classification意味著我們只需訓練一個模型,然后部署到不同的設備上。在性能較差的設備上,模型給出粗糙的分類。而在性能較好的設備上,模型給出精細的分類。這樣,我們無需為各種千奇百怪的模型一一訓練模型。
而后者常用的設定是budgeted batch classification(預算批分類)。和anytime classification不同,這次的時間限制不在單張圖片上(比如在用戶按下快門之前),而是在整批圖像上。對于這一場景而言,要處理的圖像的分類難度不一定一樣。
比如,下圖左邊的馬很好檢測,即使是一個簡單的網絡都能檢測出來。而右邊的馬,因為拍攝角度關系,不容易檢測,需要算力負擔更重的網絡架構。
圖片來源:Pixel Addict and Doyle;許可:CC BY-ND 2.0
如果整批圖像都用簡單模型分類,那么有些圖像不能被正確分類。相反,如果整批圖像都用復雜模型分類,那么在簡單圖像上浪費了很多資源。因此,我們需要一種彈性的模型,既可以使用較少的資源進行粗糙的分類,也可以使用更多的資源進行精細的分類。
我們看到,不管是anytime classification,還是budgeted batch classification,都要求模型具有既可以進行粗糙分類,又能進行精細分類的特性。所以,盡管表面上這兩個場景非常不一樣(一個的典型應用場景是移動設備上的單張圖像分類,另一個的典型應用場景是大公司高性能設備上的海量圖像分類),但其內在需求的一致性,意味著我們可以構建一個統一的模型來應對這兩個場景的挑戰(或者,至少是大體思路一致的模型架構,然后根據這兩個場景的不同進行局部調整)。
模型的直覺
應對上面提到的問題,最簡單直接的方案就是使用多個不同的網絡,每個網絡的能力不同(相應的算力需求也不一樣)。具體而言,使用一組網絡,每個網絡的能力依次遞增。然后依次使用這一組網絡進行分類。在anytime classification場景下,返回最近的分類結果。而在budgeted batch classification場景下,當網絡的結果置信度足夠高時,就返回結果,然后跳過后續的網絡,直接分類下一張圖像。
