") 降低時(shí)鐘樹功耗
降低時(shí)鐘樹功耗
雖然對(duì)系統(tǒng)級(jí)芯片開發(fā)人員來說電源管理的重要性越來越高,但有個(gè)關(guān)鍵區(qū)域經(jīng)常被忽視,那就是互連。雖然大多數(shù)電源管理工作集中于SoC的運(yùn)算部分,但采用更加模塊化互連的設(shè)計(jì)師可以減小裸片尺寸、減輕布線擁塞,這就可以將總的芯片功耗最多降低達(dá)0.7mw。如此顯著的功耗下降將成為下一代移動(dòng)和功耗敏感性數(shù)據(jù)中心應(yīng)用系統(tǒng)中的游戲規(guī)則改變者。
模塊化概念有別于其它類型的互連,因?yàn)樗煞植际郊軜?gòu)的開關(guān)、緩沖器、防 火 墻、管線結(jié)構(gòu)以及時(shí)鐘和電源域交叉組成。通過在芯片上的所有獨(dú)立單元之間使用通用傳輸協(xié)議,模塊化方法可以幫助設(shè)計(jì)師實(shí)現(xiàn)單元級(jí)時(shí)鐘選通,從而消除沒有事務(wù)處理區(qū)域的時(shí)鐘樹開關(guān)功耗。
模塊化片上網(wǎng)絡(luò)級(jí)芯片(NoC)技術(shù)還能通過邏輯局部化、盡量縮短長的走線并保持低電容來降低功耗。想要進(jìn)一步增強(qiáng)SoC設(shè)計(jì)的電源管理能力的設(shè)計(jì)師可以采取一定的措施減小芯片的面積和泄漏功耗,方法是使用NoC傳輸協(xié)議的簡易性實(shí)現(xiàn)數(shù)據(jù)路徑的串行化,進(jìn)而最大程度地減少邏輯用量。
低功耗
目前常用的頂層互連結(jié)構(gòu)一般都要依賴于較長的走線,而這些走線會(huì)消耗與它們?cè)谛酒险加玫倪壿媴^(qū)域面積不成比例的功耗。時(shí)鐘樹通常是互連內(nèi)最大的功耗源,而時(shí)鐘選通提供了降低功耗的最大潛力。另外,漏電功耗是第二大功耗源,減小這種結(jié)構(gòu)所需的邏輯面積可以最大限度地減小漏電功耗。
采用模塊化NoC互連的設(shè)計(jì)師可以從本文中了解到時(shí)鐘樹管理的局部化、數(shù)據(jù)路徑的串行化和精確定位的管線結(jié)構(gòu)所帶來的功耗和面積方面的好處。
總線和交叉矩陣:互連歷史簡介
了解互連結(jié)構(gòu)的歷史就能知道模塊化NoC設(shè)計(jì)的由來了,它能解決可擴(kuò)展性問題。
SoC是一種含CPU和外設(shè)的芯片,開發(fā)人員提出的接口協(xié)議標(biāo)準(zhǔn)可以將各單元鏈接在一起。借助新增總線主器件的推出,到外設(shè)的連接可以得到共享。控制對(duì)總線的訪問要求一個(gè)中央仲裁器,比如在板級(jí)協(xié)議中使用的仲裁器。
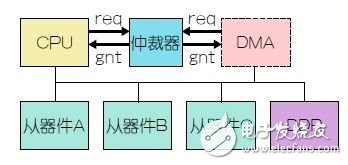
圖1:帶仲裁器的共享型總線展示了訪問控制為何要使用中央仲裁器。
隨著時(shí)間的推移,SoC設(shè)計(jì)增加了越來越多的IP內(nèi)核。由于這些設(shè)計(jì)變得越來越復(fù)雜,他們要求更多的總線接口。當(dāng)對(duì)接口進(jìn)行密集操作時(shí),總線主器件可能會(huì)浪費(fèi)很多時(shí)間等待對(duì)總線的訪問權(quán),即使在不同的主器件請(qǐng)求操作不同的從器件時(shí),也是如此。
為了解決等待延時(shí)問題,交叉矩陣開關(guān)應(yīng)運(yùn)而生,它們支持在片上互連內(nèi)不同的主和從器件之間開展并行訪問。下面這個(gè)邏輯框圖顯示了4個(gè)主器件同時(shí)對(duì)4個(gè)不同從器件進(jìn)行事務(wù)操作。
