

遙想兩年前,ChatGPT給了世界一記AI沖擊,而DeepSeek無疑是第二記沖擊。我們不僅對DeepSeek強勁的性能所震撼,也讓遠在大洋彼岸的OpenAI、谷歌、META等一眾玩家感受到莫大壓力,從而紛紛繼續“卷”起來,效仿DeepSeek的“開源”模式。
對于DeepSeek本身,人們關注其如何在有限算力實現強大性能,更關注其在重重條令圍城之下的未來之路。而在最近,全世界的芯片廠商集體出動,紛紛宣布支持DeepSeek。尤其是眾多國產AI芯片廠商,集體發力,為DeepSeek建立了一個堅實的后盾。
緣起:DeepSeek成功背后
為什么DeepSeek能夠掀起如此巨浪?因為令人驚訝的是,目前普遍認為DeepSeek僅僅用了550萬美元的成本實現了openAI上億美元做到的事。總結起來,DeepSeek有四點創新:
第一,拉低整體成本。信息顯示,DeepSeek V3模型的訓練總計耗用278.8萬GPU小時,相當于在2048塊H800 GPU集群上訓練約2個月,成本為557.6萬美元。相比之下,GPT-4o的訓練成本約為1億美元,需使用上萬塊性能更強的H100 GPU。同時,DeepSeek V3的成本僅為Llama 3的7%。AI專家指出,達到DeepSeek V3級別的能力需接近16000顆GPU的集群。
之所以有很低的成本,是DeepSeek的模型架構與主流設計有所不同,采用了細顆粒度的MoE(混合專家)結構。雖然細顆粒度MoE并非首創,例如阿里也在探索這一方向,但DeepSeek通過這一架構在推理時僅激活部分參數,從而顯著降低成本。此外,DeepSeek在推理機制中引入了LLA,與市場上常見的多頭注意力機制不同,后者需要所有參數參與計算,而DeepSeek僅激活少量參數,進一步提升了效率。當前先進模型大多采用鄧氏架構,而DeepSeek的創新在于通過細顆粒度MoE和LLA實現了更高效的推理。
第二,訓練方法。傳統方法為FP32和FP16的混合精度,DeepSeek則采用FP8參數,比較敏感的組件還是FP16。分布式混合精度目前做的比較少,訓練方法里面也有工程優化,之前時延導致GPU利用率不是很高,DeepSeek用流水線并行,高效利用通信網絡,提升速率。
第三,編程不同。DeepSeek采用了NVIDIA PTX指令集(Parallel Thread Execution ISA)來提升執行效能。PTX是NVIDIA GPU最底層的控制語言,用更細顆粒度來調度底層單元,將硬件調度細化。不過,此處需要注意PTX并非是CUDA的替代品,對于大部分開發者來說學習門檻較高,所以才有了CUDA來簡化開發過程。
