

2. 引言
這篇論文提出了一種創(chuàng)新的3D室內(nèi)場景分割方法,這在增強現(xiàn)實、機器人技術(shù)等領(lǐng)域是一個關(guān)鍵的任務(wù)。該任務(wù)的核心是從多種3D場景表現(xiàn)形式(如網(wǎng)格或點云)中預(yù)測3D物體掩膜。歷史上,傳統(tǒng)方法在分割訓(xùn)練過程中未遇到的新物體類別時常常遇到困難,這限制了它們在陌生環(huán)境中的有效性。
最近的進展,如Segment Anything Model(SAM),在2D圖像分割方面顯示出潛力,能夠在無需額外訓(xùn)練的情況下分割陌生的圖像。本文探討了將SAM原理應(yīng)用于3D場景分割的可能性,具體研究了是否可以直接將SAM應(yīng)用于2D幀,以分割3D場景,而無需額外訓(xùn)練。這一探索基于SAM的一個獨特特點:它的提示功能,即它接受各種輸入類型來指定圖像中的分割目標。
作者指出了一個關(guān)鍵挑戰(zhàn):確保同一3D物體在不同幀中的2D分割的一致性。他們觀察到,像SAM3D這樣的現(xiàn)有方法,它將自動化SAM應(yīng)用于單個幀,但在不同幀中存在不一致性,導(dǎo)致3D分割效果不佳。另一種方法,SAM-PT,在視頻跟蹤中效果顯著,但在3D場景中失敗,因為物體并非始終出現(xiàn)在所有幀中。
為了應(yīng)對這些挑戰(zhàn),論文提出了一個名為SAMPro3D的新框架,該框架在輸入場景中定位3D點作為SAM提示。這些3D提示被投影到2D幀上,確保了跨幀一致的像素提示和相應(yīng)的掩膜。這種方法確保了同一3D物體在不同視角下的分割掩膜的一致性。
SAMPro3D首先初始化3D提示,使用SAM在各個幀中生成相應(yīng)的2D掩膜。然后,它根據(jù)所有幀中相應(yīng)掩膜的質(zhì)量過濾3D提示,優(yōu)先選擇在所有視圖中都能產(chǎn)生高質(zhì)量結(jié)果的提示。為了解決部分物體分割的問題,該框架合并了重疊的3D提示,整合信息以實現(xiàn)更全面的分割。SAMPro3D累積跨幀的預(yù)測結(jié)果,以得出最終的3D分割。值得注意的是,該方法不需要額外的領(lǐng)域特定訓(xùn)練或3D預(yù)訓(xùn)練網(wǎng)絡(luò),這保持了SAM的零樣本能力,是之前方法所不具備的顯著優(yōu)勢。
該論文通過廣泛的實驗驗證了SAMPro3D的有效性,展示了它在實現(xiàn)高質(zhì)量和多樣化分割方面的能力,通常甚至超過了人類級別的標注和現(xiàn)有方法。此外,它還展示了在2D分割模型(如HQ-SAM和Mobile-SAM)中的改進可以有效地轉(zhuǎn)化為改進的3D結(jié)果。這篇論文為3D室內(nèi)場景分割引入了一種開創(chuàng)性的方法,巧妙地利用了2D圖像分割模型的能力,并將其創(chuàng)新地應(yīng)用于3D領(lǐng)域。結(jié)果是一種強大的、零樣本的分割方法,顯著推進了3D視覺理解領(lǐng)域的最新發(fā)展。
3. 方法
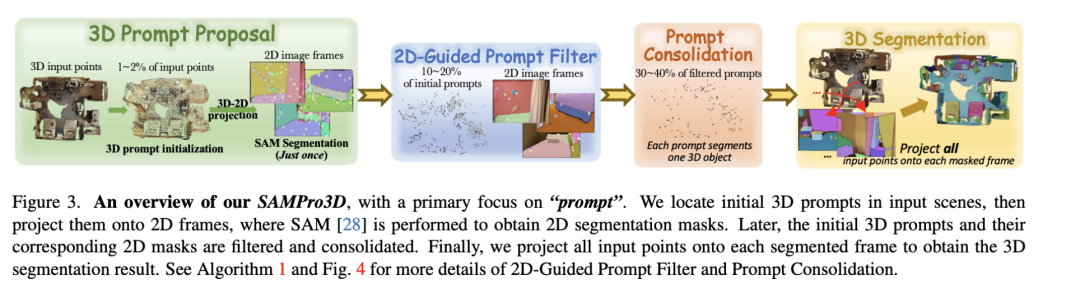
