") TFLite在有道云筆記中用于文檔識別的實踐過程
TFLite在有道云筆記中用于文檔識別的實踐過程
這一兩年來,在移動端實現(xiàn)實時的人工智能已經(jīng)形成了一波潮流。去年,谷歌推出面向移動端和嵌入式的神經(jīng)網(wǎng)絡計算框架TensorFlowLite,將這股潮流繼續(xù)往前推。TensorFlowLite如何進行操作?本文將介紹TFLite在有道云筆記中用于文檔識別的實踐過程,以及 TFLite 都有些哪些特性,供大家參考。
近年來,有道技術團隊在移動端實時 AI 能力的研究上,做了很多探索及應用的工作。2017 年 11 月 Google 發(fā)布TensorFlowLite (TFLlite) 后,有道技術團隊第一時間跟進 TFLite 框架,并很快將其用在了有道云筆記產(chǎn)品中。
以下是TFLite在有道云筆記中用于文檔識別的實踐過程。
文檔識別工作的介紹
1. 文檔識別的定義
文檔識別最初是開發(fā)有道云筆記的文檔掃描功能時面對的一個問題。文檔掃描功能希望能在用戶拍攝的照片中,識別出文檔所在的區(qū)域,進行拉伸 (比例還原),識別出其中的文字,最終得到一張干凈的圖片或是一篇帶有格式的文字版筆記。實現(xiàn)這個功能需要以下這些步驟:
識別文檔區(qū)域:將文檔從背景中找出來,確定文檔的四個角;
拉伸文檔區(qū)域,還原寬高比:根據(jù)文檔四個角的坐標,根據(jù)透視原理,計算出文檔原始寬高比,并將文檔區(qū)域拉伸還原成矩形;
色彩增強:根據(jù)文檔的類型,選擇不同的色彩增強方法,將文檔圖片的色彩變得干凈清潔;
布局識別:理解文檔圖片的布局,找出文檔的文字部分;
OCR:將圖片形式的“文字”識別成可編碼的文字;
生成筆記:根據(jù)文檔圖片的布局,從 OCR 的結果中生成帶有格式的筆記。

文檔識別就是文檔掃描功能的第一步,也是場景最復雜的一個部分
2. 文檔識別在有道 AI 技術矩陣中的角色
有道近年來基于深度神經(jīng)網(wǎng)絡算法,在自然語言、圖像、語音等媒體數(shù)據(jù)的處理和理解方面做了一系列工作,產(chǎn)出了基于神經(jīng)網(wǎng)絡的多語言翻譯、OCR(光學字符識別)、語音識別等技術。在這些技術的合力之下,我們的產(chǎn)品有能力讓用戶以他們最自然最舒服的方式去記錄內(nèi)容,用技術去理解這些內(nèi)容,并將其統(tǒng)一轉化為文本以待下一步處理。從這個角度來看,我們的各種技術組成了以自然語言為中心,多種媒體形式相互轉換的網(wǎng)絡結構。
文檔識別是從圖像轉化為文本的這條轉換鏈上,不起眼卻又不可缺少的一環(huán)。有了它的存在,我們可以在茫茫圖海中,準確找到需要處理的文檔,并將其抽取出來進行處理。
