 物體檢測經典模型YOLO新升級,YOLOv3是一個很好的檢測器
物體檢測經典模型YOLO新升級,YOLOv3是一個很好的檢測器
你肯定很少見到這樣的論文,全文像閑聊一樣,不愧是YOLO的發明者。物體檢測領域的經典論文YOLO(You Only Look Once)的兩位作者,華盛頓大學的Joseph Redmon和Ali Farhadi最新提出了YOLO的第三版改進YOLO v3,一系列設計改進,使得新模型性能更好,速度更快。達到相似的性能時,相比SSD,速度提高3倍;相比RetinaNet,速度提高3.8倍。
我今年沒怎么做研究。我花了很多時間玩Twitter。玩了一下GAN。我去年留下了一些工作[10] [1]; 我設法對YOLO進行了一些改進。但是,說實話,不是什么超級有趣的工作,只是做了一系列更新,使它變得更好。我也有幫其他人做了一些研究。
沒有錯,你看的確實是一篇論文的開頭。
今天,為你帶來一篇不走尋常路的工作,計算機視覺經典模型YOLO作者的更新。
不只是開頭,整片文章到處都嵌入詼諧,在結尾處還不忘告訴讀者,不要@他。
放心,大多數研究計算機視覺的人都只是做點令人愉快的、好的事情,比如計算國家公園里斑馬的數量[11],或者追蹤溜進他們院子時的貓[17]。但是計算機視覺已經被用于被質疑的使用,作為研究人員,我們有責任至少思考一下我們的工作可能造成的損害,并思考如何減輕這種損害。我們非常珍惜這個世界。
那么,在作者沉浸Twitter的一年里,他們對YOLO做了哪些更新呢?

我們對YOLO進行了一些更新!我們做了一些小設計,使它的表現更好。我們還對這個新網絡進行了訓練。更新版的YOLO網絡比上一版本稍大,但更準確。它的速度也還是很快,這點不用擔心。在320 × 320下,YOLOv3以22.2 mAP在22 ms運行完成,達到與SSD一樣的精確度,但速度提高了3倍。與上個版本的 0.5 IOU mAP檢測指標相比,YOLOv3的性能是相當不錯的。在Titan X上,它在51 ms內達到57.9 AP50,而RetinaNet達到57.5 AP50需要198 ms,性能相似,但速度提升3.8倍。
我今年沒怎么做研究。我花了很多時間玩Twitter。玩了一下GAN。我去年留下了一些工作[10] [1]; 我設法對YOLO進行了一些改進。但是,說實話,不是什么超級有趣的工作,只是做了一系列更新,使它變得更好。我也有幫其他人做了一些研究。
這篇文章接下來將介紹YOLOv3,然后我會告訴你我們是怎么做的。我還會寫一下我們嘗試過但失敗了的操作。最后,我們將思考這一切意味著什么。
YOLOv3
關于YOLOv3:我們主要是從其他人那里獲得好點子。我們還訓練了一個更好的新的分類網絡。本文將從頭開始介紹整個系統,以便大家理解。
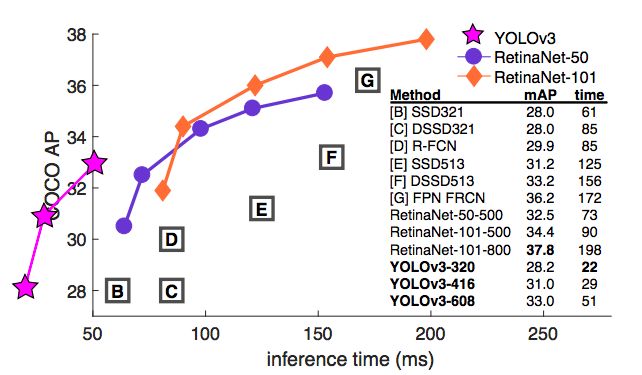
圖1:這張圖是從Focal Loss論文[7]拿來并修改的。 YOLOv3的運行速度明顯快于其他性能相似的檢測方法。運行時間來自M40或Titan X,基本上用的是相同的GPU。
邊界框預測
在YOLO9000之后,我們的系統使用維度聚類(dimension cluster)作為anchor box來預測邊界框[13]。網絡為每個邊界框預測4個坐標,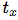
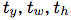 如果單元格從圖像的左上角偏移了
如果單元格從圖像的左上角偏移了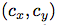 ,并且之前的邊界框具有寬度
,并且之前的邊界框具有寬度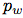 和高度
和高度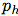 ,則預測對應以下等式:
,則預測對應以下等式:
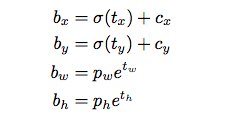
在訓練期間,我們使用平方誤差損失的和。如果一些坐標預測的ground truth是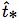 ,梯度就是ground truth值(從ground truth box計算出來)減去預測,即:?
