") 服務(wù)器數(shù)據(jù)恢復(fù)—linux操作系統(tǒng)下oracle數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例
服務(wù)器數(shù)據(jù)恢復(fù)—linux操作系統(tǒng)下oracle數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例
服務(wù)器存儲數(shù)據(jù)恢復(fù)環(huán)境&故障:
一臺存儲上有一組由16塊FC硬盤組建了一組raid。存儲前面板上的對應(yīng)10號和13號硬盤的故障燈亮起,存儲映射到redhat linux操作系統(tǒng)服務(wù)器上的卷掛載不上,業(yè)務(wù)中斷。
服務(wù)器存儲數(shù)據(jù)恢復(fù)過程:
1、通過存儲的管理后臺查看當(dāng)前存儲狀態(tài),管理后臺報告邏輯卷狀態(tài)失敗。再查看物理磁盤狀態(tài),發(fā)現(xiàn)6號盤狀態(tài)“警告”,10號和13號盤狀態(tài)“失敗”。在管理后臺將當(dāng)前存儲的完整日志狀態(tài)備份。解析日志獲取到關(guān)于邏輯卷結(jié)構(gòu)的部分信息。

北亞企安數(shù)據(jù)恢復(fù)—服務(wù)器數(shù)據(jù)恢復(fù)
2、將16塊FC盤做好標(biāo)記后從存儲中移除,使用專用工具對16塊FC盤進(jìn)行初步檢測, 發(fā)現(xiàn)16塊盤均能正常識別。檢測所有磁盤的SMART狀態(tài),發(fā)現(xiàn)6號盤的SMART狀態(tài)為“警告”,和在存儲管理后臺中的報告一致。
3、將所有磁盤以只讀方式進(jìn)行扇區(qū)級別的全盤鏡像。在鏡像過程中發(fā)現(xiàn)6號磁盤的鏡像速度很慢,結(jié)合之前的檢測結(jié)果綜合判斷,6號盤應(yīng)該存在大量損壞和不穩(wěn)定的扇區(qū)。
4、使用專業(yè)設(shè)備對6號硬盤進(jìn)行鏡像,在鏡像的同時觀察鏡像的速度和穩(wěn)定性。經(jīng)過觀察發(fā)現(xiàn)6號盤的壞道并不多,但是存在大量讀取響應(yīng)時間長的不穩(wěn)定扇區(qū)。調(diào)整6號盤的鏡像策略后繼續(xù)對6號盤進(jìn)行鏡像操作,同時觀察鏡像情況。6號盤鏡像完成,但是之前的鏡像策略會自動跳過一些不穩(wěn)定扇區(qū),所以現(xiàn)在的鏡像是不完整的。調(diào)整鏡像策略,繼續(xù)鏡像被跳過的扇區(qū),直到6號盤所有扇區(qū)全部鏡像完畢。
5、全部磁盤做完鏡像后查看日志,發(fā)現(xiàn)在管理后臺和SMART狀態(tài)中均無報錯的1號盤也存在壞道,10號和13號盤也存在大量不規(guī)則壞道。定位到目標(biāo)鏡像文件并經(jīng)過分析,發(fā)現(xiàn)ext3文件系統(tǒng)的部分關(guān)鍵源數(shù)據(jù)信息已經(jīng)被壞道破壞。只能利用6號盤通過同一條帶進(jìn)行xor,并根據(jù)文件系統(tǒng)上下文關(guān)系手動修復(fù)被損壞的文件系統(tǒng)。
