

本文轉(zhuǎn)載于極術(shù)社區(qū)
作者:非典型程序員
Ringbuffer(循環(huán)緩存)是軟件中非常常用的數(shù)據(jù)結(jié)構(gòu)之一, 在互聯(lián)網(wǎng)應(yīng)用、數(shù)據(jù)庫應(yīng)用等中使用廣泛。處理器執(zhí)行 Ringbuffer 的效率與其存儲系統(tǒng)處理共享數(shù)據(jù)的性能息息相關(guān)。
本文旨在介紹 Ringbuffer 的性能優(yōu)化方法。本文介紹基于 mutex 的 Ringbuffer 實(shí)現(xiàn)、阻塞的無鎖實(shí)現(xiàn)以及非阻塞的無鎖實(shí)現(xiàn),并且比較和分析這些不同的實(shí)現(xiàn)在 Arm 服務(wù)器平臺上的性能。
聲明:本文介紹的針對 Ringbuffer 實(shí)現(xiàn)的優(yōu)化方法來自于 Ola Liljedahl 的研究。Ola 現(xiàn)任 Arm 公司的架構(gòu)師,長期專注于網(wǎng)絡(luò)軟件的性能優(yōu)化設(shè)計(jì),尤其是可擴(kuò)展的多線程共享存儲編程。針對 Arm A 系列處理的多線程性能,他開發(fā)了一個可擴(kuò)展的多線程并行庫progress64(github.com/ARM-software/progress64)。
本文分析了 Ola 提出的主要優(yōu)化手段,并且在 Arm服務(wù)器上重現(xiàn)了 Ola 的優(yōu)化以驗(yàn)證其實(shí)際效果。博客中使用的代碼只是示例代碼(https://github.com/wangeddie67/ringbuffer_opt_demo),其功能完備性和魯棒性都不能滿足實(shí)際應(yīng)用的需求。
介紹
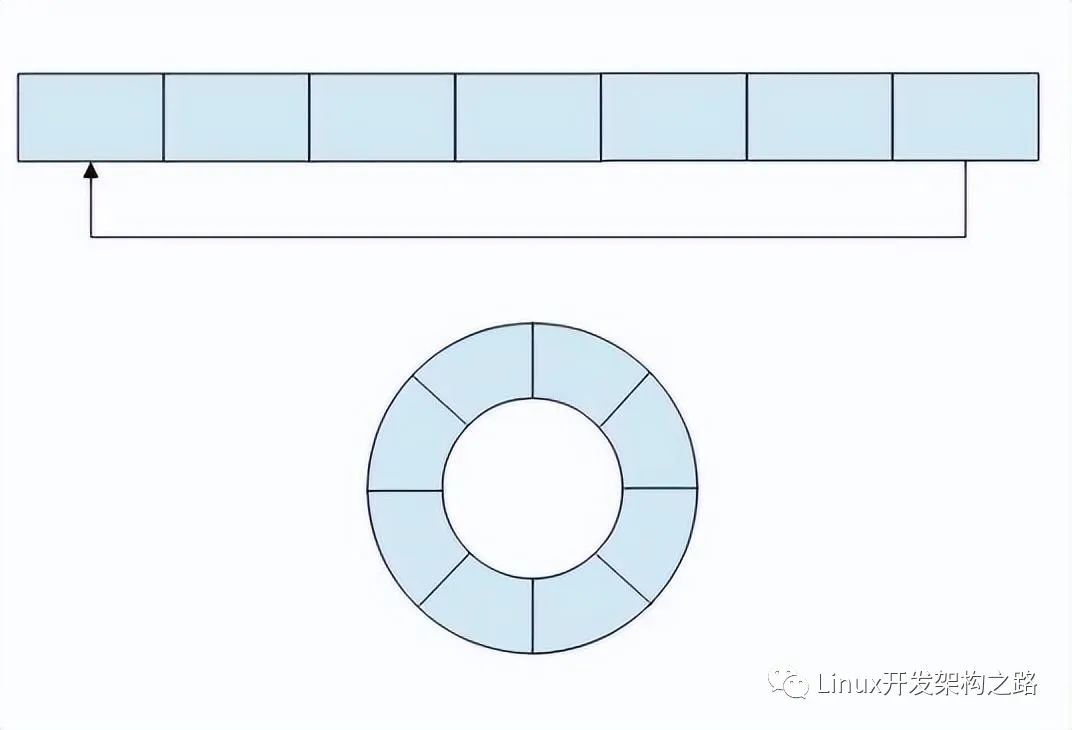
Ringbuffer 通常由一個包含數(shù)據(jù)的數(shù)組和指向隊(duì)列頭(Head)和隊(duì)尾(Tail)的指針構(gòu)成(如圖 1 左邊所示)。指針只能按照一個方向移動。當(dāng)指針移動到數(shù)組結(jié)尾時,指針會折回到隊(duì)列開始。
Head 指針表示下一個可以彈出的數(shù)據(jù);當(dāng)數(shù)據(jù)彈出隊(duì)列(稱為 Dequeue)時,Head 指針加 1。Tail 指針表示下一個可以壓入數(shù)據(jù)的單元;當(dāng)數(shù)據(jù)壓入隊(duì)列(稱為 Enqueue)時,Tail 指針加 1;
從邏輯上看,Ringbuffer 中的數(shù)組形成了一個環(huán)(如圖 1 右邊所示)。頭和尾指針在這個環(huán)上沿著相同的方向移動。這就是 Ringbuffer 名稱的由來。
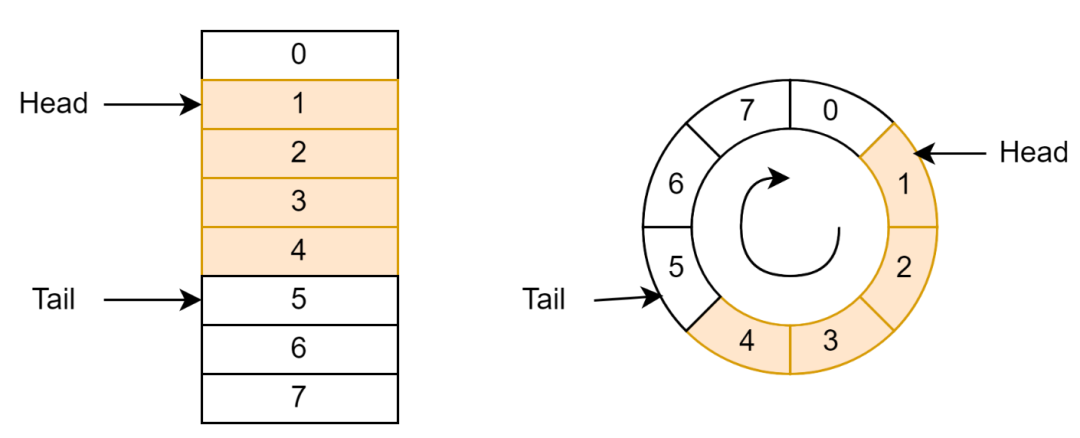
圖 1 Ringbuffer 示意圖
向 Ringbuffer 壓入單元的程序稱為生產(chǎn)者(Producer),從 Ringbuffer 彈出單元的程序稱為消費(fèi)者(Consumer),如圖 2 所示。一個 Ringbuffer 通常具有很多的生產(chǎn)者和消費(fèi)者,每個生產(chǎn)者和消費(fèi)者都是不同的線程或進(jìn)程。這些線程或進(jìn)程會被調(diào)度到系統(tǒng)中的不同處理器核心上,而 Ringbuffer 則是不同處理器核心之間共享的數(shù)據(jù)。
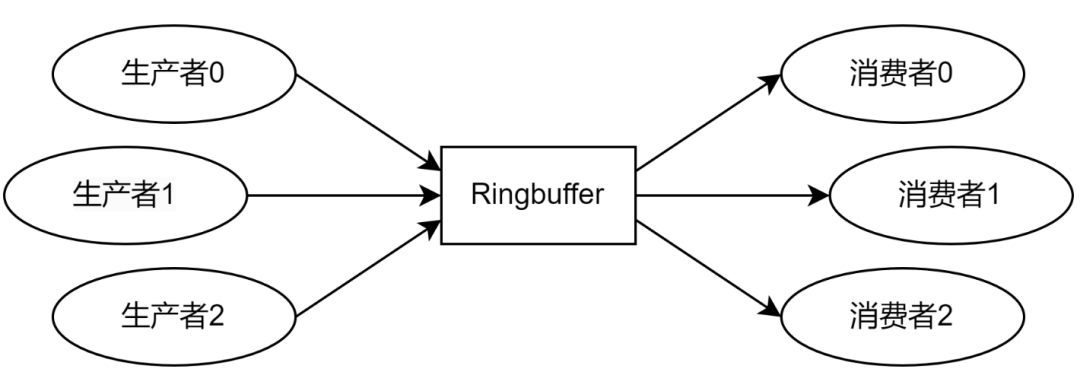
圖 2 生產(chǎn)者和消費(fèi)者
基于 Mutex 的 Ringbuffer 實(shí)現(xiàn)
為了保證共享數(shù)據(jù)的功能正確,通常使用 mutex 來進(jìn)行保護(hù) Ringbuffer,以保證只有一個生產(chǎn)者或消費(fèi)者能夠訪問或操作 Ringbuffer。
基于 Mutex 的 Ringbuffer 聲明
Ringbuffer 的數(shù)據(jù)結(jié)構(gòu)如代碼塊 1 所示。
// Entry in ring buffer
class BufferEntry
{
public:
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
int m_mutex; // Mutex for shared pointers.
unsigned int m_size; // The number of physical entries.
unsigned int m_head; // Head pointer.
unsigned int m_tail; // Tail pointer.
BufferEntry *mp_entries; // Pointer to physical entries.
