 為什么GD32F303代碼運行在flash比sram更快?
為什么GD32F303代碼運行在flash比sram更快?
我們知道一般MCU的flash有等待周期,隨主頻提升需要插入flash讀取的等待周期,以stm32f103為例,主頻在72M時需要插入2個等待周期,故而代碼效率無法達到最大時鐘頻率。

所以STM32F103將代碼加載到sram運行速度更快。
但使用GD32F303時將代碼加載到SRAM后速度反而下降了一些,這是為什么呢?
我們前面了解過GD32F303 flash的code area區是零等待的,GD32F系列MCU片上Flash中Code區和Data區使用解密
零等待訪問理論上就應該和在sram運行速度一樣,那么為何會比sram更快一些呢?
通過查閱GD32F303用戶手冊系統架構章節我們可以知道,訪問flash時可以直接通過ibus和sbus專用總線進行訪問,而訪問sram時通過AHB主機接口通過System BUS進行訪問,AHB主機接口下更還有掛載有其他主機和外設總線,共享總線帶寬。
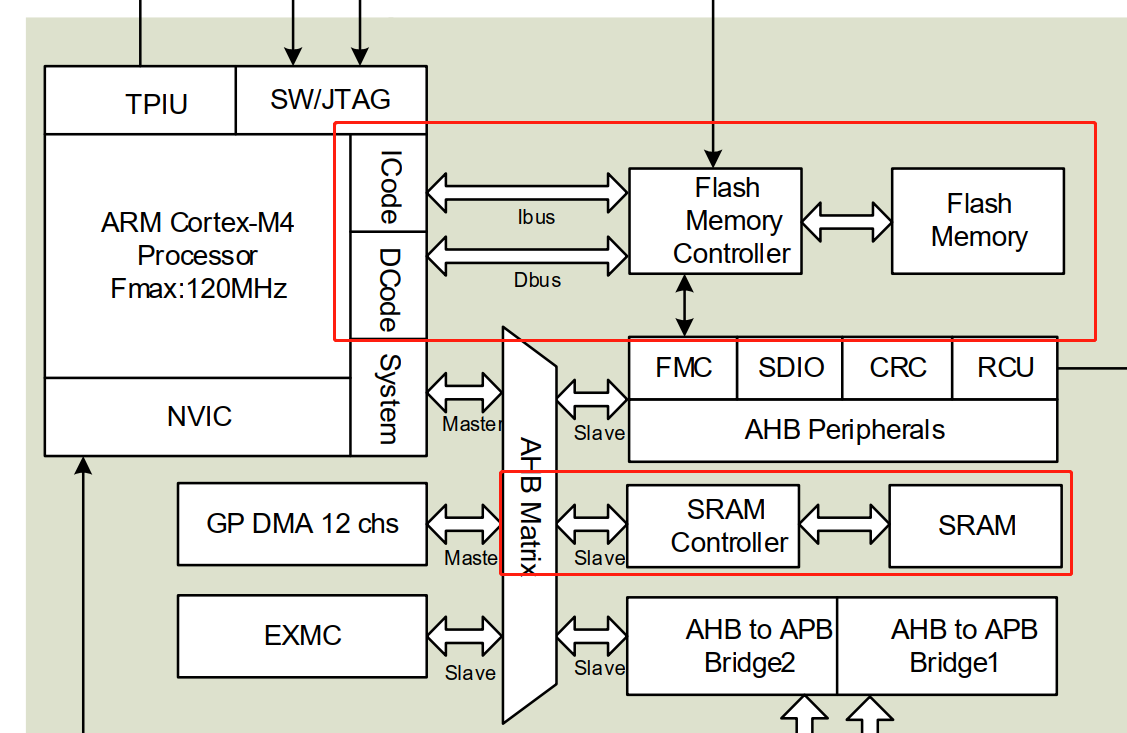
所以GD32F303的代碼運行在code area零等待區時,效率會比常規加載sram的方式更高。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
單片機
+關注
關注
6042文章
44617瀏覽量
637540 -
嵌入式
+關注
關注
5090文章
19176瀏覽量
306886 -
sram
+關注
關注
6文章
768瀏覽量
114820 -
GD32
+關注
關注
7文章
413瀏覽量
24429
發布評論請先 登錄
相關推薦


【GD32F303】星空派介紹
GD32官方資料的基礎上,提供GD32F303的庫函數開發資料、例程講解、視頻課程等。同時還提供RT-Thread相關的驅動開發、應用開發、移植等相關例程。(1)提供20多個基于GD官方標準庫的
發表于 09-11 17:55
星空派GD32F303開發板的相關資料下載
一、開發板介紹星空派(GD)開發板是由旗點科技推出的一款GD32開發板,板載GD32F303ZET6芯片,支持RT-Thread操作系統等,支持WiFi、4G、loRa等物聯通信接口。板載Fl
發表于 12-10 08:27
在GD32f303工程里使用獨立看門狗
在使用rt-thread studio建立GD32f303工程(使用board里面的f303代碼模板)。建立完畢后,使用Fwdt(獨立看門狗)的時候,在庫文件里面缺少
發表于 07-05 11:22
AN029 GD32F103程序在GD32F303和GD32F403芯片上運行DSP
AN029 GD32F103程序在GD32F303和GD32F403芯片上運行DSP
發表于 02-27 18:33
?0次下載

GD32F303固件庫開發
/qq_24312945/article/details/124325797] GD32F303固件庫開發(2)----讀保護與寫保護 芯片讀保護以后,flash將不可以從外部讀取,這樣可以防止別人讀取或者盜取芯片代碼,如果想再

STM32CUBEMX開發GD32F303(17)----內部Flash讀寫
本章STM32CUBEMX配置STM32F103,并且在GD32F303中進行開發,同時通過開發板內進行驗證。
本例程主要講解如何對芯片自帶Flash進行讀寫,用芯片內部Flash可

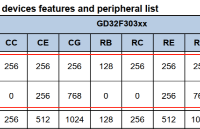
GD32F303為什么啟動慢?
在MCU開發中,有一項非常重要的參數——MCU啟動時間,即MCU上電后到程序開始運行這段時間。我們來看下GD32F303的datasheet中對啟動時間的描述:
【GD32F303紅楓派開發板使用手冊】第五講 FMC-片內Flash擦寫讀實驗
MC即Flash控制器,其提供了片上Flash操作所需要的所有功能,在GD32F303系列MCU中,Flash前256K字節空間內,?CPU執行指令零等待,具有相同主頻下最快的
【GD32F303紅楓派開發板使用手冊】第二十講 SPI-SPI NAND FLASH讀寫實驗
通過本實驗主要學習以下內容:
?SPI通信協議,參考19.2.1東方紅開發板使用手冊
?GD32F303 SPI操作方式,參考19.2.2東方紅開發板使用手冊
?NAND FLASH基本原理
?SPI NAND介紹
?使用GD32F
【GD32 MCU 移植教程】2、從 GD32F303 移植到 GD32F503
GD32E503 系列是 GD 推出的 Cortex_M33 系列產品,該系列資源上與 GD32F303 兼容度非常高,本應用筆記旨在幫助您快速將應用程序從 GD32F303 系列微控





 工商網監
工商網監
評論