 算法與數據結構——迭代器模式
算法與數據結構——迭代器模式
周立功教授數年之心血之作《程序設計與數據結構》以及《面向AMetal框架與接口的編程(上)》,書本內容公開后,在電子行業掀起一片學習熱潮。經周立功教授授權,本公眾號特對《程序設計與數據結構》一書內容進行連載,愿共勉之。
第三章為算法與數據結構,本文為3.4 迭代器模式。
>>> 3.4.1 迭代器與容器
在初始化數組中的元素時,通常使用下面這樣的for循環語句遍歷數組:

這段代碼中的循環變量i,該變量的初始值為0,然后遞增為1、2、3、...,程序在每次i遞增后都將值賦給a[i]。數組中保存了許多元素,通過指定數組下標,即可從中選擇任意一個元素。for語句中的i++的作用是讓i的值在每次循環后自增1,這樣就可以訪問數組中的下一個元素,從而實現了從頭到尾逐一遍歷數組元素的功能。
由此可見,常用的循環結構就是一種迭代操作,在每一次迭代操作中,對迭代器的修改即等價于修改循環控制的標志或計數器。而容器是一種保存值的集合的數據結構,C有兩種內建的容器:數組和結構體。雖然C沒有提供更多的容器,但用戶可以按需編寫自己的容器,比如,鏈表、哈希表等。
將i的作用抽象化、通用化后形成的模式,在設計模式中i稱為迭代器(Iterator)模式,Iterate的字面意思是重復、反復聲明,其實就是重復做某件事,Iterator模式用于遍歷數組中的元素。迭代器的基本思想是迭代器變量存儲了容器的某個元素的位置,因此能夠遍歷該位置的元素。通過迭代器提供的方法,可以繼續遍歷容器的下一個元素。
顯而易見,迭代器是一種抽象的設計概念,因為在程序設計語言中并沒有直接對應于這個概念的實物。《設計模式》一書提供了23種設計模式的完整描述,其中iterator模式的定義為:在遍歷一個容器對象時,提供一種方法順序訪問一個容器對象中的各個元素,而又不暴露該對象的內部表示方式。其中心思想是將數據容器和算法分開且彼此獨立,最后再用黏合劑將它們撮合在一起。
>>> 3.4.2 迭代器接口
為什么一定要考慮引入Iterator這種復雜的設計模式呢?如果是數組,直接使用for循環語句進行遍歷處理不就可以了嗎?為什么要在集合之外引入Iterator這個角色呢?一個重要的理由是,引入Iterator后可以將遍歷與實現分離。
實際上無論是單向鏈表還是雙向鏈表,其查找算法與遍歷算法的實現沒有多少差別,基本上都是重復勞動。如果代碼中有bug,則需要修改所有相關的代碼。為什么會出現這樣的情況呢?主要是接口設計不合理所造成的,其最大的問題就是將容器和算法放在了一起,且算法的實現又依賴于容器的實現,因而必須為每一個容器開發一套與之匹配的算法。
假設要在2種容器(雙向鏈表、動態數組)中分別實現6種算法(交換、排序、求最大值、求最小值、遍歷、查找),顯然需要2×6=12個接口函數才能實現目標。隨著算法數量的不斷增多,勢必導致函數的數量成倍增加,重復勞動的工作量也越大。如果將容器和算法單獨設計,則只需要實現6個算法函數就行了。即算法不依賴容器的特定實現,算法不會直接在容器中進行操作。比如,排序算法無需關心元素是存放在數組或線性表中。
在正式引入迭代器之前,不妨分析一下如程序清單 3.49所示的冒泡排序算法。
程序清單 3.49 冒泡排序算法

如果任何一次遍歷沒有執行任何交換,則說明記錄是有序的且終止排序。其中,p1指向數組的首元素,pNext指向p1所指向的元素的下一個元素,p2指向數組的尾元素(圖 3.21(a))。