3. 文檔識別的算法簡介
我們的文檔識別算法基于 FCNN (Fully Convolutional Neural Network) ,這是一種特別的 CNN(卷積神經(jīng)網(wǎng)絡),其特點是對于輸入圖片的每一個像素點,都對應著一個輸出(相對的,普通的 CNN 網(wǎng)絡則是每一張輸入圖片對應著一個輸出)。因此,我們可以標記一批包含文檔的圖片,將圖片中文檔邊緣附近的像素標注為正樣本,其他部分標注為副樣本。訓練時,以圖片作為 FCNN 的輸入,將輸出值與標注值作對比得到訓練懲罰,從而進行訓練。關于文檔識別算法的更多細節(jié),可以參見有道技術團隊的《文檔掃描:深度神經(jīng)網(wǎng)絡在移動端的實踐》這篇文章。
由于算法的主體是 CNN,因此文檔掃描算法中主要用到的算子(Operator)包括卷積層、Depthwise 卷積層、全連接層、池化層、Relu 層這些 CNN 中常用的算子。
4. 文檔識別與 TensorFlow
能夠訓練和部署 CNN 模型的框架非常多。我們選擇使用TensorFlow框架,是基于以下幾方面的考慮的:
TensorFlow 提供的算子全面且數(shù)量眾多,自己創(chuàng)建新的算子也并不麻煩。在算法研發(fā)的初期會需要嘗試各種不同的模型網(wǎng)絡結構,用到各種奇奇怪怪的算子。此時一個提供全面算子的框架能夠節(jié)省大量的精力;
TensorFlow能夠較好的覆蓋服務器端、Android 端、iOS 端等多個平臺,并在各個平臺上都有完整的算子支持;
TensorFlow是一個比較主流的選擇,這意味著當遇到困難時,更容易在互聯(lián)網(wǎng)上找到現(xiàn)成的解決辦法。
5. 為什么想在文檔識別中用 TFLite
在 TFLite 發(fā)布之前,有道云筆記中的文檔識別功能是基于移動端TensorFlow庫 (TensorFlowMobile) 的。當TFLite發(fā)布后,我們希望遷移到TFLite上。促使我們遷移的主要動力是鏈接庫的體積。
經(jīng)過壓縮后,Android 上的TensorFlow動態(tài)庫的體積大約是 4.5M 左右。如果希望滿足 Android 平臺下的多種處理器架構,可能需要打包 4 個左右的動態(tài)庫,加起來體積達到 18M 左右;而 tflite 庫的體積在 600K 左右,即便是打包 4 個平臺下的鏈接庫,也只需要占用 2.5M 左右的體積。這在寸土寸金的移動 App 上,價值是很大的。
TFLite的介紹
1. TFLite 是什么
TFLite 是 Google I/O 2017 推出的面向移動端和嵌入式的神經(jīng)網(wǎng)絡計算框架,于2017年11月5日發(fā)布開發(fā)者預覽版本 (developer preview)。相比與TensorFlow,它有著這樣一些優(yōu)勢:
