 英偉達2024年GTC人工智能大會看點,黃仁勛發布最炸裂的B200 GPU,講述人工智能奇跡
英偉達2024年GTC人工智能大會看點,黃仁勛發布最炸裂的B200 GPU,講述人工智能奇跡
2024年GTC人工智能大會,和過去一樣,黃仁勛,這位穿黑色皮夾克的男人用兩個小時講述了人工智能的奇跡,發布最炸裂的B200 GPU,以及讓人工智能唱歌跳舞的下一代硬件和軟件技術。
JAEALOT
2024年3月19日
2024年GTC人工智能大會,黃仁勛向一群崇拜的技術人員和投資者發表了現場主題演講。和過去一樣,這位穿黑色皮夾克的男人用兩個小時講述了人工智能的奇跡,以及讓人工智能唱歌跳舞的下一代硬件和軟件技術。
老黃的主題演講從公司過去二十年左右的歷程開始。不得不說,英偉達二十年左右發展成今天人工智能的領頭羊,是非常了不起的。
接著便是本次大會的重磅產品,Blackwell B200 GPU,號稱是如今世界上最強大的AI芯片。
在這里,我們可以看到一個 Arm CPU,兩側是 DRAM 封裝,以及兩個相連的下一代 GPU。在此圖中,每個 Blackwell GPU 似乎都有八個 HBM 包和兩個計算芯片。
這是Blackwell GPU芯片和Hopper H100芯片的尺寸比較。
這是兩款芯片的特寫照,濃縮就是精華~不斷超越摩爾定律,開始自己的老黃定律。
NVIDIA 為現有 DGX/HGX 系統提供 Blackwell GPU 設計,DGX B100 和 HGX B100 適用于 x86 服務器。它的設計功率約為 700W,因此可以在現有系統中工作。
NVIDIA Blackwell HGX B100
這是 NVIDIA Grace Blackwell,配有兩Blackwell GPU 和一個 Grace CPU,每個 CPU 都有內存。板卡頂部有 NVLink,板卡底部有 PCIe。

NVIDIA Grace Blackwell GB200 生產板
這就是未來的 Arm 和 NVIDIA。下面是開發板,上面是生產板。

NVIDIA Grace Blackwell 開發板
以下是配備 192GB HBM3e 的 Blackwell GPU 的規格,聽起來像是 8x 8-hi HBM 堆棧。

還有一些新功能,例如可以處理 FP4 和 FP6 的新變壓器引擎。第五代 NVLink、RAS、安全 AI 和解壓縮引擎。

FP4 和 FP6 比 Hopper 增加了大量性能。

NVIDIA 還發布了 ConnectX-8 / ConnectX-800G Infiniband。800GBps 網絡已經到來,所以這必須是 PCIe Gen6。

NVIDIA ConnectX 8
有趣的是,NVIDIA 仍在使用 BlueField-3 DPU,而不是新一代。考慮到其他所有內容都進行了修訂,這感覺很奇怪。
這是 800Gbps NVIDIA Quantum Infiniband 交換機。

800Gbps NVIDIA 量子交換機
這是新的 NVLink 開關芯片。這是一件大事,因為業內其他公司沒有這樣的擴展解決方案。

NVLink開關芯片
這是新的 NVIDIA DGX GB200 NVL72。通過 NVLink 連接 72 個 Blackwell GPU。

NVIDIA GB200 72 Blackwell GPU 通過 NVLink 完全連接
這是一款液冷且支持 NVLink 的 DGX。這比當前的 DGX 系統大得多。這大約是120kW。

