 一文詳解基于以太網的GPU Scale-UP網絡
一文詳解基于以太網的GPU Scale-UP網絡
最近Intel Gaudi-3的發布,基于RoCE的Scale-UP互聯,再加上Jim Keller也在談用以太網替代NVLink。而Jim所在的Tenstorrent就是很巧妙地用Ethernet實現了片上網絡之間的互聯。所以今天有必要來講講這個問題。
實現以太網替代NVLink需要什么手段,不只是一個傳輸協議的問題,還涉及到GPU架構的一系列修改,本質上這個問題等價于如何把HBM掛在以太網上,并實現Scale-Out和滿足計算需求的一系列通信優化,例如SHARP這類In-Network-Computing等, 全球來看能同時搞定這個問題的人也就那么幾個,至少明確的說UltraEthernet壓根就沒想明白。
有必要回答以下幾個問題,或者說博通要搞個NVLink一樣的東西出來,必須解決如下幾個問題:
1.Latency Boundary是多少?高吞吐高速Serdes FEC和超過萬卡規模的互聯帶來的鏈路延遲都是不可抗的,這些并不是說改一個包協議,弄一個HPC-Ethernet就能搞定的。
2.傳輸的語義是什么?做網絡的這群人大概只懂個SEND/RECV。舉個例子,UEC定義的Reliable Unordered Delivery for Idempotent operations(RUDI)其實就是一個典型的技術上的錯誤,一方面它滿足了交換律和冪等律,但是針對一些算子,例如Reduction的加法如何實現冪等?顯然這群人也沒做過,還有針對NVLink上那種細顆粒度的訪存,基于結合律的優化也是不支持的。更一般來說,它必須演進到Semi-Lattice的語義才行。
3.更大內存在NVLINK上池化的問題? 解決計算問題中Compute Bound算子的部分時間/空間折中,例如KV Cache等。
4.動態路由和擁塞控制能力1:1無收斂的Lossless組網對于萬卡集群通過一些hardcode的調優沒什么太大的問題,而對于十萬卡和百萬卡規模集群來看,甚至需要RDMA進行長傳,這些問題目前來看沒有一個商業廠商能解決的。
