") 探索對抗訓練的概率分布偏差:DPA雙概率對齊的通用域自適的目標檢測方法
探索對抗訓練的概率分布偏差:DPA雙概率對齊的通用域自適的目標檢測方法

論文標題:Universal Domain Adaptive Object Detection via Dual Probabilistic Alignment
論文地址:
https://arxiv.org/abs/2412.11443
代碼地址:
https://github.com/WeitaiKang/SegVG/tree/main
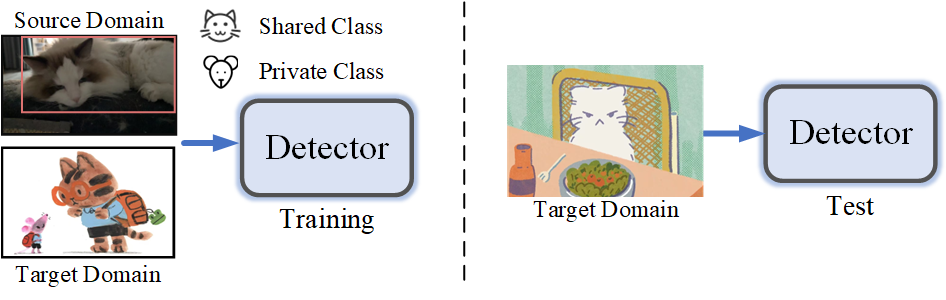
▲ 圖1. UniDAOD任務示例 (通用跨域目標檢測)
目標檢測作為計算機視覺領域的核心任務,在閉集場景中已經取得了顯著的進展。然而,現(xiàn)有的方法通常假設類別集合是固定的,并依賴于大量的標注數(shù)據(jù),這導致它們在處理跨域數(shù)據(jù)時,特別是在源域與目標域之間存在域偏移的情況下,泛化性能受限。例如,針對晴天數(shù)據(jù)訓練的目標檢測模型往往難以有效適應霧天或其他場景條件下的場景變化。
為了應對這一挑戰(zhàn),域自適應目標檢測(Domain Adaptive Object Detection, DAOD)方法被提出。DAOD 的主要目標是通過將源域的有標簽數(shù)據(jù)遷移到目標域的無標簽數(shù)據(jù)上,從而緩解源域與目標域之間分布不一致所帶來的性能下降問題。
在源域和目標域類別集合相同的前提下,DAOD 能夠有效實現(xiàn)跨域遷移,并減少對大規(guī)模標注數(shù)據(jù)的依賴,從而降低了高昂的數(shù)據(jù)標注成本。然而,在開放世界場景中,源域與目標域之間可能會存在私有類別(即目標域包含源域未見過的類別)。因此,傳統(tǒng)的 DAOD 方法受限于閉集假設,無法處理私有類別的域對齊問題,從而限制了其在開放世界場景中的應用。
為了解決這一問題,通用域自適應目標檢測(Universal Domain Adaptive Object Detection, UniDAOD)方法被提出。UniDAOD 通過放寬類別集合的閉集假設,能夠在沒有類別先驗信息的情況下實現(xiàn)源域與目標域的跨域對齊,從而適應包括閉集、部分集和開放集等多種場景。此方法顯著提升了目標檢測模型在開放世界中的魯棒性和泛化能力,拓展了目標檢測技術在更復雜和動態(tài)場景中的應用范圍。
現(xiàn)有UniDAOD模型的不足
現(xiàn)有的通用域自適應目標檢測(UniDAOD)方法的核心思想借鑒了域自適應目標檢測(DAOD)和通用域自適應(UniDA)方法的范式。
具體而言,UniDAOD 方法結合了 DAOD 系列的基礎對齊方法,包括實例對齊與全局對齊,并借鑒了 UniDA 系列方法來挖掘源域和目標域中的公共類別樣本。在 UniDA 中,通過構建概率閾值機制,域判別器的概率層面能夠篩選出公共類別的樣本,從而實現(xiàn)源域與目標域的對齊。
因此,現(xiàn)有的 UniDAOD 方法的基本流程通常包括以下步驟:
首先,區(qū)分源域和目標域中的類別,并將其劃分為公共類別和私有類別;
接著,去除私有類別,僅保留公共類別;
然后,針對這些公共類別的特征進行對齊,從而實現(xiàn)從開放集場景到閉集場景的轉變。
在域判別器的設計上,UniDAOD 通過設定概率閾值來進一步區(qū)分源域和目標域中的公共類別與私有類別,從而達到更精確的對齊效果。
盡管 UniDAOD 方法在許多場景下表現(xiàn)良好,尤其是在處理從閉集場景到開放集場景的轉變時,然而,直接使用 DAOD 和 UniDA 的方法結論,使得 UniDAOD 方法在開放世界場景下仍然存在次優(yōu)化問題。具體來說,以下兩個問題值得進一步探索:
1. 全局特征與實例特征是否都對齊公共類別特征?
