 自然語言常用的自回歸解碼方法
自然語言常用的自回歸解碼方法
本文為大家分享自然語言生成中的解碼方法,主要包括兩部分:自回歸生成中常用的解碼方法,以及適用于大模型推理加速的speculative decoding方法。
1.自回歸生成中常用的解碼方法
在生成文本序列時,由于全局搜索整個序列所需的計算成本極高,我們通常使用自回歸生成(autoregressive generation),即逐個生成token,如下圖所示。目前最常用的解碼方法(即選擇token的方法)包括:貪心搜索、波束搜索、top-k采樣和top-p采樣。此外,本文也會介紹通過改變概率分布來控制生成效果的temperature和repetition penalty。

貪心搜索(Greedy Search)
在每個時間步,我們會基于已生成的文本來計算詞表中各詞語的概率分布,最直接的方法就是選擇概率最大的詞。
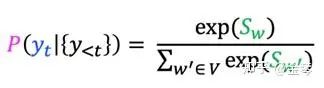
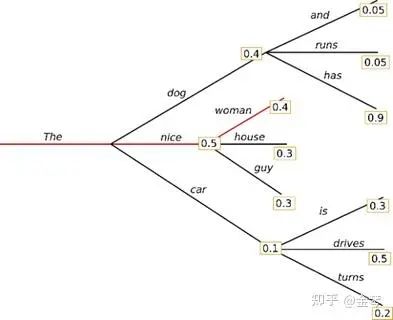
貪心搜索的生成速度很快,短序列看起來效果也還可以,但很快就會出現語言不流暢、重復、缺乏多樣性等問題。其主要問題是可能會忽略那些低概率詞后可能出現的高概率詞。比如在下圖示例中,整體概率更高的序列“The dog has”就被漏掉了。
波束搜索 (Beam search)
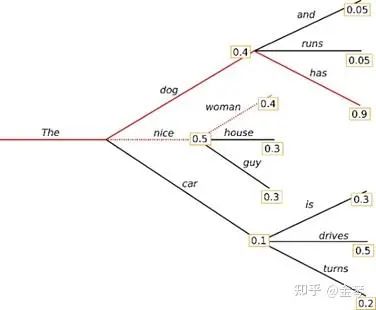
為了解決上述問題,人們引入了波束搜索的方式。也就是在每一步中,都保留概率最高的k個序列,如下圖所示。
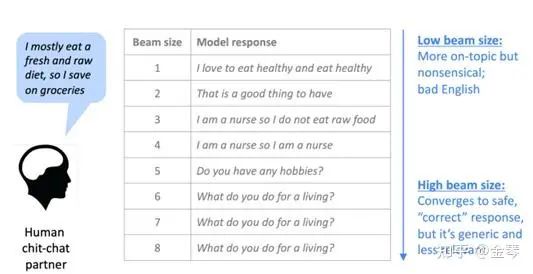
在選擇beam size時,較小的值會使解碼速度更快,但生成的結果可能會出現與貪心搜索類似的問題。較大的值可以緩解這些問題,但計算成本會增加。而且對于對話生成等開放領域任務,較大的beam size還可能會傾向于生成更通用的回復。
總的來說,beam search在機器翻譯、文章摘要等任務中效果較好。但是,由于它仍然是基于最大概率的方法,所以不適用于需要多樣性和創造力的開放域任務。
Top-K采樣 (Top-K sampling)
為了使生成的文本更具創新性和多樣性,人們在選擇token的策略中引入了一定的隨機性,也就是從一部分詞中進行隨機采樣。最基礎的方法就是top-k采樣,即選擇概率最高的k個詞,基于這些詞的概率分布進行采樣。
在選擇k值時,較大的值會使生成的內容更具多樣性,但可能會生成不合理的內容;較小的值則使生成的內容多樣性較低,但質量更有保證。我們可以根據任務的不同選擇合適的k值。
由于top-k采樣的k值是固定的,不同的概率分布可能會帶來不同的問題。如圖所示,當概率分布較平坦時(上半圖),top-k采樣可能會剔除許多概率相近的合理詞語;而當概率分布較陡峭時(下半圖),可能會保留一些概率很低的不合理詞語。因此,我們可以考慮動態調整k值,也就是實施top-p采樣。
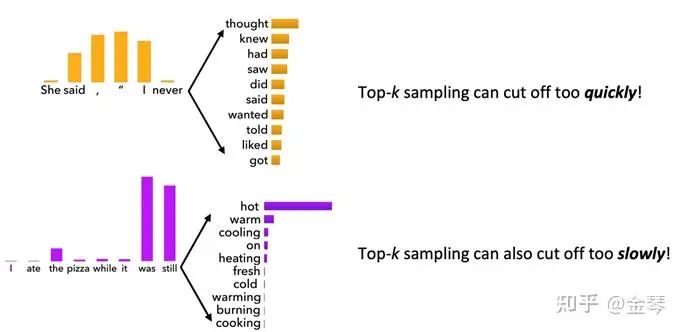
Top-P采樣 (Top-p sampling)
如上文所述,top-p采樣的思路是根據具體的概率分布情況來調整k值的選擇。具體地,從累積概率超過某個閾值 p 的k個詞中進行隨機采樣。基于此,以上討論的兩種問題都能得到解決。