考慮到超大規模模型訓練的一系列需求,把HBM直接掛載在以太網上并實現了一系列集合通信卸載的,放眼全球現在也就只有少數幾個團隊干過,前三個問題我是在四年前做NetDAM項目時就已經完全解決干凈了,第四個去年也在某個云的團隊一起解決干凈了。
下面我們將介紹一些Gaudi3/Maia100/TPU等多個廠商的互聯,然后再分析一下NVLink的演進,最后再來談談如何能夠真正地解決這些問題 at Scale, 再強調(Diss)一下at Scale這事沒做好就別瞎叫。
1. 當前ScaleUP互聯方案概述
1.1 Intel Gaudi3
從Gaudi3 whitepaper[1]來看,Gaudi的Die如下圖所示: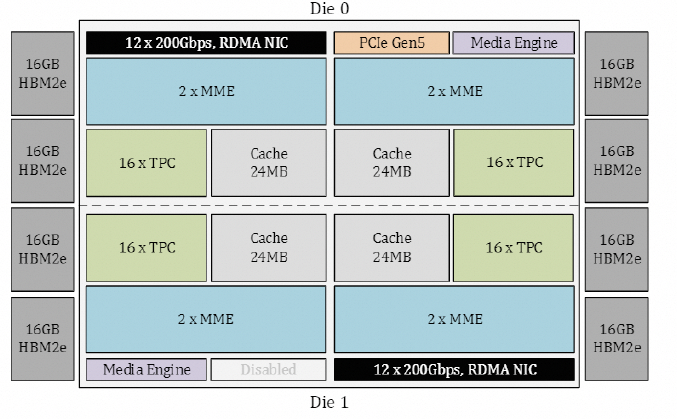
內置了24個RoCE 200Gbps的鏈路,其中21個用于內部FullMesh,三個用于外部鏈接。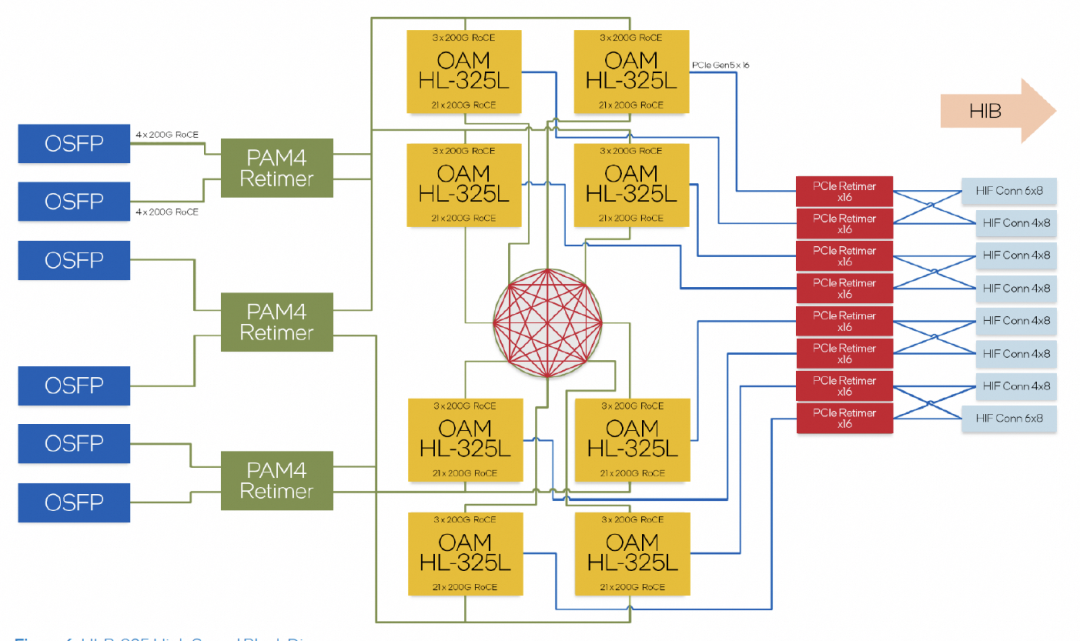
超大規模組網的拓撲,計算了一下Leaf交換機的帶寬是一片25.6T的交換機。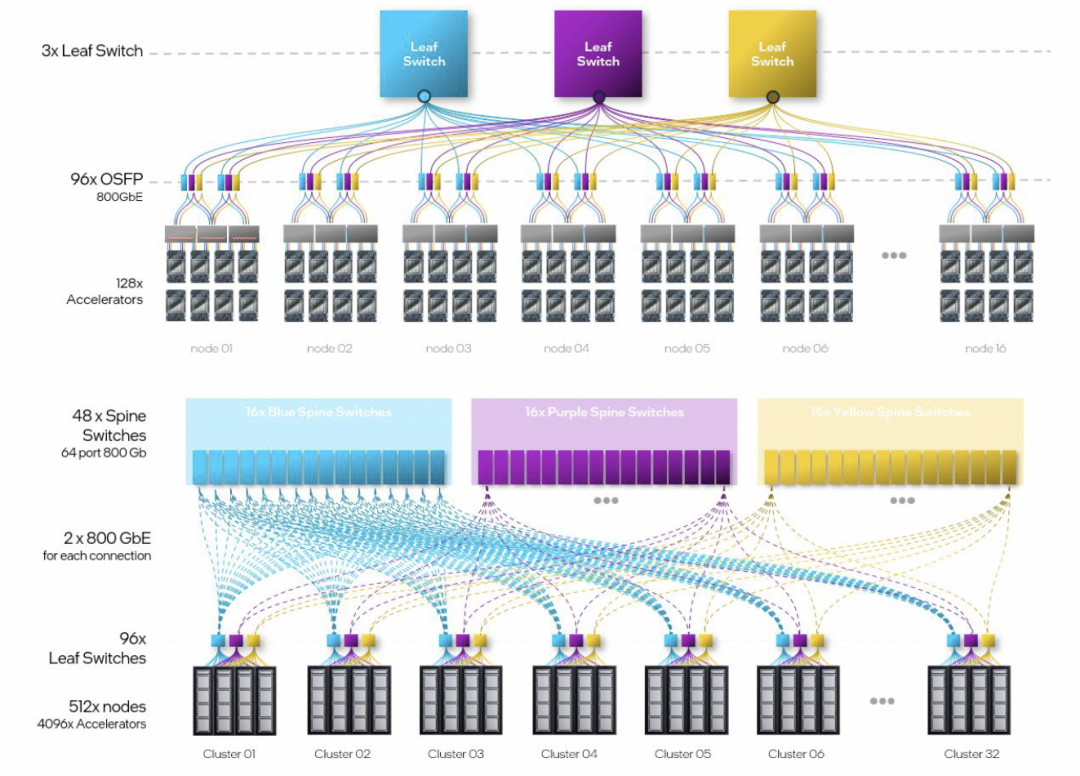
但是Intel WhitePaper有一系列的問題值得去仔細爬一下。
1.1.1 擁塞控制
Intel的白皮書闡述的是沒有使用PFC,而是采用了Selective ACK機制。同時采用了SWIFT來做CC算法避免使用ECN,基本上明眼人一看,這就是復用了Google Falcon在Intel IPU上做的Reliable Transport Engine。
1.1.2 多路徑和In-Network Reduction
Intel宣稱支持Packet Spraying,但是交換機用的哪家的呢,一定不是自己家的Tofino。那么只能是博通了。另外In-Network Reduction支持了FP8/BF16等, Operator只支持Sum/Min/Max,再加上UEC有一些關于In-Network-Computing(INC)的工作組,應該基本上就清楚了。
1.2 Microsoft Maia100
沒有太多的信息,只有4800Gbps單芯片的帶寬,然后單個服務器機框4張Maia100,整個機柜8個服務器構成一個32卡的集群。
放大交換機和互聯的線纜來看,有三個交換機,每個服務器有24個400Gbps網絡接口,網口間有回環的連接線(圖中黑色),以及對外互聯線(紫色)。