2. 概率閾值是否在復雜的檢測任務中對不同特征都有效?
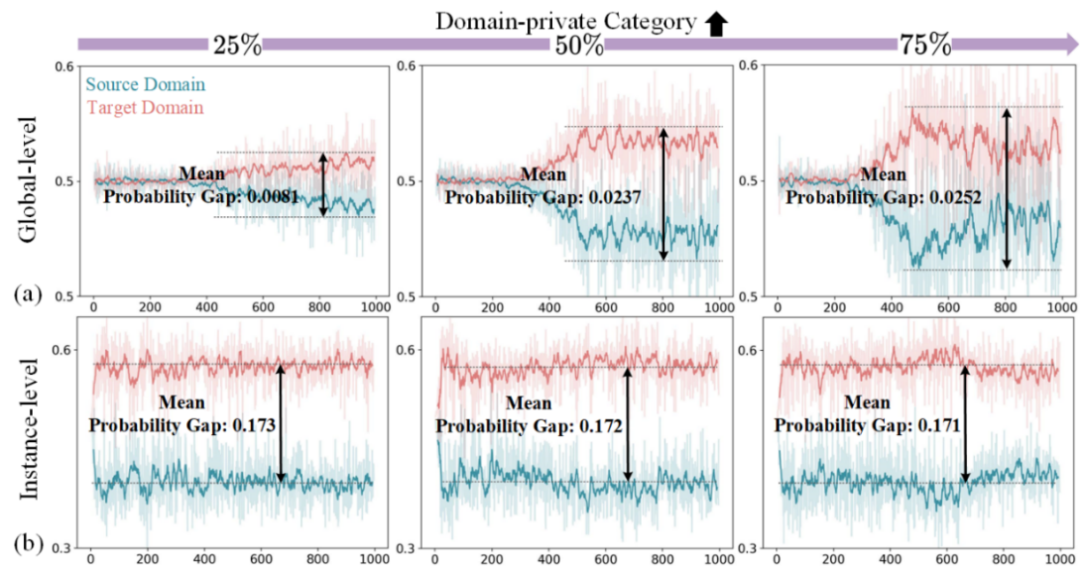
▲ 圖2. 域鑒別器中的概率的可視化。橫軸為訓練迭代次數(shù)(×100),縱軸為域判別器的概率。
為了探索上述問題,我們在圖 2 中對域判別器的概率進行了可視化分析。圖 2 為源域(Source Domain)和目標域(Target Domain)域鑒別器中的概率差異分析,分為全局級別(Global-level)和實例級別(Instance-level),在不同的域私有類別占比(25%、50%、75%)下進行評估。
在全局級別,圖 2(a) 中展示了隨著域私有類別比例的增加,源域與目標域之間的整體預測概率差異逐步擴大,表現(xiàn)為兩條概率曲線之間的間距逐漸增大,反映出域私有類別比例的提高顯著增強了域間的概率差異。
在實例級別圖 2(b) 中,呈現(xiàn)了實例目標特征的概率在源域和目標域中的概率差異。與全局級別相比,實例級別的概率差異更加顯著,即目標實例特征的概率差異在源域和目標域之間存在較大偏差。
此外,隨著域私有類別比例的增加,實例級別的概率差異并未發(fā)生顯著變化,而是保持相對穩(wěn)定。全局級別的概率差異隨著私有類別的增加而增加。
針對第一個問題,現(xiàn)有的域自適應目標檢測(DAOD)方法假設域共享類別集是已知的,并且在進行域對齊時,假定全局特征和實例特征對齊的貢獻是相同的。也就是說,全局特征和實例特征都應該對齊共享類別特征。然而,這與圖 2 中的結論相悖:全局特征傾向于對齊域私有類別,而實例特征則更傾向于對齊域共享類別。