這個方案非常直截了當,易于理解,易于實現。問題在于,多個模型所做的工作有很多是重復的(比如都需要通過卷積層提取特征之類),而使用多個模型,無法實現復用,每個模型都要從頭開始。對資源受限環境而言,這樣的浪費是不可接受的。
為了實現復用,可以把多個網絡整合成一個模型,共用許多組件,得到一個基于級聯分類層的深度網絡。
但是,CNN(卷積神經網絡)的架構原本不是為這種級聯設計的,因此這樣簡單的堆疊分類層,會導致兩個問題:
CNN的不同層在不同尺度上提取圖像的特征。一般而言,靠前的層提取精細的特征(局部),而靠后的層提取粗糙的特征(整體)。而分類高度依賴整體的粗糙特征。前面的分類層因為缺乏粗糙尺度上的特征,效果非常差。
加入的分類層可能對特征提取層造成干擾。換句話說,靠前的分類層可能影響最終分類層的效果。
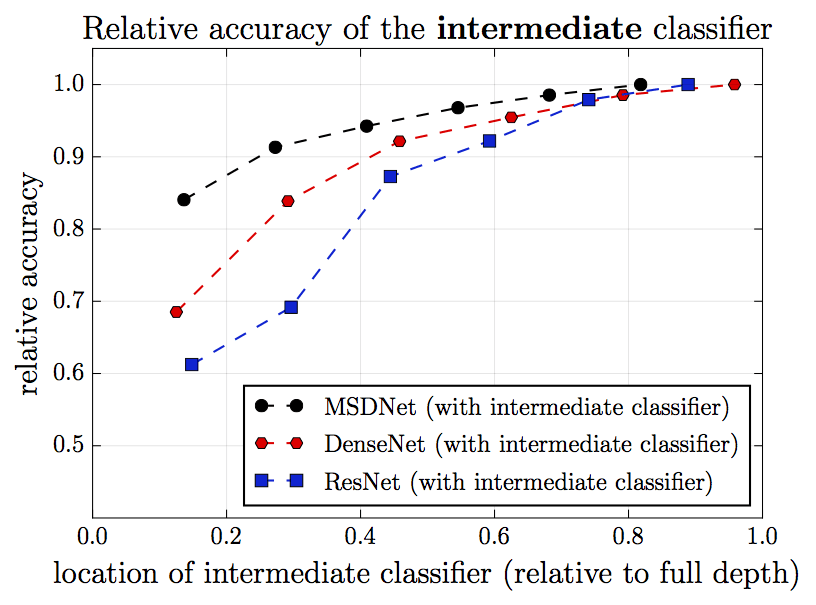
下圖為不同網絡架構在CIFAR-100上的分類結果比較。其中,縱軸為相對精確度(最終分類層的精確度為1),橫軸為中間分類層的相對位置(最終分類層的位置為1)。黑色表示MSDNet(新提出的架構),紅色表示DenseNet,藍色表示ResNet(作為比較對象)。我們看到,越靠后的分類層,分類的精確度越高。但是,在DenseNet和ResNet中,靠前的幾個分類層表現特別差,和靠后的分類層的差距特別大。這一點在ResNet上尤為明顯。這正是因為靠前的幾個分類層缺乏粗糙尺度上的特征。
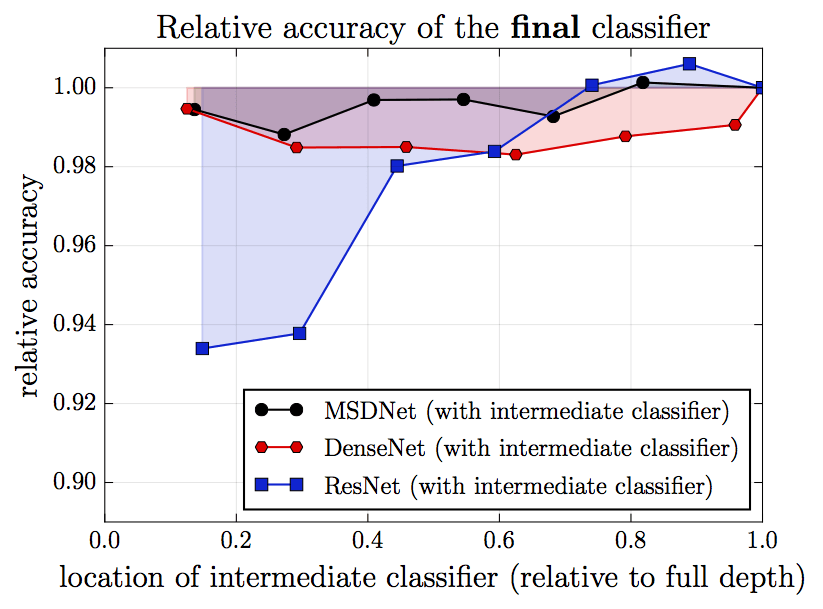
再看一張圖。這張圖中,每次在網絡中插入一個中間分類層,橫軸表示插入的單個中間分類層的位置,縱軸為相應的最終分類層的表現。我們看到,在ResNet中,插入的中間層的位置越靠前,最終分類層的表現就越差。這是因為插入的分類層干擾了特征提取層的運作。之所以插入的位置越靠前,最終分類層的表現就越差,這大概是因為,插入的分類層越靠前,相應的特征提取層就越是為較近的中間分類層的表現這一“短期目標”進行優化,相應地忽略了較遠的最終分類層這一“長期目標”的需求。
那么,該如何處理這兩個問題呢?