也就是說很有可能構成如下的拓撲: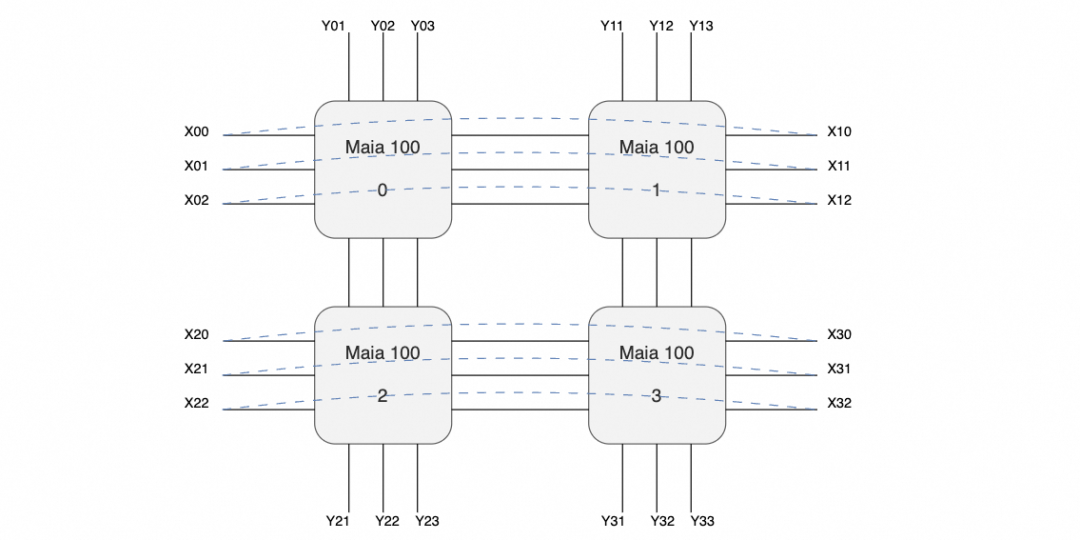
即在主板內部構成一個口字形的互聯,然后在X方向構成一個環,而在Y方向則是分別構成三個平面連接到三個交換機。
交換機上行進行機柜間的Scale-Out連接,每個機柜每個平面總共有32個400G接口, 再加上1:1收斂,上行交換機鏈路算在一起正好一個25.6T的交換機,這樣搭幾層擴展理論應該可行,算是一個Scale-Up和Scale-Out兩張網絡合并的代表。至于協議對于Torus Ring來看,簡單的點到點RoCE應該問題不大,互聯到Scale-Out交換機時就需要多路徑的能力了。
缺點是延遲可能有點大,不過這類自定義的芯片如果不是和CUDA那樣走SIMT,而是走脈動陣列的方式,延遲也不是太大的問題。另外Torus整個組就4塊,集合通信延遲影響也不大。但是個人覺得這東西可能還是用于做推理為主的,一般CSP都會先做一塊推理用的芯片,再做訓練的。另外兩家CSP也有明確的訓練推理區分AWS Trainium/Inferentia, Google也是V5p/V5e。
1.3 Google TPU
TPU互聯大家已經很清楚了,Torus Ring的拓撲結構和光交換機來做鏈路切換。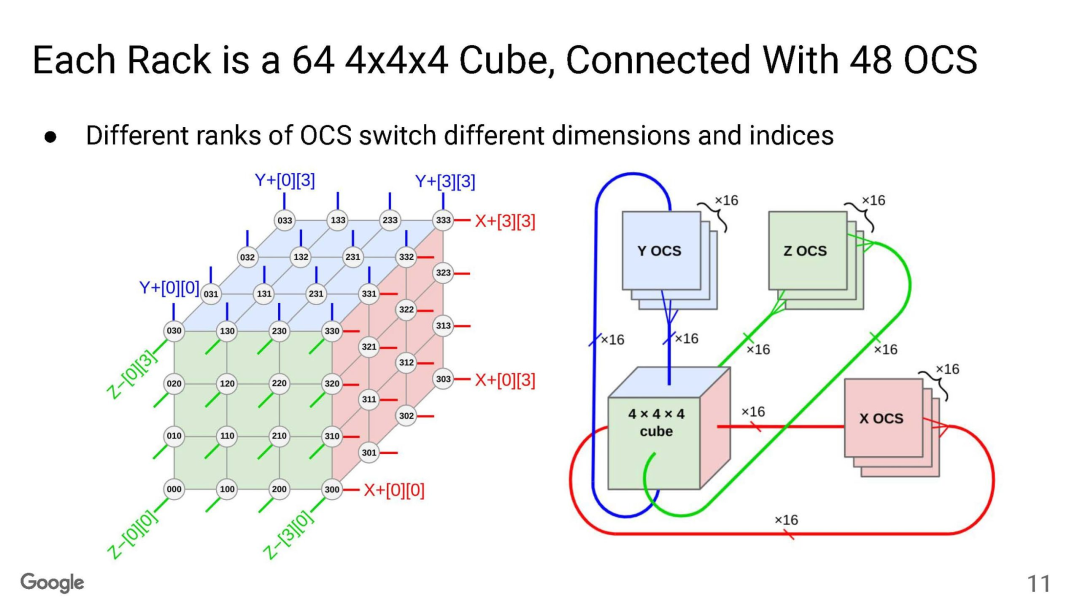
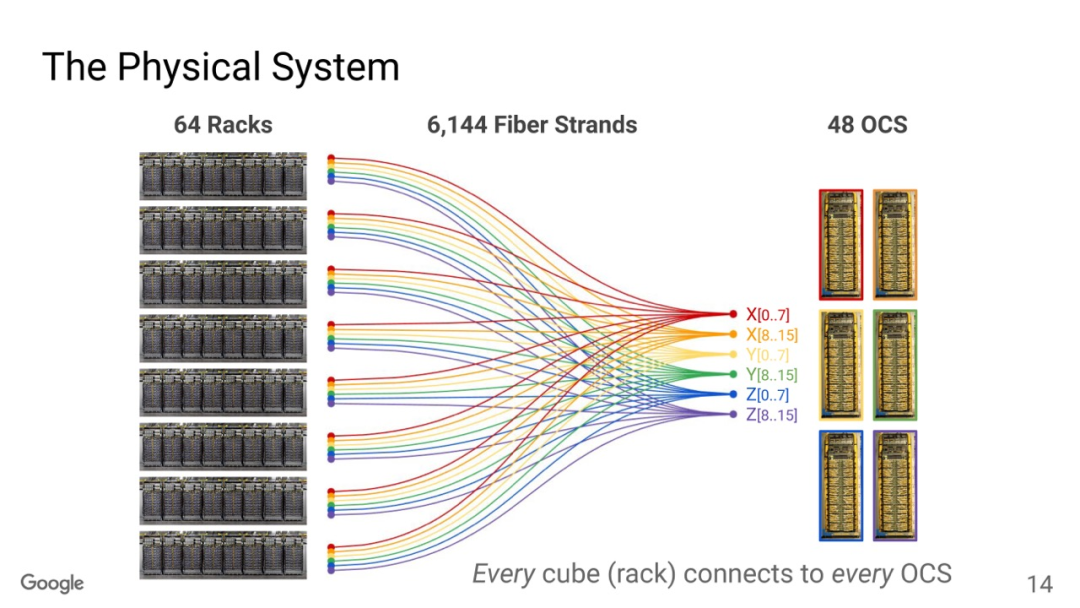
OCS有兩個目的,一個是按照售賣的規模進行動態切分,例如TPUv5p 單芯片支持4800Gbps的ICI(Inter-Chip Interconnect)連接,拓撲為3D-Torus,整個集群8960塊TPUv5p 最大售賣規模為6144塊構成一個3D-Torus。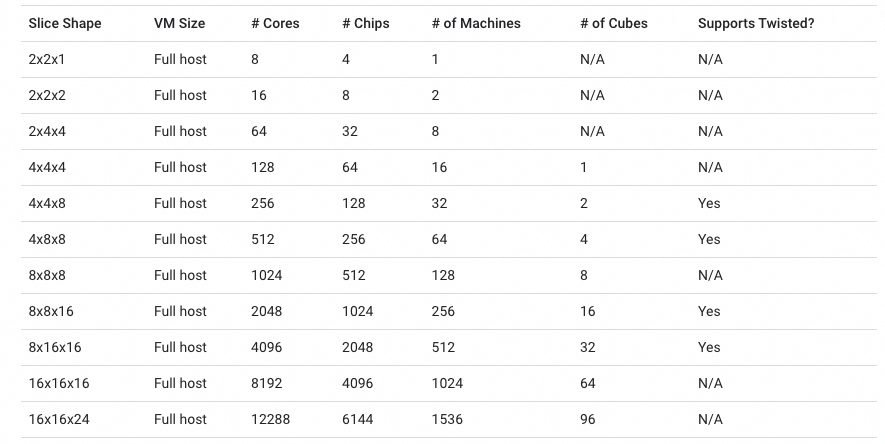
通過OCS可以切分這些接口進行不同尺度的售賣, 另一個是針對MoE這些AlltoAll的通信做擴展bisection 帶寬的優化。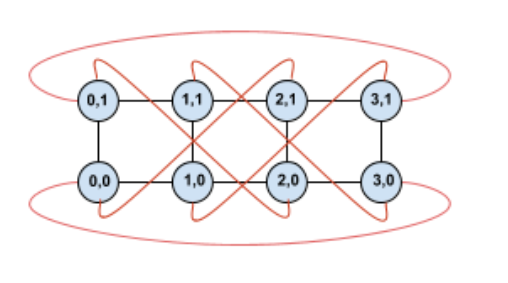