本文提出的方法名為SAMPro3D,旨在直接應(yīng)用Segment Anything Model (SAM) 對室內(nèi)場景的3D點云及其關(guān)聯(lián)的2D幀進行零樣本3D場景分割。
3D Prompt Proposal
首先,針對一個3D場景的點云 ,包含 個點,我們使用最遠點采樣(Furthest-Point Sampling, FPS)從中采樣 個點作為初始3D提示 。FPS幫助我們實現(xiàn)了場景中物體的良好覆蓋。簡化地,我們用 和 分別表示單個輸入點和一個3D提示。
接著,我們僅考慮針孔相機配置。具體來說,給定幀 的相機內(nèi)參矩陣 和世界到相機的外參矩陣 ,我們通過以下公式計算點提示 的對應(yīng)像素投影 :
其中, 和 分別是 和 的齊次坐標。我們通過深度值執(zhí)行遮擋測試,以確保當且僅當點 在幀 中可見時,像素 才有效。
然后,在圖像幀上執(zhí)行SAM分割。SAM能接受像素坐標、邊界框或掩膜等多種輸入,并預(yù)測與每個提示相關(guān)的分割區(qū)域。在我們的框架中,我們將所有計算出的像素坐標用于提示SAM,并在所有幀上獲取2D分割掩膜。通過在3D空間中定位提示,源自不同幀但由同一3D提示投影的像素提示將在3D空間中對齊,從而帶來幀間一致性。
2D-Guided Prompt Filter

在之前的提示初始化過程中,某些提示可能會生成低質(zhì)量且冗余的掩膜,這將降低最終結(jié)果的質(zhì)量。為解決這個問題,我們引入了一個機制來“收集所有幀的反饋”。我們首先采用自動化SAM提出的策略在每個單獨的幀上過濾提示。基本上,這種策略會消除那些對應(yīng)掩膜置信度低或與其他掩膜重疊度大的提示。如果一個3D提示 在某幀中有有效的像素投影 ,則它的計數(shù)器 會增加。如果該提示在該幀的過濾階段成功存活,則它的得分 會累積。在評估所有幀后,我們計算保留一個3D提示的概率 ,并在其概率超過預(yù)定義閾值 時保留該提示。這個算法使我們能夠通過考慮所有2D視圖的反饋來"讓所有幀都滿意"。它優(yōu)先選擇高質(zhì)量的提示,同時在幀間保持提示的一致性,最終提升3D分割結(jié)果。
Prompt Consolidation
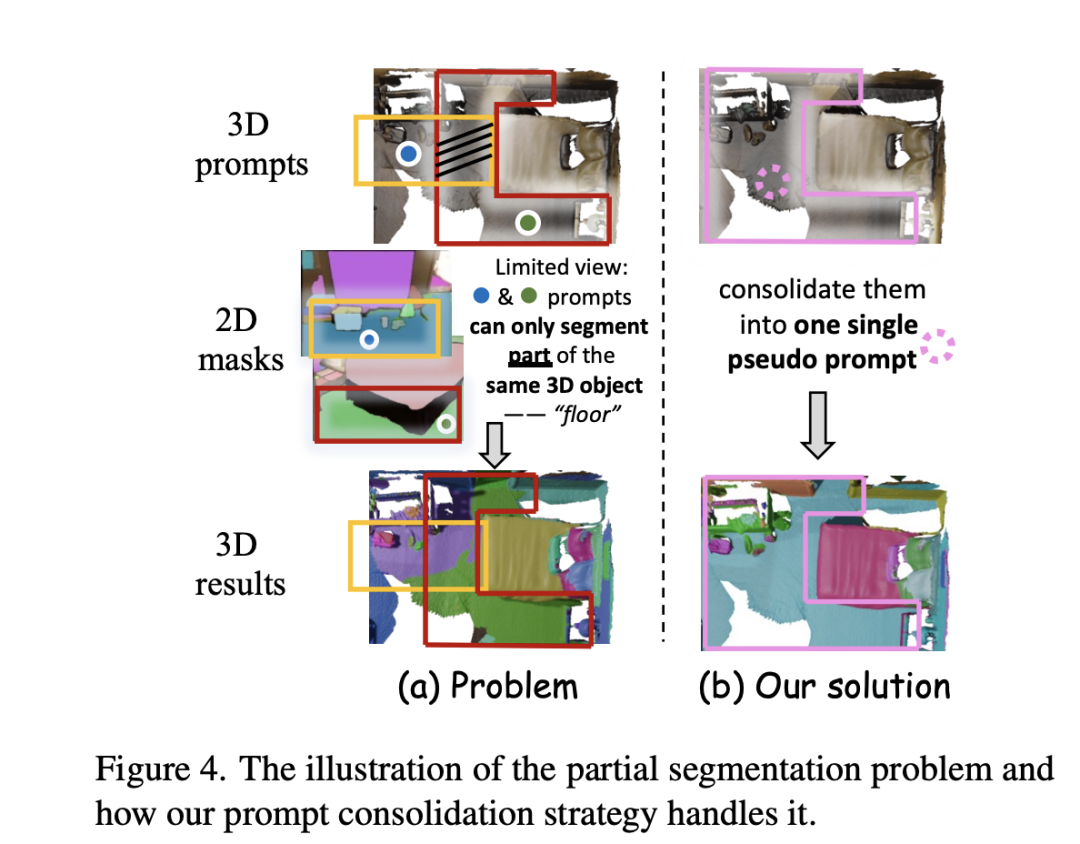
有時,由單個3D提示對齊的2D掩膜可能只分割了對象的一部分,因為2D幀的覆蓋范圍有限。為解決這個問題,我們設(shè)計了一個提示合并策略。該策略涉及檢查不同3D提示生成的掩膜,并識別它們之間的一定重疊。在這種情況下,我們認為這些提示可能正在分割同一個對象,并將它們合并為單個偽提示。這個過程促進了提示間信息的整合,導(dǎo)致更全面的對象分割。
3D Scene Segmentation
在前面的步驟之后,我們獲得了最終的3D提示集合及其在幀間的2D分割掩膜。此外,我們還確保了每個3D對象由單個提示分割,允許提示ID自然地作為對象ID。
