 聚類分析基本概念梳理
聚類分析基本概念梳理
聚類分析:簡稱聚類(clustering),是一個把數據對象劃分成子集的過程,每個子集是一個簇(cluster),使得簇中的對象彼此相似,但與 其他簇中的對象不相似。聚類成為自動分類,聚類可以自動的發現這些分組,這是突出的優點。
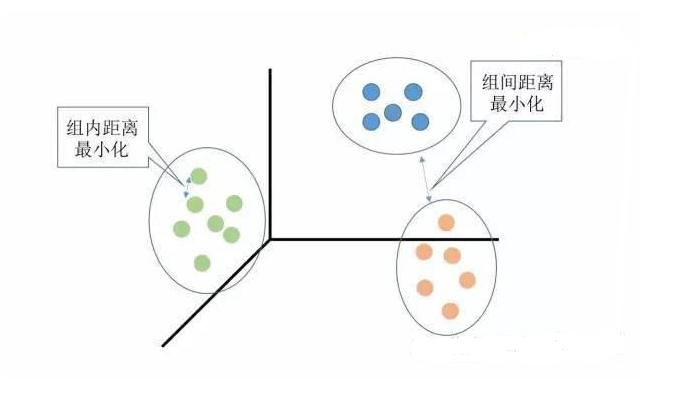
聚類分析是沒有給定劃分類別的情況下,根據樣本相似度進行樣本分組的一種方法,是一種非監督的學習算法。聚類的輸入是一組未被標記的樣本,聚類根據數據自身的距離或相似度劃分為若干組,劃分的原則是組內距離最小化而組間距離最大化,如下圖所示:
常見的聚類分析算法如下:
K-Means: K-均值聚類也稱為快速聚類法,在最小化誤差函數的基礎上將數據劃分為預定的類數K。該算法原理簡單并便于處理大量數據。
K-中心點:K-均值算法對孤立點的敏感性,K-中心點算法不采用簇中對象的平均值作為簇中心,而選用簇中離平均值最近的對象作為簇中心。
系統聚類:也稱為層次聚類,分類的單位由高到低呈樹形結構,且所處的位置越低,其所包含的對象就越少,但這些對象間的共同特征越多。該聚類方法只適合在小數據量的時候使用,數據量大的時候速度會非常慢。
基本概念梳理
監督學習:分類成為監督學習(supervised learning),因為給定了類標號的信息,即學習算法是監督的,因為它被告知每個訓練元素的 類隸屬關系。
無監督學習(unsupervised learning):因為沒有提供類標號信息。
數據挖掘對聚類的典型要求如下:可伸縮性、處理不同屬性類的能力、發現任意形狀的簇、處理噪聲數據的能力、簇的分離性
基本聚類方法描述:
1.劃分方法:(這是聚類分析最簡單最基本的方法)采取互斥簇的劃分,即每個對象必須恰好屬于一個組。劃分方法是基于距離的,給定要構建的分區數k,劃分方法首先創建一個初始劃分,然后它采用一種迭代的重定位技術,通過把對象從一個組移動到另一個組來改進劃分。一個好的劃分準則是:同一個簇中的相關對象盡可能相互“接近”或相關,而不同簇中的對象盡可能地“遠離”或不同。(什么是啟發式方法?啟發式方法指人在解決問題時所采取的一種根據經驗規則進行發現的方法。其特點是在解決問題時,利用過去的經驗,選擇已經行之有效的方法,而不是系統地、以確定的步驟去尋求答案。 如k-均值(k-means)和k-中心點(k-mediods)方法)。
2.層次方法:層次方法創建給定數據對象集的層次分解。層次方法可以分為凝聚和分裂的方法。凝聚的方法,也稱自底向上的方法,開始將每個對象作為單獨的一組,然后逐次合并相近的對象或組,直到所有的組合并成為一個組。分裂的方法,也成為自頂向下的方法,開始將所有的對象置于一個簇中,在每次的迭代中,一個簇被劃分為更小的簇,直到每個最終每個對象在單獨的一個簇中。
3.基于密度的方法:大部分劃分方法基于對象之間的距離進行聚類,這樣的方法只能發現球狀簇,而在發現任意形狀簇時遇到了困難。已經開發的基于密度的聚類方法,其主要思想是:只要“鄰域”中的密度(對象或數據點的數目)超過了某個閾值(用戶自定義),就繼續增長給定的簇。