針對第二個問題,現(xiàn)有的 UniDA 方法通過使用閾值對樣本進行篩選,但這依賴于穩(wěn)定的概率分布。在圖 2(a) 中,概率差異波動較大,導致閾值難以有效篩選樣本;而在圖 2(b) 中,概率變化相對穩(wěn)定,因此閾值篩選樣本效果較好。不同的特征在概率分布上是異構的。因此,現(xiàn)有基于閾值的范式難以在目標檢測中有效適應不同特征下的概率分布。
為了解決上述兩個問題,我們通過公式推導(見圖 3)證明了在最小化標簽函數(shù)期望的條件下,全局級別的特征傾向于對齊域私有類別,而實例級別的特征則傾向于對齊域共享類別。這一理論推導的結果與圖 2 中的實驗現(xiàn)象高度一致,進一步驗證了我們模型假設的合理性。基于這一發(fā)現(xiàn),接下來我們將引入雙概率建模方法,以實現(xiàn)異構域分布下的樣本采樣和權重估計。
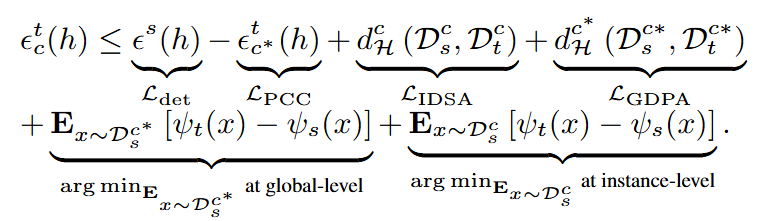
▲ 圖3. UniDAOD的泛化誤差上界
在全局特征層面,區(qū)域提議網絡(RPN)構建了前景類別 和背景類別 的類別空間。 表示標簽函數(shù)。因此,域共享和域私有類別標簽函數(shù)的概率為:。
在實例特征層面,ROI頭部(ROI-head)構建了前景域共享類別(c)、域私有類別( )和背景類別()的類別空間,其中類別數(shù)量 假設條件是大于 1 。因此,域共享和域私有類別標簽函數(shù)的概率可以表示為:
我們通過分析 P 以估計當前特征標簽函數(shù)的概率。全局特征層面最小化;
1. 當滿足條件 (global-feature) (instance-feature) 時,域私有標簽函數(shù)可以在全局特征層面最小化;
2. 當滿足條件 (global-feature) (instance-feature) 時,域共享標簽函數(shù)可以在實例特征層面最小化。
雙概率建模
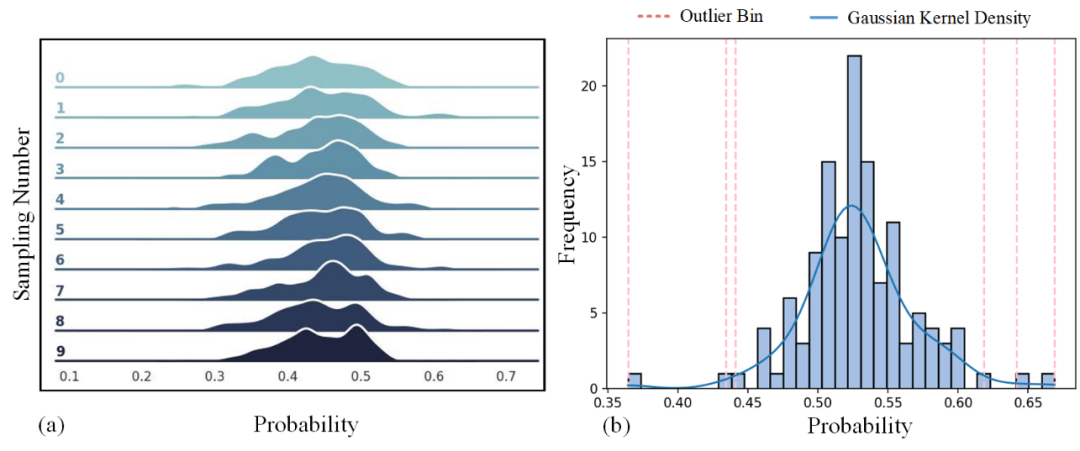
