 32位4GB系統訪問2GB數據,虛擬內存會發生什么?
32位4GB系統訪問2GB數據,虛擬內存會發生什么?
單核可以多線程嗎?
可以的。
單核創建了多線程,CPU 會從一個進程快速切換至另一個進程,其間每個進程各運行幾十或幾百個毫秒,雖然單核的 CPU 在某一個瞬間,只能運行一個進程。但在 1 秒鐘期間,它可能會運行多個進程,這樣就產生并行的錯覺,實際上這是并發。
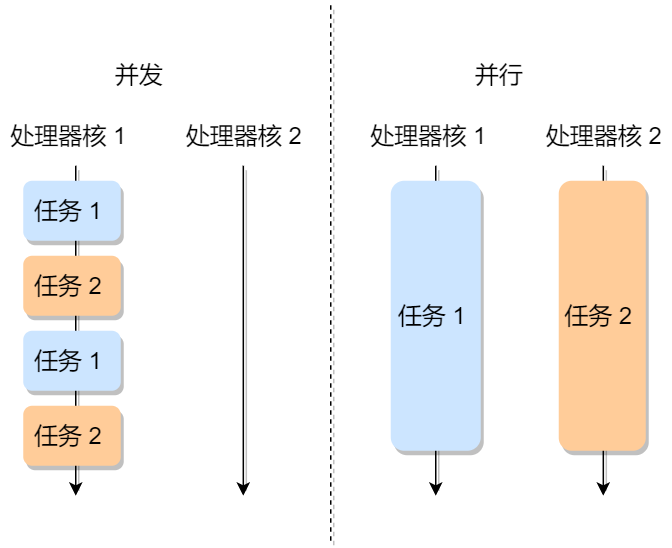
并發與并行
虛擬地址怎么找到對應的內容的?
操作系統內存管理方式主要兩種,不同的管理方式,尋址的實現是不同的:
內存分段:將進程的虛擬地址空間劃分為多個不同大小的段,每個段對應一個邏輯單位,如代碼段、數據段、堆段和棧段。每個段的大小可以根據需要進行調整,使得不同段可以按需分配和釋放內存。虛擬內存分段的優點是可以更好地管理不同類型的數據,但是由于段的大小不一致,容易產生外部碎片。
內存分頁:將進程的虛擬地址空間劃分為固定大小的頁,同時將物理內存也劃分為相同大小的頁框。通過頁表將虛擬地址映射到物理地址,并且可以按需加載和釋放頁。虛擬內存分頁的優點是可以更好地利用物理內存空間,但是可能會產生內部碎片。