圖 3.21 內部循環執行過程示意圖
如果*p1>*pNext,則交換指針所指向的內容,p1與pNext后移(圖 3.21(b)),反之指針所指向的內容不變,p1與pNext后移,經過一輪排序之后,直到p1 = p2為止,最大元素移到數組尾部。
當最大元素移到數組的尾部時,則退出內部循環。p2前移后程序跳轉到程序清單 3.49(15),p1再次指向數組的首元素,pNext指向p1所指向的元素的下一個元素(圖 3.22(a))。此時,圖 3.22(a)與圖 3.21(a)的差別在于p2指向a[3]。經過一輪循環之后,直到p1 = p2,此時整數4移到a[3]所在的位置,剩余的排序詳見圖 3.22。當p1與p2重合在數組首元素所在的位置時,表示排序結束(圖 3.22(d))。

圖 3.22 外部循環執行過程示意圖
由此可見,冒泡排序算法的核心是指針的操作,其主要行為如下:
-
比較指針所指向的值的大小;
-
交換指針所指向的內容;
-
指針后移,即指針指向下一個元素;
-
指針前移,即指針指向前面一個元素。
由于這里是以int類型數據為例實現冒泡排序的,因此用戶知道如何比較數據和如何交換指針所指向的內容,以及指針的前后移動。當使用支持任意類型數據的void *時,雖然算法程序不知道傳入什么類型的數據,但調用者知道,因此在調用排序算法函數時,可以由用戶傳遞參數通過回調函數實現。修改后的冒泡排序函數原型如下:

其中,compare用于比較兩個指針所指向的值的大小,compare_t類型定義如下:

swap函數用于交換兩個指針指向的內容,swap_t類型定義如下:

顯然無法通過++或--移動指針,因為不知道傳入的是什么類型的數據。如果知道數據占用4個字節,則可以通過指針的值加4或減4實現指針的移動。雖然使用這種方式可以實現指針的移動,但始終要求數據必須以數組的形式存儲,一旦離開了這個特定的容器,則無法確定指針的行為。如果將算法與鏈表結合起來使用,顯然代碼中的p1++和p2--不適合鏈表。
基于此,“不妨對指針進行抽象,讓它針對不同的容器有不同的實現,而算法只關心它的指針接口”。顯然,需要容器提供相應的接口函數,才能實現指針前移和后移,通常將這樣的指針稱為“迭代器”。從某種意義上來說,迭代器作為算法的接口是廣義指針,而指針滿足所有迭代器的要求。其優勢在于對任何種類的容器都可以用同樣的方法順序遍歷容器中的元素,而又不暴露容器的內部細節,迭代器接口的聲明詳見程序清單3.50。
程序清單3.50 迭代器接口的聲明

其中,p_iter指向的內容是由容器決定的,它既可以指向結點,也可以指向數據。無論是鏈表還是其它容器實現的pfn_next函數,其意義是一樣的,其它函數同理。如果將迭代器理解為指向數據的指針變量,則pfn_next函數讓迭代器指向容器的下一個數據,pfn_prev函數讓迭代器指向容器的上一個數據。
此時,應該針對接口編寫一些獲取或設置數值的方法。用于讀取變量的方法通常稱為“獲取方法(getter)”,用于寫入變量的方法通常稱為“設置方法(setter)”。下面以雙向鏈表為例,使用結構體指針作為dlist_iterator_if_get()的返回值,詳見程序清單3.51。
程序清單3.51 獲取雙向鏈表的迭代器接口(1)

其調用形式如下:

注意,如果省略static,則iterator_if就成了一個局部變量。由于它將在函數執行完后失效,因此返回它的地址毫無意義。這里采用了直接訪問結構體成員的方式對iterator_if_t類型的結構體賦值,顯然不同模塊之間應該盡可能避免這種方式,取而代之的是提供相應的接口,詳見程序清單 3.52。
程序清單 3.52 獲取雙向鏈表的迭代器接口(2)

其調用形式如下:
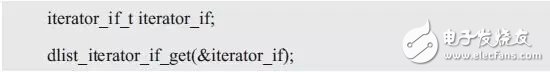
由于iterator_if_t類型的結構體中只有兩個函數指針,因此對函數指針的訪問僅包含設置和調用,詳見程序清單 3.53。
程序清單 3.53 迭代器接口(iterator.h)

這些函數的具體實現詳見程序清單3.54。
程序清單3.54 迭代器接口的實現

現在可以直接調用iterator_if_init()實現dlist_iterator_if_get(),詳見程序清單 3.55。
程序清單 3.55 獲取雙向鏈表的迭代器接口(3)