第四,AI Infra,通常集群是三層網絡,DeepSeek是兩層,通信庫降低PCIe消耗,減少GPU內存消耗增高網絡通信速度,HF Reduce、分布式文件系統、調度平臺用得比較靈活。
雖說在各種突破之下,DeepSeek的表現驚人。但對大多數用戶來說,也許更多的體驗是“服務器繁忙,請稍后再試”,除了國外對于DeepSeek的攻擊以外,也許DeepSeek的算力真的不夠用了。
根據國泰君安證券分析師舒迪、李奇測算,假設DeepSeek日均訪問量為1億次、每次提問10次,每次提問的回復用到1000個token,1000個token大概對應750個英文字母,則DeepSeek每秒的推理算力需求為1.6*1019TOPs。在這種普通推理情境下,假設DeepSeek采用的是FP8精度的H100卡做推理,利用率50%,那么推理端H100卡的需求為16177張,A100卡的需求為51282張。
這種情況下,AI芯片就顯得格外重要了。
后盾:國產芯片撐起一片天
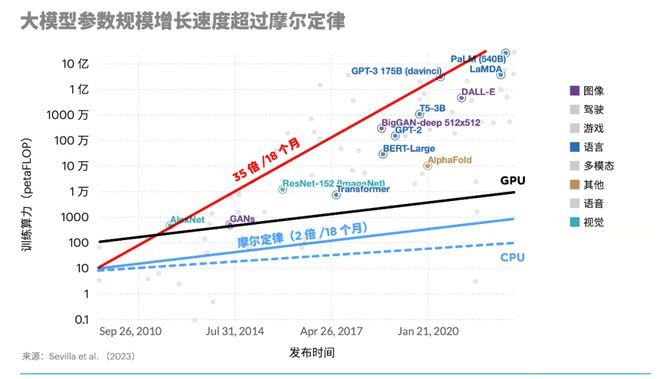
事實上,芯片算力一直都在追著大模型奔跑。換句話說,未來算力需求一定難以滿足現在AI發展,DeepSeek未來會面對
據OpenAI測算,自2012年以來,AI模型訓練算力需求每3~4個月就翻一番,每年訓練AI模型所需算力增長幅度高達10倍。而連摩爾定律中,芯片計算性能翻一番的周期為18~24個月,更何況摩爾定律已經出現放緩跡象。專家預測,未來幾年OpenAI僅訓練模型?少還需要200~300億美元的硬件,Google需要200-300億美元,Anthropic需要100-200億美元,未來幾年至少投入1000億美元純粹用到訓練?模型。
芯片廠商當然沒有錯過DeepSeek這一機會,比如在春節期間,國外芯片廠商接連宣布支持DeepSeek:
1月25日,AMD將DeepSeek-V3模型集成于Instinct MI300X GPU;
1月31日,NVIDIA NIM微服務預覽版支持DeepSeek-R1模型英偉達;
1月31日,英特爾DeepSeek模型能在酷睿AIPC上離線使用;
2月1日,英特爾Gaudi 2D Al加速器支持DeepSeek Janus Pro模型。
自從AI大模型來了,英偉達喝湯喝到撐,GPU也就成了香餑餑。但在地緣政治局勢愈發緊張的現如今,國內高端AI芯片不斷被圍追堵截。因此,自主可控成了不可不談的問題。近幾日,DeepSeek獲國產芯片廠商力挺,成為支撐DeepSeek的“天團”。
1.華為:華為云宣布與硅基流動聯合首發并上線基于華為云昇騰云服務的DeepSeek R1/V3推理服務;DeepSeek-R1、DeepSeek-V3、DeepSeek-V2、Janus-Pro正式上線昇騰社區;華為DCS AI全棧解決方案中的重要產品—ModelEngine,全面支持DeepSeek大模型R1&V3和蒸餾系列模型的本地部署與優化,加速客戶AI應用快速落地;