還有一個是容錯,這是3D Torus拓撲必須要考慮的一個問題,有一些更新是這周NSDI‘24 講到一個《Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer》[2] 后面我們將專門介紹。 另一方面Google還支持通過數據中心網絡擴展兩個Pod構建Multislice的訓練,Pod間做DP并行。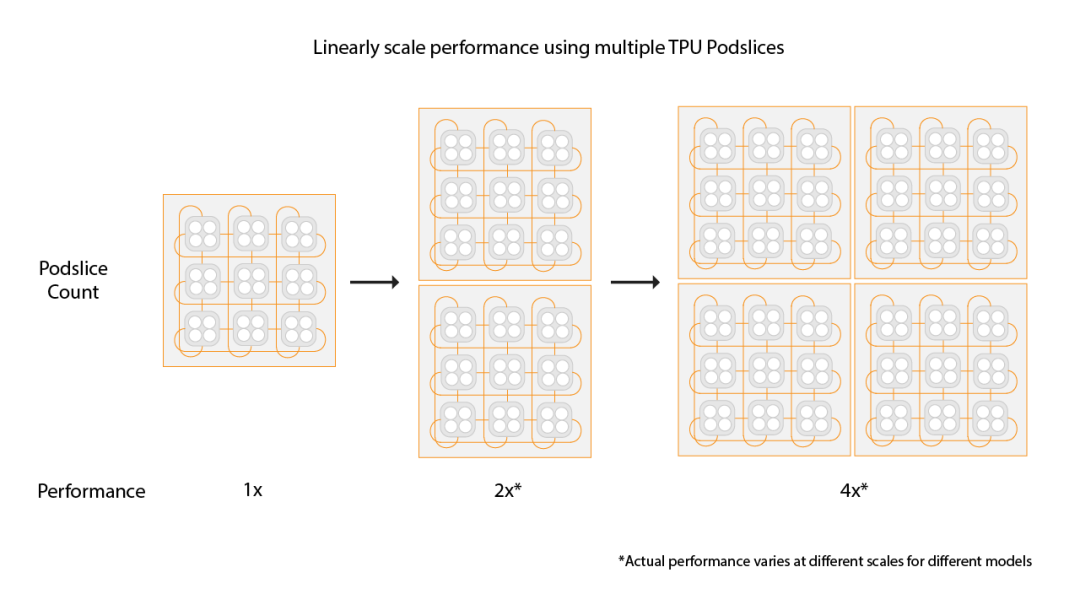
1.4 AWS Trainium
Trainium架構如下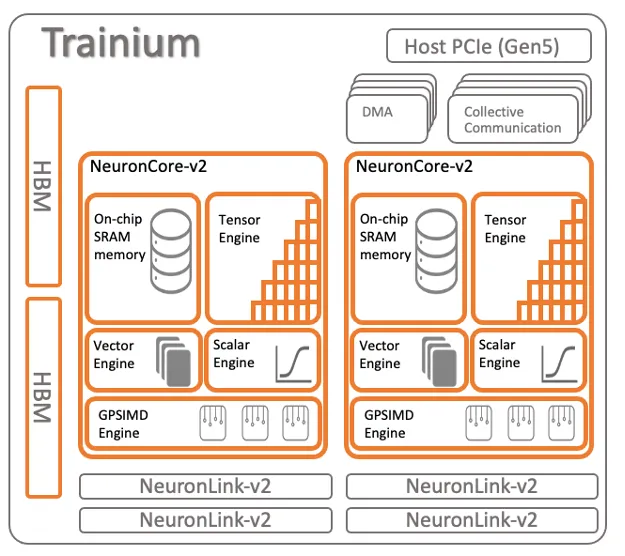
16片構成一個小的Cluster,片間互聯如下: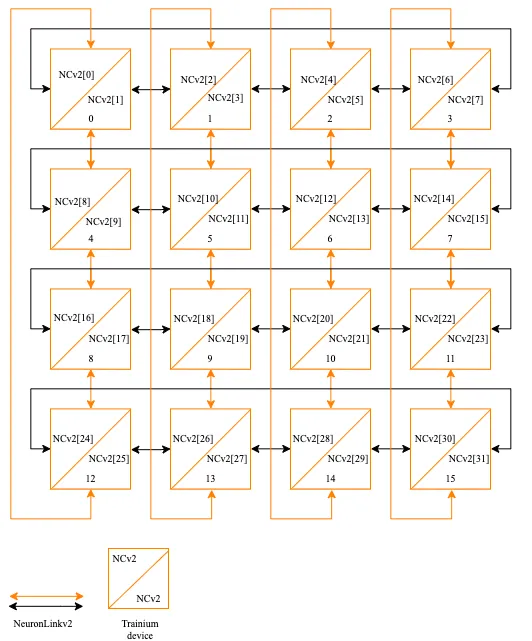
也是一個2D Torus Ring的結構。
1.5 Tesla Dojo
它搞了一個自己的Tesla Transport Protocol,統一Wafer/NOC和外部以太網擴展。
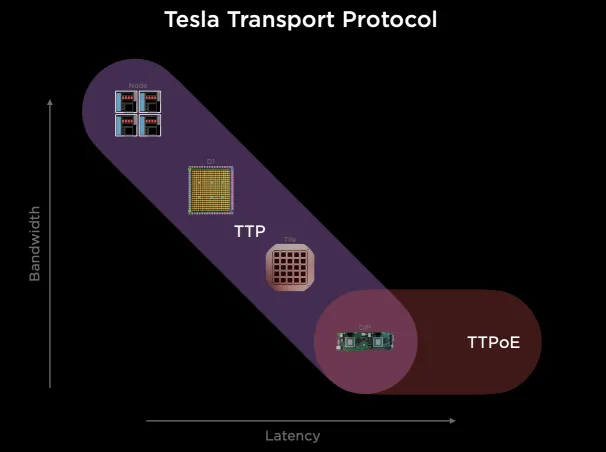
它通過臺積電的System-on-Wafer將25個D1計算單元封裝在一個晶圓上, 并采用5x5的方式構建2D Mesh網絡互聯所有的計算單元, 單個晶圓構成一個Tile.每個Tile有40個I/O Die。
Tile之間采用9TB/s互聯。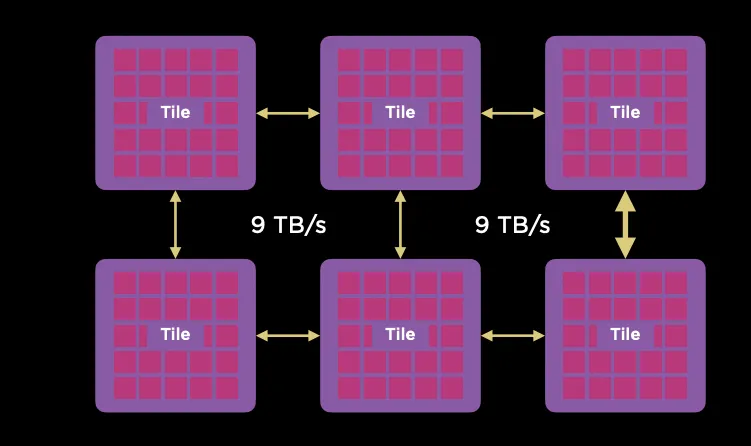
可以通過片上網絡路由繞開失效的D1核或者Tile。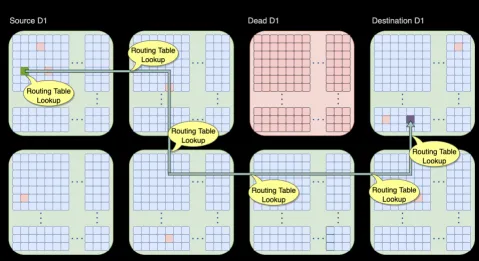
對外Scale-Out的以太網有一塊DIP,每個D1計算引擎有自己的SRAM, 而其它內存放置在帶HBM的Dojo接口卡(DIP)上。
每個網卡通過頂部的900GB/s特殊總線TTP(Tesla Transport Protocol)連接到Dojo的I/O Die上, 正好對應800GB HBM的帶寬, 每個I/O Die可以連接5個Dojo接口卡(DIP)。

由于內部通信為一個2D Mesh網絡, 長距離通信代價很大, 針對片上路由做了一些特殊的設計。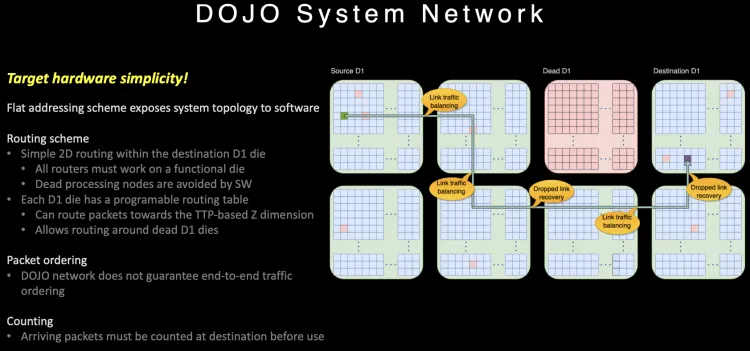
路由在片上提供多路徑,并且不保序, 同時針對大范圍長路徑的通信, 它很巧妙的利用Dojo接口卡構建了一個400Gbps的以太網TTPoE總線來做shortcut。