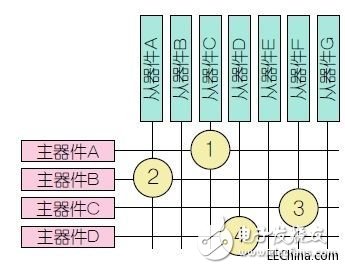
圖2:SoC設(shè)計(jì)中的交叉矩陣開關(guān)邏輯視圖,展示了每個(gè)從器件端復(fù)用器的關(guān)系。
從物理上看,交叉矩陣開關(guān)是用每個(gè)從器件端的復(fù)用器(mux)實(shí)現(xiàn)的。每個(gè)復(fù)用器以分布式仲裁機(jī)制與仲裁器相耦合。
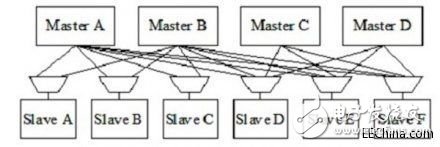
圖3:4個(gè)主器件、6個(gè)從器件的交叉矩陣實(shí)現(xiàn)表明,在SoC周圍采用完整數(shù)據(jù)路徑的尺寸路由是不切實(shí)際的。
這種方法最多只能擴(kuò)展到幾個(gè)主和從器件接口。然而,除了特定數(shù)量外,在SoC周圍路由完整數(shù)據(jù)路徑的尺寸對(duì)布局布線來說也變得不切實(shí)際。
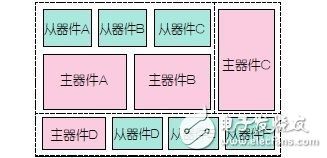
圖4:隨著功能清單的增長和IP模塊的增加,SoC底層規(guī)劃變得更加復(fù)雜。
對(duì)于具有很多個(gè)主/從接口的更加復(fù)雜的芯片來說,有必要在多個(gè)物理區(qū)域設(shè)計(jì)獨(dú)立的互連,具體取決于IP內(nèi)核分組的布局情況。不同區(qū)域之間的橋接提供了主器件和從器件之間必要的互連。
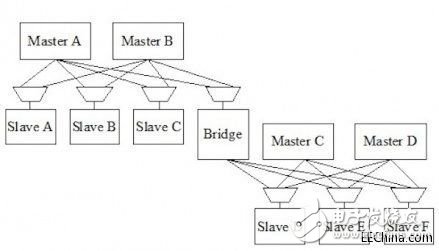
圖5:4個(gè)主器件與6個(gè)從器件的互連,用了一個(gè)橋承載邏輯延時(shí)開銷。
橋會(huì)為數(shù)據(jù)處理的增加延時(shí)周期,因?yàn)樗鼈兂休d了邏輯延時(shí)部分。
交叉矩陣互連可以解決并行訪問帶來的系統(tǒng)架構(gòu)問題,但在有大量主和從IP模塊的情況下,又會(huì)造成芯片中的物理實(shí)現(xiàn)問題。
模塊化設(shè)計(jì)和NoC
為了減小延時(shí),地址可以在主接口側(cè)解碼,并轉(zhuǎn)換為簡單的路由ID號(hào)。片上的仲裁器-復(fù)用器和路由器-解復(fù)用器網(wǎng)絡(luò)可以使用簡單的路由ID,并通過鏈路芯片周圍的簡單偽開關(guān)復(fù)用器擴(kuò)展路由分布。這樣做還能實(shí)現(xiàn)更好的互連邏輯布局。對(duì)于芯片中越來越多的走線來說,布局越來越重要,因?yàn)樗鼤?huì)使路由更加容易。
NoC互連可以同時(shí)解決這兩個(gè)問題,因此在手機(jī)應(yīng)用處理器、數(shù)字電視和機(jī)頂盒控制器等先進(jìn)設(shè)計(jì)中得到了廣泛使用。
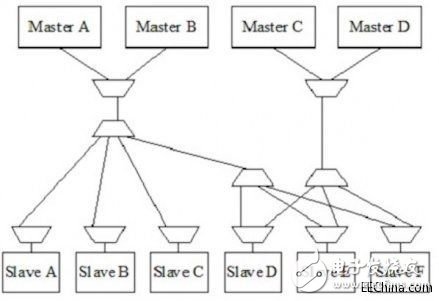
圖6:利用一個(gè)NoC實(shí)現(xiàn)的4個(gè)主器件與6個(gè)從器件的互連。
設(shè)計(jì)師一直被要求在SoC中集成更多的功能,因此對(duì)互連技術(shù)的需求與日俱增。為了跟上形勢,對(duì)以下功能的需求非常迫切:
●到不同事務(wù)處理協(xié)議的接口
●開關(guān)(解復(fù)用-路由器和仲裁器-復(fù)用器)
●QoS(優(yōu)先級(jí))
●緩沖器
●數(shù)據(jù)路徑串行化
●統(tǒng)計(jì)性探測
●調(diào)試跟蹤
●防 火 墻
●寄存器片(管線結(jié)構(gòu))
●時(shí)鐘域交叉
●電壓域
●電源域