分段的尋址方式
分段機制下的虛擬地址由兩部分組成,段選擇因子和段內偏移量。
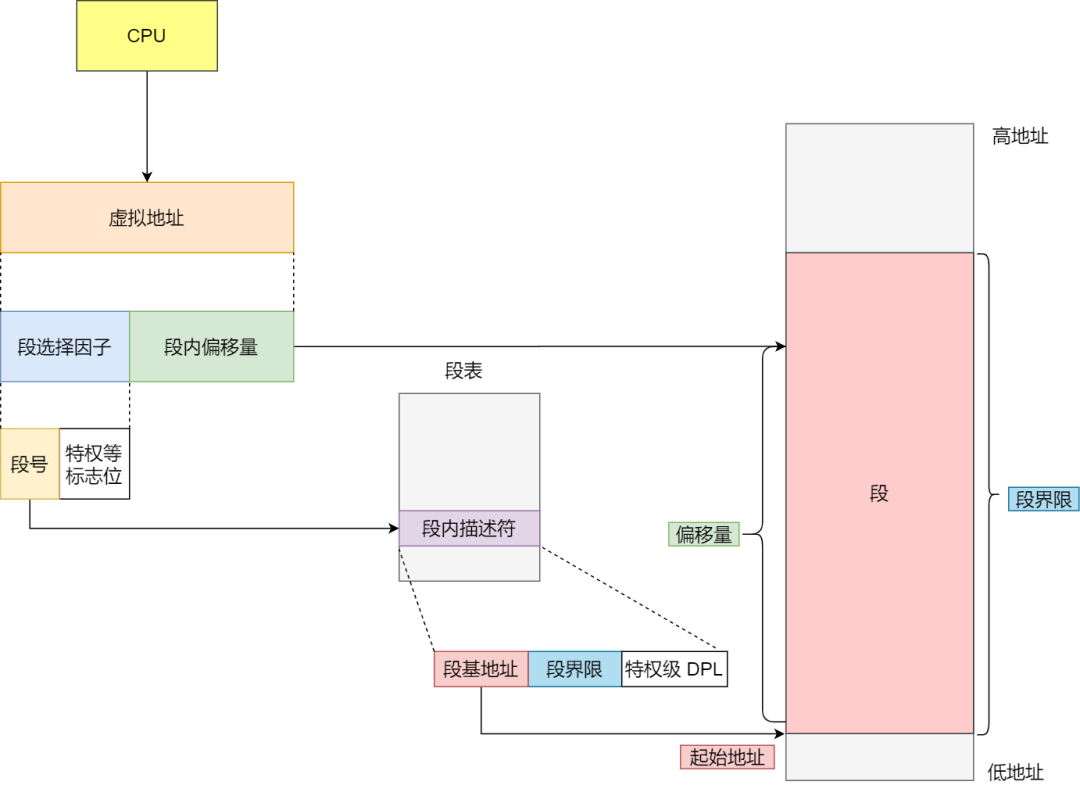
段選擇因子和段內偏移量:
段選擇子就保存在段寄存器里面。段選擇子里面最重要的是段號,用作段表的索引。段表里面保存的是這個段的基地址、段的界限和特權等級等。
虛擬地址中的段內偏移量應該位于 0 和段界限之間,如果段內偏移量是合法的,就將段基地址加上段內偏移量得到物理內存地址。
在上面,知道了虛擬地址是通過段表與物理地址進行映射的,分段機制會把程序的虛擬地址分成 4 個段,每個段在段表中有一個項,在這一項找到段的基地址,再加上偏移量,于是就能找到物理內存中的地址,如下圖:
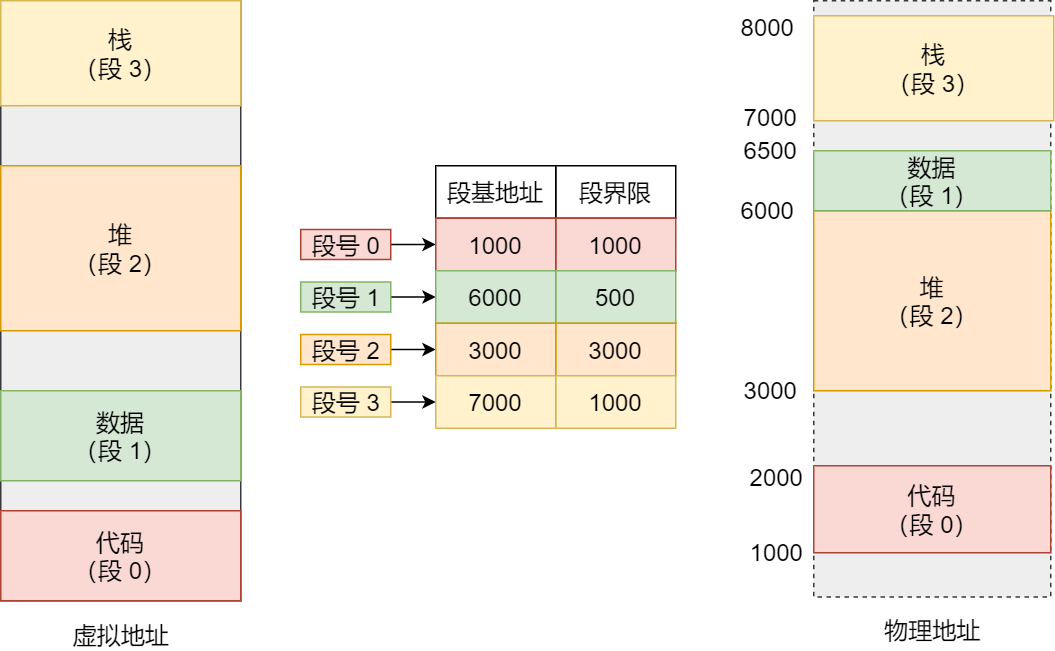
如果要訪問段 3 中偏移量 500 的虛擬地址,我們可以計算出物理地址為,段 3 基地址 7000 + 偏移量 500 = 7500。
分段的辦法很好,解決了程序本身不需要關心具體的物理內存地址的問題,但它也有一些不足之處:
第一個就是內存碎片的問題。
第二個就是內存交換的效率低的問題。
分頁的尋址方式