Dojo通過System-on-wafer的方式構建了基于晶圓尺度的高密度的片上網絡, 同時通過私有的片間高速短距離總線構建了9TB/s的wafer間的通信網絡. 然后將I/O和內存整合在DIP卡上,提供每卡900GB/s連接到晶圓片上網絡的能力,構建了一個超大規模的2D Mesh網絡, 但是考慮到片上網絡通信距離過長帶來的擁塞控制, 又設計了基于DIP卡的400Gbps逃生通道,通過片外的以太網交換機送到目的晶圓上。
1.6 Tenstorrent
Jim keller在Tenstorrent的片上網絡設計就是使用的以太網,結構很簡單, Tensor+控制頭構成一個以太網報文并可以觸發條件執行等能力,如下所示: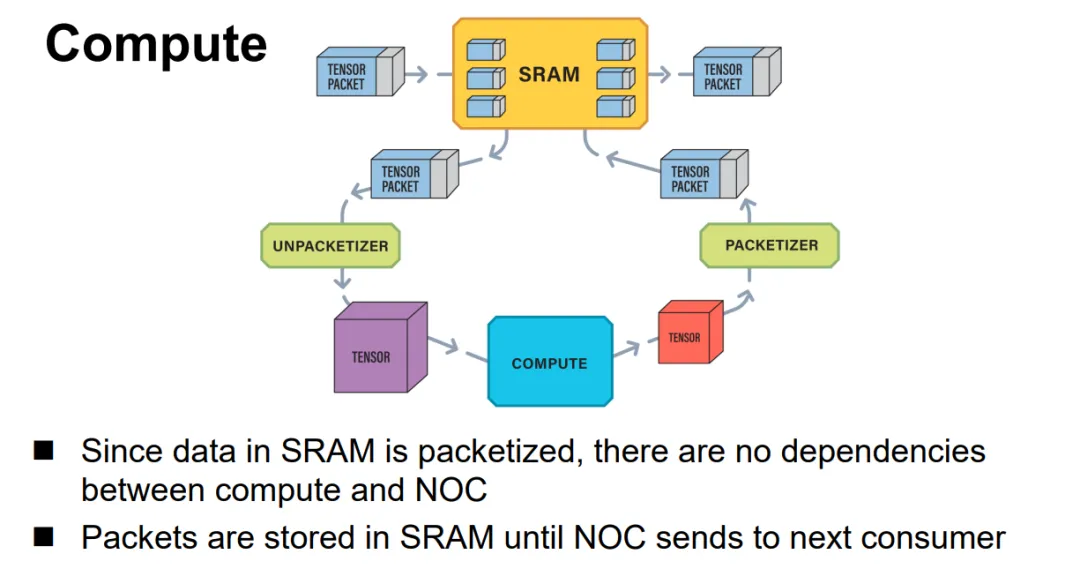
片間互聯全以太網: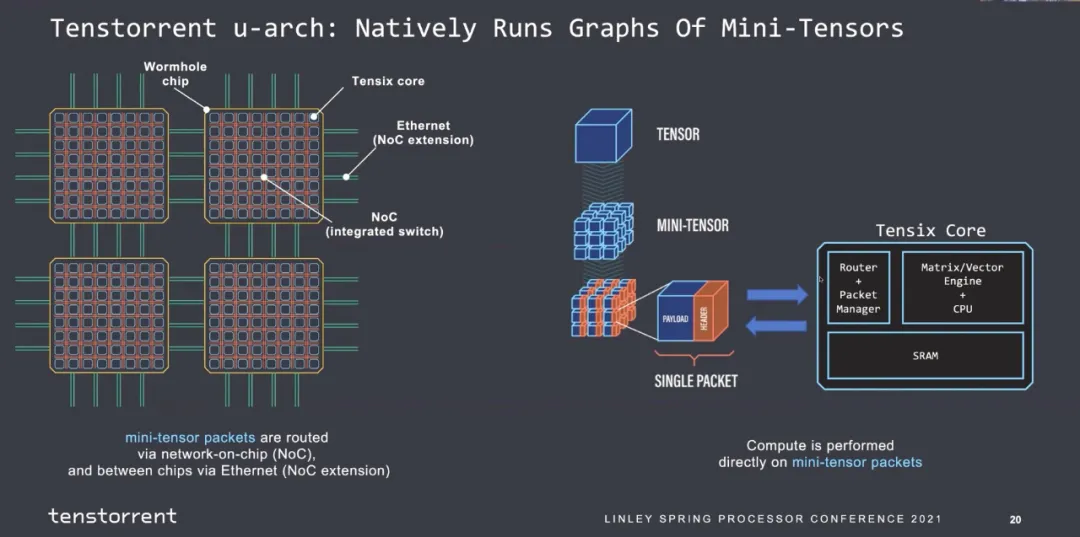
并且支持多種功能通信源語。
然后就是圖的劃分,主觀覺得每個stage的指令數是可以估計的,算子進出的帶寬是可以估計的。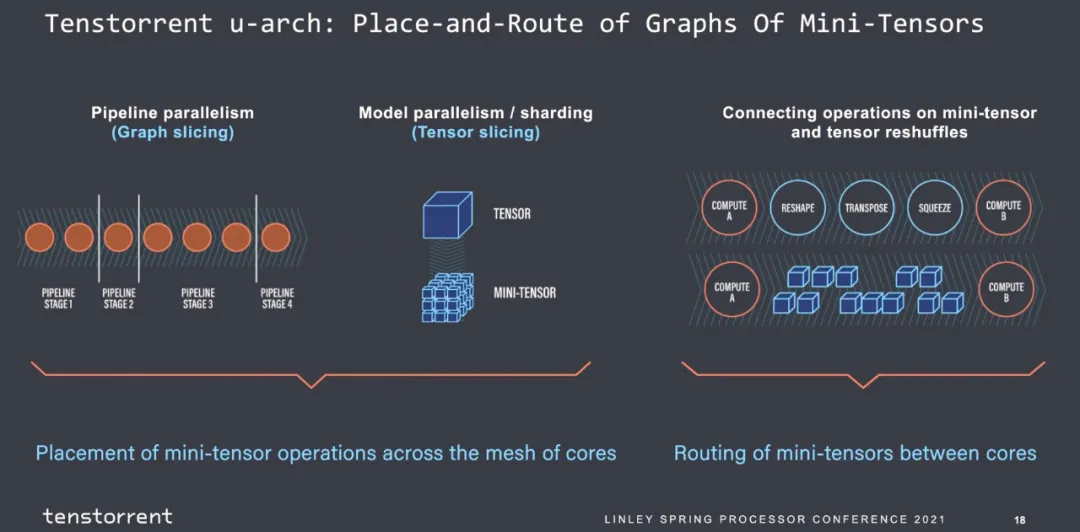
那么最后mapping到核上的約束也似乎好做: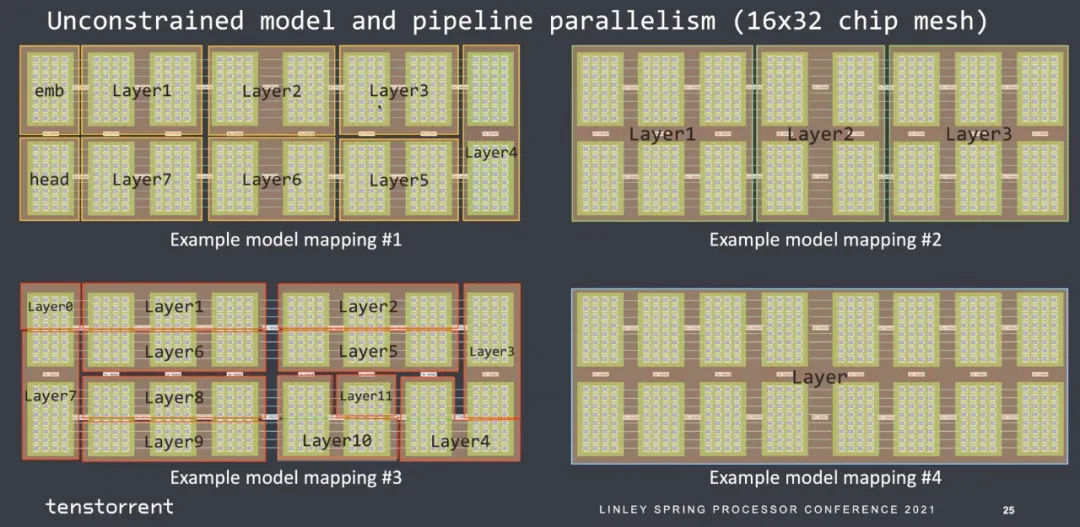
也是很簡單的一個2D Mesh結構:
可以擴展到40960個core的大規模互聯。
2. Scale-UP的技術需求
2.1 拓撲選擇
我們可以注意到在ScaleUp網絡選擇中,Nvidia當前是1:1收斂的FatTree構建,而其它幾家基本上都是Torus Ring或者2D Mesh,而Nvidia后續會演進到DragonFly。
背后的邏輯我們可以在hammingMesh的論文中看到的選擇如下: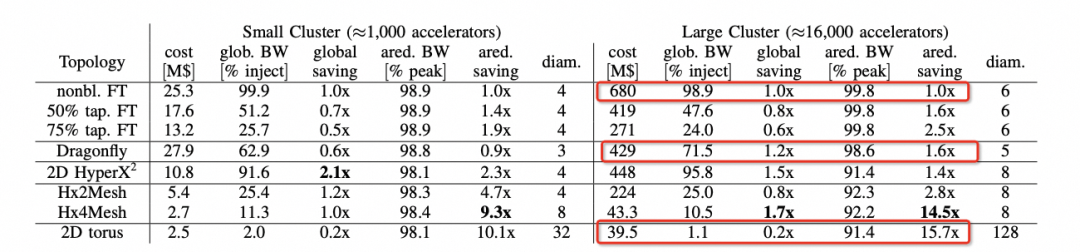
可以看到對于Allreduce帶寬來看,Torus是最便宜的,性能也能夠基本跑到峰值。但是針對MoE這類模型的AlltoAll就要考察bisection帶寬了,而DragonFly無論是在布線復雜度還是GlobBW以及網絡直徑上都還不錯,所以明白了Bill Dally的選擇了吧?