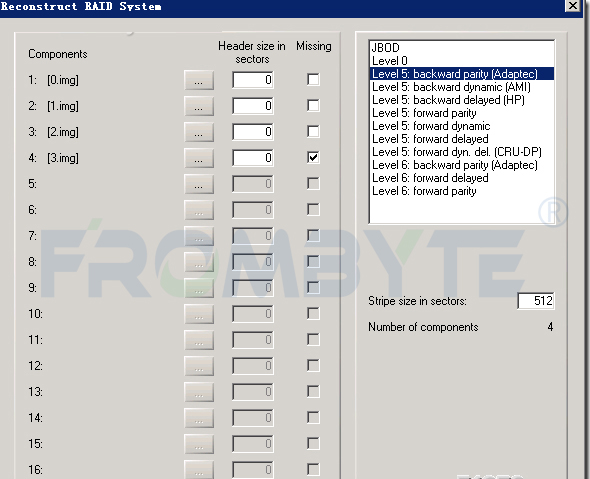
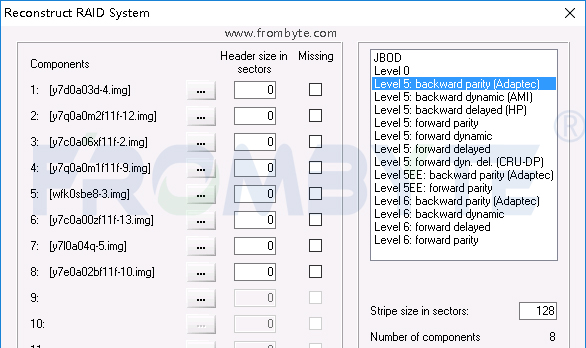
6、將所有鏡像文件全部展開。根據(jù)北亞企安數(shù)據(jù)恢復(fù)工程師對ext3文件系統(tǒng)的逆向研究和對日志文件的分析,獲取到16塊FC盤在存儲中的盤序、RAID塊大小、RAID的校驗走向和方式等信息。根據(jù)上述獲取到的信息虛擬重組RAID,RAID重組完成后進(jìn)一步解析ext3文件系統(tǒng)。和用戶后溝通提取出一些oracle的dmp文件并嘗試進(jìn)行恢復(fù)。
7、在使用dmp文件進(jìn)行恢復(fù)的過程中,數(shù)據(jù)庫報告imp-0008錯誤。仔細(xì)分析導(dǎo)入dmp文件的日志文件,發(fā)現(xiàn)恢復(fù)的dmp文件有問題。重新分析raid結(jié)構(gòu),并進(jìn)一步確定ext3文件系統(tǒng)被破壞的程度,重新恢復(fù)出dmp文件和dbf原始庫文件。將恢復(fù)出來的dmp文件移交給用戶進(jìn)行數(shù)據(jù)導(dǎo)入測試,測試過程一切順利沒有發(fā)現(xiàn)問題。對恢復(fù)出來的dbf原始庫文件進(jìn)行校驗檢測,所有文件均通過測試。
8、拷貝數(shù)據(jù)庫文件到原數(shù)據(jù)庫服務(wù)器作為備份,路徑為/home/oracle/tmp/syntong。在根目錄下創(chuàng)建了oradata文件夾,并把備份的syntong文件夾拷貝到oradata目錄下。更改oradata文件夾及其所有文件的屬組和權(quán)限。備份原數(shù)據(jù)庫環(huán)境,包括ORACLE_HOME下product文件夾下的相關(guān)文件。
9、配置監(jiān)聽,使用原機中的splplus連接到數(shù)據(jù)庫。嘗試啟動數(shù)據(jù)庫到nomount狀態(tài),狀態(tài)查詢發(fā)現(xiàn)環(huán)境和參數(shù)文件正常。 嘗試啟動數(shù)據(jù)庫到mount狀態(tài),狀態(tài)查詢也沒有問題。啟動數(shù)據(jù)庫到open狀態(tài),出現(xiàn)報錯。

北亞企安數(shù)據(jù)恢復(fù)—服務(wù)器數(shù)據(jù)恢復(fù)
10、經(jīng)過檢測和分析,北亞企安數(shù)據(jù)恢復(fù)工程師判斷此故障原因是控制文件和數(shù)據(jù)文件信息不一致,這是一類由于異常斷電或突然關(guān)機引起的常見故障。
11、逐個檢測數(shù)據(jù)庫文件,沒有發(fā)現(xiàn)物理損毀。
12、在mount狀態(tài)下,備份控制文件。查看修改備份的控制文件,取得其中的重建控制文件命令。把命令復(fù)制到一個新建腳本文件controlfile.sql中。
13、關(guān)閉數(shù)據(jù)庫,刪除/oradata/syntong/下的3個控制文件。 啟動數(shù)據(jù)庫到nomount狀態(tài),執(zhí)行controlfile.sql腳本。