};
代碼 1 基于 Mutex 的 Ringbuffer 聲明
數(shù)據(jù)數(shù)組中每個單元BufferEntry只提供一個指針,指針指向?qū)嶋H需要進(jìn)入 Ringbuffer 的數(shù)據(jù)結(jié)構(gòu)。當(dāng) Enqueue 和 Dequeue 時,只需要復(fù)制數(shù)據(jù)結(jié)構(gòu)的指針即可,而不需要復(fù)制數(shù)據(jù),從而減少數(shù)據(jù)拷貝的開銷。
基于 Mutex 的 Ringbuffer 的 Enqueue 和 Dequeue 函數(shù)
圖 3 展示了 Enqueue 和 Dequeue 的流程圖。圖 3 左邊展示的是阻塞操作的流程圖;右邊展示的是非阻塞操作的流程圖。如果實(shí)現(xiàn)的是阻塞式的操作,那么函數(shù)一直重復(fù)檢查空滿條件,直到 Ringbuffer 的滿足操作所需的空滿條件;如果實(shí)現(xiàn)的是非阻塞式的操作,那么函數(shù)可以在檢查空滿條件失敗后直接退出。
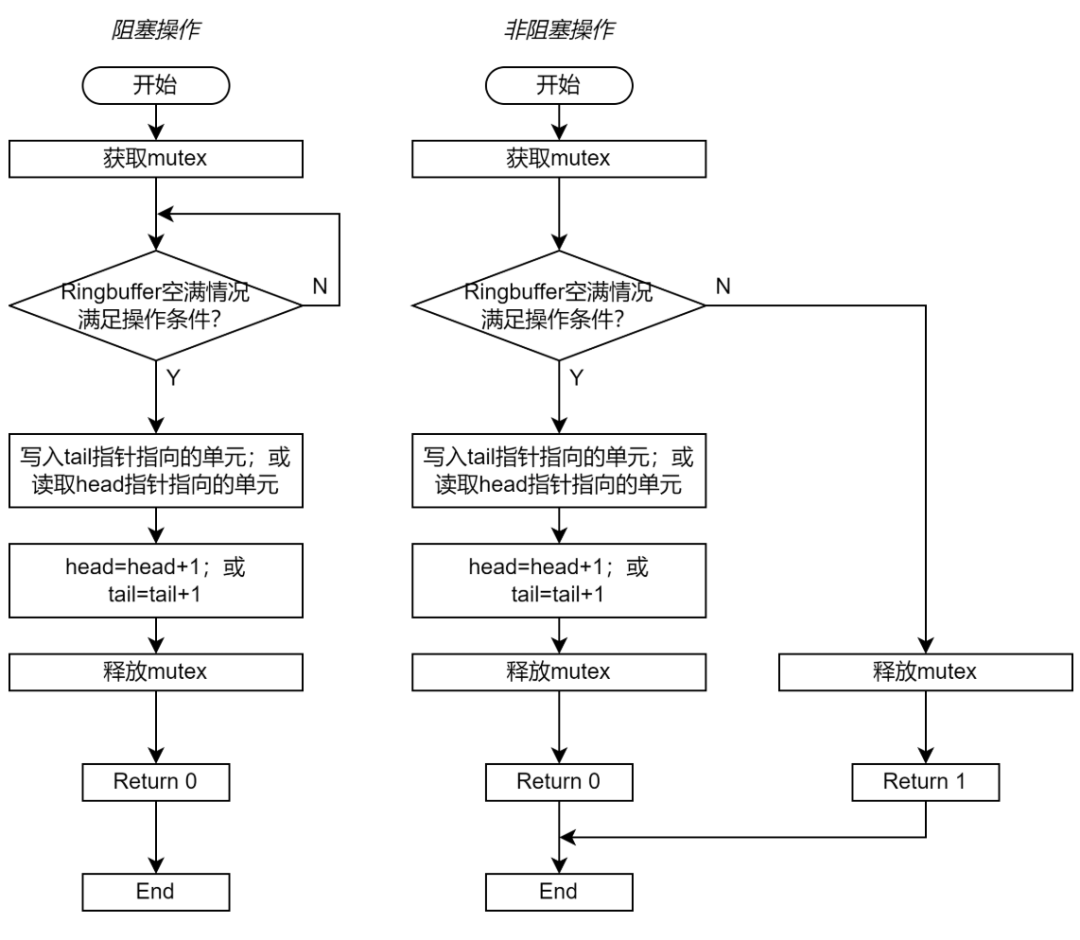
圖 3 基于 Mutex 的 Ringbuffer 實(shí)現(xiàn)流程圖
循環(huán)隊(duì)列的空滿控制有很多種方法。在本系列文章的示例中采用邏輯單元和物理單元的控制方法。head 和 tail 的范圍并不只限于物理單元的數(shù)量,而是可以一直累加。訪問單元時,將(head MOD size)或(tail MOD size)得到對應(yīng)的物理單元。
對于 Enqueue 操作,需要 Ringbuffer 不為滿,即m_head+m_size!=m_tail(head 和 tail 之差不大于物理單元的數(shù)量)。
對于 Dequeue 操作,需要Ringbuufer 不為空,即m_head!=m_tail (head 和 tail 沒有指向同一個單元)。
基于 Mutex 的 Ringbuffer 實(shí)現(xiàn)如下:
// Blocking Enqueue Function int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry) { // Lock mutex. lock(&ring_buffer->m_mutex); // Ringbuffer is full. Do nothing. while (ring_buffer->m_head + ring_buffer->m_size == ring_buffer->m_tail); // Enqueue entry. int enq_ptr = ring_buffer->m_tail % ring_buffer->m_size; ring_buffer->mp_entries[enq_ptr].mp_ptr = entry; // Increase tail pointer. ring_buffer->m_tail = ring_buffer->m_tail + 1; // Unlock mutex. unlock(&ring_buffer->m_mutex); return 0; } // Blocking Dequeue Function int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry) { // Lock mutex. lock(&ring_buffer->m_mutex); // Ringbuffer is empty. Do nothing. while (ring_buffer->m_head == ring_buffer->m_tail); // Dequeue entry. int deq_ptr = ring_buffer->m_head % ring_buffer->m_size; *entry = ring_buffer->mp_entries[deq_ptr].mp_ptr; ring_buffer->mp_entries[deq_ptr].mp_ptr = NULL; // Increase head pointer. ring_buffer->m_head = ring_buffer->m_head + 1; // Unlock mutex. unlock(&ring_buffer->m_mutex); return 0; }
代碼 2 基于 Mutex 的 Ringbuffer 實(shí)現(xiàn)
Lock 和 Unlock
Ringbuffer 最多允許一個生產(chǎn)者或一個消費(fèi)者對于 Ringbuffer 進(jìn)行操作。這需要通過鎖標(biāo)志m_mutex進(jìn)行控制。考慮到 pthread 中的 mutex API 引入的系統(tǒng)調(diào)度開銷過大,這里采用__sync_val_compare_and_swap原語實(shí)現(xiàn) lock 和 unlock 操作。
type __sync_val_compare_and_swap(type* ptr, type oldval, type newval);
__sync_val_compare_and_swap原語提供了同步和原子 CAS 操作兩個功能,其功能核心是 CASAL 指令。原語將ptr指向的變量與oldval比較,如果值相同則將ptr指向的變量修改為newval,并返回ptr指向變量的舊值;反之,則不修改ptr指向的變量,并返回ptr指向變量的值。同時,原語保證了 load/store 的同步,即在指令序上先于原語的 load/store 已經(jīng)完成,指令序上晚于原語的 load/store 不會執(zhí)行。
用__sync_val_compare_and_swap原語實(shí)現(xiàn)的 lock 和 unlock 功能如下:
// Lock function
void lock(int *mutex)
{
while (__sync_val_compare_and_swap(mutex, 0, 1) != 0)
{
}
}
// Unlock function
void unlock(int *mutex)
{
__sync_val_compare_and_swap(mutex, 1, 0);
}
代碼 3 lock 和 unlock 函數(shù)的實(shí)現(xiàn)