輕量級。如上所述,通過 TFLite 生成的鏈接庫體積很小;
沒有太多依賴。TensorFlowMobile 的編譯依賴于 protobuf 等庫,而 tflite 則不需要大的依賴庫;
可以用上移動端硬件加速。TFLite 可以通過 Android Neural Networks API (NNAPI) 進行硬件加速,只要加速芯片支持 NNAPI,就能夠為 TFLite 加速。不過目前在大多數(shù) Android 手機上,Tflite 還是運行在 CPU 上的。
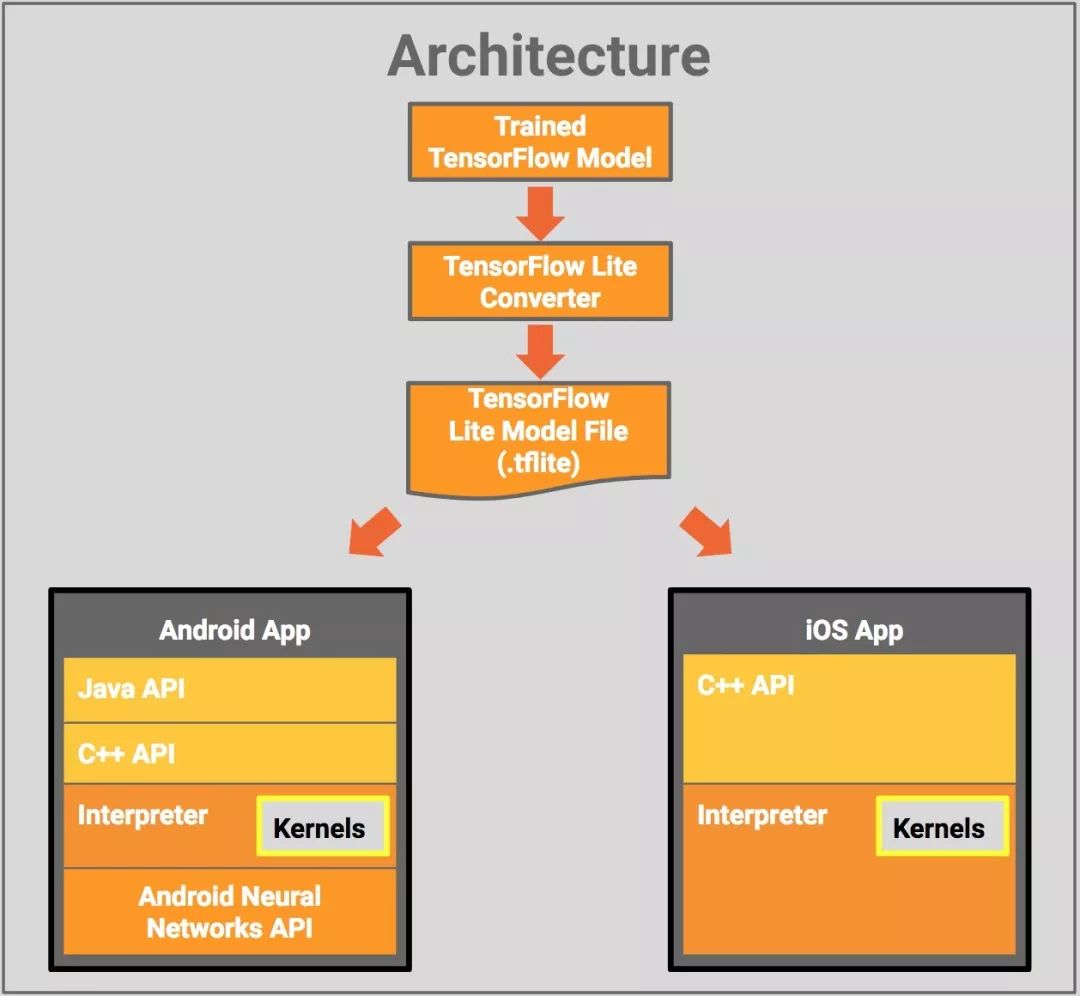
TensorFlow Lite的架構設計
2. TFLite 的代碼結構
作為 TFLite 的使用者,我們也探索了一下 TFLite 的代碼結構,這里分享一下。
目前,TFLite 的代碼位于TensorFlow工程中 "tensorflow/contrib/lite" 文件夾下。文件夾下有若干頭/源文件和一些子文件夾。
其中,一些比較重要的頭文件有:
model.h:和模型文件相關的一些類和方法。其中 FlatBufferModel 這個類是用來讀取并存儲模型內(nèi)容的,InterpreterBuilder 則可以解析模型內(nèi)容;
Interpreter.h:提供了用以推斷的類 Interpreter,這是我們最常打交道的類;
context.h:提供了存儲 Tensors 和一些狀態(tài)的 struct TfLiteContext。實際使用時一般會被包裝在 Interpreter 中;
此外,有一些比較重要的子文件夾:
kernels:算子就是在這里被定義和實現(xiàn)的。其中 regester.cc 文件定義了哪些算子被支持,這個是可以自定義的。
downloads:一些第三方的庫,主要包括:
abseil: Google 對 c++ 標準庫的擴展;
eigen: 一個矩陣運算庫;
farmhash: 做 hash 的庫;
flatbuffers: TFLite 所使用的 FlatBuffers 模型格式的庫;
gemmlowp: Google 開源的一個低精度矩陣運算庫;
neon_2_sse: 把 arm 上的 neon 指令映射到相對應的 sse 指令。
java:主要是 Android 平臺相關的一些代碼;
nnapi:提供了 nnapi 的調(diào)用接口。如果想自己實現(xiàn) nnapi 可以看一看;
schema:TFLite 所使用的 FlatBuffers 模型格式的具體定義;
toco:protobuf 模型轉換到 FlatBuffers 模型格式的相關代碼。
我們是怎么用TFLite的?