這對(duì)互連設(shè)計(jì)提出了新的挑戰(zhàn)。設(shè)計(jì)師希望IP可以重復(fù)使用并且可以重復(fù)配置。而在交叉矩陣邏輯中支持不斷增加的功能要求將會(huì)提高復(fù)雜性,減慢關(guān)鍵路徑速度。另外,許多走線即使在少量數(shù)據(jù)操作時(shí)也會(huì)被觸發(fā),因此消耗了與之不成比例的功耗。然而,可復(fù)用的模塊化互連設(shè)計(jì)在簡便性、速度、面積和功效方面有很大的優(yōu)勢,可克服傳統(tǒng)總線和交叉矩陣技術(shù)的復(fù)雜性。
事務(wù)、傳輸和物理層
NoC技術(shù)采用了一種三層協(xié)議,其中事務(wù)層作為最高層。該技術(shù)使用AMBA、PIF、OCP或其它工業(yè)標(biāo)準(zhǔn)協(xié)議執(zhí)行所要求的讀寫操作,同時(shí)也是對(duì)于通過互連連接的IP模塊的設(shè)計(jì)師來說,也是可見的接口。
NoC中的傳輸層協(xié)議由網(wǎng)絡(luò)接口單元(NIU)進(jìn)行管理。它為每個(gè)事務(wù)創(chuàng)建一個(gè)或多個(gè)數(shù)據(jù)包。所有數(shù)據(jù)包都一個(gè)包頭。讀數(shù)據(jù)包和寫數(shù)據(jù)包都在包頭后包含數(shù)據(jù)載荷。包頭將地址、事務(wù)參數(shù)和邊帶信號(hào)作為域進(jìn)行解碼。NIU控制顯著的事務(wù)和帶標(biāo)簽的序列。包頭格式是最小的,并針對(duì)每個(gè)NoC作了不同程度的優(yōu)化。包頭在互連內(nèi)的每個(gè)偽開關(guān)處將來自發(fā)起者的請(qǐng)求路由到目標(biāo),并將來自目標(biāo)的響應(yīng)路由到發(fā)起者。請(qǐng)求和響應(yīng)路徑是獨(dú)立的,因此可以消除邏輯和架構(gòu)方面的依賴性,從而避免死鎖。
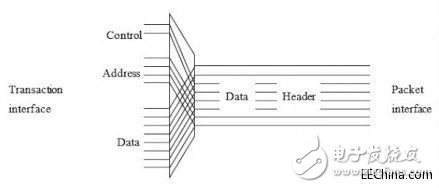
圖7:將地址/控制信號(hào)與事務(wù)接口和包傳輸接口間的數(shù)據(jù)復(fù)用起來可以簡化互連設(shè)計(jì)。
模塊化設(shè)計(jì)支持使用非常簡單的協(xié)議在物理層上傳輸傳送包。這種協(xié)議由以下信號(hào)組成:
●Data [N 位] (由發(fā)送者驅(qū)動(dòng))
●Valid [1 位] (由發(fā)送者驅(qū)動(dòng))
● Ready [1 位] (由接收者驅(qū)動(dòng))
“Valid”和“Ready”實(shí)現(xiàn)流程控制,支持后壓式反饋。這種簡單的握手協(xié)議存在于NoC的所有單元之間。簡單接口標(biāo)準(zhǔn)化后允許所有單元可交換地連接在一起,就像兒童的積木一樣。
時(shí)鐘樹選通
利用眾所周知的芯片設(shè)計(jì)方法,可以在不要求觸發(fā)的周期內(nèi)選通每個(gè)觸發(fā)器端的時(shí)鐘。這種方法適用于采用所有互連技術(shù)的觸發(fā)器,不過不能解決時(shí)鐘樹功耗問題。
時(shí)鐘樹是個(gè)單一信號(hào),因此比數(shù)據(jù)路徑要窄得多。然而,為了到達(dá)所有物理上分布的觸發(fā)器,時(shí)鐘樹比每個(gè)數(shù)據(jù)路徑位有多得多的基本特征。根據(jù)定義,時(shí)鐘在每個(gè)時(shí)鐘周期內(nèi)會(huì)觸發(fā)兩次,因此時(shí)鐘樹的功耗一般要顯著大于數(shù)據(jù)路徑。