mutex變量為 0 表示mutex釋放;變量為 1 表示mutex鎖定。在 lock 函數(shù)中,如果當(dāng)前mutex為 0(釋放),則更新為 1(鎖定),并且 lock 函數(shù)返回 0;反之則 lock 函數(shù)返回 1。 基于 mutex 的 ringbuffer 實(shí)現(xiàn)的完整源碼請參見(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/mutex_blkring.h)。
測試框架
測試程序包含一個控制測試過程的主線程和多個充當(dāng)生產(chǎn)者和消費(fèi)者的子線程。主線程首先創(chuàng)建并初始化 Ringbuffer,并且創(chuàng)建指定數(shù)量的子線程,最后等待子線程結(jié)束。子線程數(shù)量可以配置。 每個子線程即使生產(chǎn)者也是消費(fèi)者。每次測試迭代從隊(duì)列中讀取一個單元,再將這個單元(不做額外操作)插入隊(duì)尾,即一次 Dequeue 和一次 Enqueue 操作。整個測試過程需要執(zhí)行的 Enqueue 和 Dequeue 操作數(shù)量相同。如果將一部分線程設(shè)置為生產(chǎn)者,另一部分線程設(shè)置為消費(fèi)者,那么數(shù)據(jù)單元一定由生產(chǎn)者向消費(fèi)者移動。這可能在互聯(lián)結(jié)構(gòu)中出現(xiàn)具有方向性的數(shù)據(jù)流,從而加強(qiáng)測試結(jié)果與線程調(diào)度的核心的物理位置的關(guān)系。 為了保證子線程同步啟動測試,子線程首先會陷入 barrier。當(dāng)所有子程序都創(chuàng)建完成后,子線程從 barrier 退出。每個線程執(zhí)行的測試迭代數(shù)量都相同。
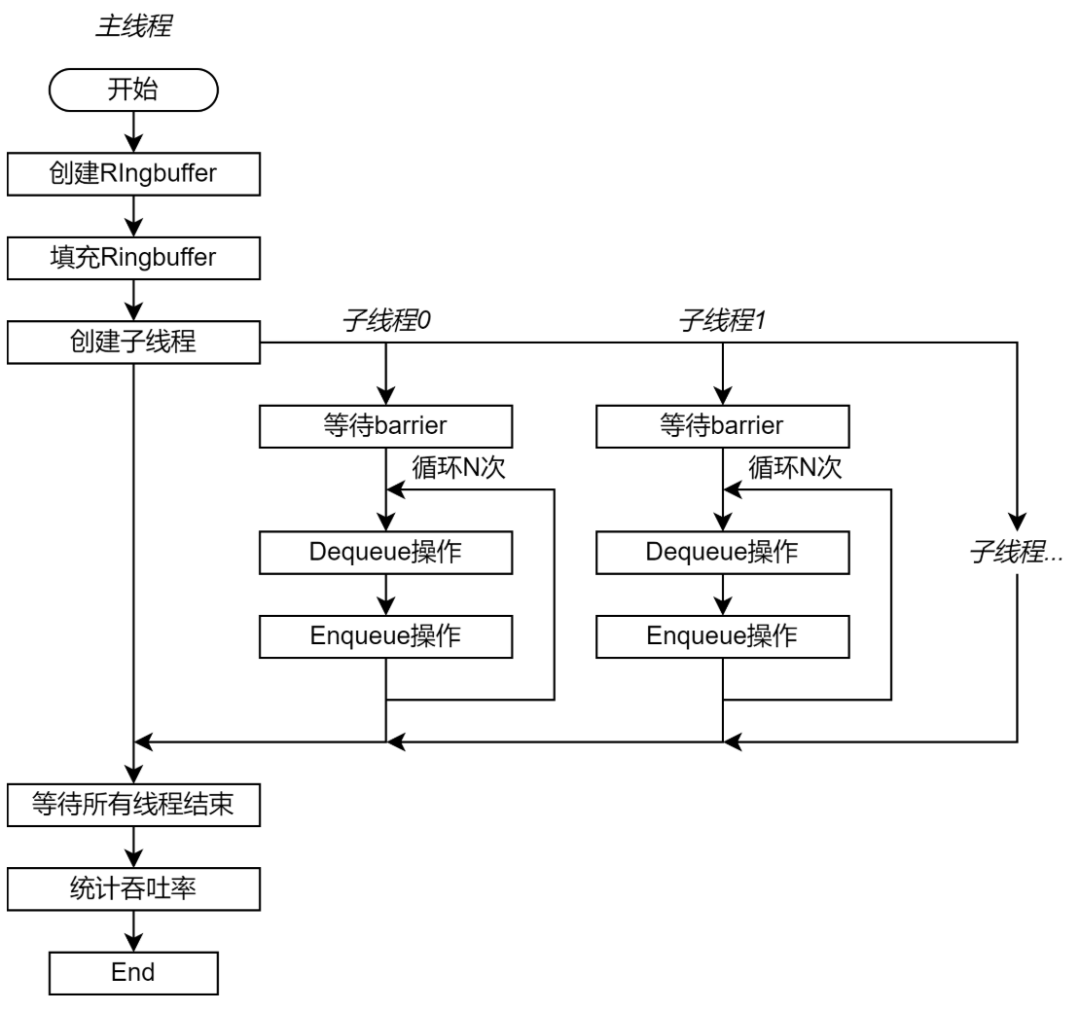
圖 4 測試程序流程圖 每個子線程獨(dú)立統(tǒng)計(jì)測試階段完成的時間,并且分別計(jì)算操作的吞吐率。這是為了避免統(tǒng)計(jì)過程引入新的共享數(shù)據(jù)。最后,主線程獲取每個子線程統(tǒng)計(jì)的操作吞吐率,并且求和得到總吞吐率。吞吐率用每秒執(zhí)行的 Enqueue 或 Dequeue 操作數(shù)量表示,即 op/s。 由于 Ringbuffer 的性能與存儲系統(tǒng)的性能有直接關(guān)聯(lián),因此子線程調(diào)度到的核心對于具體實(shí)現(xiàn)具有很大的關(guān)系。為了保證測試的穩(wěn)定性,需要將子線程調(diào)度到指定的核心(綁核)。如果不做綁核,那么相同實(shí)現(xiàn)的相同配置的不同測試結(jié)果可能會大相徑庭,測試結(jié)果偏差極大。 測試框架的源碼請參見https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/testbench/testbench.cc)。
基于 Mutex 的 Ringbuffer 實(shí)現(xiàn)的測試結(jié)果
測試采用的 Arm 服務(wù)器具有 32 個 N1 處理器,使用 CMN600 作為互聯(lián)結(jié)果。測試用的 Arm 服務(wù)器上并沒有區(qū)分 NUMA 結(jié)點(diǎn),因此采用自然映射的關(guān)系,即子線程 0 調(diào)度到 CPU0;子線程 1 調(diào)度到 CPU1,以此類推。 圖 5 展示了基于 Mutex 的 Ringbuffer 的性能測試結(jié)果。顯然,隨著子線程數(shù)量的增加,Ringbuffer 的吞吐率顯著降低。當(dāng)使用 2 個子線程時,吞吐率為 3985230 op/s;當(dāng)使用全部 32 個子線程時,吞吐率為 323111 op/s。前者是后者的 12.3 倍。
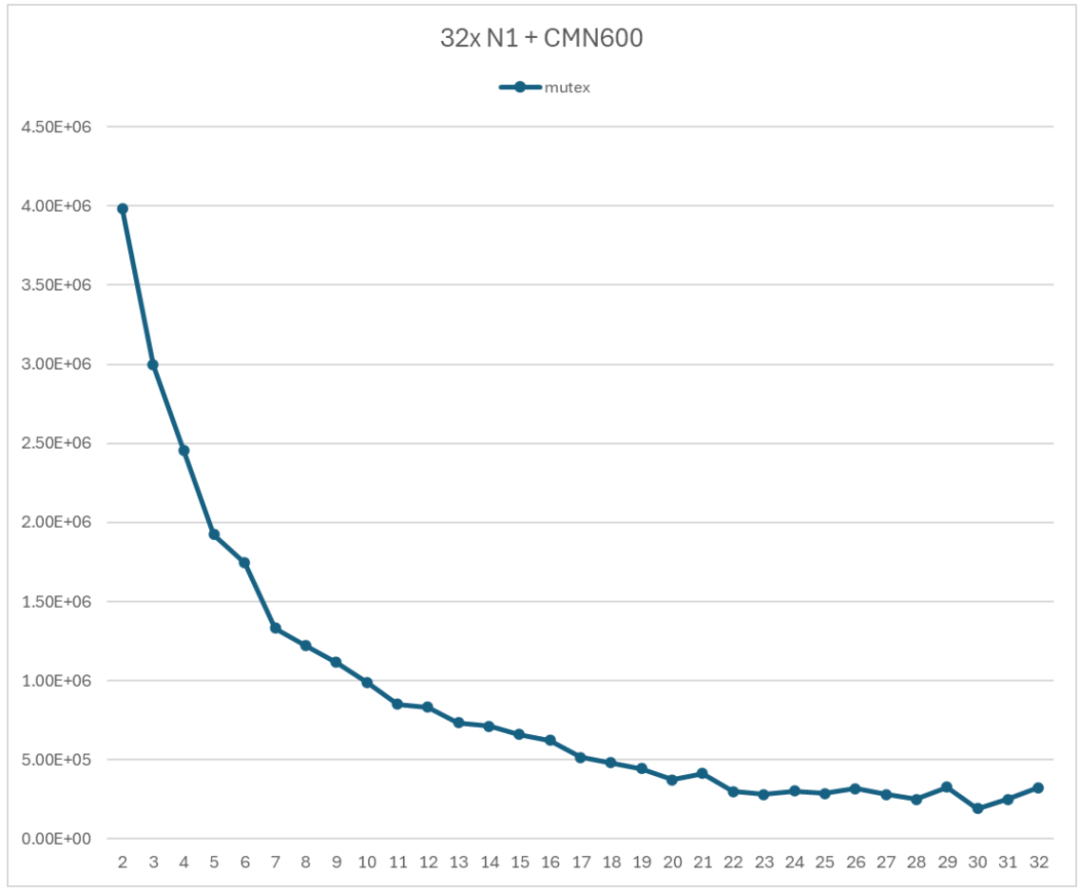
圖 5 基于 Mutex 的 Ringbuffer 性能測試
圖 5 展示的性能測試結(jié)果是典型的以多線程競爭為主導(dǎo)的性能曲線。隨著參與競爭的子線程數(shù)增加,在競爭 mutex 上花費(fèi)的時間就更多,導(dǎo)致性能快速下降。 使用 perf 工具對于啟動 16 個線程的測試程序進(jìn)行熱點(diǎn)分析,熱點(diǎn)分析結(jié)果如圖 6 所示。圖中橙色部分提示了lock函數(shù)占用了程序執(zhí)行時間的 91%。因此,對于 Ringbuffer 進(jìn)行優(yōu)化的首要步驟就是采用無鎖的實(shí)現(xiàn)方式。 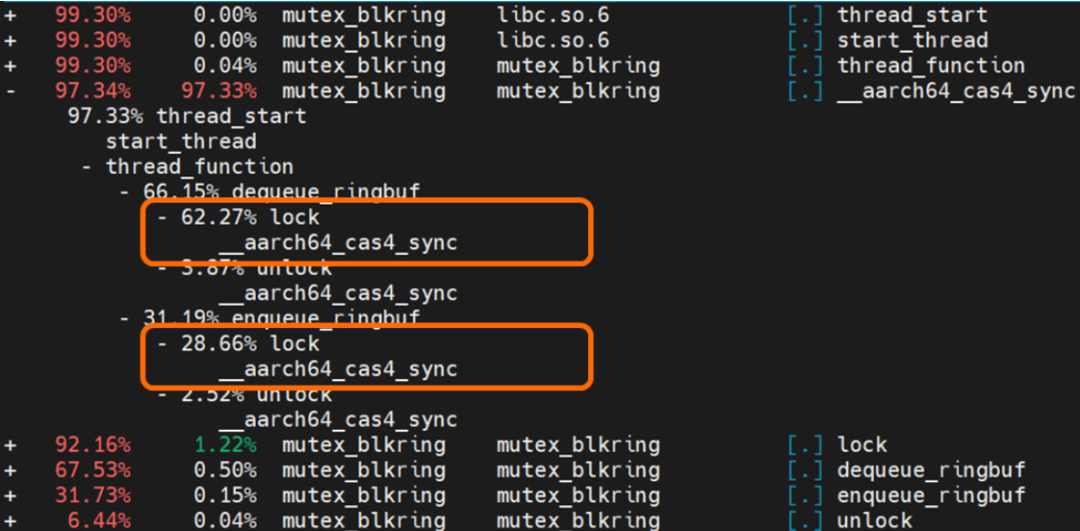 圖 6 Perf 熱點(diǎn)分析結(jié)果
圖 6 Perf 熱點(diǎn)分析結(jié)果
無鎖 Ringbuffer 實(shí)現(xiàn)
對于多線程共享程序,需要使用 mutex 來保護(hù)對于共享變量的 load-modify-store 代碼序列,從而保證功能正確性。但是 mutex 的競爭引入了非常明顯的性能開銷。因此,需要探索無鎖的 Ringbuffer 實(shí)現(xiàn)。
用原子操作替代鎖
除了 mutex,另一種可以保護(hù)共享變量的方法是原子操作。單個原子操作就是由 load-modify-store 三個部分構(gòu)成。原子操作保證,在完成 load-modify-store 序列之前,被訪問的地址不會被其他指令訪問。典型的原子操作包括 Compare-and-swap (CAS),以及 Arm 提供的 LDADD 等原子操作。如果有多個 PE 針對同一個共享變量發(fā)起多個原子操作,那么這些操作只能按照某種順序串行,而不能并行。執(zhí)行順序取決于硬件實(shí)現(xiàn)。 CAS 保證了對于 mutex 的操作都是串行的。例如 PE1 執(zhí)行原子操作 CAS(x, 0, 1),同時 PE2 執(zhí)行原子操作 CAS(x, 0, 2):
如果 PE1 先讀取到 x 的值,那么 PE1 的 CAS 操作成功;PE2 讀取到的 x 的值是 PE1 更新后的值=1,CAS 操作失敗。最后 PE1 中返回值是 0;PE2 中返回值是 1;x 的值是 1。