▲ 圖4. 實例級別特征的概率分布與頻率建模
通過圖 3 中的理論分析,我們已經明確了全局特征與實例特征在對齊過程中的不同作用,并揭示了域私有類別與域共享類別之間的關系。在此基礎上,雙概率建模方法能夠有效解決這些問題。
具體而言,我們通過對全局特征和實例特征進行正態(tài)分布建模,從而實現(xiàn)樣本的采樣與加權,進而更好地進行對齊。由于對抗訓練中的數(shù)據(jù)概率分布近似正態(tài)分布,因此我們采用正態(tài)分布對全局特征和實例特征進行建模,以進行樣本的采樣與加權。
在圖 4(a) 中,左圖展示了多次對實例特征進行采樣后的概率分布,結果表明這些特征的概率分布基本符合正態(tài)分布。因此,我們提出的一個直觀思路是通過正態(tài)分布建模概率,并剔除那些不符合正態(tài)分布的樣本。圖 4(b) 展示了我們的方法:首先計算樣本梯度的模長,并將其劃分為不同的 bins,進而建模高斯分布。
可以看到,位于分布邊緣之外的 bins 對應的樣本是需要剔除的樣本。所有這些 bins 的總和代表了特征空間中距離特征質心的采樣半徑,并且在對抗訓練過程中,基于源域或目標域數(shù)據(jù)的高斯分布,該半徑會動態(tài)調整。
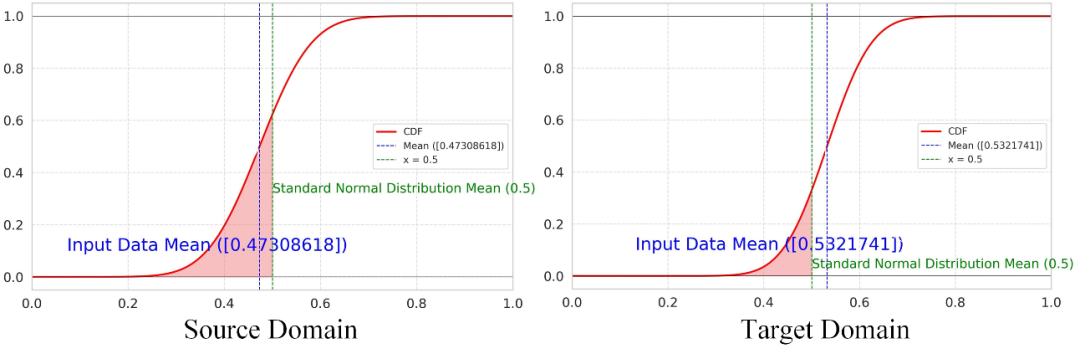
▲ 圖5. 全局級別特征的分布累計函數(shù)CDF
在全局特征層面,我們通過使用累計分布函數(shù)(Cumulative Distribution Function, CDF)來估計私有類別的分布,從而避免因過度域對齊而導致的負遷移問題。根據(jù)圖 2 的結論,私有類別的增強概率通常偏離 0.5,因此在 CDF 上,私有類別的數(shù)量與其對應的分布值之間存在一定的關系。
