 谷歌推出新的移動框架MobileNetV2提高多種計算機視覺任務
谷歌推出新的移動框架MobileNetV2提高多種計算機視覺任務
當地時間4月3日,谷歌推出了一款新的移動框架MobileNetV2,基于上一代MobileNet,這款模型能顯著提高多種計算機視覺任務。
去年我們推出了MobileNetV1,這是一款為移動設備而設計的通用計算機視覺神經網絡模型,它有分類、檢測等功能。這種可以在個人移動設備上運行深度網絡的能力極大地提升了用戶體驗,不僅能隨時隨地訪問,還非常安全、私密、省電。隨著新應用的出現,用戶可以與現實世界進行實時交互,同樣對更高效的深度網絡也有更多的需求。
今天,我們很高興宣布MobileNetV2已經可以支持下一代移動視覺應用。MobileNetV2在MobileNetV1上做出了重大改進,并推動了目前移動設備的視覺識別技術的發展,包括圖像分類、檢測和語義分割。MobileNetV2作為TensorFlow-Slim圖像分類庫的一部分發布,或者您可以在Colaboratory中探索MobileNetV2。另外,您還可以利用Jupyter下載筆記本并進行使用。MobileNetV2也可以作為TF-Hub上的模塊使用,預訓練的檢查點可以在GitHub上找到。
MobileNetV2的創建基于MobileNetV1的思想,使用深度可分離卷積作為高效的構建模塊。然而,V2在架構中引入了兩種新特征:
圖層間的線性瓶頸層
瓶頸層之間的快捷連接
基本結構如圖所示:

可以看到,瓶頸對模型的中間輸入和輸出進行編碼,而內層包括了模型能將低級概念(如像素)轉換為高級描述符(如圖像類別)的能力。最后,剩余的連接和傳統一樣,快速連接可實現更快的訓練速度和更高的準確性。具體細節可以查看論文:MobileNetV2:Inverted Residuals and Linear Bottlenecks:https://arxiv.org/abs/1801.04381。
它與第一代MobileNets相比如何?
總體而言,在整個延遲頻譜中,MobileNetV2模型在相同精度下的速度更快。特別的是,新模型所用的操作次數減少了2次,參數減少了30%,在谷歌pixel手機上的速度比V1快了30%~40%,同時達到了更高的準確性。
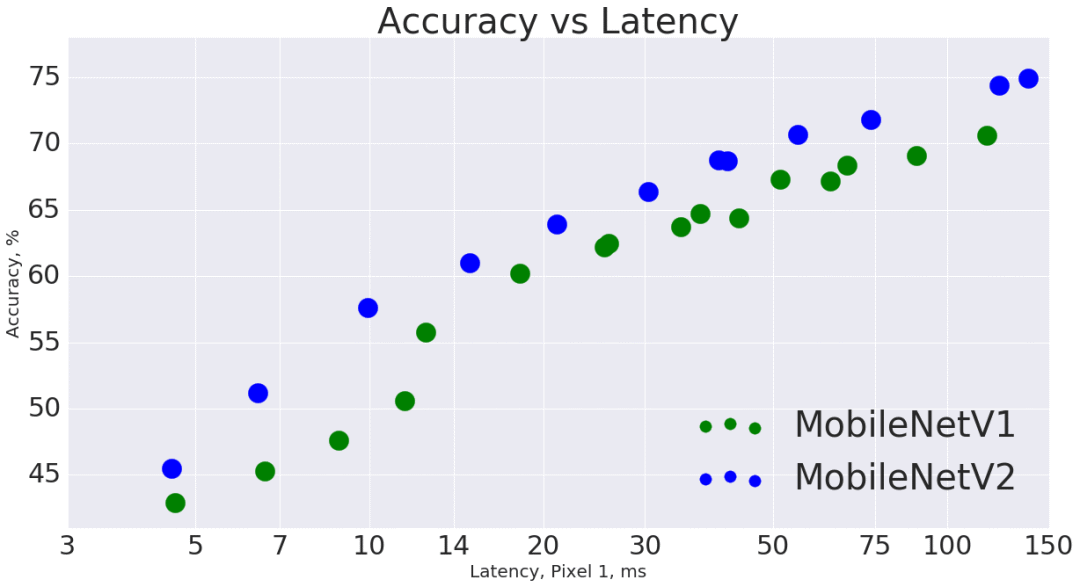
MobileNetV2在目標物體檢測和分割時是一個非常高效的特征提取器。例如,當與新發布的SSDLite合作進行物體檢測時,新模型在做到與V1同樣準確的情況下,速度快了35%。我們已經在TensorFlow目標物體檢測API中開源了此模型。

為支持移動設備的語義分割,我們將MobileNetV2當做特征提取器安裝在簡化版的DeepLabv3上。在語義分割的基準PASCAL VOC 2012中,我們的結果與將V1作為特征提取器實現了相似的性能,但是參數少了5.3倍,在乘加運算上操作次數減少了5.2倍。

由此可見,MobileNetV2作為許多視覺識別任務的基礎,是移動設備上高效的模型。我們希望與學術界和開源社區共享,以此幫助更多人的研究和應用發展。
-
谷歌
+關注
關注
27文章
6192瀏覽量
105810 -
計算機視覺
+關注
關注
8文章
1700瀏覽量
46074
原文標題:谷歌推出MobileNetV2,為下一代移動設備CV網絡而生
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺技術的AI算法模型
計算機視覺的五大技術
計算機視覺的工作原理和應用
機器人視覺與計算機視覺的區別與聯系
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺和機器視覺區別在哪
深度學習在計算機視覺領域的應用
機器視覺與計算機視覺的區別
計算機視覺的主要研究方向
計算機視覺的十大算法






 工商網監
工商網監
評論