為了分割3D場景中的所有點,我們繼續(xù)將 extit{所有}場景輸入點投影到每個分割幀上,并使用以下步驟計算它們的預(yù)測:對于場景中的每個單獨輸入點 ,如果它被投影到幀 中由提示 分割的掩膜區(qū)域內(nèi),我們將其在該幀中的預(yù)測指定為提示ID 。我們累積 在所有幀中的預(yù)測,并根據(jù)最多次分配給它的提示ID確定其最終預(yù)測ID。通過對所有輸入點重復(fù)此過程,我們可以實現(xiàn)輸入場景的完整3D分割。
4. 實驗
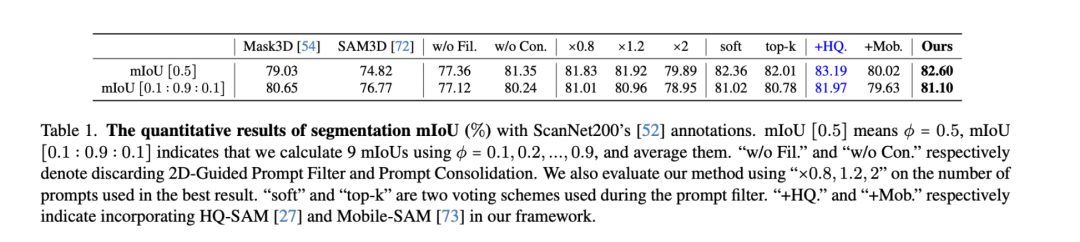
從這個表格中提供的實驗數(shù)據(jù)中,我們可以得出一些結(jié)論關(guān)于3D室內(nèi)場景分割性能。這些數(shù)據(jù)基于ScanNet200數(shù)據(jù)集的標注,評價指標是mIoU(mean Intersection over Union),一個常用的衡量圖像分割效果的指標。
與其他方法的比較:在mIoU 和mIoU 這兩個指標上,我們的方法與其他兩個主要對比方法Mask3D和SAM3D相比,表現(xiàn)更優(yōu)。特別是在mIoU 上,我們的方法達到了82.60%,高于Mask3D的79.03%和SAM3D的74.82%。
過濾和合并提示的重要性:不使用2D引導(dǎo)的提示過濾(w/o Fil.)和不使用提示合并(w/o Con.)的情況下,性能有所下降,這表明這兩個步驟對于最終的分割效果是重要的。
提示數(shù)量的影響:在不同數(shù)量的提示下(即 ),我們的方法表現(xiàn)出相對穩(wěn)定的性能,其中使用時性能最佳。
投票機制的影響:在提示過濾時使用的兩種不同投票機制(soft和top-k)中,soft策略略優(yōu)于top-k策略,尤其是在mIoU 指標上。
增強SAM的作用:引入HQ-SAM(+HQ.)和Mobile-SAM(+Mob.)后,可以觀察到性能提升,尤其是HQ-SAM,它在mIoU 指標上達到了83.19%,顯示了進一步優(yōu)化SAM模型在3D室內(nèi)場景分割中的潛力。
這些實驗結(jié)果表明,本文提出的方法在3D室內(nèi)場景分割任務(wù)上具有強大的性能,尤其是在采用2D引導(dǎo)的提示過濾和提示合并策略,以及進一步增強SAM模型時。此外,這些結(jié)果還揭示了不同提示數(shù)量和投票機制對性能的影響,以及優(yōu)化3D提示的潛力。
5. 討論
這篇論文在3D室內(nèi)場景分割領(lǐng)域提出了一種創(chuàng)新的方法,展示了顯著的性能提升,尤其是在處理具有挑戰(zhàn)性的零樣本場景時。其主要優(yōu)勢在于有效地利用了Segment Anything Model(SAM),通過一系列精心設(shè)計的步驟,如3D提示提議、2D引導(dǎo)的提示過濾和提示合并策略,來改善3D場景的分割效果。這種方法充分利用了SAM在2D圖像分割領(lǐng)域的強大能力,并巧妙地將其擴展到3D場景,顯示了跨領(lǐng)域應(yīng)用的巨大潛力。
特別是,該方法通過3D提示的初始化和精確過濾,確保了3D分割的精度和一致性。此外,通過集成HQ-SAM和Mobile-SAM,該方法進一步提升了其性能,顯示了在不斷發(fā)展的深度學(xué)習(xí)領(lǐng)域中,通過集成新技術(shù)以適應(yīng)更復(fù)雜應(yīng)用場景的重要性。