2.2 動態路由和可靠傳輸
雖然所有的人都在扯RoCE有缺陷,BF3+Spectrum-4有Adaptive Routing,博通有DLB/GLB來演進Packet Spraying還有和思科一樣的VoQ的技術,當然還有Meta的多軌道靜態路由做流量工程,或者管控平面去調度親和性。但簡單來說,這些都是在萬卡規模可以解決一部分問題的,而at Scale這個難題現在要到十萬卡以上規模,怎么做?
從算法上解決Burst是一件很難的事情,而更難的是所有的人不去想Burst怎么造成的,天天屎上雕花的去測交換機buffer來壓burst,據說還有人搞確定性網絡和傅立葉分析來搞?想啥呢?
這是一個非常難的問題,就看工業界其它幾個廠什么時候能想明白吧?另一方面是系統失效和彈性售賣,Google在NSDI24的文章里面提到會產生碎片的原因: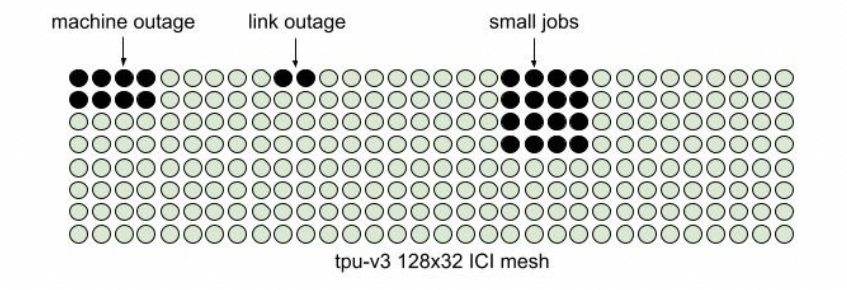
如果不考慮這些問題會導致調度難題。ICI內部的路由表實現配合OCS交換機是一個不錯的選擇。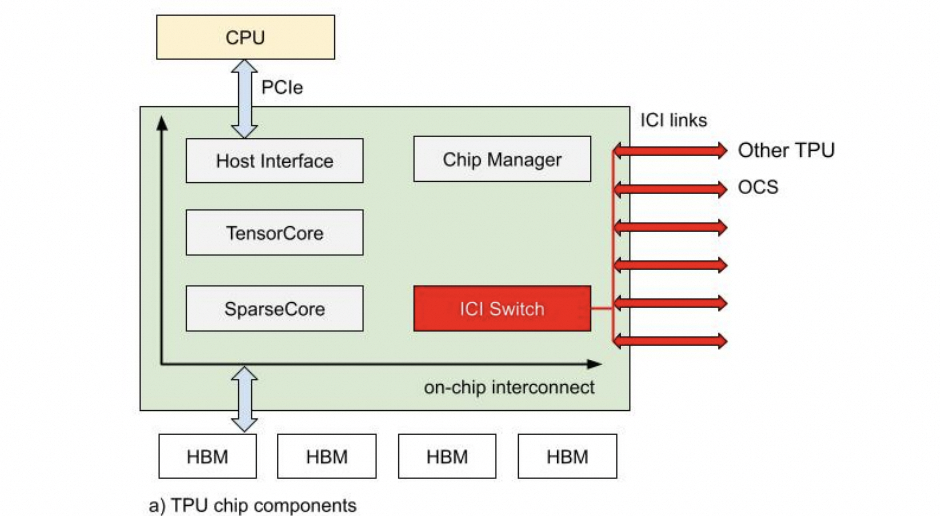
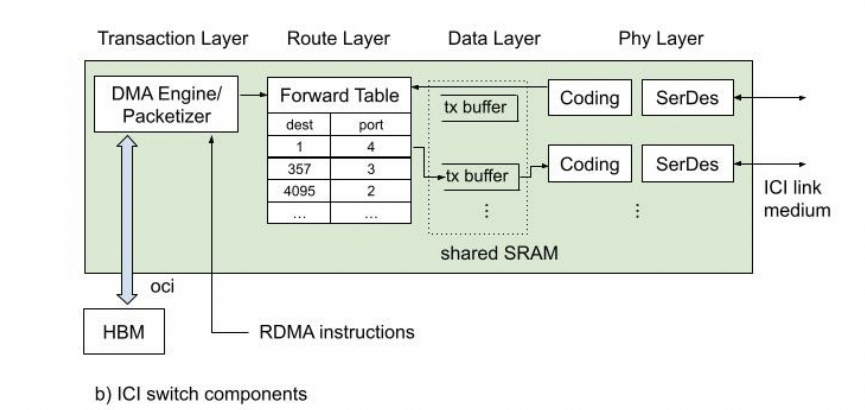
這篇論文詳細地公開了ICI的物理層/可靠傳輸層/路由層和事務層,后面會詳細講解一下這篇論文。
為什么這個事情對以太網支持ScaleUP很重要呢?因為以太網一定需要在這里實現一個路由層支撐DragonFly和失效鏈路切換的能力。
3. Scale UP延遲重要么? 其實回答這個問題本質是GPU如何做Latency Hidding,以及Latency上NVLink和RDMA之間的差異。需要注意的是本來GPU就是一個Throughput Optimized處理器,又極致的追求低延遲那么一定是實現上有問題。而本質上的問題是NVLink是內存語義,而RDMA是消息語義,另一方面是RDMA在異構計算實現的問題。
3.1 RDMA實現的缺陷
RDMA相對于NVLink延遲大的關鍵因素在CPU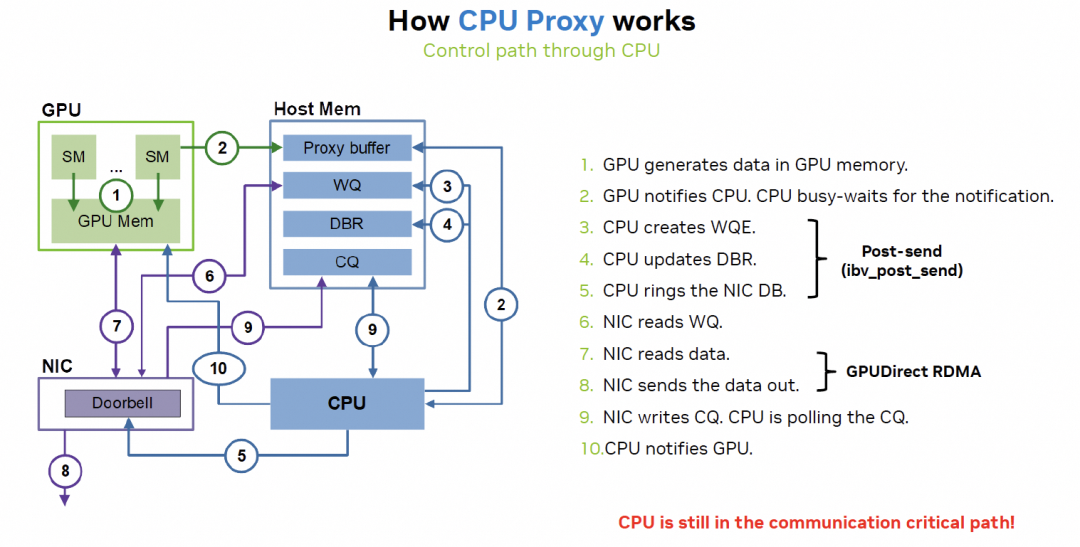
英偉達在通過GDA-KI來解決: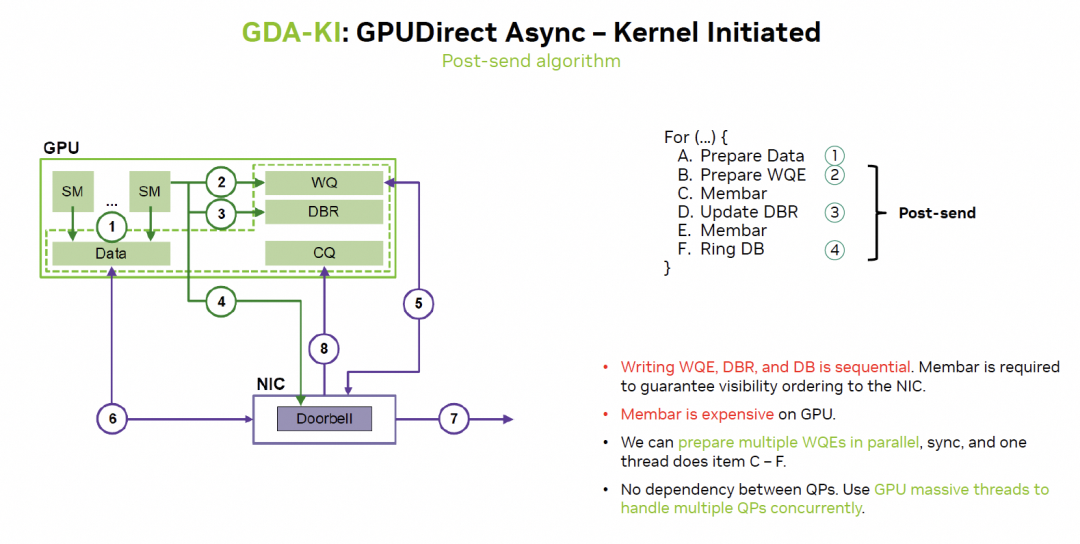