,梯度就是ground truth值(從ground truth box計算出來)減去預測,即:?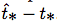 。 通過翻轉上面的方程可以很容易地計算出這個ground truth值。
。 通過翻轉上面的方程可以很容易地計算出這個ground truth值。
YOLOv3使用邏輯回歸來預測每個邊界框的 objectness score。如果邊界框比之前的任何其他邊界框都要與ground truth的對象重疊,則該值應該為1。如果先前的邊界框不是最好的,但確實與ground truth對象重疊超過某個閾值,我們會忽略該預測,如Faster R-CNN一樣[15]。我們使用.5作為閾值。 但與[15]不同的是,我們的系統只為每個ground truth對象分配一個邊界框。如果先前的邊界框未分配給一個ground truth對象,則不會對坐標或類別預測造成損失,只會導致objectness。
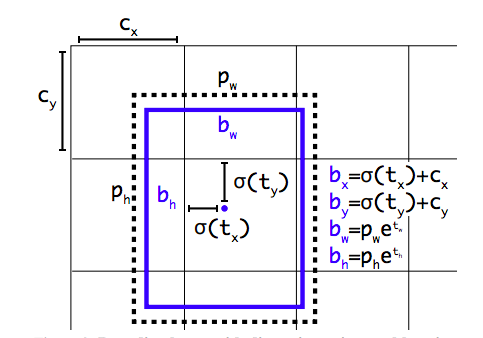
圖2: 具有dimension priors和location prediction的邊界框。我們預測了框的寬度和高度,作為cluster centroids的偏移量。我們使用sigmoid函數預測相對于濾波器應用位置的邊界框的中心坐標。這個圖是從YOLO9000論文[13]拿來的。
類別預測
每個框使用多標簽分類來預測邊界框可能包含的類。我們不使用softmax,因為我們發現它對于性能沒有影響,而是只是使用獨立的邏輯分類器。在訓練過程中,我們使用二元交叉熵損失來進行類別預測。
這個公式有助于我們轉向更復雜的領域,如Open Images數據集[5]。在這個數據集中有許多重疊的標簽(例如,Woman和Person)。可以使用softmax強加一個假設,即每個box只包含一個類別,但通常情況并非如此。多標簽方法可以更好地模擬數據。
不同尺度的預測
YOLOv3可以預測3種不同尺度的box。我們的系統使用一個特征金字塔網絡[6]來提取這些尺度的特征。在基本特征提取器中,我們添加了幾個卷積層。其中最后一層預測三維tensor編碼的邊界框,objectness 和類別預測。我們在COCO[8]數據集的實驗中,每個尺度預測3個box,因此tensor為N×N×[3 *(4 + 1 + 80)],4個邊界框offset,1 objectness預測,以及80個類別預測。
接下來,我們從之前的2個層中取得特征圖,并對其進行2倍上采樣。我們還從網絡獲取特征圖,并使用 element-wise 添加將其與我們的上采樣特征進行合并。這種方法使我們能夠從上采樣的特征和早期特征映射的細粒度信息中獲得更有意義的語義信息。然后,我們再添加幾個卷積層來處理這個組合的特征圖,并最終預測出一個相似的Tensor,雖然現在它的大小已經增大兩倍。
我們再次執行相同的設計來對最終的scale預測box。因此,我們對第3個scale的預測將從所有之前的計算中獲益,并從早期的網絡中獲得精細的特征。
我們仍然使用k-means聚類來確定bounding box priors。我們只是選擇了9個clusters和3個scales,然后在整個scales上均勻分割clusters。在COCO數據集上,9個cluster分別為(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90) ,(156×198),(373×326)。
特征提取器
我們使用一個新的網絡來執行特征提取。該新網絡是用于YOLOv2,Darknet-19的網絡和更新的殘差網絡的混合方法。我們的網絡使用連續的3×3和1×1卷積層,但現在也有一些shortcut連接,并且網絡的大小顯著更大。它有53個卷積層,所以我們稱之為......Darknet-53!