我們先考慮第二個問題,分類層的干擾問題。如前所述,特征提取層為較近的中間分類層優化,而忽視了較遠的最終分類層的需求。那么,如果我們把特征提取層也和靠后的分類層連接起來呢?通過特征提取層和之后的分類層的直接連接,不就可以避免過于為靠前的分類層優化,忽視靠后的分類層了嗎?事實上,Gao Huang等在CVPR 2017上發表的DenseNet就提供了這樣的特性。
5層的DenseNet組件
之前的圖片也表明,DenseNet下,前面插入分類層,對最終分類層的影響不大。
至于第一個缺乏粗糙尺度特征的問題,可以通過維護一個多尺度的特征映射來解決。
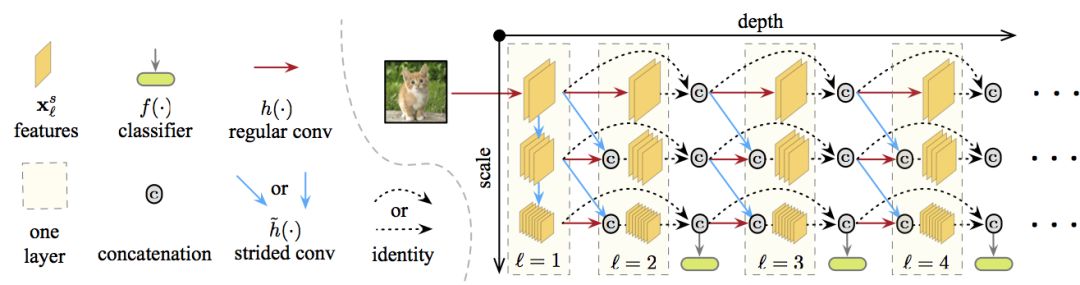
在上圖中,深度由左往右依次加深,尺度由上往下,從精細到粗糙,所有分類器都使用粗糙層的特征(粗糙層和分類高度相關)。特定層和尺度上的特征映射通過連接以下一個或兩個卷積計算得出:
同一尺度上之前層的通常卷積操作的結果(圖中橫向的紅線)
(如果可能的話,)前一層更精細尺度上的特征映射的步進卷積操作(圖中對角的藍線)。
結合這兩種,就得到了多尺度密集網絡(Multi-Scale Dense Network),簡稱MSDNet.
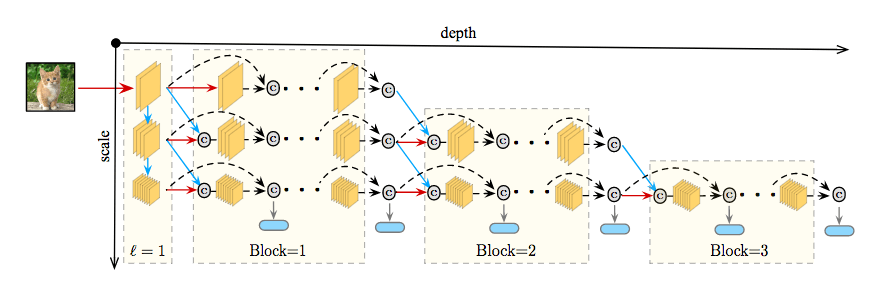
MSDNet架構
如前所示,MSDNet的架構為下圖:
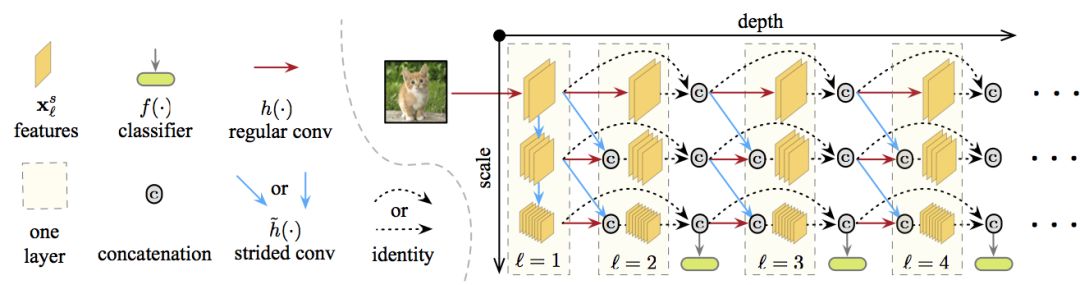
第一層第一層(l=1)比較特別,因為它包含垂直連接(圖中藍線)。它的主要作用是在所有尺度上提供表示“種子”。粗糙尺度的特征映射通過降采樣獲得。
后續層后續層遵循DenseNet的結構,特定層和尺度上的特征映射的連接方式如上一節所述。第一層和后續層的輸出詳見下圖。

分類器分類器同樣遵循DenseNet的密集連接模式。每個分類器由兩個卷積層、一個平均池化層、一個線性層組成。如前所述,在anytime設定中,當預算時間用盡后,輸出最近的預測。在batch budget設定下,當分類器fk的預測置信度(softmax概率的最大值)超過預先定義的閾值θk時退出。在訓練前,計算網絡到達第k個分類器的算力開銷Ck。相應地,一個樣本在分類器k處退出的概率為qk= z(1-q)k-1q. 其中,q為樣本到達分類器且得到置信度足夠的分類并退出的退出概率。我們假定q在所有層上都是恒定的。z是一個歸一化常數,確保∑kp(qk) = 1. 在測試時,需要確保分類測試集Dtest中的所有樣本的總開銷不超過期望預算B。也就是|Dtest|∑kqkCk≤ B這一限制。我們可以在驗證集上求解這一限制中的q值,進而決定θk.