在交叉矩陣中,每個(gè)時(shí)鐘網(wǎng)絡(luò)即使在數(shù)據(jù)不流動(dòng)時(shí)也會(huì)觸發(fā)。雖然理論上在交叉矩陣中的任何地方都沒有數(shù)據(jù)傳送時(shí)仍能在周期中實(shí)現(xiàn)到所有交叉矩陣邏輯的時(shí)鐘選通,但有些不切實(shí)際。它要求對(duì)多個(gè)遠(yuǎn)端信號(hào)進(jìn)行大的時(shí)鐘選通復(fù)用,以產(chǎn)生激活信號(hào)并回送至多個(gè)遠(yuǎn)端觸發(fā)器。
因此,用組合邏輯的最簡模塊搭建互連可以實(shí)現(xiàn)單元級(jí)時(shí)鐘選通功能,并且其顆粒遠(yuǎn)比單片交叉矩陣中的精細(xì)得多。
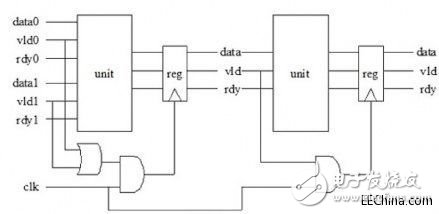
圖8:通過模塊化方法搭建互連就可以使用組合邏輯的單元級(jí)時(shí)鐘選通功能。
只有在有效的握手信號(hào)有效時(shí)單元內(nèi)和單元間的寄存器才會(huì)觸發(fā),用于指示數(shù)據(jù)業(yè)務(wù)的存在。選通邏輯對(duì)每個(gè)單元來說是局部的,因此路徑更短,并且最大限度地減少了產(chǎn)生激活信號(hào)所需的復(fù)用電路。時(shí)鐘選通是分布式的,模塊化互連的每個(gè)模塊在空閑時(shí)鐘周期時(shí)關(guān)閉,而不管系統(tǒng)余下部分的狀態(tài)。這樣可以實(shí)現(xiàn)接近理想的最小開關(guān)功耗。
模塊化的其它好處
除了時(shí)鐘選通外,其它好處包括改進(jìn)了混合式閾值電壓(Vt)綜合的使用、減少了漏電功耗、改善了邏輯簡易性,并實(shí)現(xiàn)了局部化。
在小模塊之間的任何地方插入管線結(jié)構(gòu)以滿足最小延時(shí)時(shí)序要求提高了綜合工具收斂時(shí)序的能力。由于有更大的余量,綜合有效減少了從默認(rèn)高Vt單元到更快的低Vt單元的路徑數(shù)量。這樣,模塊化設(shè)計(jì)單元之間的管線結(jié)構(gòu)就能減少漏電功耗。另外,更容易的時(shí)序收斂也能改善EDA工具的使用,有助于實(shí)現(xiàn)最小面積方面的最優(yōu)化(更小的裸片面積可減少漏電功耗)。
64位AXI事務(wù)接口協(xié)議要求至少272條走線。對(duì)于模塊化方法來說,一個(gè)64位數(shù)據(jù)包接口要求148條線(每個(gè)請(qǐng)求響應(yīng)網(wǎng)絡(luò)中有64位數(shù)據(jù)+8字節(jié)激活+ready+valid=74)。因此,將事務(wù)打包并在發(fā)起者和目標(biāo)傳輸時(shí)可以將芯片底層規(guī)劃內(nèi)的走線數(shù)量減少1.8倍(272/148=1.8)。
因?yàn)檫@種方法針對(duì)單元之間的接口使用的是簡單物理層協(xié)議,所以很容易改變包數(shù)據(jù)的串行化處理。全部要求就是簡單的復(fù)用器和寄存器,以便減小數(shù)據(jù)路徑寬度。
改變數(shù)據(jù)路徑的串行化處理方式,使之不超過滿足芯片不同部分的帶寬要求所需的寬度,可以減少芯片所有部分的互連邏輯面積,而且這些芯片都要求小于最大帶寬。一般來說,大多數(shù)芯片中的絕大部分頂層互連不要求最大帶寬。
局部化
將接口之間的復(fù)用器等單元實(shí)現(xiàn)局部化處理后,單元之間的走線平均長度將變短。這意味著走線電容使得電流的消耗變得更小。這樣還能簡化后端版圖工藝,因?yàn)樗軠p少遠(yuǎn)距離放置的邏輯之間對(duì)連接的依賴性。