NVIDIA DGX GB200 NVL72
這是使用銅的 NVLink 主干,可節省約 20kW 的功率。

NVIDIA DGX GB200 NVL72 NVLink Spine 不帶光學器件
NVIDIA GB200 機箱中還有帶有兩個 GB200 復合體的交換機。

NVIDIA GB200 內部 NVLink 開關
以下是 NVIDIA Blackwell 計算節點的概述。

NVIDIA Blackwell 計算節點
以下是 GPU 對 Pascal 性能的影響。為了實現這一目標,NVIDIA 做了很多事情,例如添加張量核心、改變精度等,此外還縮小了工藝并在芯片上塞進了更多晶體管。
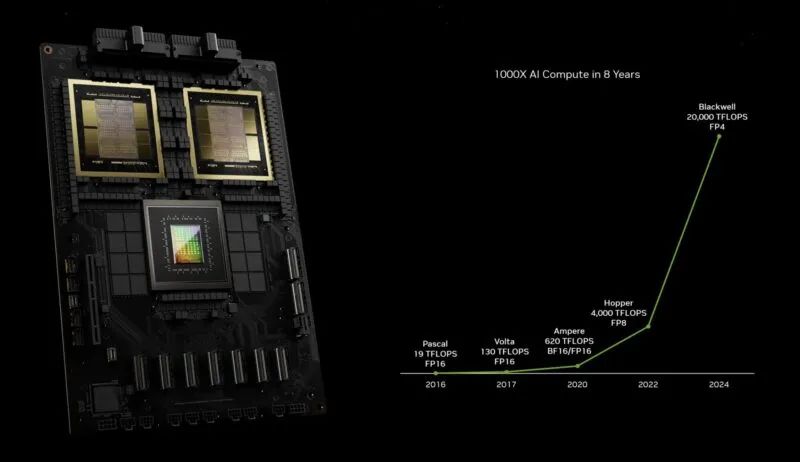
NVIDIA Pascal 到 Blackwell 的 AI 計算擴展
NVIDIA 表示,由于采用了新的 NVSwitch 和新的 FP4 變壓器引擎,Blackwell 的性能大約是 Hopper 的 30 倍。紫色線是如果 NVIDIA 建造一個更大的帶有更多晶體管的 Hopper 時會發生的情況。
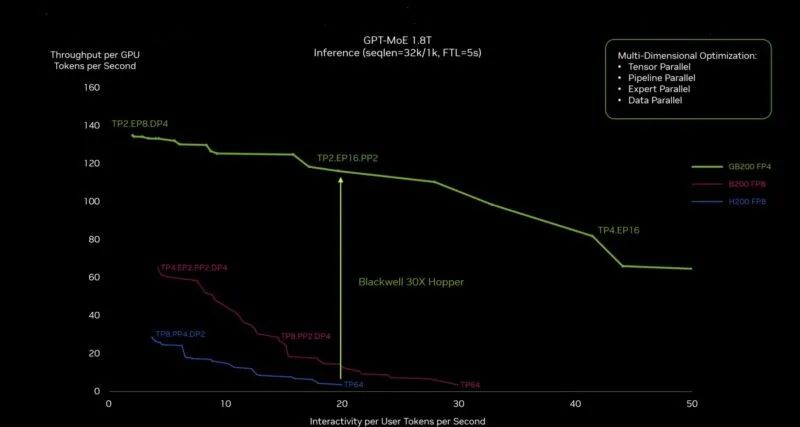
NVIDIA Blackwell To Hopper 推理性能
如果您是另一家生產與 NVIDIA 規模相當的人工智能加速器的公司,這應該會讓您感到緊張。AWS、Google、Microsoft 和 OEM/ODM 都是 Blackwell 的客戶。
NVIDIA 剛剛展示了 Apple Vision Pro 在 Omniverse 中的工作情況。這將為蘋果打開一個巨大的市場。
Apple Vision Pro 和 NVIDIA Omniverse