損失函數在訓練中,所有分類器使用交叉熵損失函數L(fk),并最小化加權累積損失:

上式中,D為訓練集,wk為第k個分類器的權重,wk≥ 0. 如果預算分布P(B)是已知的,我們可以使用權重wk結合關于預算B的先驗知識。在實踐中,我們發現,所有損失函數使用同樣的權重效果較好。
網絡化簡和惰性演算以上的網絡架構可以通過兩種直截了當的方法進一步化簡。首先,在每層維持所有尺度并不高效。一個簡單的降低網絡尺寸的策略是將網絡分為S塊,在第i塊中僅僅保留最粗糙的(S - i + 1)尺度。移除尺度的同時,在塊之間加上相應的過渡層,使用1x1卷積合并連接起來的特征,并在通過步進卷積將精細尺度的特征傳給粗糙尺度之前截取一半的頻道。
其次,由于第l層的分類器只使用最粗糙尺度的特征,第l層的更精細的特征映射(以及S-2層之前的一些更精細的特征映射)不影響該分類器的預測。因此,只沿著下一個分類器所需路徑傳播樣本可以最小化不必要的計算。研究人員稱這一策略為惰性演算。
試驗
數據集
研究人員在3個圖像分類數據集上評估了MSDNet的效果:
CIFAR-10
CIFAR-100
ILSVRC 2012(ImageNet)
CIFAR數據集包括50000張訓練圖像和10000張測試圖像,圖像大小為32x32像素。研究人員留置了5000張訓練圖像作為驗證集。CIFAR-10包含10個分類,CIFAR-100包含100個分類。研究人員應用了標準的數據增強技術:圖像每邊補零4個像素,接著隨機剪切以得到32x32圖像。圖像以0.5概率水平翻轉,通過減去頻道均值和除以頻道標準差進行歸一化。
ImageNet數據集包含1000分類,共計一百二十萬張訓練圖像和50000張驗證圖像。研究人員留置50000張訓練圖像以估計MSDNet的分類器的置信度閾值。研究人員應用了Kaiming He等在Deep Residual Learning for Image Recognition(arXiv:1512.03385)中提出的數據增強技術。在測試時,圖像被縮放到256x256像素,然后中央剪切為224x224像素。
訓練細節在CIFAR數據集上,所有模型(包括基線模型)使用隨機梯度下降(SGD)訓練,mini-batch大小為64. 使用了Nesterov動量法,動量權重為0.9(不帶抑制),權重衰減為10-4。所有模型訓練300個epoch,初始學習率為0.1,在150和225個epoch后除10. ImageNet的優化規劃與此類似,只不過mini-batch大小增加到256,所有模型訓練90個epoch,在30和60個epoch后降低學習率。
用于CIFAR數據集的MSDNet使用3個尺度。第一層使用3x3卷積(Conv),組歸一化(BN),ReLU激活。后續層遵循DenseNet的設計,Conv(1x1)-BN-ReLU-Conv(3x3)-BN-ReLU. 3個尺度上的輸出頻道數分別為6、12、24. 每個分類器包含2個降采樣卷積層(128維3x3過濾器),1個2x2平均池化層,1個線性層。
用于ImageNet的MSDNet使用4個尺度,相應地,每層生成16、32、64、64特征映射。在傳入MSDNet的第1層之前,原始圖像先經過7x7卷積和3x3最大池化(步長均為2)轉換。分類器的結構和用于CIFAR的MSDNet相同,只不過每個卷積層的輸出頻道數和輸入頻道數一樣。
CIFAR數據集上,用于anytime設定的MSDNet有24層。分類器對第2x(i+1)層的輸出進行操作,其中i=1,...,11. 而用于budgeted batch設定的MSDNet深度為10到36層。第k個分類器位于第(∑ki=1i)層。
ImageNet上的MSDNet(anytime和budgeted batch設定)使用4個尺度,相應地,第i個分類器操作第(kxi+3)層的輸出,其中i=1,...,5,k=4,6,7.