如果 PE2 先讀取到 x 的值,那么 PE2 的 CAS 操作成功;PE1 讀取到的 x 的值是 PE2 更新后的值=2,CAS 操作失敗。最后 PE1 的返回值是 2;PE2 的返回值是 0;x 的值是 2。
在 Ringbuffer 實(shí)現(xiàn)中,特別需要保護(hù)的就是被所有生產(chǎn)者和消費(fèi)者共享的 head 和 tail 指針。可以用__atomic_fetch_add原語來實(shí)現(xiàn)指針的原子指令并且實(shí)現(xiàn)指針的累加。 __atomic_fetch_add原語的聲明如下,其核心指令是 LDADD。原語讀取ptr指向的變量,然后將變量累加val后的新值會寫到原來的位置;同時,原語將ptr指令的變量的舊值返回。
type __atomic_fetch_add (type *ptr, type val, int memorder)將__atomic_fetch_add原語應(yīng)用到 head 或 tail 指針上,則可以將存儲在內(nèi)存中的指針變量加 1,并且同時將加 1 前的舊值返回。這就相當(dāng)于將目前 head/tail 指針指向的單元分配給了當(dāng)前的 Enqueue 或 Dequeue 的生產(chǎn)者或消費(fèi)者,同時與其他生產(chǎn)者或消費(fèi)者同步了更新后的指針。
Enqueue 和 Dequeue
圖 7 展示了 Enqueue 和 Dequeue 的流程圖。
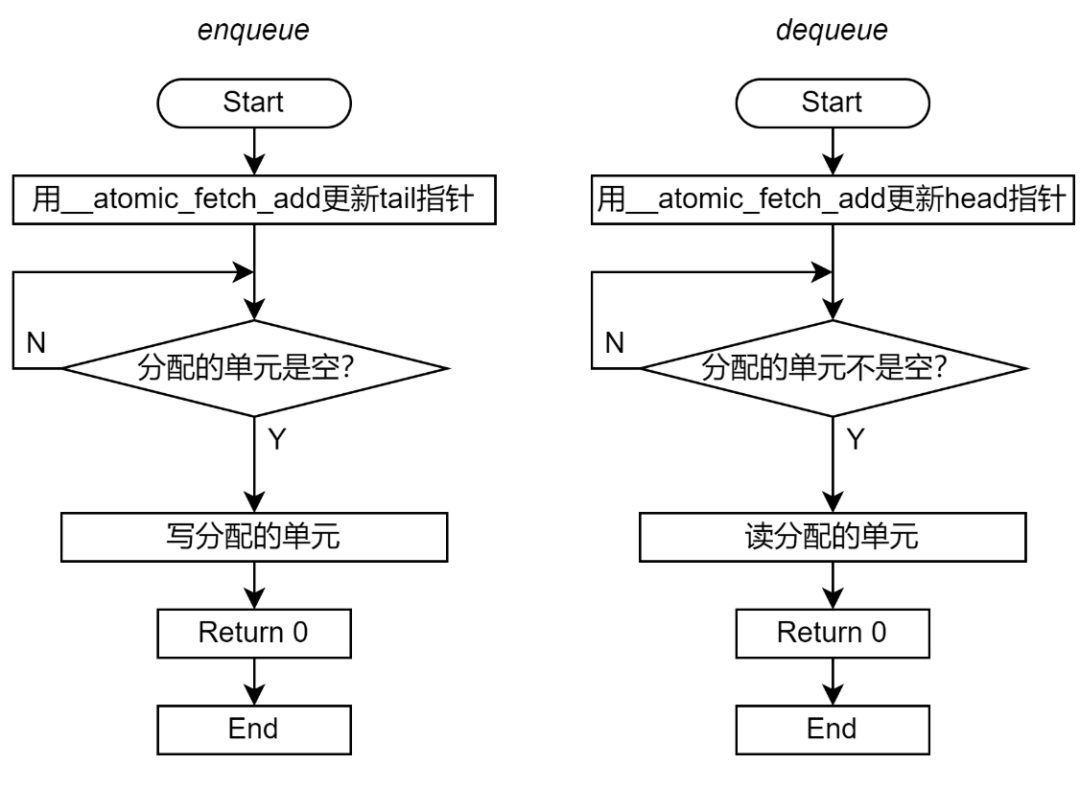
圖 7 無鎖 Ringbuffer 實(shí)現(xiàn)流程圖(使用原子操作替換 mutex) 相對于基于 mutex 的 Ringbuffer 實(shí)現(xiàn),無鎖 Ringbuffer 實(shí)現(xiàn)從軟件和硬件兩方面的優(yōu)化。 從軟件的角度,無鎖 Ringbuffer 的關(guān)鍵區(qū)要小很多。在基于 mutex 的 Ringbuffer 實(shí)現(xiàn)(圖 8 左側(cè))中,鎖保護(hù)了整個 Enqueue 和 Dequeue 過程,每個 Enqueue 和 Dequeue 過程都只能串行執(zhí)行。在無鎖 Ringbuffer 實(shí)現(xiàn)(圖 8 右側(cè))中,原子指令只保護(hù)了對于 head 或 tail 指針的累加。除了__atomic_fetch_add必須串行,其他部分都是可以并行的,從而增加了程序的并行度。
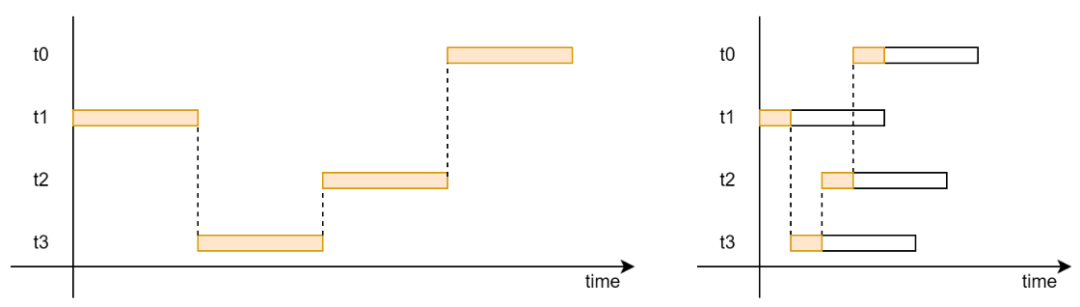
圖 8 基于 mutex 的 Ringbuffer 實(shí)現(xiàn)和無鎖 Ringbuffer 實(shí)現(xiàn)的關(guān)鍵區(qū)(著色部分)對比 從硬件的角度,原子指令引入更少的 snoop 操作。使用常規(guī)的 load 指令讀取數(shù)據(jù)后,在 PE 側(cè)的緩存中的數(shù)據(jù)副本的狀態(tài)為 Share(共享)。所有訪問這個數(shù)據(jù)的 PE 的緩存都會具有這個共享數(shù)據(jù)的副本。當(dāng)共享數(shù)據(jù)被某個 PE 修改后,需要大量的 snoop 去失效其他 PE 中的所有副本。 使用原子指令讀取數(shù)據(jù)之后,數(shù)據(jù)的緩存狀態(tài)為 Exclusive(獨(dú)有),即只有一個 PE 具有這個共享數(shù)據(jù)的副本。當(dāng)另一個 PE 也執(zhí)行原子操作后,只需要一個 snoop 就可以將已經(jīng)存在副本清除。 從帶寬的角度,更少 snoop 數(shù)量意味著 snoop 通信占用的通信帶寬更少,提供給數(shù)據(jù)通信的帶寬就會更高。從延遲的角度,load/store 操作需要等到其引起的所有 snoop 都完成才能被標(biāo)識為完成。更少的 snoop 數(shù)量意味著等待 snoop 完成的時間更短。 無鎖 Ringbuffer 同時從這兩方面優(yōu)化中受惠,暫時沒有辦法定量分析出哪一個優(yōu)化的作用更大。一般來說,縮小關(guān)鍵區(qū)的作用更大。
邏輯單元序號
上述的無鎖 Ringbuffer 仍然可能導(dǎo)致功能錯誤。例如一個 Ringbuffer 有 16 個物理單元。首先為生產(chǎn)者 A 分配的邏輯單元是 16;隨后,為生產(chǎn)者 B 分配的單元是 32;這兩個單元映射到相同的物理單元 0。雖然單元分配和指針更新是串行的,但是對于數(shù)據(jù)單元的訪問是并行的,因此并不能保證生產(chǎn)者 B 訪問物理單元 0 時,生產(chǎn)者 A 一定完成了操作。可能生產(chǎn)者 A 和生產(chǎn)者 B 同時查詢到單元是空閑,進(jìn)而同時對這個物理單元進(jìn)行寫入。此時無法保證寫入單元的究竟是生產(chǎn)者 A 的數(shù)據(jù)還是生產(chǎn)者 B 的數(shù)據(jù)。 為了解決這樣的問題,Ola 提出,給每個單元增加一個域來表示其對應(yīng)的邏輯單元序號。只有當(dāng)邏輯單元序號與 head/tail 指針一致的時候才能進(jìn)行訪問。當(dāng) Dequeue 單元的時候,需要更新邏輯單元序號,將單元的序列號增加物理單元的總數(shù)。 還是上面的例子,當(dāng)生產(chǎn)者 A 和 B 同時查詢到內(nèi)存是空閑時,由于單元的序列號與生產(chǎn)者 A 分配的單元匹配,那么生產(chǎn)者 A 可以操作這個單元;生產(chǎn)者 B 則因?yàn)樾蛄刑柌黄ヅ涠荒茉L問,需要繼續(xù)等待。 增加邏輯單元序號后的 Enqueue 和 Dequeue 流程圖如圖 9。
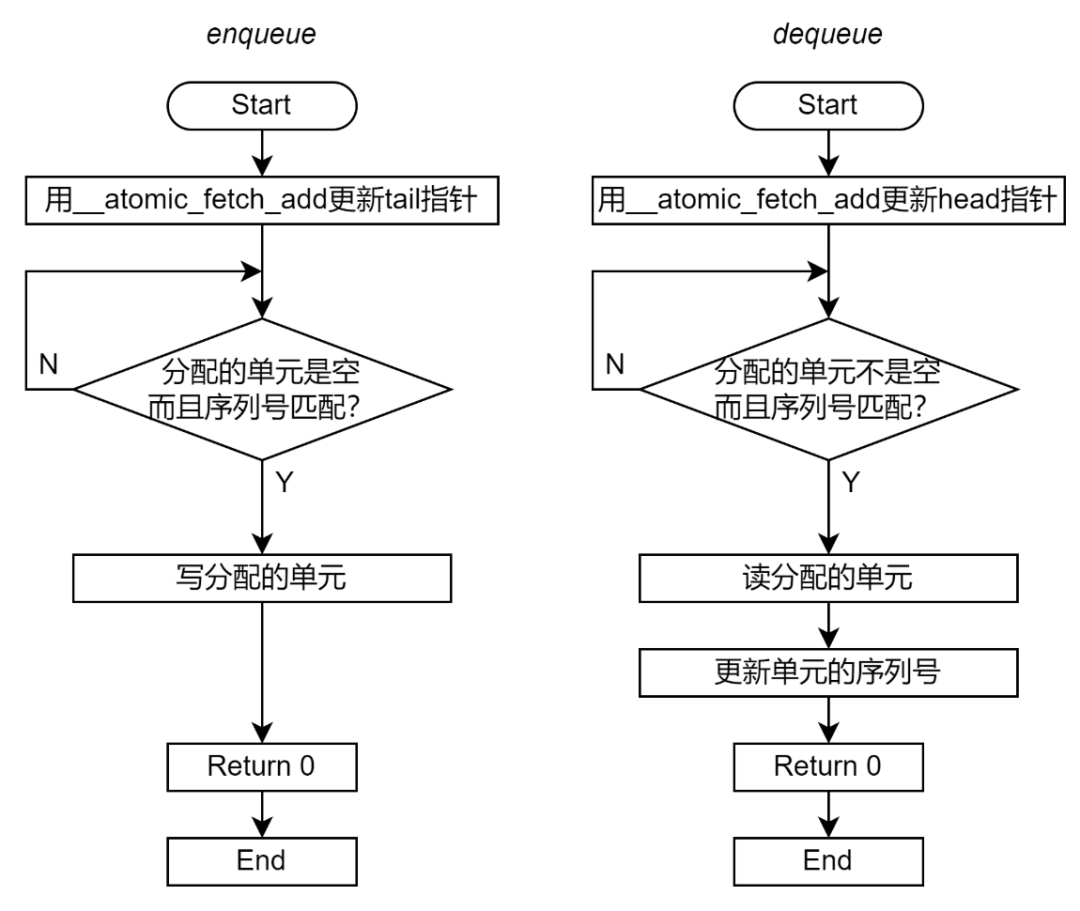
圖 9 無鎖 Ringbuffer 實(shí)現(xiàn)流程圖(使用原子操作替換 mutex)
無鎖 Ringbuffer 聲明
無鎖 Ringbuffer 的聲明如下。Ringbuffer 不需要 mutex 進(jìn)行保護(hù)。
// Entry in ring buffer
class BufferEntry
{
public:
unsigned int m_sn; // Sequential number.