虛擬地址與物理地址之間通過頁表來映射,如下圖:
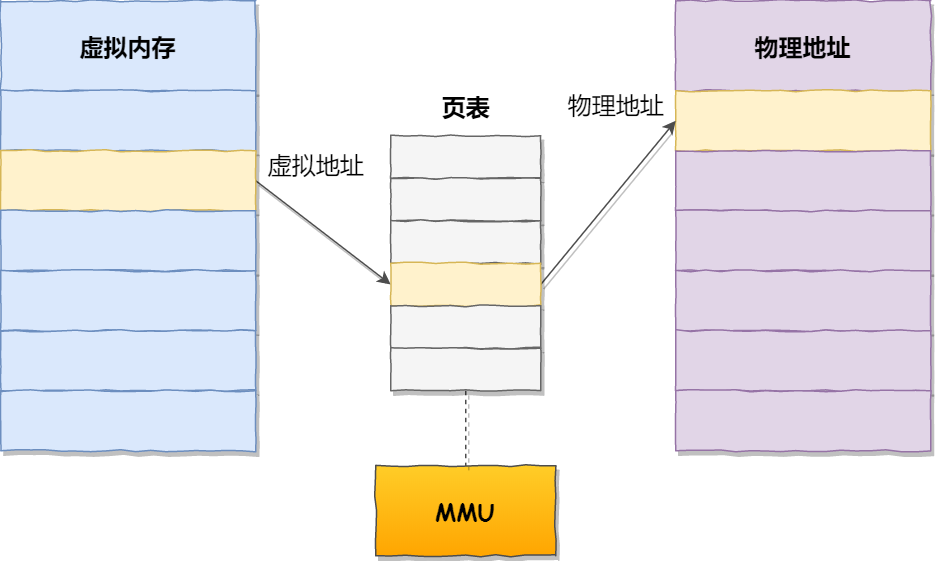
頁表是存儲在內存里的,內存管理單元 (MMU)就做將虛擬內存地址轉換成物理地址的工作。
而當進程訪問的虛擬地址在頁表中查不到時,系統會產生一個缺頁異常,進入系統內核空間分配物理內存、更新進程頁表,最后再返回用戶空間,恢復進程的運行。
在分頁機制下,虛擬地址分為兩部分,頁號和頁內偏移。頁號作為頁表的索引,頁表包含物理頁每頁所在物理內存的基地址,這個基地址與頁內偏移的組合就形成了物理內存地址,見下圖。
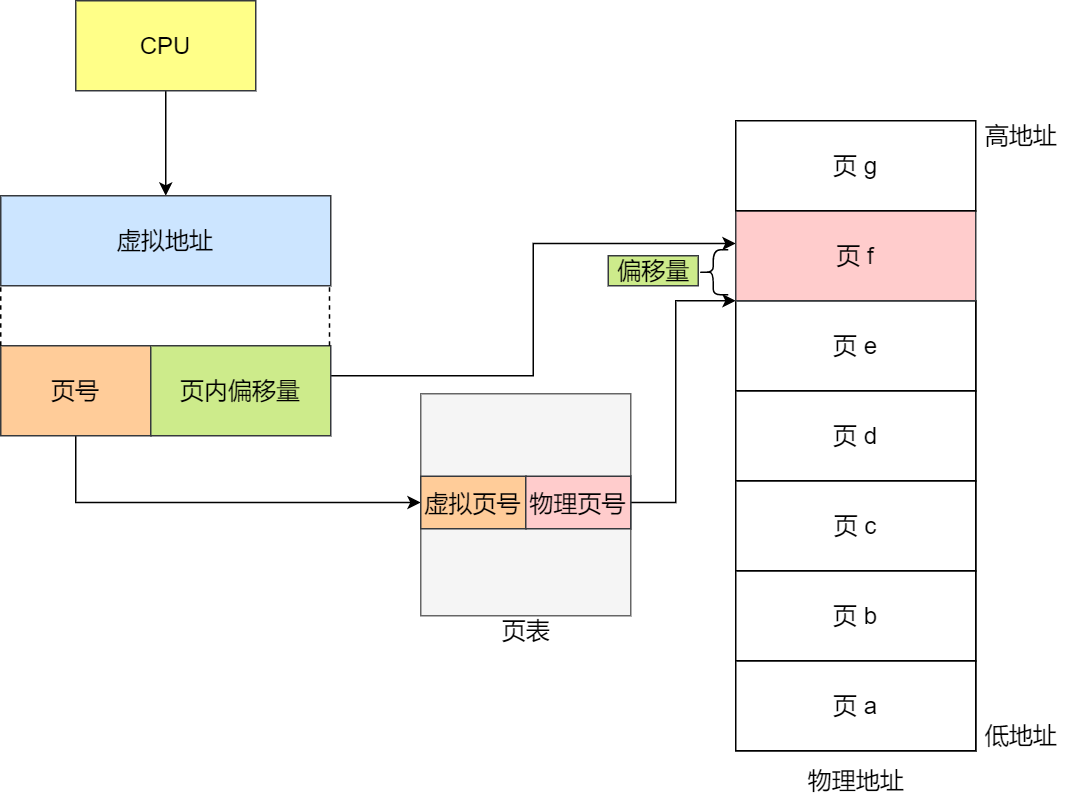
總結一下,對于一個內存地址轉換,其實就是這樣三個步驟:
把虛擬內存地址,切分成頁號和偏移量;
根據頁號,從頁表里面,查詢對應的物理頁號;
直接拿物理頁號,加上前面的偏移量,就得到了物理內存地址。
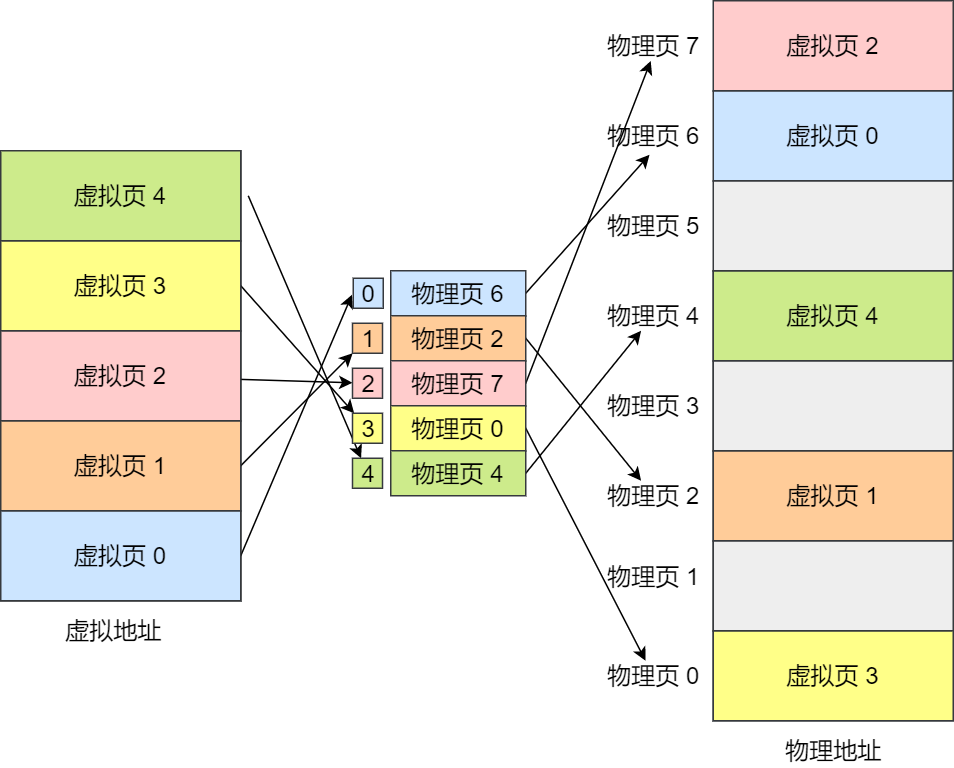
下面舉個例子,虛擬內存中的頁通過頁表映射為了物理內存中的頁,如下圖:
32位 4G 執行2G的東西,虛擬內存會有什么變化呢?