這樣來看實際上很多訪存延遲都更容易隱藏了。
3.2 細粒度的內存訪問
另一個問題是NVLink基于內存語義,有大量細粒度的Load/Store訪問,因此對傳輸效率和延遲非常重要,但如果用以太網RDMA替換該怎么做呢?一來肯定就要說這個事情,包太長了,需要HPC Ethernet。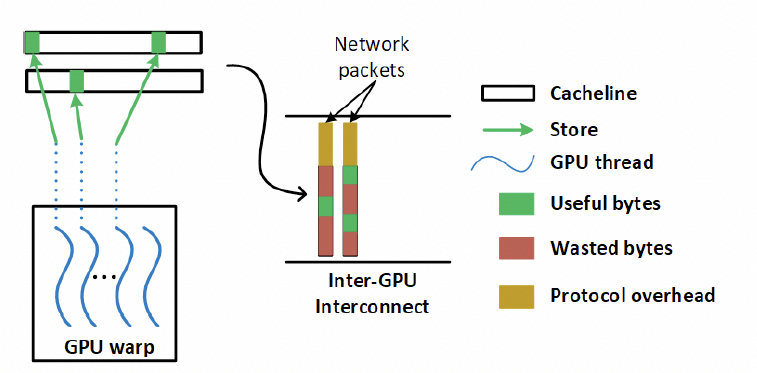
其實這就是我在NetDAM里面一直闡述的一個問題,對于RDMA的消息,需要實現對內的Semi-Lattice語義。
交換律可以保證數據可以用UnOrder方式提交。
冪等保證了丟包重傳的二意性問題,但是需要注意的是對于Reduce這樣的加法操作有副作用時,需要基于事務或者數據的冪等處理,當然我在做NetDAM的時候也解決了。
結合律針對細粒度的內存訪問,通過結合律編排,提升傳輸效率。
對于訪存的需求,在主機內的協議如下: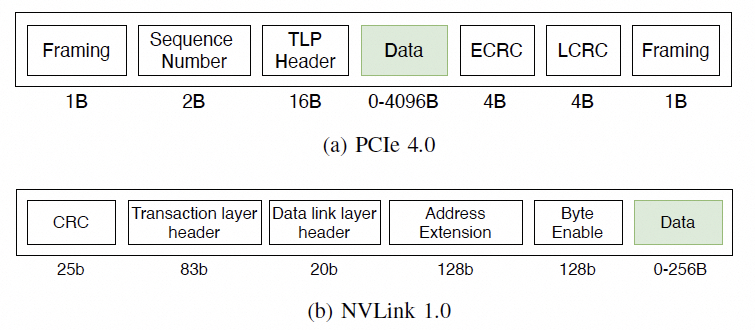
通常是一個FLIT的大小,而在這個基礎上要支持超大規模的ScaleUP互聯和支撐可靠性又要加一些路由頭,還有以太網頭,還有如果超大規模集群要多租戶隔離還有VPC頭,這些其實支持起來都沒有太大問題的,因為當你考慮到了 結合律即可。但是UEC似乎完全沒理解到,提供了RUDI的支持交換律和冪等律支持了,結合律忘了,真是一個失誤。 而英偉達針對這個問題怎么解的呢?結合律編碼: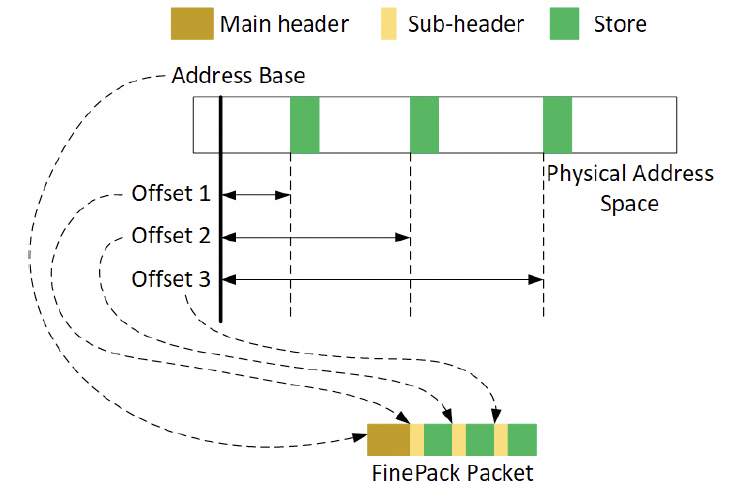
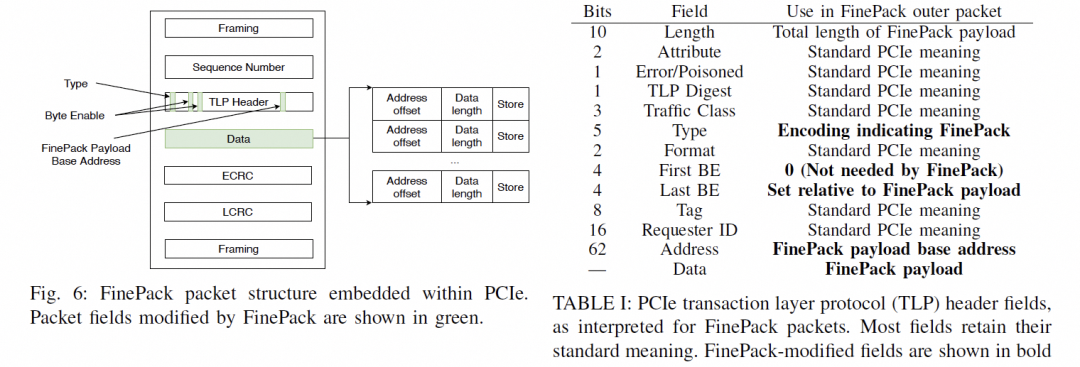
最終細顆粒度訪存的問題解決了。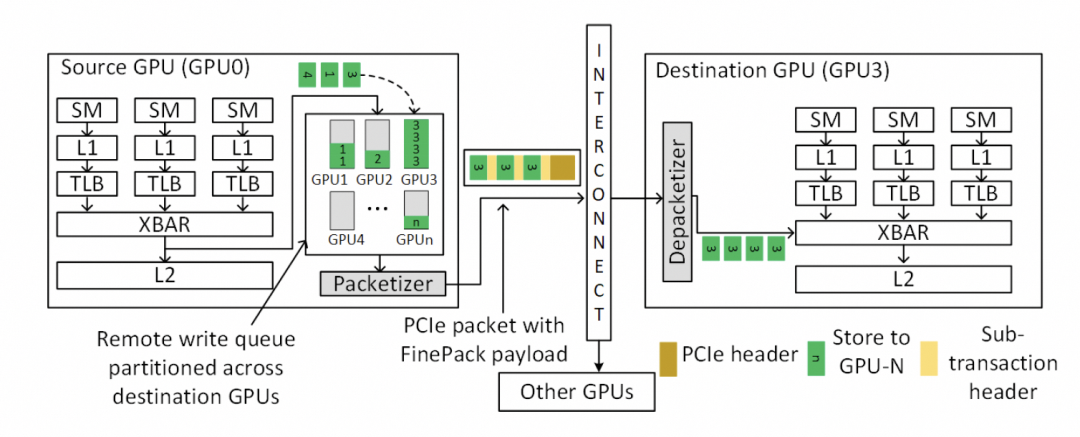
下一代的NVLink一定會走到這條路里面來Infiniband和NVLink這兩張ScaleOut和ScaleUP網絡一定會融合。
3.2 ScaleUP的內存池化
現在很多大模型的問題都在于HBM容量不夠,當然英偉達通過拉個Grace和NVLink C2C擴展,本質上是ScaleUP網絡需要池化內存。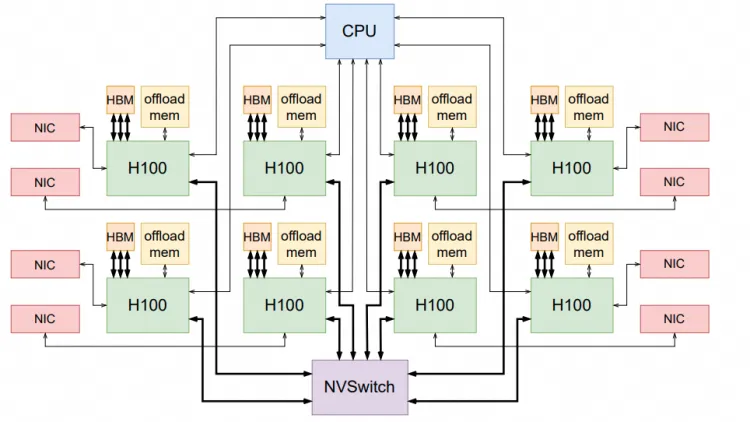