2.沐曦:Gitee AI聯合沐曦首發全套DeepSeek R1千問蒸餾模型,全免費體驗;DeepSeek-V3滿血版在國產沐曦GPU首發體驗上線;
3.天數智芯:成功完成與 DeepSeek R1 的適配工作,并且已正式上線多款大模型服務,其中包括DeepSeek R1-Distill-Qwen-1.5B、DeepSeek R1-Distill-Qwen-7B、DeepSeek R1-Distill-Qwen-14B等;
4.摩爾線程:基于Ollama開源框架,完成了對DeepSeek-R1-Distill-Qwen-7B蒸餾模型的部署,并在多種中文任務中展現了優異的性能;
5.海光信息:DeepSeek V3和R1模型完成海光DCU適配并正式上線;海光DCU成功適配DeepSeek-Janus-Pro多模態大模型;
6.壁仞科技:DeepSeek R1在壁仞國產AI算力平臺發布,全系列模型一站式賦能開發者創新;
7.太初元碁:基于太初T100加速卡2小時適配DeepSeek-R1系列模型,一鍵體驗,免費API服務;
8.云天勵飛:完成 DeepEdge10 “算力積木”芯片平臺與DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B大模型的適配,可以交付客戶使用;
9.燧原科技:完成對DeepSeek全量模型的高效適配,包括DeepSeek-R1/V3 671B原生模型、DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek R1-Distill-Llama-8B/70B等蒸餾模型。截至目前,DeepSeek的全量模型已在慶陽、無錫、成都等智算中心完成了數萬卡的快速部署;
10.昆侖芯:完成全版本模型適配,這其中包括DeepSeek MoE 模型及其蒸餾的Llama/Qwen等小規模dense模型;
11.靈汐芯片:完成了DeepSeek-R1系列模型在靈汐KA200芯片及相關智算卡的適配,助力國產大模型與類腦智能硬件系統的深度融合;
12.鯤云科技:全新一代的可重構數據流AI芯片CAISA 430成功適配DeepSeek R1蒸餾模型推理;
13.希姆計算:僅用數小時就將DeepSeek-R1全系列蒸餾模型快速適配到自研RISC-V開源指令集的推理加速卡系列之上,并落地全國多個千卡級以上智算中心;
14.算能:算能自研RISC-V開源指令集融合服務器SRM1-20,成功適配并本地部署DeepSeek-R1-Distill-Qwen-7B/1.5B模型;