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
unsigned int m_size; // The number of physical entries.
unsigned int m_head; // Head pointer.
unsigned int m_tail; // Tail pointer.
BufferEntry *mp_entries; // Pointer to physical entries.
}
代碼 3 無鎖 Ringbuffer 聲明
無鎖 Ringbuffer 的 Enqueue 和 Dequeue 函數(shù)
Enqueue 和 Dequeue 函數(shù)的實(shí)現(xiàn)如下。
// Blocking Enqueue Function
int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry)
{
// Update the tail pointer.
int sn = __atomic_fetch_add(&ring_buffer->m_tail, 1, __ATOMIC_RELAXED);
int enq_ptr = sn % ring_buffer->m_size;
// Check the data entry until empty.
unsigned int entry_sn;
void *entry_ptr;
do
{
// Replace load by atomic load.
// entry_sn = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].m_sn, __ATOMIC_RELAXED);
// entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, __ATOMIC_RELAXED);
entry_sn = ring_buffer->mp_entries[enq_ptr].m_sn;
entry_ptr = ring_buffer->mp_entries[enq_ptr].mp_ptr;
} while (entry_sn != sn || entry_ptr != NULL);
// Write entry.
// Replace store by atomic store.
// __atomic_store_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, entry, __ATOMIC_RELEASE);
ring_buffer->mp_entries[enq_ptr].mp_ptr = entry;
return 0;
}
// Blocking Dequeue Function
int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry)
{
// Update the head pointer.
int sn = __atomic_fetch_add(&ring_buffer->m_head, 1, __ATOMIC_RELAXED);
int deq_ptr = sn % ring_buffer->m_size;
// Check the data entry until not empty.
unsigned int entry_sn;
void *entry_ptr;
do
{
// Replace load by atomic load.
// entry_sn = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].m_sn, __ATOMIC_RELAXED);
// entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, __ATOMIC_ACQUIRE);
entry_sn = ring_buffer->mp_entries[deq_ptr].m_sn;
entry_ptr = ring_buffer->mp_entries[deq_ptr].mp_ptr;
} while (entry_ptr == NULL || entry_sn != sn);
// Read entry.
*entry = entry_ptr;
// Replace store by atomic store
// __atomic_store_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, 0, __ATOMIC_RELAXED);
ring_buffer->mp_entries[deq_ptr].mp_ptr = 0;
// Update sequence number.
// Replace store by atomic store
// __atomic_store_n(&ring_buffer->mp_entries[deq_ptr].m_sn, sn + ring_buffer->m_size, __ATOMIC_RELEASE);
ring_buffer->mp_entries[deq_ptr].m_sn = sn + ring_buffer->m_size;
return 0;
}
代碼 4 無鎖 Ringbuffer 的 Enqueue 和 Dequeue 函數(shù)
Enqueue 和 Dequeue 函數(shù)中對于數(shù)據(jù)單元的 load/store 操作可以進(jìn)一步被原子操作__atomic_load_n和__atomic_store_n取代。代碼 4 中的注釋給出了可以替換的原子操作。
無鎖 ringbuffer 實(shí)現(xiàn)的完整源碼請參見(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/lockfree_blkring.h)。
使用原子操作數(shù)據(jù)單元的無鎖 Ringbuffer 實(shí)現(xiàn)的完整源碼請參見(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/atomic_blkring.h)。
無鎖 Ringbuffer 性能測試結(jié)果
無鎖 Ringbuffer 的性能如圖 10 所示。曲線 mutex 表示基于 mutex 的 Ringbuffer 實(shí)現(xiàn);lockfree 和 atomic 表示無鎖 Ringbuffer 實(shí)現(xiàn)(lockfree 使用普通 load/store 操作數(shù)據(jù)單元;atomic 使用原子 load/store 操作數(shù)據(jù)單元)。
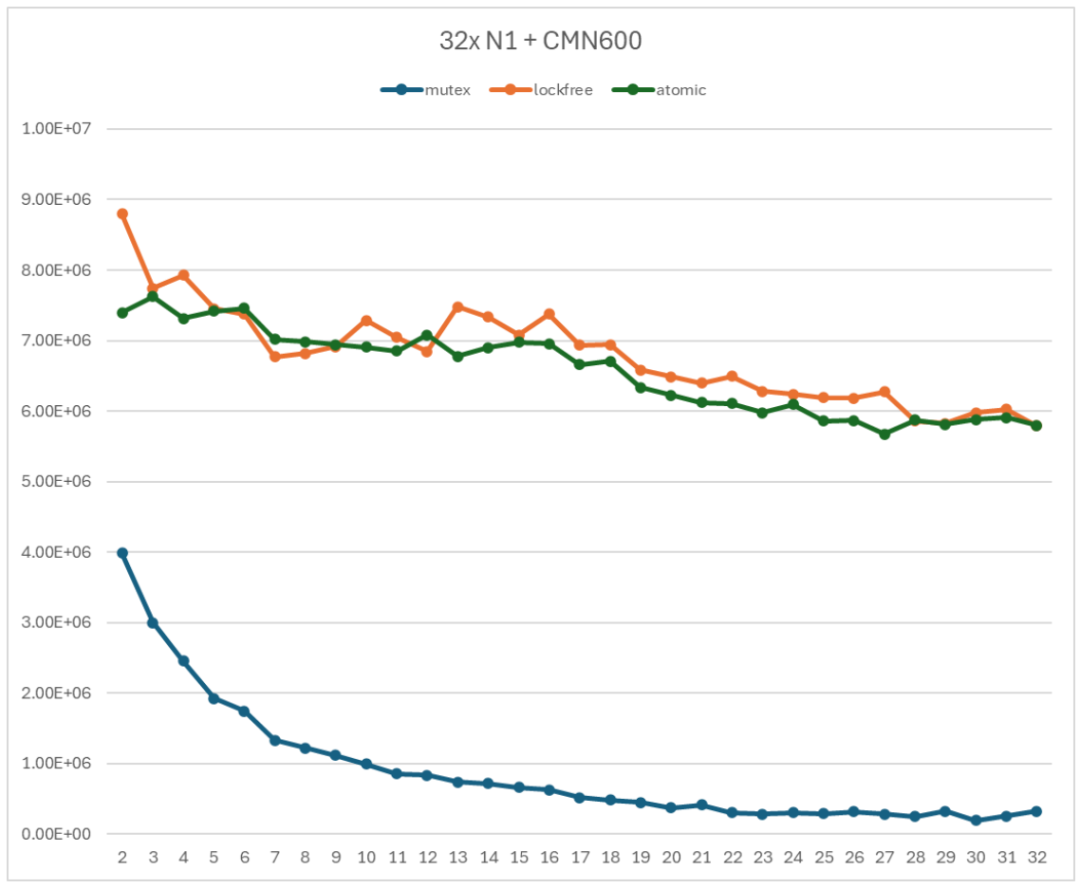
圖 10 無鎖 Ringbuffer 性能測試
從圖 10 中可以發(fā)現(xiàn),相對于基于 mutex 的 Ringbuffer 實(shí)現(xiàn),無鎖 Ringbuffer 實(shí)現(xiàn)的性能得到了很大的提升。用 atomic 曲線和 mutex 曲線進(jìn)行比較。當(dāng)只有 2 個線程時,無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率是基于 mutex 的 Ringbuffer 實(shí)現(xiàn)的吞吐率的 1.86 倍;當(dāng)使用 32 個線程時,無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率是基于 mutex 的 Ringbuffer 實(shí)現(xiàn)的吞吐率的 18 倍。
從圖 10 中可以發(fā)現(xiàn),對于數(shù)據(jù)單元的訪問是否使用原子操作對于性能的影響并不明顯。兩條曲線基本上是重合的。這是因?yàn)闇y試的 ringbuffer 提供了足夠的單元,多個線程共享 Ringbuffer 單元的競爭并不強(qiáng)烈。
無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率還是會隨著子線程數(shù)增加而降低,但是并不如基于 mutex 的 Ringbuffer 強(qiáng)烈。當(dāng)使用 2 個子線程時,吞吐率為 7394830 op/s;當(dāng)使用全部 32 個子線程時,吞吐率為 5800350 op/s。前者是后者的 1.27 倍。
利用 Perf 分析程序熱點(diǎn)只能定位到特點(diǎn)在 enqueue 和 dequeue 函數(shù),無法提供進(jìn)一步的信息。因此使用 Arm 的 top-down 工具對于微架構(gòu)執(zhí)行情況進(jìn)行詳細(xì)分析,得到的結(jié)果如圖 11。
