 機器人平臺JetPack 3.1使Jetson的低延遲推斷性能翻了一番
機器人平臺JetPack 3.1使Jetson的低延遲推斷性能翻了一番
NVIDIA發布了針對JetsonTX1和TX2的生產Linux軟件JetPack 3.1。隨著TensorRT 2.1和cuDNN 6.0的升級,JetPack 3.1可為實時應用程序(如視覺導航和運動控制)提供高達2倍的深度學習推理性能,這些應用程序可從批量加速1中獲益。改進的特性使Jetson能夠部署更強大的智能,實現一代自動化機器,包括傳送機器人,遠程呈現和視頻分析。為了進一步推動機器人技術的發展,NVIDIA最近推出的Isaac Initiative是一個端到端的平臺,用于在現場培訓和部署高級AI。
圖1. Liquid Robotics公司的再生波和太陽能波浪滑翔機能夠與Jetson一起自主穿越海洋進行低功耗視覺和人工智能處理。
AI在邊緣
當NVIDIA推出Jetson TX2時,事實上的邊緣計算平臺獲得了顯著的功能提升。如圖1中的Wave Glider平臺所示例,網絡邊緣的遠程物聯網(IoT)設備經常會遇到降低的網絡覆蓋率,延遲和帶寬。雖然物聯網設備通常用作將數據轉發到云端的網關,但邊緣計算重新考慮了物聯網訪問安全板載計算資源的可能性。NVIDIA的Jetson嵌入式模塊在Jetson TX1上提供1 TFLOP / s的服務器級性能,在功耗低于10W的Jetson TX2上提供雙倍的AI性能。
JetPack 3.1
帶有Linux的JetPack 3.1對于Tegra(L4T)R28.1是帶有長期支持(LTS)的Jetson TX1和TX2的生產軟件版本。用于TX1和TX2的L4T板級支持包(BSP)適用于客戶的產品化,其共享的Linux內核4.4代碼庫提供了兼容性和兩者之間的無縫移植。從JetPack 3.1開始,開發人員可以在TX1和TX2上訪問相同的庫,API和工具版本。
表1:Jetson TX1和TX2的JetPack 3.1和L4T BSP中包含的軟件包版本。NVIDIA JetPack 3.1 - 軟件組件Linux Tegra R28.1Ubuntu 16.04 LTS aarch64CUDA工具包8.0.82cuDNN6.0TensorRT2.1 GAGStreamer 1.8.2VisionWorks1.6OpenCV4Tegra 2.4.13-17Tegra系統分析器3.8Tegra圖形調試器2.4Tegra多媒體APIV4L2相機/編解碼器API除了從cuDNN 5.1升級到6.0以及維護更新到CUDA 8之外,JetPack 3.1還包括用于構建流媒體應用程序的最新視覺和多媒體API。您可以將JetPack 3.1下載到您的主機上,以便使用最新的BSP和工具對Jetson進行閃存。
使用TensorRT 2.1進行低延遲推理