北亞企安數(shù)據(jù)恢復(fù)—服務(wù)器數(shù)據(jù)恢復(fù)
14、重建控制文件完成后,直接啟動數(shù)據(jù)庫,仍然報錯,需要進(jìn)一步處理。

北亞企安數(shù)據(jù)恢復(fù)—服務(wù)器數(shù)據(jù)恢復(fù)
執(zhí)行恢復(fù)命令:

北亞企安數(shù)據(jù)恢復(fù)—服務(wù)器數(shù)據(jù)恢復(fù)
做介質(zhì)恢復(fù),直到返回報告。
15、嘗試open數(shù)據(jù)庫。
SQL>alter database open resetlogs;
16、數(shù)據(jù)庫啟動成功。把原來temp表空間的數(shù)據(jù)文件加入到對應(yīng)的temp表空間中。
17、對數(shù)據(jù)庫進(jìn)行各種常規(guī)檢查,沒有任何錯誤。
18、進(jìn)行emp備份。全庫備份完成,沒有報錯。
19、將應(yīng)用程序連接到數(shù)據(jù)庫,在應(yīng)用層面驗證數(shù)據(jù)。
20、經(jīng)過驗證,用戶方確認(rèn)數(shù)據(jù)完整有效,認(rèn)可數(shù)據(jù)恢復(fù)結(jié)果。
審核編輯 黃宇
-
Linux
+關(guān)注
關(guān)注
87文章
11339瀏覽量
210120 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9293瀏覽量
85851 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6882瀏覽量
123585 -
數(shù)據(jù)恢復(fù)
+關(guān)注
關(guān)注
10文章
585瀏覽量
17580
發(fā)布評論請先 登錄
相關(guān)推薦
服務(wù)器數(shù)據(jù)恢復(fù)—raid5陣列上層win系統(tǒng)+oracle數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例
SqlServer數(shù)據(jù)恢復(fù)—SqlServer數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例
服務(wù)器數(shù)據(jù)恢復(fù)—光纖存儲硬盤故障燈亮起的數(shù)據(jù)恢復(fù)案例

數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—Oracle ASM實例無法掛載的數(shù)據(jù)恢復(fù)案例
服務(wù)器數(shù)據(jù)恢復(fù)—Linux網(wǎng)站服務(wù)器硬盤出現(xiàn)壞扇區(qū)的數(shù)據(jù)恢復(fù)案例
Oracle數(shù)據(jù)恢復(fù)—異常斷電后Oracle數(shù)據(jù)庫啟庫報錯的數(shù)據(jù)恢復(fù)案例
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—Oracle數(shù)據(jù)庫文件system01.dbf損壞的數(shù)據(jù)恢復(fù)案例
Oracle數(shù)據(jù)恢復(fù)—Oracle數(shù)據(jù)庫delete刪除的數(shù)據(jù)恢復(fù)方法
Oracle數(shù)據(jù)恢復(fù)—Oracle刪除數(shù)據(jù)不用怕!這些數(shù)據(jù)恢復(fù)方法了解一下
服務(wù)器數(shù)據(jù)恢復(fù)—RAID5多塊磁盤掉線導(dǎo)致崩潰的數(shù)據(jù)恢復(fù)案例
服務(wù)器數(shù)據(jù)恢復(fù)—KVM虛擬機raw格式磁盤文件數(shù)據(jù)恢復(fù)案例
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—raid5陣列上層Sql Server數(shù)據(jù)庫數(shù)據(jù)恢復(fù)案例

MongoDB數(shù)據(jù)恢復(fù)—MongoDB數(shù)據(jù)庫文件損壞的數(shù)據(jù)恢復(fù)案例
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—Sql Server數(shù)據(jù)庫文件丟失的數(shù)據(jù)恢復(fù)案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論