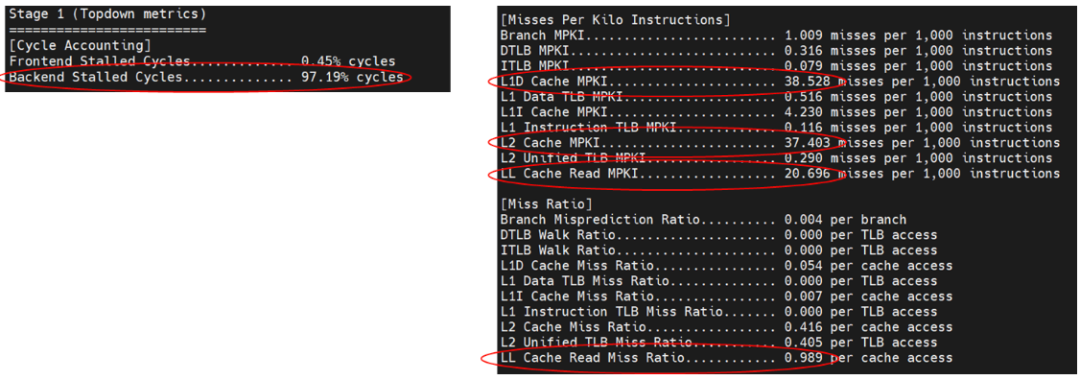
圖 11 利用 Top-down 對無鎖 Ringbuffer 進(jìn)行性能分析
圖 11 中用紅圈標(biāo)注了主要注意的指標(biāo)。首先,程序明確屬于后端瓶頸的程序,后端阻塞周期高達(dá) 97%。其次,L1、L2 和 LC(Last-level cache)明顯高于其他異常情況,這表示程序中存在大量的數(shù)據(jù)競爭。最后 L1、L2 和 LC 的數(shù)據(jù)缺失率屬于同一量級,這表示數(shù)據(jù)競爭是全局性的,需要通過系統(tǒng)的最后一級緩存才能得到解決。top-down 的分析結(jié)果提示,無鎖的 ringbuffer 實(shí)現(xiàn)仍然導(dǎo)致了大量的全局性的數(shù)據(jù)沖突。
無鎖 Ringbuffer 的對齊改進(jìn)
通過對于程序的分析,符合上述特征的共享數(shù)據(jù)只有 head 和 tail 指針。因?yàn)?head 和 tail 指針處于相同的緩存行。這就導(dǎo)致生產(chǎn)者和消費(fèi)者仍然在競爭同一個緩存行。可以通過對與 Ringbuffer 的數(shù)據(jù)結(jié)構(gòu)進(jìn)行緩存行對齊,減少不同生產(chǎn)者和消費(fèi)者競爭同一個緩存行的情況。
Ringbuffer 實(shí)現(xiàn)的緩存行對齊包含兩個部分:
head/tail 指針的對齊。將 head 指針和 tail 指針分別放置到不同的緩存行。這可以通過 C 語言原語 alignas 實(shí)現(xiàn)。
class RingBuffer
{
public:
alignas(64) unsigned int m_size;
alignas(64) unsigned int m_head;
alignas(64) unsigned int m_tail;
alignas(64) BufferEntry *mp_entries;
}
代碼 5 對齊的無鎖 Ringbuffer 的聲明
這樣只有生產(chǎn)者競爭 tail 指針?biāo)诘木彺嫘校幌M(fèi)者競爭 head 指針?biāo)诘木彺嫘小?br />數(shù)據(jù)單元的對齊。這是為了避免訪問不同單元的線程因?yàn)閱卧幱谙嗤彺嫘卸a(chǎn)生競爭。比如訪問物理單元 0-3 的線程實(shí)際上在競爭同一個緩存行。
這一部分可以通過空間換效率的方式實(shí)現(xiàn)。一個緩存行(64B)中可以放置 4 個單元(每個單元 16B,8B 指針和 8B 序列號)。在初始化時分配 4 倍的單元,在 Enqueue 和 Dequeue 每次都只使用 4 對齊的序號。邏輯單元 0 對應(yīng)到物理單元 0;邏輯單元 1 對應(yīng)到物理單元 4;依次類推。
物理單元序號計(jì)算方法如下:
int enq_ptr = (sn % ring_buffer->m_size) * 4;
代碼 6 對齊的無鎖 Ringbuffer 映射邏輯單元到物理單元
對齊后的無鎖 ringbuffer 的內(nèi)存分布如下。其中紅色部分是實(shí)際訪問的數(shù)據(jù)單元。綠色部分是沒有使用到的數(shù)據(jù)單元。
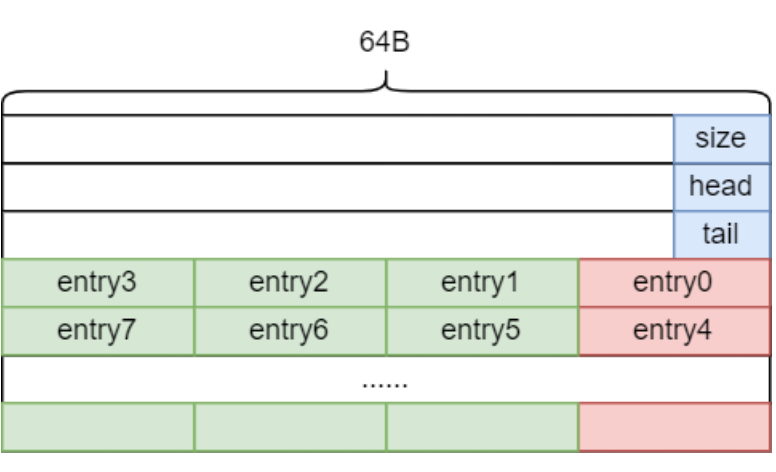
圖 12 對齊后的無鎖 Ringbuffer 的內(nèi)存分布
需要說明的是,當(dāng)物理數(shù)據(jù)單元數(shù)量遠(yuǎn)大于生產(chǎn)者和消費(fèi)者數(shù)量時,數(shù)據(jù)單元的對齊對于性能的影響非常微小。因?yàn)楣蚕硪粋€緩存行的線程數(shù)量很小,最多只有 4 個。
緩存行對齊的無鎖 ringbuffer 實(shí)現(xiàn)的完整源碼請參見(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/align_blkring.h)。
對齊的無鎖 Ringbuffer 性能測試結(jié)果
緩存行對齊的無鎖 Ringbuffer 的性能如圖 13 所示。曲線 mutex 表示基于 mutex 的 Ringbuffer 實(shí)現(xiàn);lockfree 和 atomic 表示無鎖 Ringbuffer 實(shí)現(xiàn)(lockfree 使用普通 load/store 操作數(shù)據(jù)單元;atomic 使用原子 load/store 操作數(shù)據(jù)單元);align 表示緩存行對齊后的無鎖 Ringbuffer 實(shí)現(xiàn)。
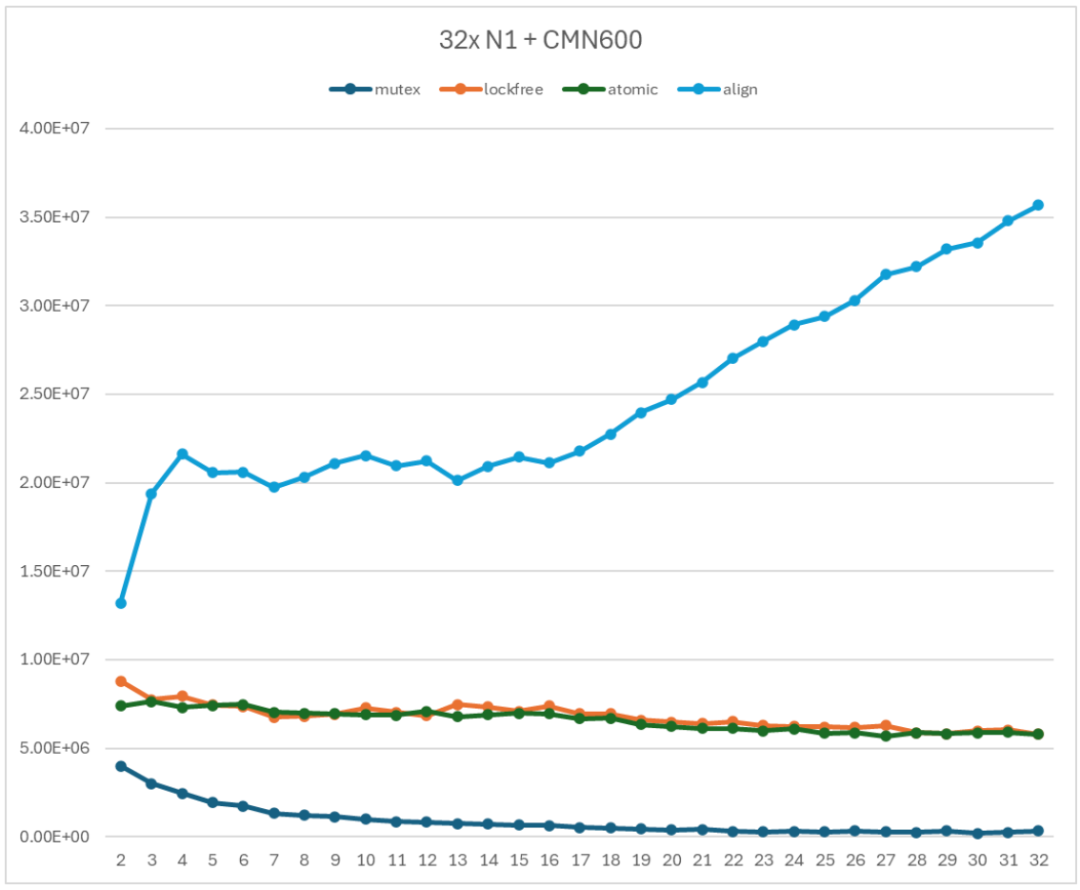
圖 13 對齊的無鎖 Ringbuffer 性能測試
緩存行對齊的無鎖 Ringbuffer 實(shí)現(xiàn)的性能曲線隨著子線程數(shù)量的增加呈現(xiàn)增長的趨勢。具體來說,
首先,當(dāng)子線程數(shù)小于 16 時,吞吐率隨著子線程數(shù)增加而趨向于一個穩(wěn)定的值。這個穩(wěn)定值受限于是互聯(lián)網(wǎng)絡(luò)能夠提供的最大帶寬。
其次,當(dāng)子線程數(shù)大于 16 時,吞吐率隨著子線程數(shù)增加而增加。這與互聯(lián)結(jié)構(gòu)的拓?fù)溆嘘P(guān)系。當(dāng)子線程數(shù)大于 32 時,新的子線程被分配到互聯(lián)結(jié)構(gòu)的另一半部分,從而使得能夠利用的帶寬增加。
用 align 曲線和 mutex 曲線進(jìn)行比較。當(dāng)只有 2 個線程時,無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率是基于 mutex 的 Ringbuffer 實(shí)現(xiàn)的吞吐率的 3.31 倍;當(dāng)使用 16 個線程時,無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率是基于 mutex 的 Ringbuffer 實(shí)現(xiàn)的吞吐率的 33.8 倍。當(dāng)使用 32 個線程時,無鎖 Ringbuffer 實(shí)現(xiàn)的吞吐率是基于 mutex 的 Ringbuffer 實(shí)現(xiàn)的吞吐率的 110 倍。
緩存行對齊的無鎖 Ringbuffer 實(shí)現(xiàn)的性能曲線與基于 mutex 的 Ringbuffer 實(shí)現(xiàn)和無鎖 Ringbuffer 的實(shí)現(xiàn)有本質(zhì)上的不同,呈現(xiàn)了一種互聯(lián)帶寬測試的規(guī)律。這表示緩存行對齊的無鎖 Ringbuffer 實(shí)現(xiàn)能夠充分利用互聯(lián)網(wǎng)絡(luò)提供的通信性能,是一個非常有利于系統(tǒng)規(guī)模擴(kuò)展的 Ringbuffer 實(shí)現(xiàn)。
非阻塞 Ringbuffer 實(shí)現(xiàn)
前文介紹的無鎖 Ringbuffer 實(shí)現(xiàn)存在一個重大的功能缺陷,就是上述實(shí)現(xiàn)只能構(gòu)建阻塞式的 Ringbuffer。當(dāng)生產(chǎn)者或消費(fèi)者進(jìn)入 Enqueue 或 Dequeue 函數(shù)后,生產(chǎn)者或消費(fèi)者的程序會一直嘗試操作,直到操作成功才能推出 Enqueue 或 Dequeue 函數(shù)。
在實(shí)際軟件更加傾向于實(shí)現(xiàn)非阻塞的 Ringbuffer。因?yàn)楫?dāng) Enqueue 或 Dequeue 操作不成功時,軟件可以主動進(jìn)行線程調(diào)度或休眠,將處理器資源讓渡給可以進(jìn)行操作的線程或任務(wù)。這有利于提高資源利用率。
指針保護(hù)
這里分三個步驟來推演非阻塞 Ringbuffer 的實(shí)現(xiàn)。
第一步。為了能夠?qū)崿F(xiàn)非阻塞的 Ringbuffer,那么仍然需要在 Enqueue 和 Dequeue 函數(shù)的開始的時候檢查隊(duì)列的空滿情況。如果 Ringbuffer 不滿足進(jìn)行 Enqueue 或 Dequeue 的條件,則退出函數(shù)并且返回錯誤代碼。
考慮到這一點(diǎn),非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程應(yīng)當(dāng)如下圖:
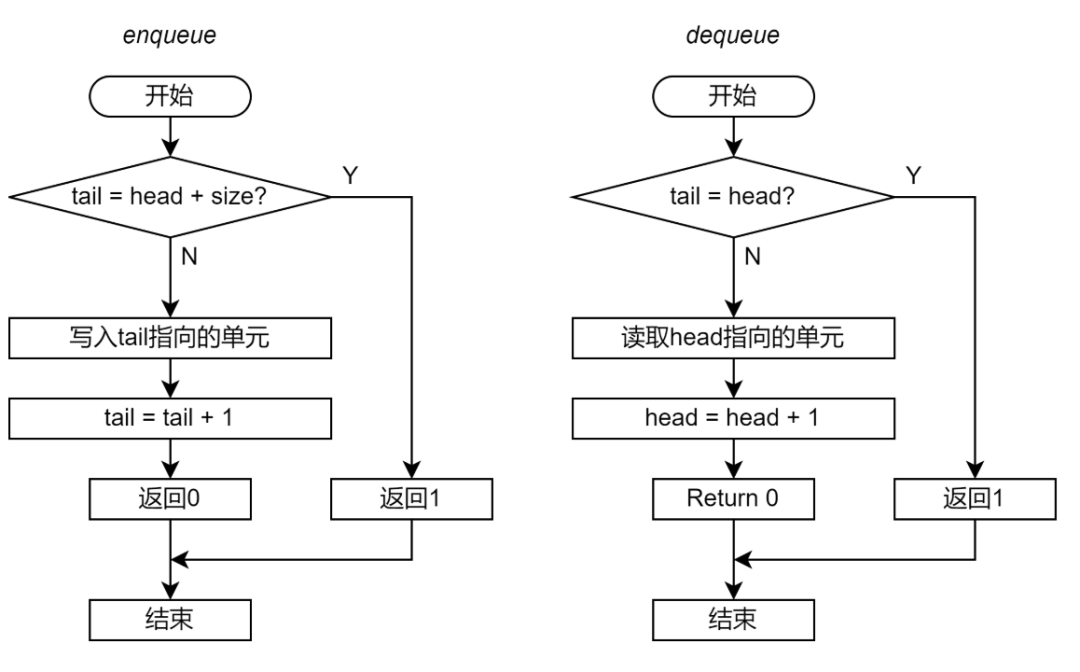
圖 14 非阻塞無鎖 Ringbuffer 實(shí)現(xiàn)的流程圖(第一步)