15.清微智能:可重構計算架構RPU芯片已完成DeepSeek-R1系列模型的適配和部署運行;
16.龍芯中科:搭載龍芯3號CPU的設備成功啟動運行DeepSeek R1 7B模型,實現本地化部署;
17.瀚博:已完成DeepSeek-V3與R1全系列模型訓推適配,單機可支持V3與R1 671B全量滿血版模型部署。
復盤:國產AI芯片發展現狀
前兩年,美國千方百計阻止英偉達向中國出售尖端AI芯片,不想放棄中國市場的英偉達,迅速推出中國特供版,但對國內來說,卻不香了。所謂中國特供芯片,性能砍了25%,但減量不減價,國產廠商則紛紛點名華為,尤其是華為升騰910B芯片。那么,除了華為,我國還有哪些AI芯片企業值得關注?
AI芯片主要分為GPGPU(通用圖形處理器)、FPGA(可編程邏輯器件)、ASIC(專用集成電路)、存算一體和類腦芯片幾種。根據在網絡中的位置,又可以分為云端AI芯片 、邊緣和終端AI芯片。
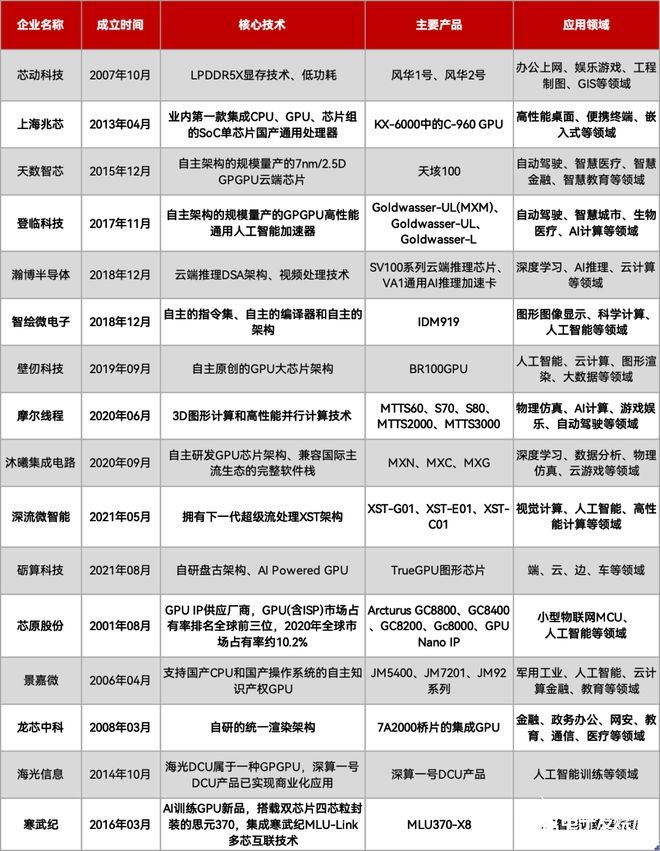
GPU/GPGPU:與GPU不同,GPGPU就是將GPU圖形顯示部分“摘掉”,全力走通用計算,特別適合用在深度學習訓練方面。目前國內GPU存在許多玩家,整個行業也經歷過一輪洗牌。
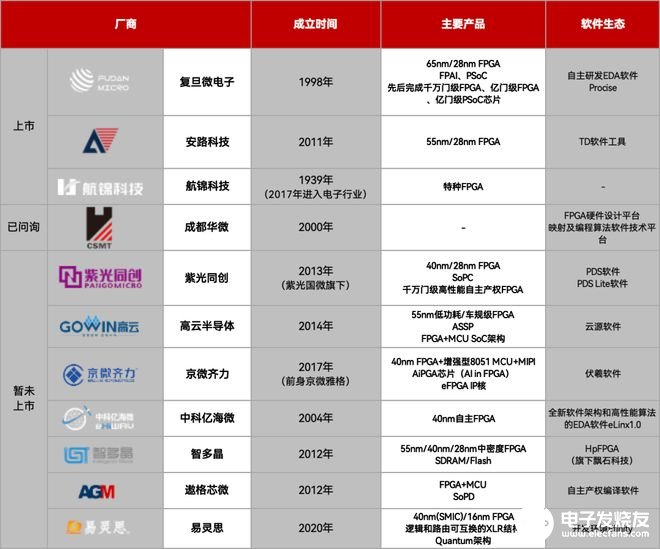
FPGA:可編程的靈活性是任何其它計算芯片無法替代的,同時它在AI領域也具備一定計算能力,但相對來說,FPGA的成本就相對高一些了,而且FPGA開發也很難,軟件生態沒有GPGPU的CUDA那么方便。
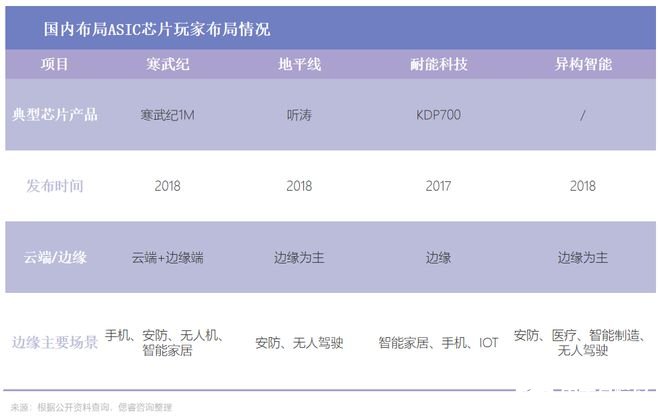
ASIC:性能強、功耗低,NPU也是加入神經單元的一種ASIC,不過針對特定算法計算,算法是無法修改的,想要做另一種算法就要再造一種ASIC芯片,前期開發需要FPGA輔助進行。
值得一提的是,TPU,全稱Tensor Processing Unit,是一種專為處理張量運算而設計的ASIC芯片,由谷歌自研在2016年推出首款產品,目前國內也有中昊芯英這一玩家。
存算一體:能耗比極佳,能夠突破存儲墻和功耗墻,但商業化進程加速了,而且據說ST也準備在未來發布具有存算一體芯片的MCU。
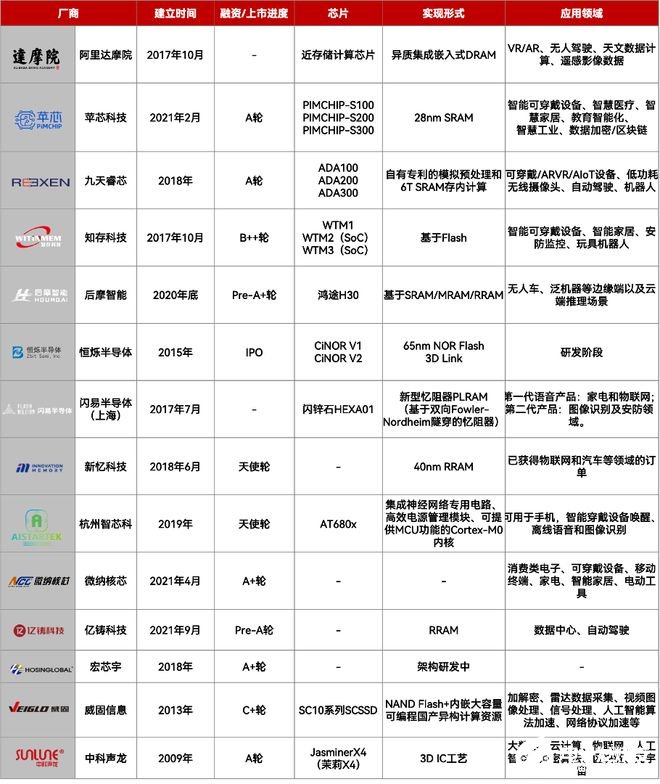
類腦計算:性能更強、功耗更低,算法也變成了SNN,但全世界都在研究之中,還未商業化。
可重構計算:能夠重新配置的數據流處理器架構,專為特定用例量身定制,可在其“計算結構”上并行執行經過特殊優化的代碼。特別是在低功耗嵌入式和邊緣計算中,并且需要支持通用編程語言的專有軟件堆棧(編譯器)。
目前,可重構計算的玩家包括清微智能、鯤云科技、千芯科技、瀾起科技。(可參考文章:《》)