JetPack 3.1中包含最新版本的TensorRT,因此您可以在Jetson上部署優化的運行時深度學習推斷。TensorRT通過網絡圖優化,內核融合和半精度FP16支持提高推理性能。TensorRT 2.1包括多重配料等關鍵特性和增強功能,進一步提高了Jetson TX1和TX2的深度學習性能和效率,并降低了延遲。
批量大小1的性能得到顯著改善,導致GoogLeNet的延遲降至5毫秒。對于延遲敏感的應用程序,批處理大小1提供最低的延遲,因為每一幀在到達系統時都會被處理(而不是等待批量處理多個幀)。如Jetson TX2上的圖2所示,使用TensorRT 2.1實現了GoogLeNet和ResNet圖像識別推斷的TensorRT 1.0吞吐量的兩倍。
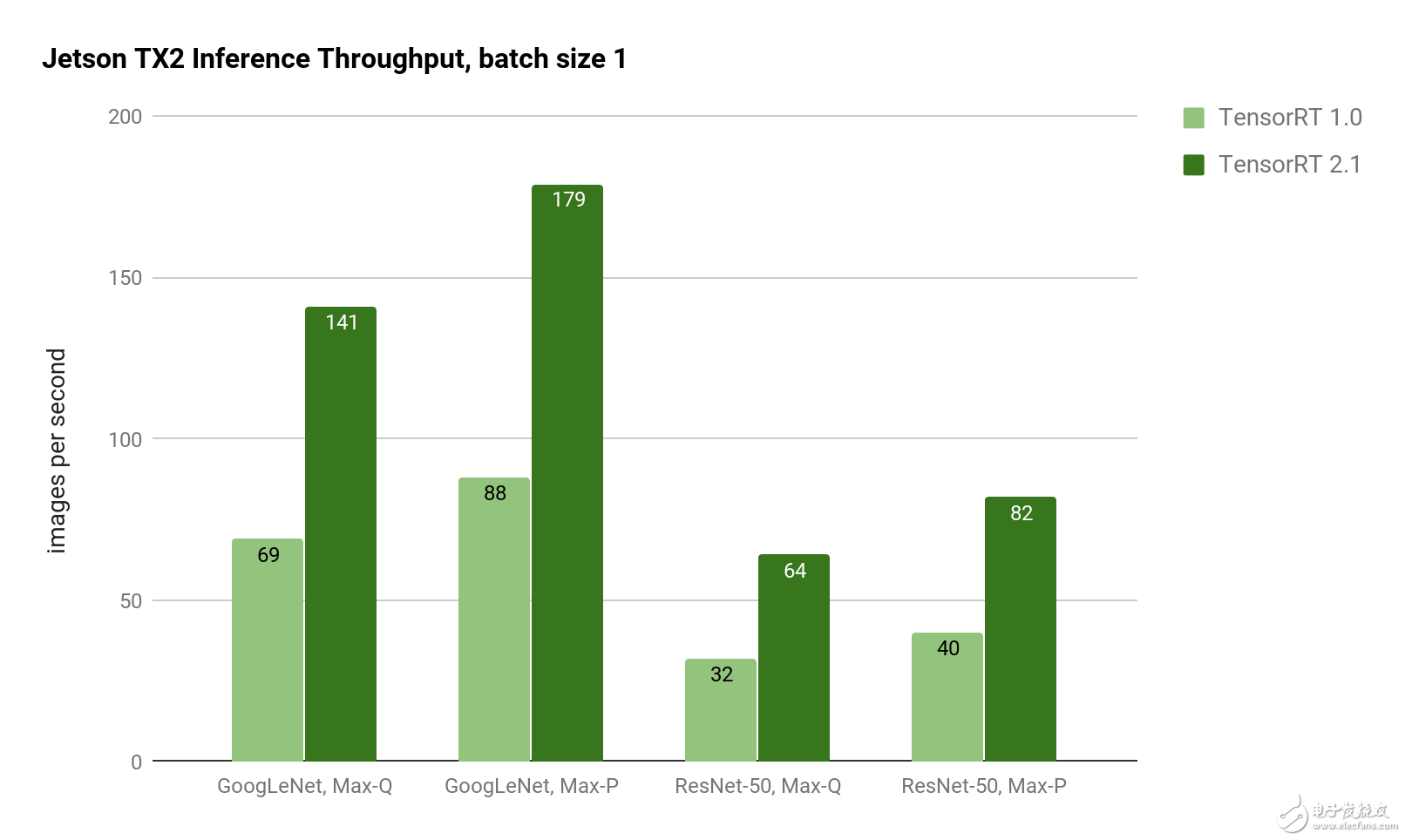 圖2:使用Jetson TX2 Max-Q和Max-P功率曲線的GoogLeNet和ResNet-50的推理吞吐量。TensorRT 2.1在GoogleLeNet和ResNet上提供了兩倍的推理吞吐量。
圖2:使用Jetson TX2 Max-Q和Max-P功率曲線的GoogLeNet和ResNet-50的推理吞吐量。TensorRT 2.1在GoogleLeNet和ResNet上提供了兩倍的推理吞吐量。
表2中的等待時間顯示批量大小為1時的比例縮減。對于Genson TX2,Jetson TX2在Max-P性能曲線中實現了5ms的延遲,在Max-Q效率曲線中運行時延遲了7ms。ResNet-50在Max-P中有12.2ms的延遲,在Max-Q中有15.6ms的延遲。ResNet通常用于提高超越GoogLeNet的圖像分類精度,使用TensorRT 2.1可以使運行時性能提高2倍以上。憑借Jetson TX2的8GB內存容量,即使在像ResNet這樣的復雜網絡上,也可以實現高達128的大批量生產。
表2:比較TensorRT 1.0和2.1的Jetson TX2深度學習推斷延遲測量。(越低越好。)網絡潛伏加速TensorRT 1.0TensorRT 2.1GoogLeNet,Max-Q14.5ms7.1ms2.04xGoogLeNet,Max-P11.4ms為5.6ms2.04xResNet-50,Max-Q31.4ms15.6ms2.01xResNet-50,Max-P24.7ms12.2ms2.03x減少的延遲允許深度學習推理方法用于要求接近實時響應的應用中,如避免碰撞和高速無人機和地面車輛上的自主導航。
自定義圖層
通過用戶插件API支持自定義網絡層,TensorRT 2.1能夠運行最新的網絡和功能,擴展支持包括殘余網絡(ResNet),遞歸神經網絡(RNN),一次只能看一次(YOLO)和更快-RCNN。自定義圖層是在用戶定義的C ++插件中實現的,這些插件實現IPlugin了以下代碼中的界面。
#include“NvInfer.h”使用命名空間nvinfer1;classMyPlugin:IPlugin{上市:
intgetNbOutputs()const;
DimsgetOutputDimensions(intindex,constDims*inputs,