是否還有別的方式呢?英偉達其實已經在干了,附送一篇論文的截圖,后面詳細會講。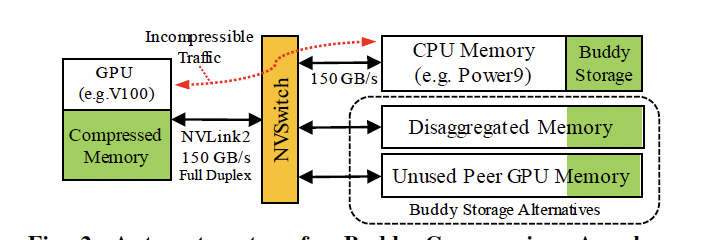
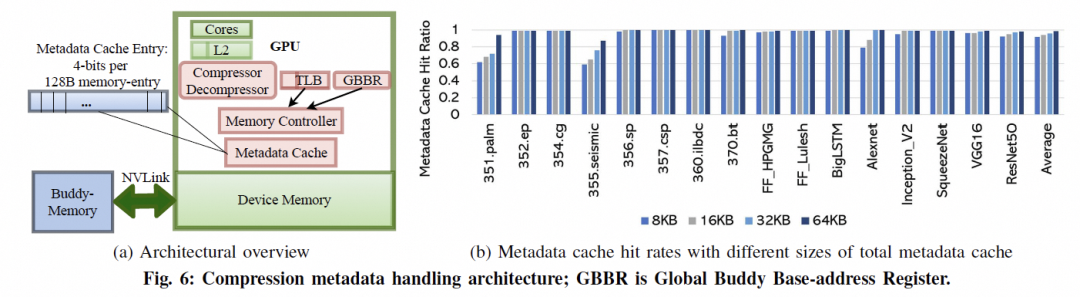
3. 結論 任何一家公司如果想做Ethernet的Scale UP,需要考慮以下大量的問題:
延遲并不是那么重要,配合GPU做一些訪存的修改FinePack成Message語義,然后再Cache上處理一下隱藏延遲即可;
ScaleUP網絡的動態路由和租戶隔離能力非常關鍵,要想辦法做好路由,特別是資源受到鏈路失效產生的碎片問題;
RDMA語義不完善,而簡單的抄SHARP也有一大堆坑,需要實現Semi-Lattice語義,并且支撐一系列有副作用的操作實現冪等;
Fabric的多路徑轉發和擁塞控制,提升整個Fabric利用率;
大規模內存池化。
當然我再勸你們好好讀讀NetDAM的論文,基于以太網ScaleUP直連HBM的實踐,消息編碼和Jim Keller做的幾乎一致,而且都是在同一時期不同出發點的工作,另一方面大規模池化天然就支持。還有就是原生的In-Network-Computing/Programming加速。
當然擁塞控制和多路徑轉發是最近一年多和幾個團隊一起搞的新的工作,至此基本上拼圖已經補全了。
-
以太網
+關注
關注
40文章
5433瀏覽量
171926 -
單芯片
+關注
關注
3文章
420瀏覽量
34587 -
交換機
+關注
關注
21文章
2645瀏覽量
99759 -
Mesh網絡
+關注
關注
0文章
44瀏覽量
14227 -
HBM
+關注
關注
0文章
381瀏覽量
14774
原文標題:談談基于以太網的GPU Scale-UP網絡
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文詳解車載以太網




詳解工業以太網
以太網的分類及靜態以太網交換和動態以太網交換、介紹
一文詳解什么是實時以太網
工業以太網與傳統以太網絡的比較
一文讀懂以太網與CANoe的配置
一文了解工業以太網交換機






 工商網監
工商網監
評論