4.基于網格的方法:把對象空間量化為有限個單元,形成一個網格結構。所有的聚類操作都在這個網格上進行。這種方法的主要優點是處理速度快。
劃分方法:
k-均值方法是怎樣工作的:k-均值方法把簇的形心定義為簇內點的均值。流程如下:在D中隨機的選擇k個對象,每個對象代表一個簇的初始均值或中心。對剩下的每個對象,根據其各個簇中心的歐氏距離,將它分配到最相似的簇。然后該算法迭代的改善簇內變差。對于每個簇,它使用上次迭代分配到該簇的對象,計算新的均值。然后使用更新后的均值作為新的簇中心,重新分配所有對象。這個過程被稱為迭代的重定位(iterative relocation)。 缺點:對利群點比較敏感。
k-均值算法流程:
1.從數據集D中選擇k個對象作為初始簇的中心
2.根據簇中對象的均值,將每個對象分配到最相似的簇。然后更新簇的均值,也就是重新計算每個簇的對象的均值。直到簇中的均值不再發生變化時算法結束
k-中心點算法對k-均值方法的優化:為了降低k-均值算法對離群點的敏感性,研究了k-中心點方法。我們可以不采用簇中對象的均值作為參考點,而是使用實際對象來代表簇,每個簇使用一個代表對象。其余每個對象被分配到與其最為相似的代表性對象所在的簇中。
k-中心點算法:從數據集D中隨機選擇k個對象作為初始的代表對象或種子 2.將每個剩余的對象分配到最近的代表對象所代表的簇,并隨機的選擇一個非代表對象o并計算用o代替代表對象oj的總代價S,如果S《0,則o替換oj,形成新的k個代表對象的集合 3.當簇內的成員不再發生變化時則結束算法。
k-means VS k-mediods:當存在噪聲利群點時,k-中心點方法比k-均值方法更棒,這是因為中心點不像均值那樣容易受到利群點或其他極端值的影響。然而k-中心點每次迭代的復雜度是O(k(n-k)^2) 。當n合k比較大時,這種計算開銷變得相當大,遠高于k-均值方法。
基于密度的方法:
DBSCAN(一重基于高密度連通區域的基于密度的聚類):該算法找出核心對象,也就是其鄰域稠密的對象。它連接核心對象和它們的鄰域,形成稠密區域作為簇。
DBSCAN如何確定對象的鄰域?:用戶先指定一個參數e》0用來指定每個對象的鄰域半徑。對象o的e-鄰域是以o為中心、以e為半徑的空間。
DBSCAN算法流程:
1.首先標記所有的對象為“未探索”
2.然后隨機選擇一個為探索的對象p并標記為“已探索”
3.如果p的e-鄰域至少有MinPts(鄰域密度閾值)個對象,則創建一個新的簇C,并把p添加到C中,并把它們記作N,遍歷N中的每個成員p‘,如果p’的鄰域也至少有MinPts個對象則保留,否則把p‘從N中刪除。
4.否則標記p為噪聲 5.直到把所有的對象都遍歷完為止
-
聚類分析
+關注
關注
0文章
16瀏覽量
7424
發布評論請先 登錄
相關推薦
RAM技術的基本概念
STM32的中斷系統基本概念
spss聚類分析樹狀圖
FPGA設計中時序分析的基本概念

介紹時序分析基本概念MMMC





 工商網監
工商網監
評論