Temperature
除了改變選詞策略,我們還可以通過調整概率分布來改變生成效果,一個常用的思路是在概率分布的Softmax函數中引入Temperature參數(下圖公式中的τ)。
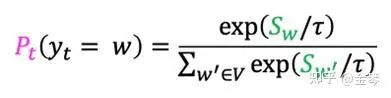
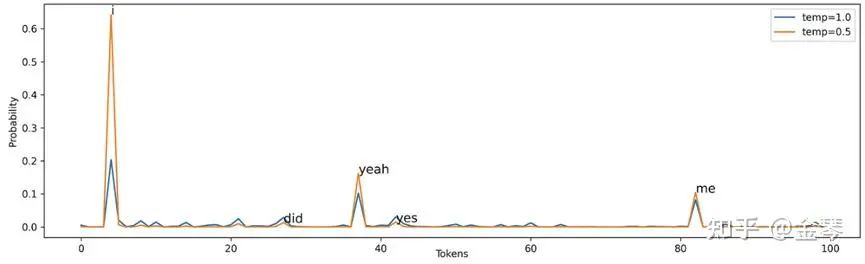
Temperature的取值一般在0-1之間,值越大,概率分布越平緩,生成的序列更具多樣性,適合于需要創造性的任務;值越小,概率分布越陡峭,生成的序列更穩定,適合于需要準確度的任務。
Repetition Penalty
在文本生成中,重復性高是一個常見問題。一個常用的解決方法是降低已生成詞的概率,即在Softmax函數中對已生成的詞額外除以一個θ。一般來說,該值取1.1或者1.2即可。
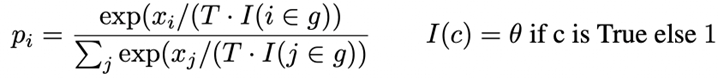
2.Speculative Decoding方法
在大模型的時代,隨著模型參數量增加,生成token所需的訪存時間大大增加,傳統的串行式的自回歸生成方法不再適用。為了提高大模型的推理速度,近年來,許多研究開始關注speculative decoding,一種Draft-then-Verify的解碼方法。如下圖所示,在Draft階段,先用更高效的方式生成長度為k的序列;然后在Verify階段,將該序列輸入大模型,一次性驗證這k個token是否合理,并修改不合理的token。
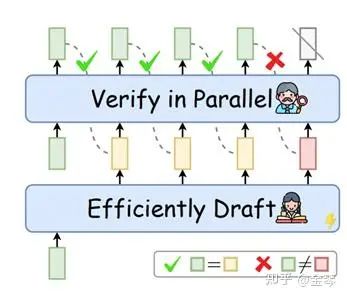
該方法的動機主要源于兩點:(1)序列中的許多簡單詞可以用更有效、更簡單的方法生成。例如,在以下序列"Geoffrey Hinton did his PhD at the University of Edinburgh."中,"of"很容易判斷,我們完全可以使用1B的模型來代替100B的模型;(2)傳統自回歸生成的推理過程主要受限于訪存速度,即生成每個token時都需要等待LLM的參數讀寫。使用draft-then-verify的思路,雖然目標大模型的計算量沒變,但是內存訪問時間大大降低了。

為了更清晰地展示speculative decoding的過程,我們以下圖為例。在每一步,Draft階段會生成5個token,綠色的是目標模型確認的token,紅色是目標模型第一個拒絕的token,藍色是經過修正的token(注意,第一個被拒絕的token之后的所有token都將被丟棄)。比如第一步,Draft階段生成了5個token,目標模型接受輸入 "[START] Japan ’ s benchmark bond",計算每個token位置對應的概率分布,然后拒絕了 "bond",并基于概率分布采樣,將其改為 "n"。

可以發現,在Speculative Decoding中有三部分具體策略:(1)Draft策略,例如使用更小的、與目標模型分布接近的模型進行自回歸生成;(2)Verify策略,例如判斷候選詞是否是目標模型中概率最大的詞;(3)Correct策略,例如使用greedy decoding或者contrastive decoding。近期關于speculative decoding的綜述 [3] 中對不同的方法進行了詳細的總結。


總結
本文總結了最常用的自回歸解碼方法。進行自回歸文本生成時,大家可以根據各方法的原理調整參數。此外,本文介紹了一種提升解碼效率 (efficiency) 的方法,即speculative decoding方法。除此之外,還可以從提升解碼質量(quality)、可控性 (controllability)、多樣性 (diversity)、可信度 (faithfulness) 等方面繼續進行相關研究探索。
審核編輯:黃飛
-
自然語言
+關注
關注
1文章
291瀏覽量
13396 -
大模型
+關注
關注
2文章
2543瀏覽量
3111
原文標題:自然語言生成中的解碼方法匯總
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自然語言處理怎么最快入門?
【推薦體驗】騰訊云自然語言處理
深度視頻自然語言描述方法

什么是自然語言處理_自然語言處理常用方法舉例說明

自然語言處理怎么最快入門_自然語言處理知識了解
自然語言處理方法和應用
自然語言處理的ELMO使用






 工商網監
工商網監
評論