1. TFLite 的編譯
TFLite 可以運行在 Android 和 iOS 上,官方給出了不同的編譯流程。
在 Android 上,我們可以使用 bazel 構建工具進行編譯。bazel 工具的安裝和配置就不再贅述了,有過TensorFlow編譯經(jīng)驗的同學應該都熟悉。依照官方文檔,bazel 編譯的 target 是 "http://tensorflow/contrib/lite/java/demo/app/src/main:TfLiteCameraDemo",這樣得到的是一個 demo app。如果只想編譯庫文件,可以編譯 "http://tensorflow/contrib/lite/java:tensorflowlite" 這個 target,得到的是 libtensorflowlite_jni.so 庫和相應的 java 層接口。
更多細節(jié)見官方文檔:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/demo_android.md
在 iOS 上,則需要使用 Makefile 編譯。在 mac 平臺上運行 build_ios_universal_lib.sh,會編譯生成 tensorflow/contrib/lite/gen/lib/libtensorflow-lite.a 這個庫文件。這是個 fat library,打包了 x86_64, i386, armv7, armv7s, arm64 這些平臺上的庫。
更多細節(jié)見官方文檔:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/demo_ios.md
兩個平臺上 TFLite 庫的調(diào)用接口也有所不同:Android 上提供了 Java 層的調(diào)用接口,而 iOS 上則是 c++ 層的調(diào)用接口。
當然,TFLite 的工程結構是比較簡單的,如果你熟悉了 TFLite 的結構,也可以用自己熟悉的編譯工具來編譯 TFLite。
2. 模型轉換
TFLite 不再使用舊的 protobuf 格式(可能是為了減少依賴庫),而是改用 FlatBuffers 。因此需要把訓練好的 protobuf 模型文件轉換成 FlatBuffers 格式。
TensorFlow 官方給出了模型轉化的指導。首先,由于 TFLite 支持的算子比較少,更不支持訓練相關的算子,因此需要提前把不需要的算子從模型中移除,即 Freeze Graph ;接著就可以做模型格式轉換了,使用的工具是 tensorflow toco。這兩個工具也是通過 bazel 編譯得到。
更多細節(jié)見官方文檔:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/devguide.md
3. 缺失的算子
TFLite 目前僅提供有限的算子,主要以 CNN 中使用到的算子為主,如卷積、池化等。我們的模型是全卷積神經(jīng)網(wǎng)絡,大部分算子 TFLite 都有提供,但 conv2d_transpose(反向卷積)算子并沒有被提供。幸運的該算子出現(xiàn)在網(wǎng)絡模型的末端,因此我們可以將反向卷積之前的計算結果取出,自己用 c++ 實現(xiàn)一個反向卷積,從而計算出最終的結果。由于反向卷積的運算量并不大,所以基本沒有影響到運行速度。
如果不巧,你的模型需要但 TFLite 缺少的算子并非出現(xiàn)在網(wǎng)絡的末端,該怎么辦呢?你可以自定義一個 TFLite 算子,將其注冊在 TFLite 的 kernels 列表中,這樣編譯得到的 TFLite 庫就可以處理該算子了。同時,在模型轉換時,還需要加上 --allow_custom_ops 選項,將 TFLite 默認不支持的算子也保留在模型中。
更多細節(jié)見官方文檔:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/custom_operators.md
TFLite 優(yōu)缺點
優(yōu)點:在庫的大小、開發(fā)方便程度、跨平臺性、性能之間達成一個平衡
作為對比,有道技術團隊選取了一些其他的移動端深度學習框架,分別分析其在“開發(fā)方便程度、跨平臺性、庫的大小、性能”四個方面的表現(xiàn):
TensorFlowMobile,由于和 server 上的TensorFlow是同一套代碼,所以可以直接使用 server 上訓練得到的模型,開發(fā)非常方便;能支持 Android, iOS, 跨平臺性沒問題;如前所述,庫的大小比較大;性能主流。
caffe2,可以比較方便的從 caffe 訓練出的模型轉換到 caffe2 ,但缺少一些算子, 開發(fā)方便程度一般;能支持 Android, iOS,跨平臺性沒問題;庫編譯出來比較大,但是是靜態(tài)庫可以壓縮;性能主流。