>>>3.4.3 算法的接口
由于使用迭代器可以輕松地實現指針的前移或后移,因此可以使用迭代器接口實現冒泡排序算法。其函數原型為:

其中,p_if表示算法使用的迭代器接口。begin與end是一對迭代器,表示算法的操作范圍,但不一定是容器的首尾迭代器,因此算法可以處理任何范圍的數據。為了判定范圍的有效性,習慣采用前閉后開范圍表示法,即使用begin和end表示的范圍為[begin,end),表示范圍涵蓋bigen到end(不含end)之間的所有元素。當begin==end時,上述所表現的便是一個空范圍。
compare同樣也是比較函數,但比較的類型發生了變化,用于比較兩個迭代器所對應的值。其類型compare_t定義如下:
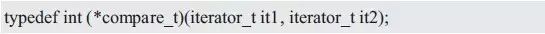
swap函數用于交換兩個迭代器所對應的數據,其類型swap_t定義如下:

由此可見,接口中只有迭代器,根本沒有容器的蹤影,從而做到了容器與冒泡排序算法徹底分離,基于迭代器的冒泡排序算法詳見程序清單3.56。
程序清單3.56 冒泡排序算法函數

下面以一個簡單的例子來測試驗證基于迭代器的冒泡排序算法,詳見程序清單3.57。將整數存放到雙向鏈表中,首先將5、4、3、2、1分別加在鏈表的尾部,接著調用dlist_foreach()遍歷鏈表,看是否符合預期,然后再調用算法庫的iter_sort()排序。當排序完畢后鏈表的元素應該是從小到大排列的,再次調用算法庫的dilst_foreach()遍歷鏈表,看是否符合預期。
程序清單3.57 使用雙向鏈表、算法和迭代器

在這里,使用了dlist_foreach()遍歷函數,既然通過迭代器能夠實現冒泡排序,那么也能通過迭代器實現簡單的遍歷算法,此時遍歷算法與具體容器無關。遍歷函數的原型如下:
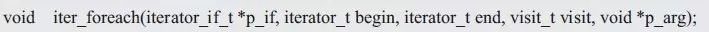
其中,p_if表示算法使用的迭代器接口,begin與end表示算法需要處理的迭代器范圍,visit是用戶自定義的遍歷迭代器的函數。其類型visit_t定義如下:

visit_t的參數是p_arg指針和it迭代器,其返回值為int類型的函數指針。每遍歷一個結點均會調用visit指向的函數,傳遞給p_arg的值即為用戶參數,其值為iter_foreach()函數的p_arg參數,p_arg的值完全是由用戶決定的,傳遞給it迭代器的值即為指向當前遍歷的迭代器,iter_foreach()函數的實現詳見程序清單3.58。
程序清單3.58 遍歷算法函數

現在可以將程序清單3.57中的第43行和第48行中的dlist_foreach()函數修改為使用iter_foreach()函數,看能否得到相同的效果?
如果將數據保存在數組變量中,那么將如何使用已有的冒泡排序算法呢?由于數組也是容器,因此只要實現基于數組的迭代器即可,詳見程序清單3.59。
程序清單3.59 使用數組實現迭代器接口

基于新的迭代器,同樣可以直接使用冒泡排序算法實現排序,詳見程序清單3.60。
程序清單3.60 使用數組、算法和迭代器

由此可見,通過迭代器冒泡排序算法也得到了復用。如果算法庫里有幾百個函數,那么只要實現迭代器接口的2個函數即可,從而達到復用代碼的目的。顯然,迭代器是一種更靈活的遍歷行為,它可以按任意順序訪問容器中的元素,而且不會暴露容器的內部結構。
-
數據結構
+關注
關注
3文章
573瀏覽量
40192 -
迭代
+關注
關注
0文章
21瀏覽量
8709
原文標題:周立功:迭代器模式——實現代碼復用
文章出處:【微信號:ZLG_zhiyuan,微信公眾號:ZLG致遠電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據結構與算法分析(Java版)(pdf)
C#數據結構和算法分析_ 魏寶剛


了解Python數據結構迭代對象、迭代器、生成器的概念
大牛分享平時如何學習數據結構與算法
算法和數據結構基礎知識分享(上)
算法和數據結構基礎知識分享(中)
算法和數據結構基礎知識分享(下)





 工商網監
工商網監
評論