為了避免直接將 CDF 作為權重進行對齊所可能引發(fā)的過度域對齊問題,我們計算源域和目標域的 CDF,并采用正則化方法對其進行調整。具體的 CDF 計算公式如下:
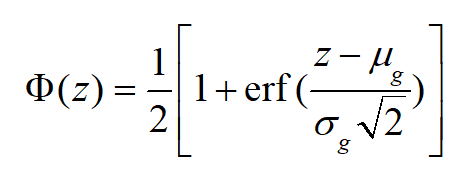
為了避免直接將 CDF 作為權重進行對齊所導致的過度域對齊,我們對源域和目標域的 CDF 值進行正則化調整。具體來說,我們設計了以下正則化形式作為域對齊的權重:
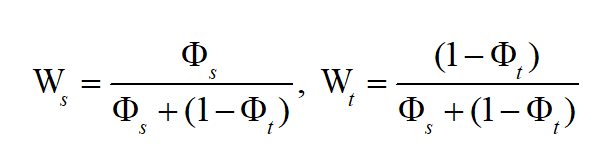
DPA模型框架
DPA 的模型設計思路主要來源于我們得到的公式(見圖 3)。在圖 6 中,DPA 包含三個定制模塊:全局級別域私有對齊(GDPA)、實例級別域共享對齊(IDSA)和私有類別約束(PCC)。
為了最小化目標域的域共享類別的上限 ,DPA 包括 GDPA、IDSA 和 PCC,以優(yōu)化方程:
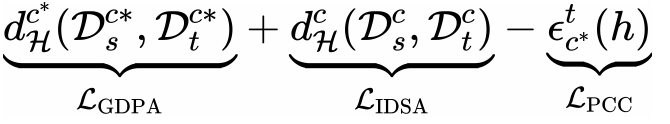
中的項。GDPA 最小化域私有類別 域分布差異 ,適用于全局級特征;IDSA 最小化域共享類別域分布差異 ,適用于實例級特征。此外,PCC 最大化目標域的域私有類別風險誤差 。
具體來說,GDPA 利用全局級別采樣挖掘域私有類別樣本并通過累積分布函數(shù)計算對齊權重來解決全局級別私有類別對齊。IDSA 利用實例級別采樣挖掘域共享類別樣本并通過高斯分布計算對齊權重來進行域共享類別域對齊以解決特征異質性問題。PCC 在特征和概率空間之間聚合域私有類別質心以緩解負遷移。
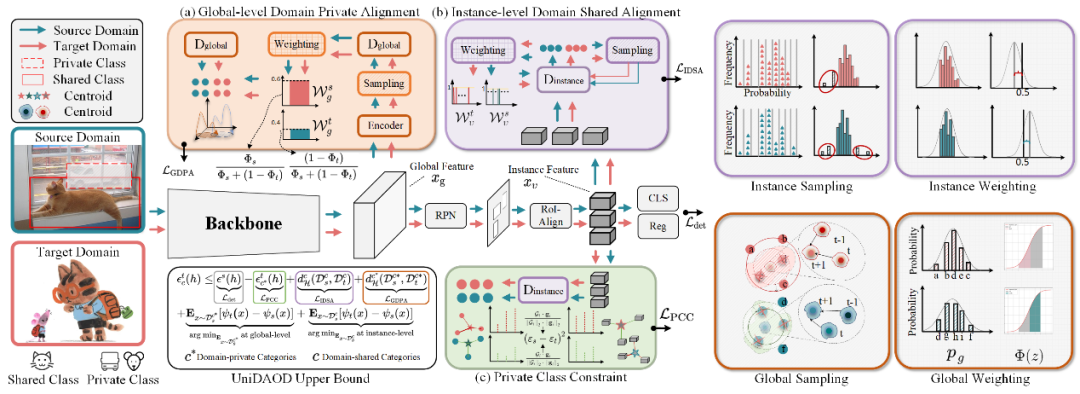
▲ 圖6. 本文所提出的DPA 框架示意圖
實驗結果
我們在三個域自適應場景(開放集、部分集和封閉集)中,針對五個數(shù)據(jù)集對我們的DPA框架進行了評估。這些數(shù)據(jù)集包括:Foggy Cityscapes、Cityscapes、Pascal VOC、Clipart1k 和 Watercolor。