這個新網絡比Darknet19強大得多,而且比ResNet-101或ResNet-152更高效。以下是在ImageNet上的結果:
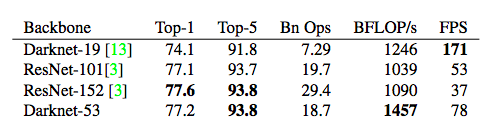
表2:網絡的比較。各網絡的準確性、Bn Ops、每秒浮點運算次數,以及FPS。
每個網絡都使用相同的設置進行訓練,并在256×256的單精度進行測試。Runtime是在Titan X上以256×256進行測量的。可以看到,Darknet-53可與最先進的分類器相媲美,但浮點運算更少,速度更快。Darknet-53比ResNet-101性能更好,而且速度快1.5倍。Darknet-53與ResNet-152具有相似的性能,速度提高2倍。
Darknet-53也可以實現每秒最高的測量浮點運算。這意味著網絡結構可以更好地利用GPU,從而使其評估效率更高,速度更快。這主要是因為ResNets的層數太多,效率不高。
訓練
我們仍然用完整的圖像進行訓練。我們使用不同scale進行訓練,使用大量的數據增強,批規范化,等等。我們使用Darknet神經網絡框架進行訓練和測試[12]。
具體做法和結果
YOLOv3的表現非常好!請參見表3。就COCO奇怪的平均mean AP指標而言,它與SSD的變體性能相當,但速度提高了3倍。不過,它仍比RetinaNet模型差一些。
當時,以mAP的“舊”檢測指標比較時,當IOU = 0.5(或表中的AP50)時,YOLOv3非常強大。它的性能幾乎與RetinaNet相當,并且遠高于SSD的變體。這表明YOLOv3是一個非常強大的對象檢測網絡。不過,隨著IOU閾值增大,YOLOv3的性能下降,使邊界框與物體完美對齊的效果不那么好。
過去,YOLO不擅長檢測較小的物體。但是,現在我們看到了這種情況已經改變。由于新的多尺度預測方法,我們看到YOLOv3具有相對較高的APS性能。但是,它在中等尺寸和更大尺寸的物體上的表現相對較差。
當用AP50指標表示精確度和速度時(見圖3),可以看到YOLOv3與其他檢測系統相比具有顯著的優勢。也就是說,YOLOv3更快、而且更好。
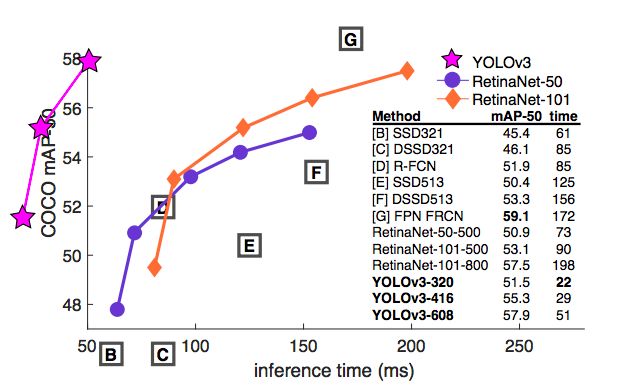
圖3
一些試了沒用的方法
我們在研究YOLOv3時嘗試了很多方法。很多都不起作用。這些可以了解一下。
Anchor box x,y 偏移量預測。我們嘗試使用常規的anchor box預測機制,可以使用線性激活將x,y的偏移預測為box的寬度或高度的倍數。我們發現這種方法降低了模型的穩定性,并且效果不佳。
線性x,y預測,而不是邏輯預測。我們嘗試使用線性激活來直接預測x,y的偏移,而不是用邏輯激活。這導致了MAP的下降。
Focal loss。我們嘗試使用Focal loss。這一方法使mAP降低了2點左右。YOLOv3對Focal loss解決的問題可能已經很強健,因為它具有單獨的對象預測和條件類別預測。因此,對于大多數例子來說,類別預測沒有損失?或者其他原因?這點還不完全確定。