機(jī)頂盒(STB)SoC上的結(jié)果
支持1080p120幀的中端機(jī)頂盒SoC就使用了模塊化NoC互連,它展示了模塊化方法的優(yōu)勢。這種模型使用了11個(gè)主器件和6個(gè)從NIU的互連,消耗的邏輯面積是183k個(gè)門。
我們分析了三種時(shí)鐘選通式開關(guān)活動(dòng)場景。首先是最差的視頻處理場景,其中被設(shè)為120Hz顯示輸出的視頻解碼器和CPU是系統(tǒng)的主要負(fù)載,它們消耗了幾乎所有可用的DDR內(nèi)存帶寬。
第二種場景則呈現(xiàn)了普通案例視頻解碼器的復(fù)雜性。第三種場景沒有視頻解碼,只是用網(wǎng)絡(luò)瀏覽方式,可實(shí)現(xiàn)每秒30幀的中等顯示刷新率。
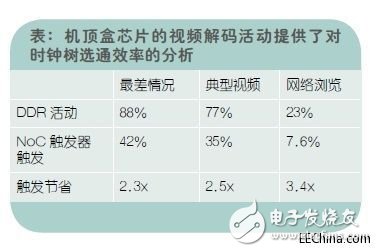
交叉矩陣在DDR活動(dòng)期間的每個(gè)周期都必須要激活,因此在第一種情況下模塊化設(shè)計(jì)通過觸發(fā)DDR活動(dòng)可以降低2.3倍的功耗,第二種情況是2.5倍,第三種情況是3.4倍。
在待機(jī)場景,模塊化NoC互連展示了比交叉矩陣更強(qiáng)的觸發(fā)節(jié)省效果。另外,更大的芯片有更多的主NIU邏輯要訪問同樣受限的共享資源。這些芯片需要用更大比例的時(shí)間選通更多數(shù)量的觸發(fā)器。因此對(duì)模塊化NoC設(shè)計(jì)來說觸發(fā)節(jié)省效果隨著芯片尺寸的增加而增強(qiáng)。
減少時(shí)鐘樹功耗
模塊化NoC可以極大地降低高集成度芯片中頂層互連結(jié)構(gòu)的功耗。通過局部化時(shí)鐘選通功能,時(shí)鐘樹只在數(shù)據(jù)傳送的路線上并且只在傳送周期內(nèi)有功耗。這樣可以顯著降低時(shí)鐘樹的功耗。另外,局部的串行化處理從最大程度地減少了支持每條鏈路的帶寬要求所需的數(shù)據(jù)路徑邏輯。這又進(jìn)一步減小了漏電面積。另外,模塊化支持更加精細(xì)的管線顆粒,可以更好地收斂時(shí)序且不浪費(fèi)余量。這又進(jìn)一步允許綜合工具使用更小、更加高效的門。
-
SoC設(shè)計(jì)
+關(guān)注
關(guān)注
1文章
148瀏覽量
18792 -
NoC
+關(guān)注
關(guān)注
0文章
38瀏覽量
11740
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
時(shí)鐘樹優(yōu)化與有用時(shí)鐘延遲
射頻識(shí)別芯片設(shè)計(jì)中時(shí)鐘樹功耗的優(yōu)化與實(shí)現(xiàn)
一文讀懂時(shí)鐘樹
前后端協(xié)同的時(shí)鐘樹設(shè)計(jì)方法
時(shí)鐘網(wǎng)格與時(shí)鐘樹設(shè)計(jì)方法對(duì)比研究
基于CCopt引擎的SMIC40nm低功耗工藝CortexA9的時(shí)鐘樹實(shí)現(xiàn)

射頻識(shí)別芯片設(shè)計(jì)的時(shí)鐘樹功耗實(shí)戰(zhàn)
什么是門控時(shí)鐘 門控時(shí)鐘降低功耗的原理
STM32F10X-時(shí)鐘樹詳細(xì)介紹

STM32時(shí)鐘樹
評(píng)價(jià)時(shí)鐘樹質(zhì)量的方法
時(shí)鐘樹綜合CTS階段如何去降低Latency和Skew





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論