我們在三鐘域自適應場景(開放集、部分集和封閉集)中,針對五個數(shù)據(jù)集對我們的DPA框架進行了評估。這些數(shù)據(jù)集包括:Foggy Cityscapes、Cityscapes、Pascal VOC、Clipart1k 和 Watercolor。
在開放集場景中,源域和目標域均包含共享類別和私有類別樣本。我們引入了多個共享類別比例 來構建不同的共享類別比例基準,其中 和 分別表示源域和目標域的類別集合。在部分集場景中,源域的類別集合是目標域類別集合的子集,或者反之亦然。在封閉集場景中,源域和目標域的類別集合完全相同。
開放集場景中的性能結果
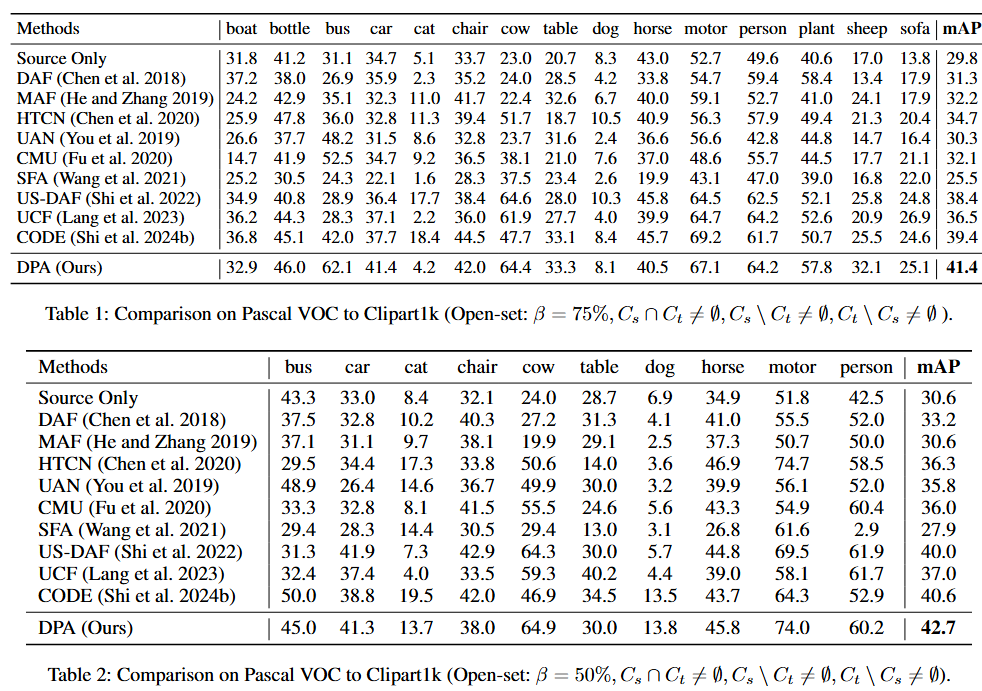
開放集場景中的性能結果
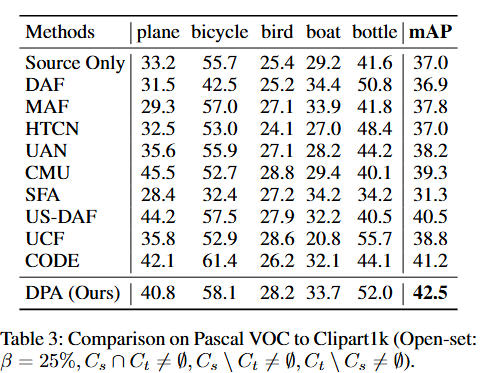
部分集場景中的性能結果
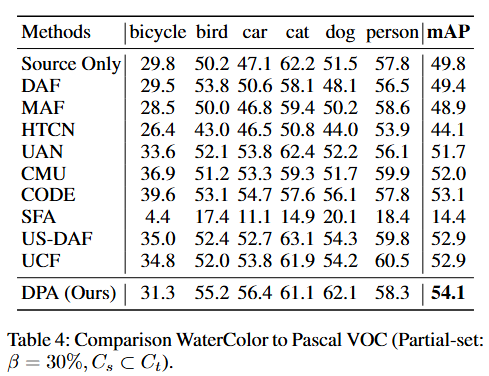
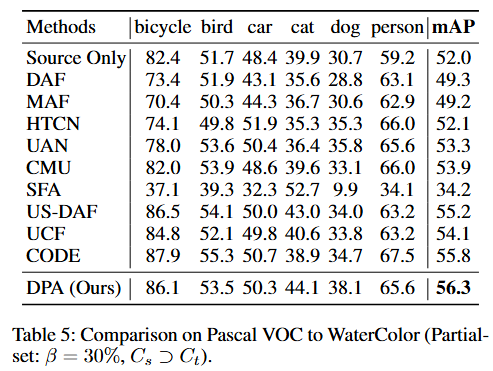
封閉集場景中的性能結果
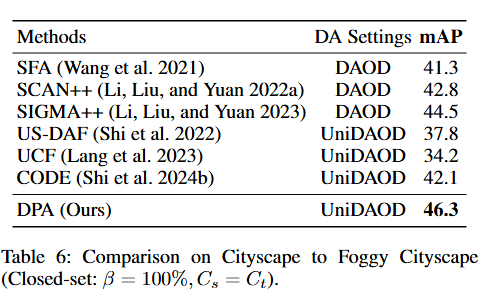
消融實驗
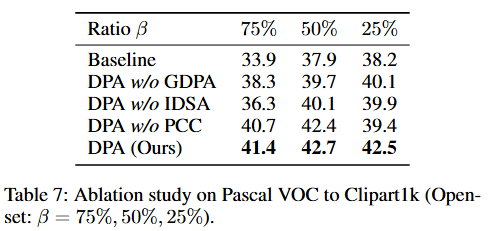
可視化分析
為了比較所提方法與現(xiàn)有 DAOD 和 UniDAOD 方法在正遷移和負遷移方面的性能,我們在圖 7 中展示了 DAOD 和 UniDAOD 相對于僅使用源域模型的性能提升。
結果顯示,DAOD 方法存在顯著的負遷移,其中 DAF、MAF 和 HTCN 在類別 0 上的平均精度(AP)分別下降約 2%、4% 和 1%。
