 如何選擇神經網絡種類
如何選擇神經網絡種類
在人工智能和機器學習領域,選擇適合的神經網絡種類是構建高效、準確模型的關鍵步驟。這一過程涉及對任務類型、數據特性、計算資源及模型性能要求等多方面的綜合考慮。
一、明確任務類型
首先,需要明確所要解決的任務類型,因為不同類型的任務往往適合不同類型的神經網絡。任務類型大致可以分為以下幾類:
- 分類任務 :如果任務是識別或分類輸入數據(如圖像、文本、語音等),則可以選擇前饋神經網絡(如多層感知機MLP)、卷積神經網絡(CNN)、長短時記憶網絡(LSTM)等。其中,CNN特別適用于圖像分類任務,因為它能有效提取圖像中的空間特征。
- 回歸任務 :如果目標是預測一個連續值(如價格、溫度等),則可以選擇前饋神經網絡(如MLP)、卷積神經網絡(在某些特定場景下)等。
- 序列生成任務 :對于需要生成序列數據的任務(如機器翻譯、文本生成等),循環神經網絡(RNN)及其變體(如LSTM、GRU)是更好的選擇,因為它們能夠捕捉序列中的時序依賴關系。
- 生成任務 :如果目標是生成逼真的數據樣本(如圖像、文本等),則生成對抗網絡(GAN)是一個強有力的工具。GAN通過生成器和判別器的對抗訓練來生成高質量的數據樣本。
- 強化學習任務 :在某些情況下,任務可能涉及通過與環境交互來學習最優策略,這時可以考慮使用深度強化學習模型,如DQN(深度Q網絡)等。
二、分析數據特性
數據的特性對選擇神經網絡種類至關重要。以下是一些關鍵的數據特性及其對應的神經網絡選擇建議:
- 數據規模 :
- 大數據集 :對于大規模數據集,可以選擇更復雜的神經網絡結構(如深層CNN、LSTM等),以充分挖掘數據中的模式。
- 小數據集 :在小數據集上,選擇較簡單的神經網絡結構(如淺層MLP)或使用遷移學習方法可能更為合適,以避免過擬合。
- 數據維度 :
- 高維數據 :如圖像數據,通常選擇卷積神經網絡(CNN),因為CNN能有效處理高維空間數據,并通過卷積操作提取局部特征。
- 低維數據 :對于低維數據(如時間序列數據),循環神經網絡(RNN)及其變體(LSTM、GRU)可能更合適。
- 數據類型 :
- 數據分布 :
- 如果數據分布復雜且存在多模態特性,可以考慮使用混合模型(如混合專家系統)或集成學習方法來結合多個神經網絡的優點。
三、考慮計算資源
計算資源是選擇神經網絡種類時不可忽視的因素。不同的神經網絡對計算資源的需求差異很大:
- 模型復雜度 :更復雜的神經網絡(如深層CNN、大型LSTM網絡)需要更多的計算資源來訓練和推理。因此,在選擇模型時需要考慮可用計算資源的限制。
- 訓練時間 :某些神經網絡(如深層網絡)可能需要較長的訓練時間才能達到良好的性能。如果時間緊迫,可能需要選擇訓練速度更快的模型或采用并行計算技術來加速訓練過程。
四、評估模型性能
在選擇神經網絡種類后,需要通過實驗來評估模型的性能。以下是一些常用的評估指標:
- 準確率/精確度 :對于分類任務,準確率是最直觀的評估指標。然而,在某些情況下(如不平衡數據集),精確度可能不是最佳指標,需要考慮其他指標(如F1分數、ROC曲線下的面積AUC等)。
- 損失函數值 :損失函數是衡量模型預測值與實際值之間差異的重要指標。在訓練過程中,應密切關注損失函數值的變化趨勢以判斷模型的收斂情況。
- 過擬合與欠擬合 :通過觀察訓練集和驗證集上的性能差異來評估模型是否存在過擬合或欠擬合問題。過擬合通常表現為訓練集上性能很好但驗證集上性能較差;欠擬合則表現為訓練集和驗證集上性能均較差。
五、總結與建議
綜上所述,選擇神經網絡種類是一個綜合考慮任務類型、數據特性、計算資源和模型性能要求的過程。在實際應用中,建議遵循以下步驟:
- 明確任務類型和目標。
- 分析數據的規模和特性。
- 考慮計算資源和時間成本 :
計算資源包括CPU、GPU、TPU等硬件設備的可用性以及內存和存儲的容量。不同的神經網絡結構對計算資源的需求差異很大。例如,深層卷積神經網絡(CNN)在圖像識別任務中表現出色,但其訓練和推理過程可能需要大量的計算資源,特別是在處理高分辨率圖像時。相比之下,一些輕量級的網絡結構(如MobileNet、SqueezeNet等)雖然性能可能稍遜一籌,但能夠在計算資源有限的情況下實現較快的推理速度。
此外,時間成本也是不可忽視的因素。對于需要快速迭代和部署的應用場景,選擇訓練時間較短的模型更為合適。例如,在實時系統中,模型的推理速度可能比準確率更為重要。 - 評估模型的可解釋性和健壯性 :
在某些應用場景中,模型的可解釋性和健壯性也是選擇神經網絡種類的重要考慮因素。可解釋性指的是模型預測結果的可理解程度,這對于需要決策支持或法律合規性的領域尤為重要。例如,在醫療診斷中,醫生可能更傾向于使用可解釋性較強的模型,以便理解模型的預測依據。