ResNet有62層,每個分辨率包含10個殘差塊(共3個分辨率)。研究人員在每個分辨率的第4、8個殘差塊訓練中間分類器,共計6個中間分類器(再加上最終分類器)。
DenseNet有52層,包含3個密集塊,每塊有16層。6個中間層位于每塊的第6、12層。
所有模型均使用Torch框架實現,代碼見GitHub(gaohuang/MSDNet)。
CIFAR-10
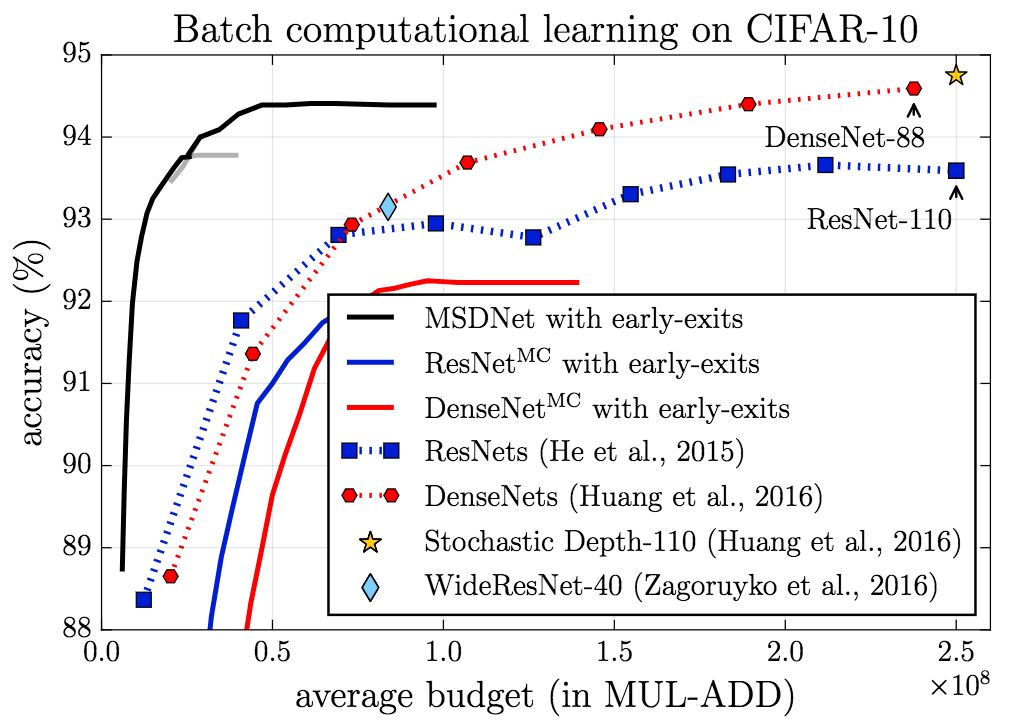
在CIFAR-10上,無論是在anytime設定下,還是在budgeted batch設定下,MSDNet的表現(精確度)都顯著超過基線。

CIFAR-100
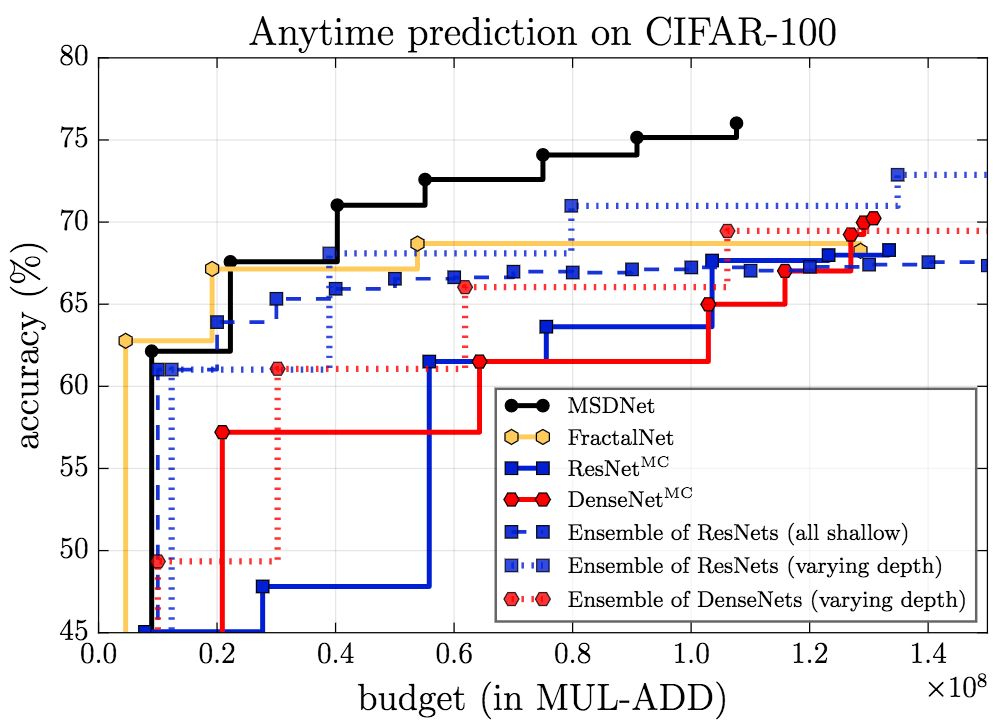
上圖為anytime設定下的結果,可以看到,除了在預算極小的情形下,MSDNet的表現都超過了其他模型。在預算極小的情形下,集成方法具有優勢,因為預測是由第一個(小型)網絡作出的,這一網絡專門為預算極小的情形優化。