相比之下,UniDAOD 方法有效緩解了負遷移,CODE 和 DPA 在類別 4 上分別實現(xiàn)了約 3% 和 10% 的正遷移。這種基于類別的性能分析證明了所提方法能夠有效應對負遷移并增強正遷移效果。
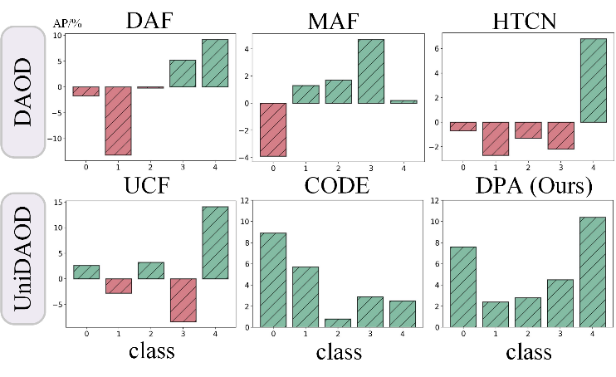
▲ 圖7. 相較于Source-Only模型的類別性能提升(類別包括飛機、自行車、鳥、船和瓶子)。正遷移以綠色表示,負遷移以紅色表示。
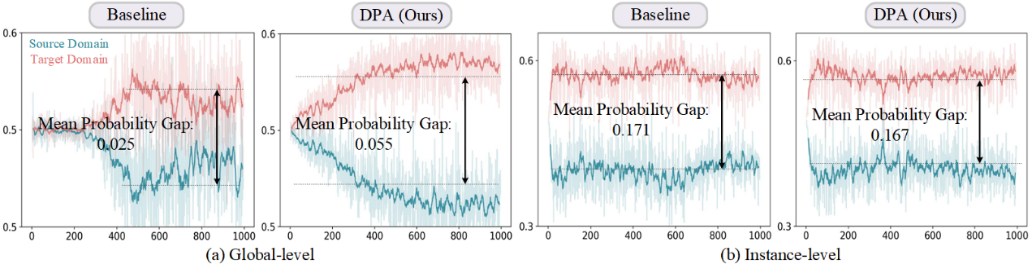
▲ 圖8. 關于類別對齊的定性分析,以平均概率差為指標:(a) 全局特征對齊,(b) 實例特征對齊。橫軸表示訓練迭代次數(shù)(×100),縱軸為域判別器的概率。基準實驗采用 Pascal VOC 到 Clipart1k 數(shù)據(jù)集()。
我們進一步分析了 DPA 框架在開放集對齊中的概率差表現(xiàn)。如圖8(a) 所示,全局級別的平均概率差在 DPA 中更加顯著,這突顯了其在區(qū)分域私有類別方面的有效性。相比之下,圖 8(b) 顯示實例級別的平均概率差較小,這表明 DPA 能更好地對齊域共享類別。
此外,我們對全局域私有對齊進行了權重定量分析(見圖 9)。隨著域私有類別比例的增加,平均權重差也隨之增大,這表明對抗訓練通過權重調整,自適應地懲罰了與域私有類別相關的特征。
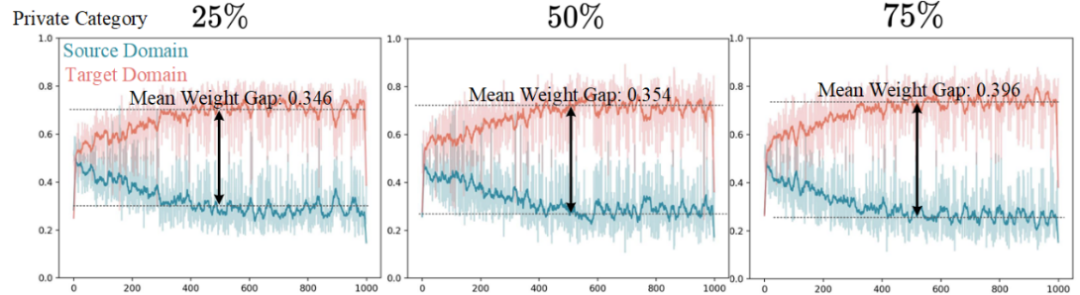
▲ 圖9. 針對全局域私有特征的權重定量分析。橫軸表示訓練迭代次數(shù)(×100),縱軸表示源域和目標域的權重值。
總結