融合:千行百業正在被重塑
DeepSeek誕生的本身,也在促進著國內所有行業的發展,形成了一個循環的產業鏈。千行百業,正在因為DeepSeek而重塑,各行各業也不斷支持DeepSeek。
1.汽車產業:吉利汽車、東風汽車、東風旗下嵐圖汽車等均宣布了接入DeepSeek,大模型“上車”已經成為大趨勢;
2.手機:華為系統級智能體小藝在HarmonyOS NEXT(原生鴻蒙)上接入了DeepSeek最新的R1模型,OPPO Find N5也將接入DeepSeek;
3.云計算:阿里云、百度智能云、騰訊云、華為云已經官宣支持 DeepSeek大模型;
4.教育應用:網易有道、云學堂均宣布全面擁抱DeepSeek-R1;
5.網絡安全:360、奇安信、啟明星辰、安恒、北信源、天融信、國投智能、安博通、永信至誠、亞信、拓爾思、觀安信息均宣布接入DeepSeek;
6.生物醫藥:恒瑞醫藥、醫渡科技、智云健康、豫資開勒均宣布了DeepSeek的接入與部署;
7.電信運營商:三大運營商中國移動、聯通、電信全面宣布接入DeepSeek;
8.軟件公司:遠光軟件、安恒信息、當虹科技、萬興科技、金慧軟件接入DeepSeek模型。
總之,DeepSeek作為一次“全民狂歡”,其意義非凡。為了契合這個話題,我們也問了DeepSeek自己對于自己誕生的意義,它的回答是:DeepSeek的誕生不僅是技術上的突破,更是對AI未來形態的積極探索。它通過開源共享、垂直應用和AGI愿景,推動AI從“工具”向“伙伴”演進,同時助力中國在全球AI競爭中占據更重要的戰略地位。其意義不僅限于商業成功,更在于為人類與AI共生的未來提供了一種可能性。
作者:EEWorld電子工程世界 付斌 在此特別鳴謝!
-
國產芯片
+關注
關注
2文章
289瀏覽量
30222 -
AI芯片
+關注
關注
17文章
1930瀏覽量
35446 -
算力
+關注
關注
1文章
1048瀏覽量
15158 -
DeepSeek
+關注
關注
1文章
654瀏覽量
471
發布評論請先 登錄
相關推薦
HarmonyOS NEXT開發實戰:DevEco Studio中DeepSeek的使用
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預測......
RK3588開發板上部署DeepSeek-R1大模型的完整指南
后摩智能攜手聯想開天打造基于DeepSeek的信創AI PC
鴻蒙原生應用開發也可以使用DeepSeek了
DeepSeek、晶振在AI終端中的相關應用
DeepSeek一體機發布!四大廠商入局,加速AI應用落地






 工商網監
工商網監

評論