Mental/Accelerate,這兩個都是 iOS 上的框架。比較底層,需要模型轉換&自己寫 inference 代碼,開發(fā)比較痛苦;僅支持 iOS;庫是系統(tǒng)自帶,不涉及庫大小問題;速度很快。
CoreML,這個是 WWDC17 發(fā)布的 iOS 11 上的框架。有一些模型轉換工具,只涉及通用算子時開發(fā)不算痛苦,涉及自定義算子時就很難辦了;僅支持 iOS 11 以上;庫是系統(tǒng)自帶,不涉及庫大小問題;速度很快。
最后是 TFLite:
TFLite,其模型可以由TensorFlow訓練得到的模型轉換而來,但缺少一些算子, 開發(fā)方便程度一般;能支持 Android, iOS,跨平臺性沒問題;庫編譯出來很小;就我們的實驗來看,速度比TensorFlow快一點。
可以看到,TensorFlowMobile 開發(fā)方便,通用性好,但鏈接庫大,性能主流(其他 server 端神經(jīng)網(wǎng)絡框架的 mobile 版也都有類似的特點);Mental/Accelerate 這些比較底層的庫速度很快,但不能跨平臺,開發(fā)比較痛苦;caffe2、TFLite 這類有為移動端優(yōu)化過的神經(jīng)網(wǎng)絡框架則比較平衡,雖然初時會有算子不全的問題,但只要背后的團隊不斷支持推進框架的開發(fā),這個問題未來會得到解決。
優(yōu)點:相對容易擴展
由于 TFLite 的代碼(相對于TensorFlow)比較簡單,結構比較容易理清,所以可以相對容易的去擴展。如果你想增加一個 TFLite 上沒有而TensorFlow上有的算子,你可以增加一個自定義的類;如果你想增加一個TensorFlow上也沒有的算子,你也可以直接去修改 FlatBuffers 模型文件。
缺點:ops 不夠全面
如前所述,TFLite 目前主要支持 CNN 相關的算子 ,對其他網(wǎng)絡中的算子還沒有很好的支持。因此,如果你想遷移 rnn 模型到移動端,TFLite 目前是不 OK 的。
不過根據(jù)最新的Google TensorFlow開發(fā)者峰會,Google和TensorFlow社區(qū)正在努力增加ops的覆蓋面,相信隨著更多開發(fā)者的相似需求, 更多的模型會被很好的支持。這也是我們選擇TensorFlow這樣的主流社區(qū)的原因之一。
缺點:目前還不能支持各種運算芯片
雖然 TFLite 基于 NNAPI,理論上是可以利用上各種運算芯片的,但目前還沒有很多運算芯片支持 NNAPI。期待未來 TFLite 能夠支持更多的運算芯片,畢竟在 CPU 上優(yōu)化神經(jīng)網(wǎng)絡運行速度是有上限的,用上定制芯片才是新世界的大門。
總結
這一兩年來,在移動端實現(xiàn)實時的人工智能似乎已經(jīng)形成了一波潮流。有道技術團隊在移動端 AI 算法的研究上,也做了諸多嘗試,推出了離線神經(jīng)網(wǎng)絡翻譯 (離線 NMT) 、離線文字識別 (離線 OCR) 以及離線文檔掃描等移動端實時 AI 能力,并在有道詞典、有道翻譯官、有道云筆記中進行產(chǎn)品化應用。由于目前移動端 AI 尚處在蓬勃發(fā)展階段,各種框架、計算平臺等都尚不完善。
在這里,我們以有道云筆記中的離線文檔識別功能作為實踐案例,看到了 TFLite 作為一個優(yōu)秀的移動端AI框架,能夠幫助開發(fā)者相對輕松地在移動端實現(xiàn)常見的神經(jīng)網(wǎng)絡。后續(xù)我們也會為大家?guī)砀嘤械兰夹g團隊結合 TFLite 在移動端實時 AI 方面的技術探索以及實際產(chǎn)品應用。
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4779瀏覽量
101052 -
人工智能
+關注
關注
1795文章
47642瀏覽量
239703
原文標題:玩轉TensorFlow Lite:有道云筆記實操案例分享
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
云脈文檔識別在教育行業(yè)中的應用
ELMOS用于手勢識別的光電傳感器E527.16
如何去實現(xiàn)基于HTTPClient云語音識別的POST請求功能呢
分享一種在ART-Pi Smart上進行車標識別的設計方案
使用OpenCV進行車牌數(shù)字識別的資料免費下載
虹膜識別技術的過程_虹膜識別的發(fā)展歷程
使用Python實現(xiàn)車牌識別的程序免費下載







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論