我們提出了一種用于通用域自適應目標檢測的 DPA 框架,包含兩種概率對齊方式。受理論視角啟發(fā),我們設計了 GDPA 模塊,用于對齊全局私有樣本,以及 IDSA 模塊,用于對齊實例級域共享樣本。為應對負遷移問題,我們引入了 PCC 模塊,用于混淆私有類別的可辨識性。
大量實驗表明,在開放集、部分集和封閉集場景中,DPA 框架顯著優(yōu)于現(xiàn)有的通用域自適應目標檢測方法。
-
DPA
+關注
關注
0文章
31瀏覽量
15736 -
目標檢測
+關注
關注
0文章
211瀏覽量
15650
原文標題:AAAI 2025 | 探索對抗訓練的概率分布偏差:DPA雙概率對齊的通用域自適的目標檢測方法
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網技術研究所】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
LM98640是給一個過滿度的正弦波采集大量全碼數(shù)據(jù)進行概率分布計算DNL還是給個斜坡波進行靜態(tài)測試?
一文解析LOPA應用-點火概率估算的策略與實踐

AI模型部署邊緣設備的奇妙之旅:目標檢測模型
SAR ADC輸出規(guī)律性偏差是什么原因呢?
RNN的損失函數(shù)與優(yōu)化算法解析
TAS5731M零下15度開機后概率無聲音是怎么回事?
stm32f407+ksz8863rlli概率性ping不通
LM49450輸出引腳概率性燒壞的原因?
【探討】DTAS尺寸公差分析與尺寸鏈計算邀您探索單孔銷浮動之奧秘(二),快來圍觀吧!
OPA548輸出脈沖概率性失真怎么解?
【大語言模型:原理與工程實踐】大語言模型的基礎技術
雷達檢測概率曲線的影響因素
SPI從模式MISO會概率性出現(xiàn)毛刺的原因?
深度學習檢測小目標常用方法






 工商網監(jiān)
工商網監(jiān)
評論