然而,該方法也存在一些潛在的限制。首先,盡管實驗結(jié)果表明該方法在多個指標上表現(xiàn)出色,但它依賴于SAM模型,這可能限制了其在沒有大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)時的適用性。此外,3D提示的初始化和過濾策略雖然有效,但可能需要顯著的計算資源,尤其是在處理大規(guī)模或復(fù)雜的3D場景時。此外,該方法的泛化能力尚需在更多不同類型的3D場景中進行測試和驗證。
綜上所述,盡管這篇論文在3D室內(nèi)場景分割方面取得了顯著進展,但其依賴于特定的深度學(xué)習(xí)模型和可能需要較高計算資源的處理流程,這些因素可能會影響其在實際應(yīng)用中的廣泛可行性。
6. 結(jié)論

總的來說,這篇論文提出了一種創(chuàng)新且有效的方法,用于提升3D室內(nèi)場景分割的準確度和效率。其通過集成先進的2D圖像分割模型并將其擴展到3D領(lǐng)域,展示了顯著的性能提升。盡管存在一些潛在的限制,如對預(yù)訓(xùn)練數(shù)據(jù)的依賴和高計算資源需求,但這項工作無疑為3D視覺理解領(lǐng)域帶來了新的見解和方法。
審核編輯:黃飛
-
機器人
+關(guān)注
關(guān)注
212文章
29080瀏覽量
210409 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18146 -
增強現(xiàn)實
+關(guān)注
關(guān)注
1文章
719瀏覽量
45235
原文標題:三維場景零樣本分割新突破:SAMPro3D技術(shù)解讀
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
三維觸控技術(shù)突破“二向箔”的束縛
三維快速建模技術(shù)與三維掃描建模的應(yīng)用
Handyscan三維掃描儀機械零部件三維掃描抄數(shù)服務(wù)
SMARTSCAN三維掃描儀電子產(chǎn)品配件三維掃描服務(wù)
基于Creator的三維場景優(yōu)化技術(shù)的應(yīng)用
三維立體視覺技術(shù)的應(yīng)用及其三維恢復(fù)方法介紹
3D動畫技術(shù)在計算機三維技術(shù)中實現(xiàn)了不斷發(fā)展
3D三維可視化虛擬現(xiàn)實技術(shù)應(yīng)用于玉雕器皿
3D建模技術(shù)以及智能家具三維模型的展示
基于聚類分析的三維網(wǎng)格分割技術(shù)綜述

工業(yè)工廠3D沉浸式三維數(shù)字化管理系統(tǒng)
基于三維集成技術(shù)的紅外探測器
彩色3D打印仕女圖三維掃描數(shù)字化3d打印

什么是零樣本學(xué)習(xí)?為什么要搞零樣本學(xué)習(xí)?
3D ToF三維場景距離(景深)測量系統(tǒng)簡介






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論