而在budgeted batch設定下,MSDNet的表現優于其他模型。特別值得注意的是,MSDNet僅使用110層ResNet的十分之一的算力預算就達到了相當的表現。
ImageNet
MSDNet在ImageNet上的表現同樣讓人印象深刻。
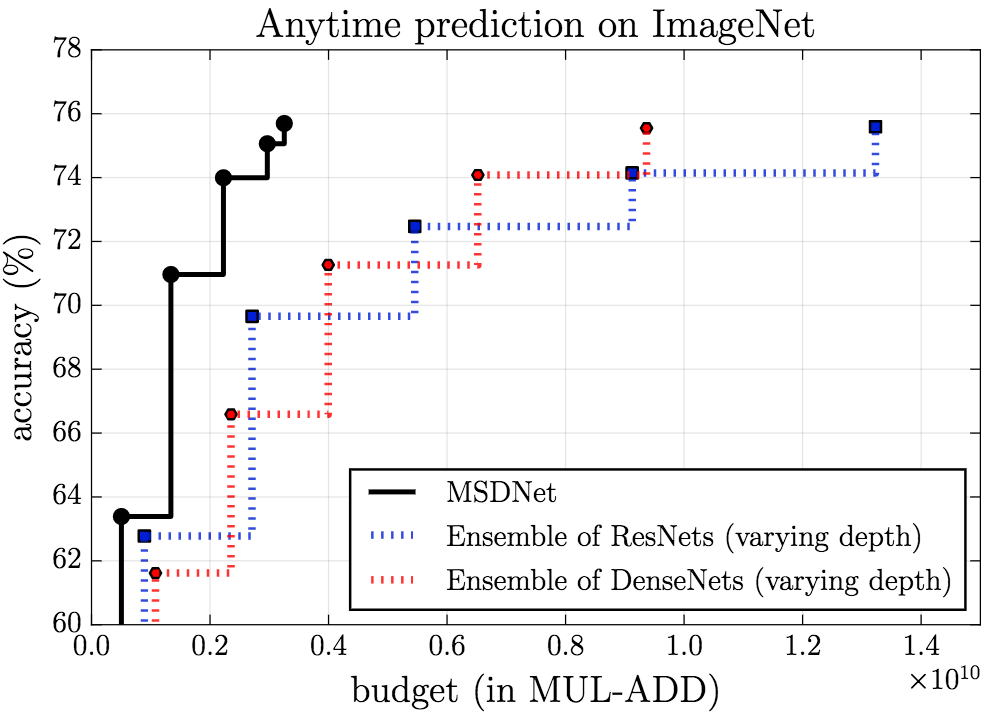
anytime

budgeted batch
消融測試
消融測試驗證了密集連接、多尺度特征、中間分類器的有效性。
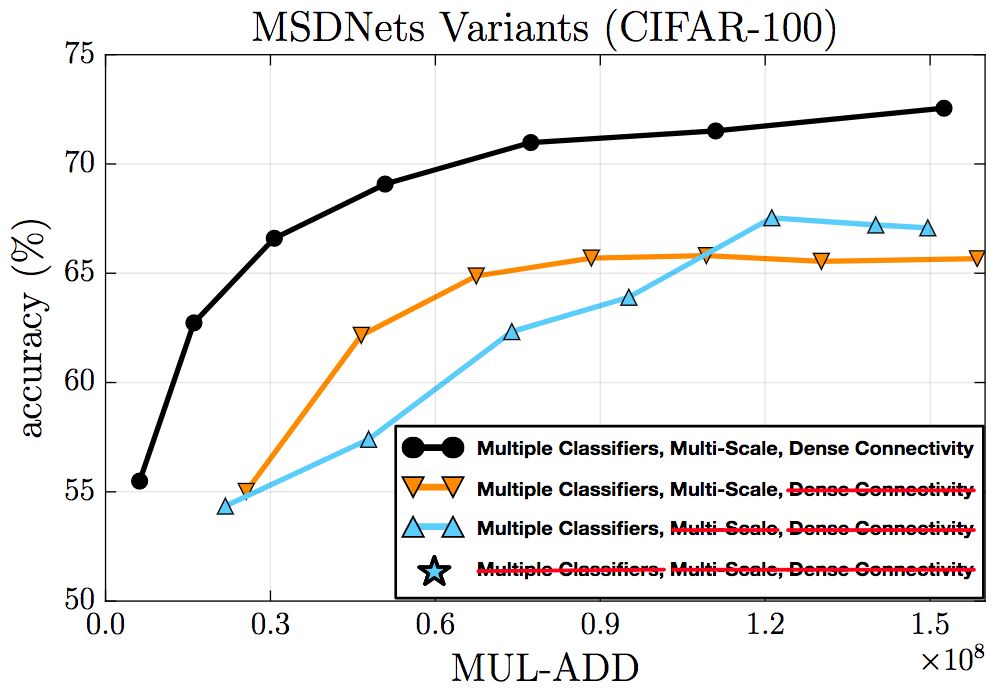
CIFAR-100上的消融測試
此外,研究人員還從ImageNet隨機選擇了一些圖片。下圖分為兩行,上面一行的圖像容易分類,下面一行的圖像較難分類。MSDNet的第一個分類器正確預測了“容易”圖像的分類,而沒能成功預測“困難”圖像的分類,而MSDNet的最終分類器正確預測了“困難”圖像的分類。
結語
在剛結束的ICLR 2018上,本文作者做了口頭報告(5月1日 04:00 -- 04:15 PM;Exhibition Hall A)。
研究人員打算以后進一步探索分類以外的資源受限深度架構,比如圖像分割。此外,研究人員也有意探索更多進一步優化MSDNet的方法,比如模型壓縮,空間適應計算,更高效的卷積操作。
-
圖像分類
+關注
關注
0文章
93瀏覽量
11944 -
深度學習
+關注
關注
73文章
5512瀏覽量
121410
原文標題:資源受限場景下的深度學習圖像分類:MSDNet多尺度密集網絡
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習視角下的貓狗圖像識別實現

討論紋理分析在圖像分類中的重要性及其在深度學習中使用紋理分析
什么是深度學習?使用FPGA進行深度學習的好處?
圖像分類的方法之深度學習與傳統機器學習
一種新的目標分類特征深度學習模型
Xilinx FPGA如何通過深度學習圖像分類加速機器學習
深度學習中圖像分割的方法和應用
詳解深度學習之圖像分割
基于深度學習的圖像修復模型及實驗對比






 工商網監
工商網監
評論