第二步。非阻塞實(shí)現(xiàn)要使用原子指令替代 mutex 保護(hù)指針。但是原子指令可以保護(hù)對于一個共享變量的 load-modify-store 序列,但是不能保證對于多個共享變量的 load-modify-store 之間的原子性。因此,Enqueue 中只能用原子指令保護(hù) tail 指針;Dequeue 中只能用原子指令保護(hù) head 指針。
考慮到這一點(diǎn),非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程應(yīng)當(dāng)如下圖:
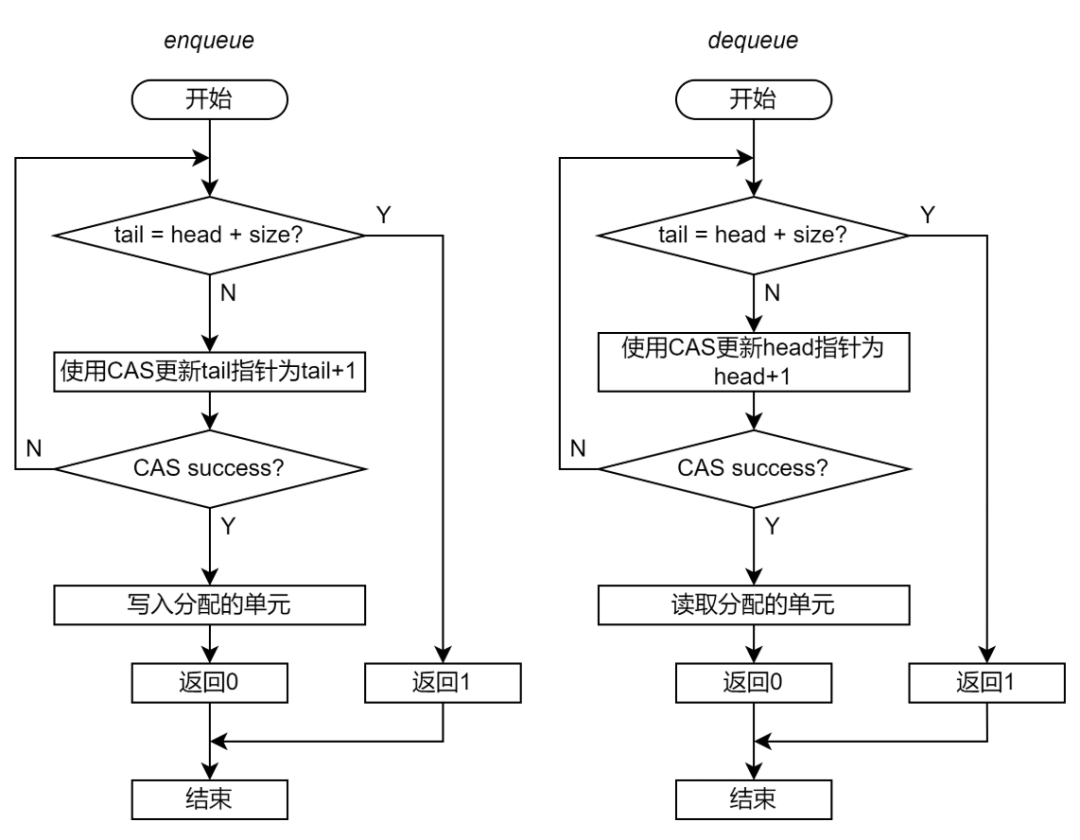
圖 15 非阻塞無鎖 Ringbuffer 實(shí)現(xiàn)的流程圖(第二步)
以 enqueue 為例,函數(shù)首先讀取指針判斷空滿條件。如果 Ringbuffer 不滿,則執(zhí)行 CAS(tail_addr, tail, tail+1)。
如果 CAS 成功,則表示從判斷空滿條件到更新 tail 這段時間,沒有其他線程修改了 tail 指針,那么可以將 tail 指向的單元分配給當(dāng)前線程,并且更新 CAS。
如果 CAS 失敗,則表示從判斷空間條件到更新 tail 這段時間,其他線程修改了 tail 指針。此時,需要返回函數(shù)開始的地方重新判斷空滿條件。
這種方法可以保證 tail 指針的更新是原子的,每個生產(chǎn)者都是在最新的 tail 值基礎(chǔ)上進(jìn)行更新。
這里使用的是__atomic_compare_exchange_n原語。
bool __atomic_compare_exchange_n (type *ptr, type *expected, type desired, bool weak, int success_memorder, int failure_memorder)
__atomic_compare_exchange_n讀取ptr指向的變量,與expected指向的變量比較。如果兩者數(shù)值相同,則更新ptr指向的變量為desired,并且返回真。如果數(shù)值不同,則將讀取的數(shù)值賦值給expected指向的變量,同時返回假。
第三步。從生產(chǎn)者的角度,Enqueue 函數(shù)需要在檢查空滿條件后分配一個單元給當(dāng)前線程,并且讓其他生產(chǎn)者知道更新后的 head 或 tail 值。第二步中引入的 CAS 操作保證了這一點(diǎn)。另一方面,消費(fèi)者需要等到分配的單元被填充后才能知道指針的更新。也就是說,生產(chǎn)者和消費(fèi)者看到指針更新的時間不同。
因此,非阻塞無鎖 Ringbuffer 引入了兩組指針分別針對生產(chǎn)者和消費(fèi)者,即 prod_head/prod_tail,和 cons_head/cons_tail,如圖 15 所示。
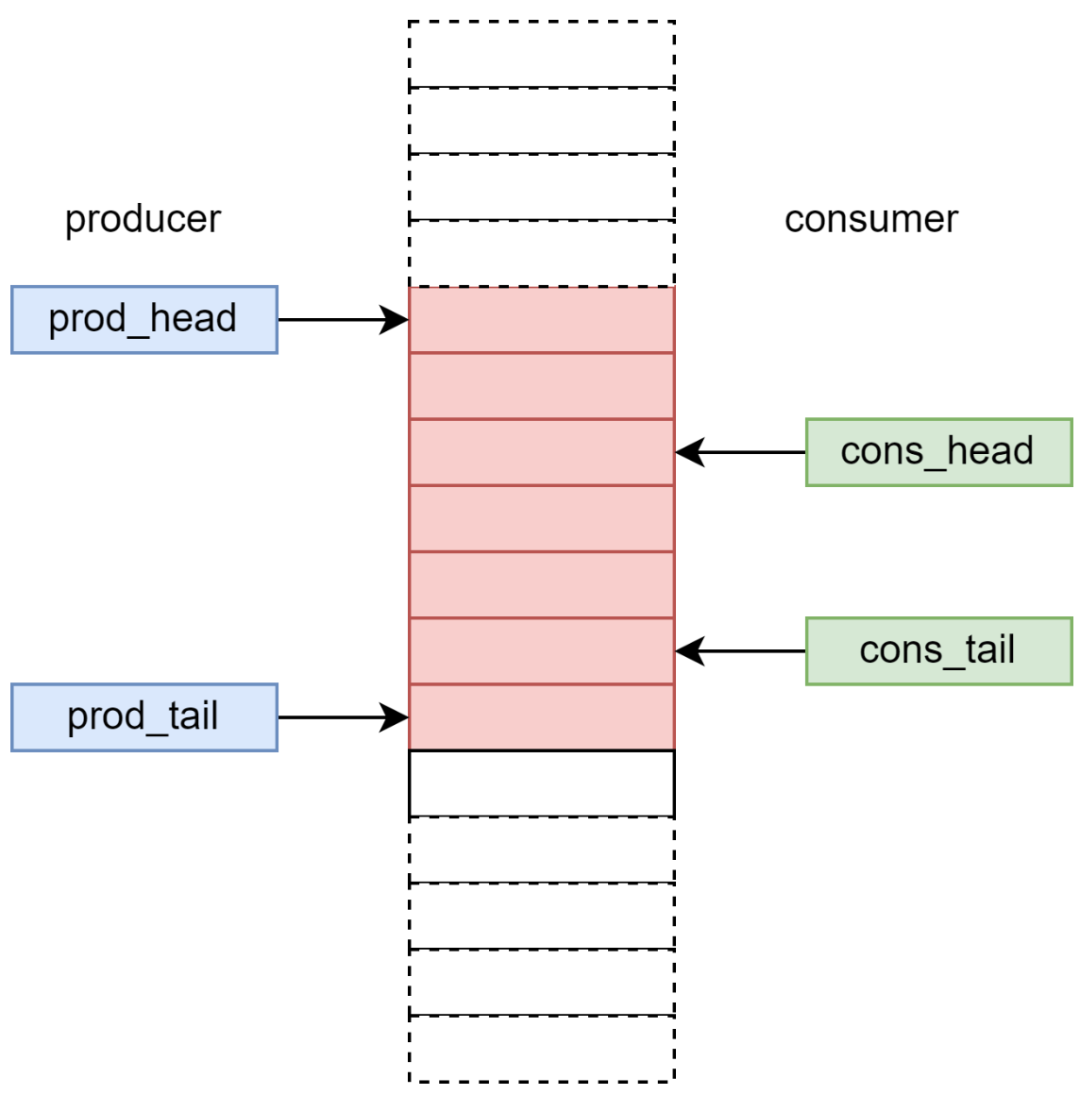
圖 16 生產(chǎn)者和消費(fèi)者指針示意圖
對于生產(chǎn)者來說,其 prod_tail 指針一定是準(zhǔn)確的,但是 prod_head 指針并不是最新的。這會導(dǎo)致生產(chǎn)者認(rèn)為 Ringbuffer 中被占用的單元數(shù)多于實(shí)際被占用的單元數(shù)量,從而導(dǎo)致生產(chǎn)者錯誤地認(rèn)為隊(duì)列是滿的,而放棄 Enqueue 操作。類似地,對于消費(fèi)者來說,其 cons_head 指針一定是準(zhǔn)確的,但是 cons_tail 指針并不是最新的。那么消費(fèi)者可能認(rèn)為空閑單元少于實(shí)際的空閑單元,從而導(dǎo)致消費(fèi)者錯誤地認(rèn)為隊(duì)列是滿的,而放棄 Dequeue 操作。這樣的誤導(dǎo)判斷雖然會導(dǎo)致生產(chǎn)者和消費(fèi)者對于 Ringbuffer 的競爭比較保守,結(jié)果是 Ringbuffer 效率降低,但是不會引起功能錯誤。
考慮到這一點(diǎn),非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的流程應(yīng)當(dāng)如下圖:
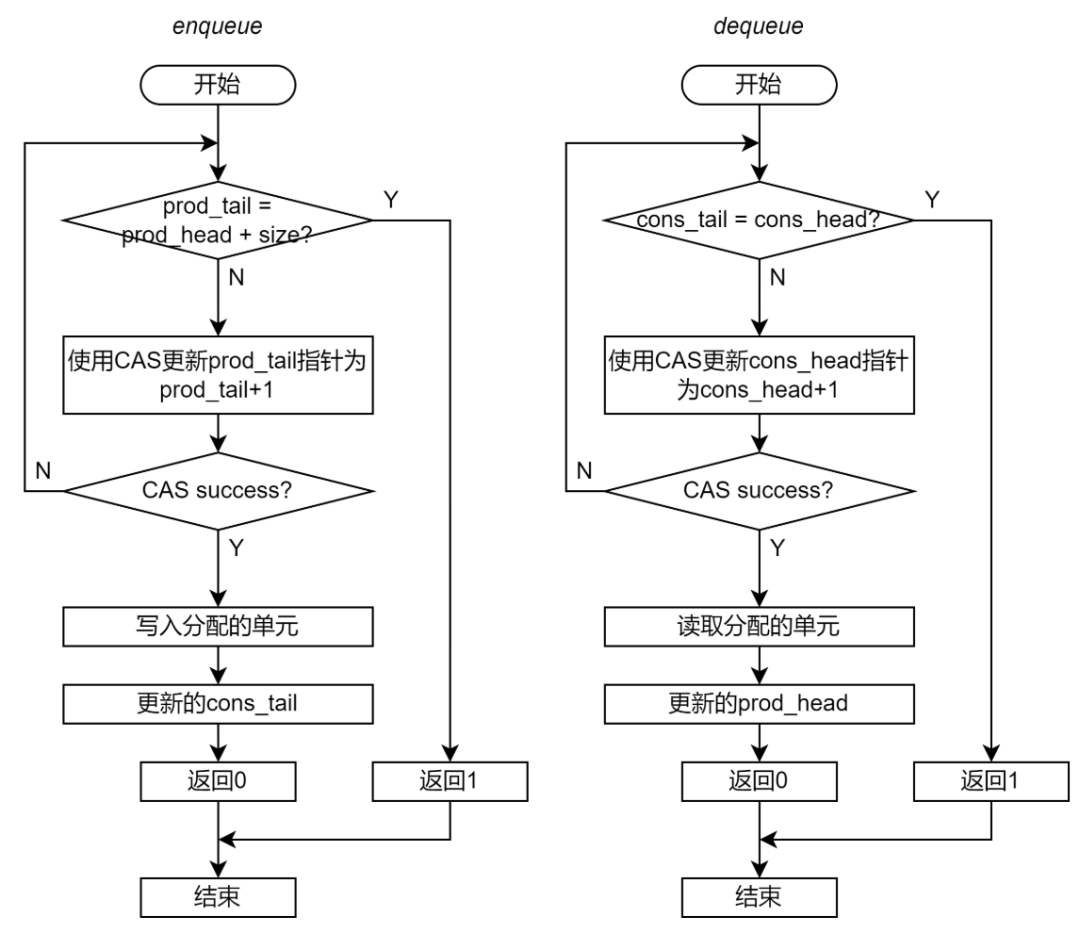
圖 17 非阻塞無鎖 Ringbuffer 實(shí)現(xiàn)的流程圖(第三步)
生產(chǎn)者和消費(fèi)者的指針同步
當(dāng) Enqueue 操作完成時,需要將生產(chǎn)者視角的 prod_tail 指針同步到消費(fèi)者視角的 cons_tail 指針,告知消費(fèi)者這些單元已經(jīng)完成了 Enqueue 操作;當(dāng) Dequeue 操作完成時,需要將消費(fèi)者的 cons_head 指針同步到消費(fèi)者的 prod_head 指針,告知生產(chǎn)者這些單元已經(jīng)完成了 Dequeue 操作。
但是這并不能夠天然保證的。因?yàn)槌酸槍?prod_tail 和 cons_head 指針的 CAS 操作,Enqueue 和 Dequeue 函數(shù)的其他部分都是并行,如圖 18 所示。因此,某個線程的分配單元完成 Enqueue 或 Dequeue 操作時,完全不能推測這個單元之前的其他單元是否完成了 Enqueue 或 Dequeue 的操作。
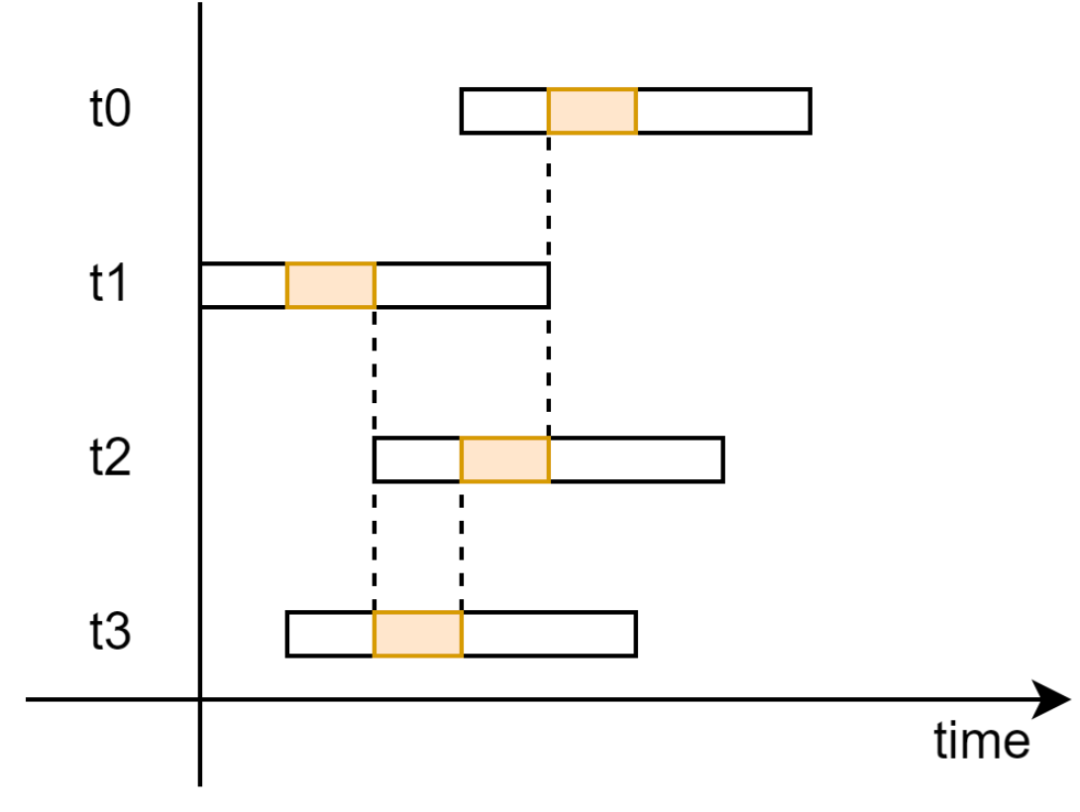
圖 18 非阻塞無鎖 Ringbuffer 的執(zhí)行時序示意圖
指針同步方式有很多種實(shí)現(xiàn)方法,主要分為順序釋放和亂序釋放兩種實(shí)現(xiàn)方法。
順序釋放。要求同步到另一個視角的單元必須完成了 Enqueue 或 Dequeue 操作。這就需要在更新指針前對于單元進(jìn)行檢查,只能將操作完成的單元可以同步給另一個視角。
比如,某個線程的 Enqueue 函數(shù)分配的單元為 16,此時 cons_tail 的值是 10,則 Enqueue 函數(shù)不能更新 cons_tail。只有 cons_tail 的值是 15 時才能更新 cons_tail。這樣才能保證之前的物理單元都已經(jīng)完成了 Enqueue 操作。
為了保證指針操作的原子性,需要使用__atomic_compare_exchange_n原語更新另一個視角的指針。
亂序釋放。在同步不同視角的指針時,不檢查單元是否已經(jīng)完全寫入完成,而是直接將指針加 1。這就會導(dǎo)致在后續(xù) Enqueue 或 Dequeue 種分配的單元不能滿足操作的要求。
比如,某個線程的 Enqueue 函數(shù)分配的單元為 16,此時 cons_tail 的值是 10。當(dāng)這個 Enqueue 函數(shù)完成時將 cons_tail 更新為 11,但是此時對于物理單元 11 的操作狀態(tài)未知。物理單元 11 有可能已經(jīng)完成了 Enqueue 操作,也有可能物理單元 11 還是空的。
為了避免功能錯誤,則需要在操作分配的單元時進(jìn)行檢查。對于 Enqueue,如果分配的單元不為空,則一直等待;類似地,對于 Dequeue,如果分配的單元為空,則也要一直等待。
為了保證指針操作的原子性,需要使用__atomic_fetch_add原語更新另一個視角的指針。
至此,我們推導(dǎo)出了,非阻塞 Ringbuffer 的 Enqueue 和 Dequeue 的完整流程,如圖 19 所示。
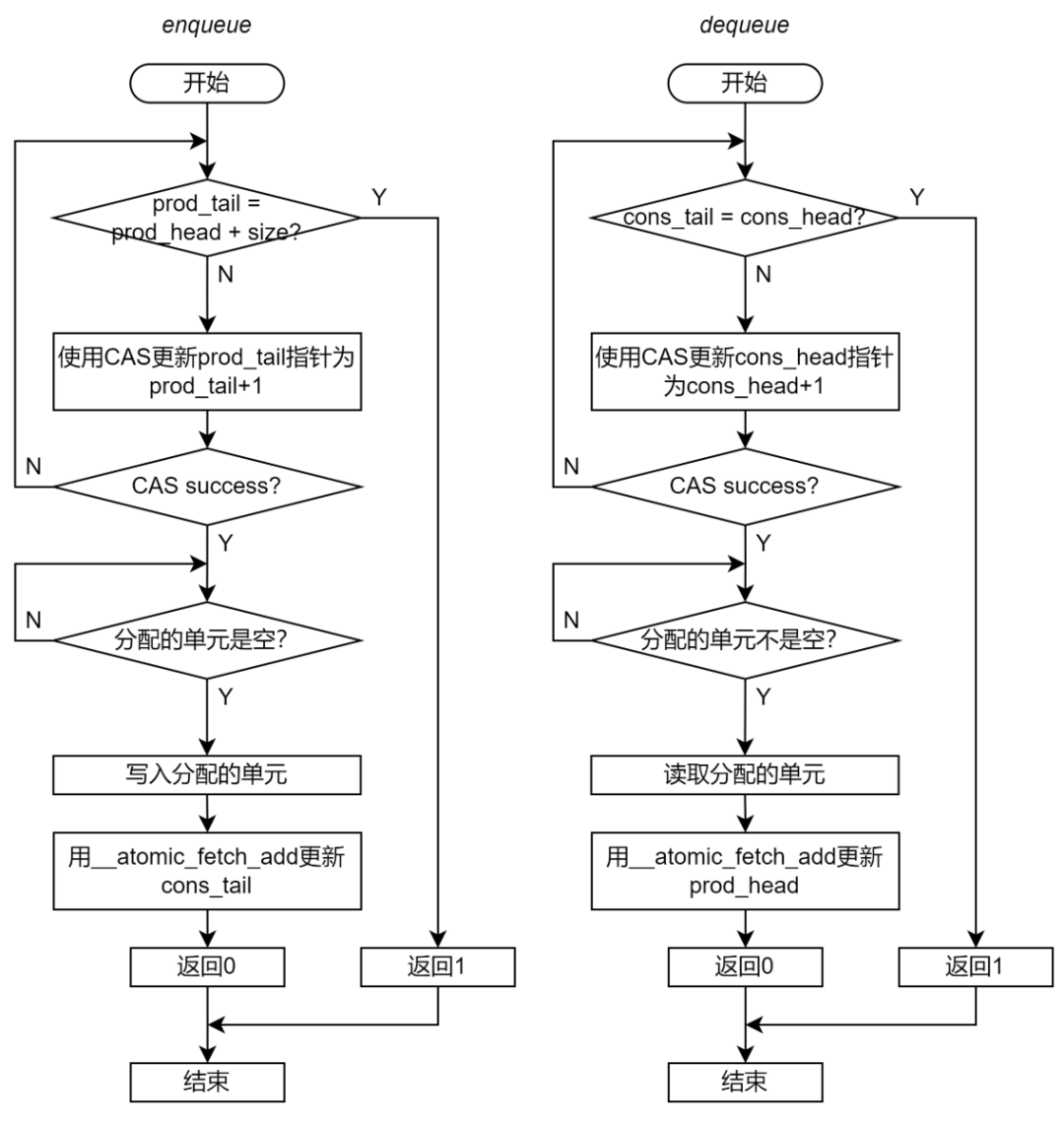
圖 19 非阻塞無鎖 Ringbuffer 實(shí)現(xiàn)的流程圖
Ringbuffer 聲明
非阻塞的無鎖 Ringbuffer 不需要序列號。每個數(shù)據(jù)單元中只有一個指向?qū)嶋H數(shù)據(jù)結(jié)構(gòu)的指針。
// Entry in ring buffer
class BufferEntry
{
public:
void *mp_ptr; // Pointer to data entry.
};
class RingBuffer
{
public:
alignas(64) unsigned int m_size;
// Pointers in the view of producer.
alignas(64) unsigned int m_prod_head; // read pointer
alignas(64) unsigned int m_prod_tail; // write pointer
// Pointers in the view of consumer.