NVIDIA 正在將預先訓練的模型與依賴項打包在一起,并使其能夠輕松部署被稱為 NVIDIA 推理微服務或 NIMS 的微服務。這不僅僅是 CUDA。這使得模型易于實施。
NVIDIA 推理微服務 NIMS
NVIDIA 將幫助公司和應用程序微調模型或定制模型。
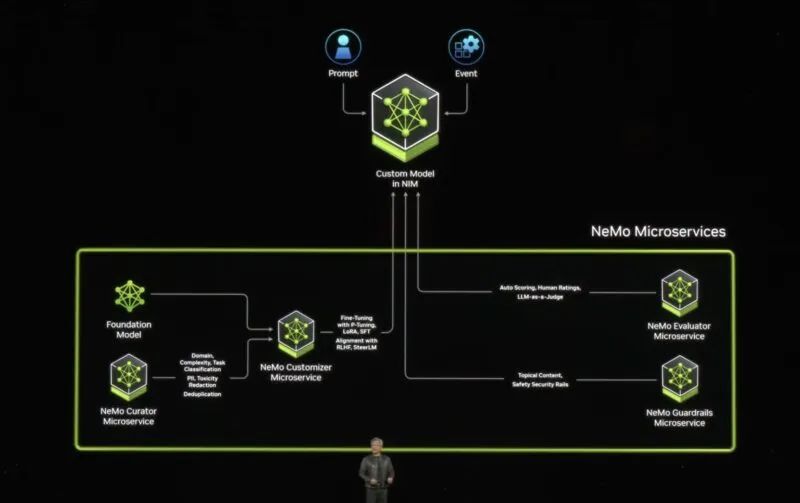
NVIDIA NeMo 微服務
借助 NVIDIA DGX Cloud,NVIDIA 希望成為 AI 代工廠,或者像臺積電一樣成為 AI 代工廠。
NVIDIA Drive Thor 將被比亞迪等公司采用。
NVIDIA 驅動雷神
NVIDIA Jetson Thor 用于更新 NVIDIA Jetson Orin 的機器人。NVIDIA 的一大賭注是下一代能夠控制人形機器人。NVIDIA 也正在為此構建一個軟件堆棧。
適用于人形機器人的 NVIDIA Jeton Thor
世界是為人類而生,因此英偉達試用 NVIDIA Thor 和 NVIDIA Project GR00T 軟件來訓練和管理新型人形機器人。
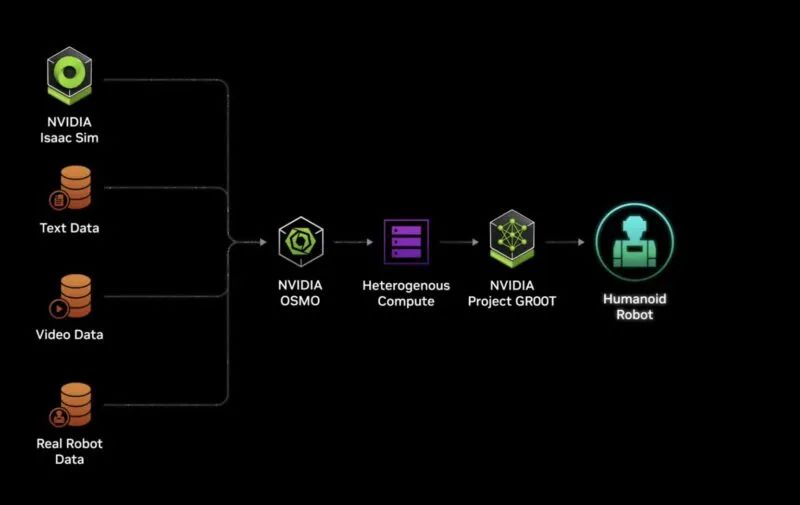
英偉達GR00T
老黃帶著由該公司提供支持的人形機器人登上舞臺,其中包括來自迪士尼的小型機器人,它們在 NVIDIA Isaac SIM 中學習行走。

NVIDIA GR00T 和機器人
NVIDIA 正試圖通過機器人技術架起數字世界與物理世界的橋梁。從公司的數據中心產品一路走到邊緣。這就是本次 GTC 2024的愿景。
-
gpu
+關注
關注
28文章
4767瀏覽量
129208 -
人工智能
+關注
關注
1794文章
47622瀏覽量
239584 -
英偉達
+關注
關注
22文章
3839瀏覽量
91669
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論