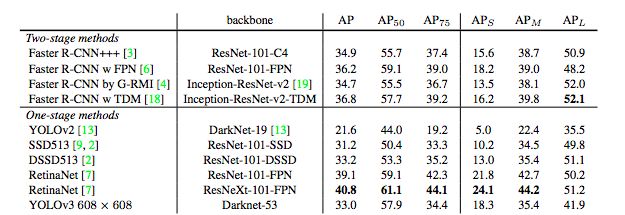
表3:再次,這張圖來自論文[7],稍作了調整。這里顯示的速度/準確度在mAP上以0.5 IOU度量進行折衷。你可以看到,YOLOv3很厲害,因為它非常高,而且離左軸遠。
雙IOU閾值和truth分配。 Faster RCNN在訓練期間使用兩個IOU閾值。如果一個預測與.7的 ground truth 重疊,它就是一個正面的例子,[.3-.7]它被忽略。如果對于所有ground truth對象,它都小于.3,這就是一個負面的例子。我們嘗試了類似的策略,但無法取得好的結果。
這一切意味著什么
YOLOv3是一個很好的檢測器。速度很快,而且很準確。在COCO上,平均AP介于0.5和0.95 IOU時,準確度不是很好。但是,對于0.5 IOU這個指標來說,YOLOv3非常好。
為什么我們要改變指標?原始的COCO論文上只有這樣一句含糊不清的句子:“一旦評估服務器完成,我們會添加不同評估指標的完整討論”。Russakovsky等人在論文中說,人類很難區分0.3與0.5的IOU。“人們目測檢查一個IOU值為0.3的邊界框,并將它與IOU 0.5的區分開來,這是非常困難的事情。”[16]如果人類都很難區分這種差異,那么它就沒有那么重要。
也許更值得思考的問題是:“現在我們有了這些檢測器,我們拿它們來做什么?”很多做這類研究的人都在Google或Facebook工作。我想至少我們已經知道這項技術已經被掌握得很好了,絕對不會用來收集你的個人信息并將其出售給....等等,你說這正是它的目的用途?Oh.
放心,大多數研究計算機視覺的人都只是做點令人愉快的、好的事情,比如計算國家公園里斑馬的數量[11],或者追蹤溜進他們院子時的貓[17]。但是計算機視覺已經被用于被質疑的使用,作為研究人員,我們有責任至少思考一下我們的工作可能造成的損害,并思考如何減輕這種損害。我們非常珍惜這個世界。
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46075 -
K-means
+關注
關注
0文章
28瀏覽量
11324
原文標題:【史上最有趣論文】物體檢測經典模型YOLO新升級,就看一眼,速度提升 3 倍!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv3的紅綠燈檢測識別(Python源碼可直接運行)
《DNK210使用指南 -CanMV版 V1.0》第四十一章 YOLO2物體檢測實驗
基于RK3399pro開發板的YOLOV3開發與實現
全志V853 在 NPU 轉換 YOLO V3 模型
NDIR氣體檢測器解決方案和PID氣體檢測器解決方案
基于YOLOV3算法的視頻監控目標檢測方法
基于神經網絡的、改進的YOLOv3目標檢測算法

一階段的物體檢測器,從直覺到細節的方方面面(一)

深度學習YOLOv3 模型設計的基本思想

采用華為云 Flexus 云服務器 X 實例部署 YOLOv3 算法完成目標檢測






 工商網監
工商網監
評論