健壯性則指模型在面對異常輸入或噪聲時的穩定性和可靠性。在實際應用中,數據往往存在噪聲和異常值,因此選擇具有較好健壯性的模型可以減少因數據問題導致的預測錯誤。 - 參考領域內的最佳實踐和成功案例 :
在選擇神經網絡種類時,參考領域內的最佳實踐和成功案例可以提供有益的指導。通過查閱相關文獻、論文和開源項目,可以了解不同神經網絡在類似任務上的表現和優缺點。這有助于快速縮小選擇范圍,并避免走彎路。 - 進行實驗和迭代 :
最終選擇哪種神經網絡種類往往需要通過實驗來驗證。在實驗過程中,可以嘗試不同的網絡結構、參數設置和優化算法等,以找到最適合當前任務和數據集的模型。同時,保持迭代的心態,根據實驗結果不斷調整和優化模型,以獲得更好的性能。 - 考慮未來擴展性和可維護性 :
隨著應用場景和數據量的不斷變化,所選的神經網絡模型可能需要進行擴展或更新。因此,在選擇模型時還需要考慮其未來擴展性和可維護性。例如,選擇具有模塊化設計、易于集成新組件和算法的模型可以方便未來的擴展和升級。
結論
選擇神經網絡種類是一個復雜而細致的過程,需要綜合考慮任務類型、數據特性、計算資源、模型性能要求以及可解釋性、健壯性、領域最佳實踐等多個因素。在實際應用中,沒有一種神經網絡能夠適用于所有場景和任務。因此,建議根據具體情況進行靈活選擇和調整,并通過實驗來驗證所選模型的性能和適用性。同時,保持對新技術和新方法的關注和學習,以便在需要時能夠及時調整和優化模型。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
人工智能
+關注
關注
1793文章
47590瀏覽量
239486 -
機器學習
+關注
關注
66文章
8435瀏覽量
132885 -
cnn
+關注
關注
3文章
353瀏覽量
22281
發布評論請先 登錄
相關推薦
神經網絡教程(李亞非)
第1章 概述 1.1 人工神經網絡研究與發展 1.2 生物神經元 1.3 人工神經網絡的構成 第2章人工神經網絡基本模型 2.1 MP模型 2.2 感知器模型 2.3
發表于 03-20 11:32
卷積神經網絡如何使用
卷積神經網絡(CNN)究竟是什么,鑒于神經網絡在工程上經歷了曲折的歷史,您為什么還會在意它呢? 對于這些非常中肯的問題,我們似乎可以給出相對簡明的答案。
發表于 07-17 07:21
【案例分享】ART神經網絡與SOM神經網絡
今天學習了兩個神經網絡,分別是自適應諧振(ART)神經網絡與自組織映射(SOM)神經網絡。整體感覺不是很難,只不過一些最基礎的概念容易理解不清。首先ART神經網絡是競爭學習的一個代表,
發表于 07-21 04:30
人工神經網絡實現方法有哪些?
人工神經網絡(Artificial Neural Network,ANN)是一種類似生物神經網絡的信息處理結構,它的提出是為了解決一些非線性,非平穩,復雜的實際問題。那有哪些辦法能實現人工神經
發表于 08-01 08:06
如何構建神經網絡?
原文鏈接:http://tecdat.cn/?p=5725 神經網絡是一種基于現有數據創建預測的計算系統。如何構建神經網絡?神經網絡包括:輸入層:根據現有數據獲取輸入的層隱藏層:使用反向傳播優化輸入變量權重的層,以提高模型的預測
發表于 07-12 08:02
基于BP神經網絡的PID控制
最近在學習電機的智能控制,上周學習了基于單神經元的PID控制,這周研究基于BP神經網絡的PID控制。神經網絡具有任意非線性表達能力,可以通過對系統性能的學習來實現具有最佳組合的PID控制。利用BP
發表于 09-07 07:43
神經網絡移植到STM32的方法
將神經網絡移植到STM32最近在做的一個項目需要用到網絡進行擬合,并且將擬合得到的結果用作控制,就在想能不能直接在單片機上做神經網絡計算,這樣就可以實時計算,不依賴于上位機。所以要解決的主要是兩個
發表于 01-11 06:20
【人工神經網絡基礎】為什么神經網絡選擇了“深度”?
由 Demi 于 星期四, 2018-09-06 09:33 發表 現在提到“神經網絡”和“深度神經網絡”,會覺得兩者沒有什么區別,神經網絡還能不是“深度”(deep)的嗎?我們常用
發表于 09-06 20:48
?700次閱讀
教大家怎么選擇神經網絡的超參數
minibatch 的大小, 輸出神經元的編碼方式, 代價函數的選擇, 權重初始化的方法, 神經元激活函數的種類, 參加訓練模型數據的規模 這些都是可以影響
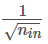
神經網絡的種類及舉例說明
神經網絡作為深度學習領域的核心組成部分,近年來在圖像識別、自然語言處理、語音識別等多個領域取得了顯著進展。本文將從神經網絡的基本原理出發,深入講解其種類,并通過具體實例進行說明,以期為初學者提供一份詳盡的入門指南。





 工商網監
工商網監
評論