alignas(64) unsigned int m_cons_head; // write pointer
alignas(64) unsigned int m_cons_tail; // read pointer
alignas(64) BufferEntry *mp_entries;
};
代碼 7 非阻塞無鎖 Ringbuffer 的聲明
Enqueue 和 Dequeue
本文測試的非阻塞 Ringbuffer 實(shí)現(xiàn)采用了亂序釋放的方法。
int enqueue_ringbuf(RingBuffer *ring_buffer, void *entry)
{
// Step 1: acquire slots
unsigned int tail = __atomic_load_n(&ring_buffer->m_prod_tail, __ATOMIC_RELAXED);
do
{
unsigned int head = __atomic_load_n(
&ring_buffer->m_prod_head, __ATOMIC_ACQUIRE);
if (ring_buffer->m_size + head == tail)
{
return 1;
}
} while (!__atomic_compare_exchange_n(&ring_buffer->m_prod_tail,
&tail, // Updated on failure
tail + 1,
/*weak=*/true,
__ATOMIC_RELAXED,
__ATOMIC_RELAXED));
// Step 2: Write slots
int enq_ptr = (tail % ring_buffer->m_size) * 8;
void *entry_ptr;
do
{
entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, __ATOMIC_RELAXED);
} while (entry_ptr != NULL);
__atomic_store_n(&ring_buffer->mp_entries[enq_ptr].mp_ptr, entry, __ATOMIC_RELEASE);
// Finally make all released slots available for new acquisitions
__atomic_fetch_add(&ring_buffer->m_cons_tail, 1, __ATOMIC_RELEASE);
return 0;
}
int dequeue_ringbuf(RingBuffer *ring_buffer, void **entry)
{
// Step 1: acquire slots
unsigned int tail = __atomic_load_n(&ring_buffer->m_cons_head, __ATOMIC_RELAXED);
do
{
unsigned int head = __atomic_load_n(
&ring_buffer->m_cons_tail, __ATOMIC_ACQUIRE);
if (head == tail)
{
return 1;
}
} while (!__atomic_compare_exchange_n(&ring_buffer->m_cons_head,
&tail, // Updated on failure
tail + 1,
/*weak=*/true,
__ATOMIC_RELAXED,
__ATOMIC_RELAXED));
// Step 2: Write slots (write NIL for dequeue)
int deq_ptr = (tail % ring_buffer->m_size) * 8;
unsigned int entry_sn;
void *entry_ptr;
do
{
entry_ptr = __atomic_load_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, __ATOMIC_ACQUIRE);
} while (entry_ptr == NULL);
*entry = entry_ptr;
__atomic_store_n(&ring_buffer->mp_entries[deq_ptr].mp_ptr, 0, __ATOMIC_RELAXED);
// Finally make all released slots available for new acquisitions
__atomic_fetch_add(&ring_buffer->m_prod_head, 1, __ATOMIC_RELEASE);
return 0;
}
代碼 8 非阻塞無鎖 Ringbuffer 的實(shí)現(xiàn)
非阻塞的無鎖 ringbuffer 實(shí)現(xiàn)的完整源碼請參見(https://github.com/wangeddie67/ringbuffer_opt_demo/blob/main/srcs/buck_blkring.h)。
非阻塞 Ringbuffer 性能測試結(jié)果
非阻塞的無鎖 Ringbuffer 的性能如圖 13 所示。曲線 mutex 表示基于 mutex 的 Ringbuffer 實(shí)現(xiàn);lockfree 和 atomic 表示無鎖 Ringbuffer 實(shí)現(xiàn)(lockfree 使用普通 load/store 操作數(shù)據(jù)單元;atomic 使用原子 load/store 操作數(shù)據(jù)單元);align 表示緩存行對齊后的無鎖 Ringbuffer 實(shí)現(xiàn);buck 表示的非阻塞無鎖 Ringbuffer 實(shí)現(xiàn)。
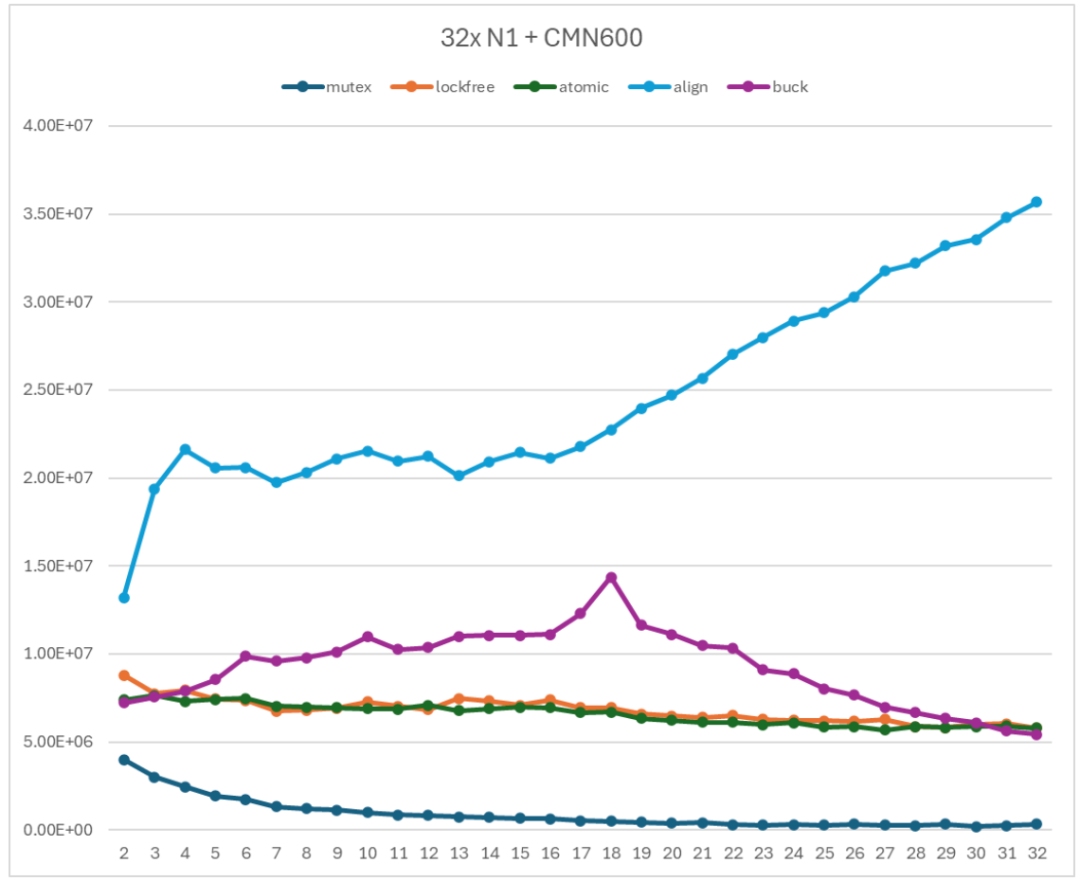
圖 20 非阻塞無鎖 Ringbuffer 性能測試
非阻塞的無鎖 Ringbuffer 的性能曲線呈現(xiàn)兩段趨勢:
從 2 個線程到 16 個線程左右,吞吐率隨著線程數(shù)增加而緩慢增加。
從 16 個線程左右到 32 個線程,吞吐率隨著線程數(shù)增加而緩慢降低。
與基于 mutex 的 Ringbuffer 相比,非阻塞 Ringbuffer 的性能要遠(yuǎn)好于基于 mutex 的 Ringbuffer 的性能,并且在使用 16-20 個線程時達(dá)到最高。
另一方面,與緩存行對齊的無鎖 Ringbuffer 實(shí)現(xiàn)相比,非阻塞 Ringbuffer 的性能差強(qiáng)人意。這是因?yàn)榉亲枞?Ringbuffer 引入了更多的指針競爭。阻塞的無鎖 Ringbuffer 實(shí)現(xiàn)的 Enqueue 和 Dequeue 中只關(guān)注一個共享指針。但是非阻塞 Ringbuffer 實(shí)現(xiàn)的 Enqueue 和 Dequeue 則需要關(guān)注三個共享指針。這就導(dǎo)致出現(xiàn)了更多的共享變量的競爭,從而引起了性能下降。
取 2 個線程、16 個線程和 32 個線程三個位置進(jìn)行定量比較,得到下表。表中第一行是吞吐率數(shù)據(jù)(單元 ops/s),第二行是相對于基準(zhǔn)(基于 mutex 的 Ringbuffer 實(shí)現(xiàn))的加速比。
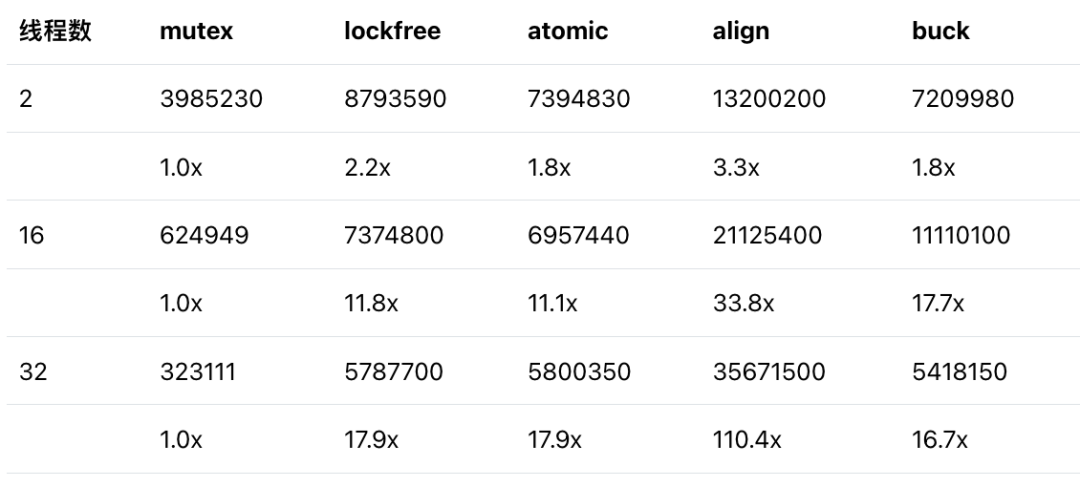
相對于基于 mutex 的 Ringbuffer,非阻塞的無鎖 Ringbuffer 可以取得超過 10 倍的吞吐率提升。這表示非阻塞的無鎖 Ringbuffer 實(shí)現(xiàn)仍然是非常有效的,值得在實(shí)際應(yīng)用中嘗試。
與 program64 的性能比較
在文系列完整的開篇處已經(jīng)聲明,本系列文章介紹的所有優(yōu)化來自于 Ola 的研究。Ola 開發(fā)的 program64 庫也是示例的 Ringbuffer 實(shí)現(xiàn)的基礎(chǔ)。
無鎖 Ringbuffer 實(shí)現(xiàn)對應(yīng)于 program64 庫中的 p64_blkring 實(shí)現(xiàn)。
非阻塞 Ringbuffer 實(shí)現(xiàn)對應(yīng)于 program64 庫中的 p64_buckring 實(shí)現(xiàn)。
這里將 program64 庫的實(shí)現(xiàn)集成到我們的測試程序中,使用相同的測試環(huán)境和配置進(jìn)行了測試。align 和 p64_blkring 是一個對照組;buck 和 p64_buckring 是一個對照組。
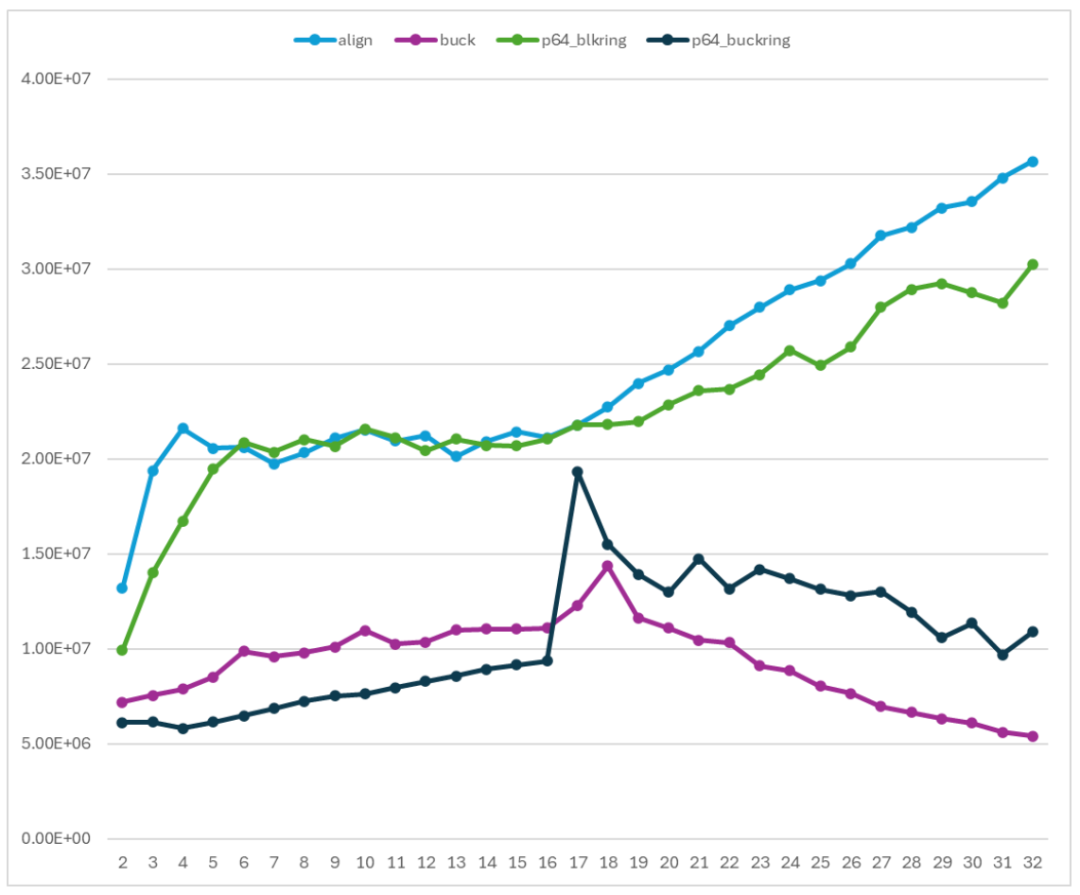
圖 21 在 Arm 平臺上與 Program64 庫對比性能
我們的示例代碼的性能與 program64 的性能在趨勢上是一致,并且在數(shù)值范圍上基本重合。兩者之間的差距則是由于實(shí)現(xiàn)的細(xì)節(jié)引入的。比如 program64 的 Enqueue 和 Dequeue 可以操作多個單元,而示例代碼只能操作一個單元。這些差距并不影響關(guān)于 Ringbuffer 優(yōu)化的結(jié)論。
結(jié)論
本文介紹了多種 Ringbuffer 實(shí)現(xiàn),并且比較和分析了不同 Ringbuffer 實(shí)現(xiàn)的性能表現(xiàn):
基于 mutex 的 Ringbuffer 性能主要受到多線程相互競爭 mutex 的影響。參與競爭的線程越多,Ringbuffer 的吞吐率越低,非常不利于系統(tǒng)規(guī)模的擴(kuò)展。
阻塞式的無鎖 Ringbuffer 能夠從原子操作和緩存行對齊兩個優(yōu)化中獲得非常明顯的收益,使得實(shí)現(xiàn)能夠充分利用系統(tǒng)中互聯(lián)系統(tǒng)提供的通信容量,是一種非常有利于系統(tǒng)規(guī)模擴(kuò)展的 Ringbuffer 實(shí)現(xiàn)。
非阻塞 Ringbuffer 實(shí)現(xiàn)豐富并完善了 Ringbuffer 的功能,并且同樣可以取得很好的性能優(yōu)化。但是由于引入了更多的共享變量,非阻塞 Ringbuffer 實(shí)現(xiàn)的性能要弱于緩存行對齊的無鎖 Ringbuffer 實(shí)現(xiàn)。
-
ARM
+關(guān)注
關(guān)注
134文章
9235瀏覽量
371734 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9485瀏覽量
86639 -
軟件
+關(guān)注
關(guān)注
69文章
5071瀏覽量
88534 -
數(shù)組
+關(guān)注
關(guān)注
1文章
419瀏覽量
26158
原文標(biāo)題:在 Arm 平臺上實(shí)現(xiàn)性能可擴(kuò)展的 Ringbuffer
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
C/C++性能優(yōu)化背后的方法論:TMAM
【獨(dú)風(fēng)科創(chuàng)】RingBuffer開源C語言組件發(fā)布啦
HBase性能優(yōu)化方法總結(jié)
Linux和Android系統(tǒng)故障和優(yōu)化性能的方法和流程探討
差動放大器的性能優(yōu)化方法
AN0004—AT32 性能優(yōu)化
使用RingBuffer處理數(shù)據(jù)
求助大神,rt_ringbuffer_peak疑問求解
《現(xiàn)代CPU性能分析與優(yōu)化》---精簡的優(yōu)化書

ringbuffer數(shù)據(jù)結(jié)構(gòu)介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論