intnbInputDims);
voidconfigure(constDims*inputDims,intnbInputs,
constDims*outputDims,intnbOutputs,
intmaxBatchSize);
intinitialize();
voidterminate();
size_tgetWorkspaceSize(intmaxBatchSize)const;
intenqueue(intbatchSize,constvoid*inputs,
void**outputs,void*工作區,
cudaStream_t流);
size_tgetSerializationSize();
voidserialize(void*buffer);保護:
虛擬?MyPlugin(){}};
您可以使用IPlugin類似于上述代碼的自定義定義來構建自己的共享對象。在用戶enqueue()函數內部,您可以使用CUDA內核實現自定義處理。TensorRT 2.1使用這種技術來實現用于增強對象檢測的Faster-RCNN插件。另外,TensorRT為長時間短期記憶(LSTM)單元和門控循環單元(GRU)提供了新的RNN層,以改進時間序列序列的基于記憶的識別。開箱即用地提供這些功能強大的新圖層類型可加速在嵌入式邊緣應用程序中部署高級深度學習應用程序。
 圖3:與Jetson一起提供的用于AI研發的機器人參考平臺。
圖3:與Jetson一起提供的用于AI研發的機器人參考平臺。
NVIDIA Isaac計劃
隨著人工智能能力的快速提升,NVIDIA推出了艾薩克計劃,以推進機器人和人工智能領域的先進技術。Isaac是開發和部署智能系統的端到端機器人平臺,包括模擬,自主導航堆棧和嵌入式Jetson以供部署。為開始開發自主AI,Isaac支持圖3所示的機器人參考平臺。這些Jetson驅動的平臺包括無人機,無人地面車輛(UGV),無人地面車輛(USV)和人類輔助機器人(HSR)。參考平臺提供了一個Jetson驅動的基礎,可以在實地進行實驗,并且該計劃將隨著時間的推移而擴展,以包含新的平臺和機器人。
開始部署AI
JetPack 3.1包括cuDNN 6和TensorRT 2.1。它現在可用于Jetson TX1和TX2。憑借對單批次推斷的低延遲性能以及對具有自定義層的新網絡的支持,雙倍的Jetson平臺比以往任何時候都更有能力進行邊緣計算。要開始開發人工智能,請參閱我們的兩天演示系列培訓和部署深度學習視覺基元,如圖像識別,物體檢測和分割。JetPack 3.1大大提高了這些深度視覺原語的性能。
-
機器人
+關注
關注
211文章
28632瀏覽量
208058 -
NVIDIA
+關注
關注
14文章
5075瀏覽量
103559 -
深度學習
+關注
關注
73文章
5512瀏覽量
121431
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論