應用程序通過 malloc 函數申請內存的時候,實際上申請的是虛擬內存,此時并不會分配物理內存。
當應用程序讀寫了這塊虛擬內存,CPU 就會去訪問這個虛擬內存, 這時會發現這個虛擬內存沒有映射到物理內存, CPU 就會產生缺頁中斷,進程會從用戶態切換到內核態,并將缺頁中斷交給內核的 Page Fault Handler (缺頁中斷函數)處理。
缺頁中斷處理函數會看是否有空閑的物理內存:
如果有,就直接分配物理內存,并建立虛擬內存與物理內存之間的映射關系。
如果沒有空閑的物理內存,那么內核就會開始進行回收內存的工作,比如會進行 swap 機制。
什么是 Swap 機制?
當系統的物理內存不夠用的時候,就需要將物理內存中的一部分空間釋放出來,以供當前運行的程序使用。那些被釋放的空間可能來自一些很長時間沒有什么操作的程序,這些被釋放的空間會被臨時保存到磁盤,等到那些程序要運行時,再從磁盤中恢復保存的數據到內存中。
另外,當內存使用存在壓力的時候,會開始觸發內存回收行為,會把這些不常訪問的內存先寫到磁盤中,然后釋放這些內存,給其他更需要的進程使用。再次訪問這些內存時,重新從磁盤讀入內存就可以了。
這種,將內存數據換出磁盤,又從磁盤中恢復數據到內存的過程,就是 Swap 機制負責的。
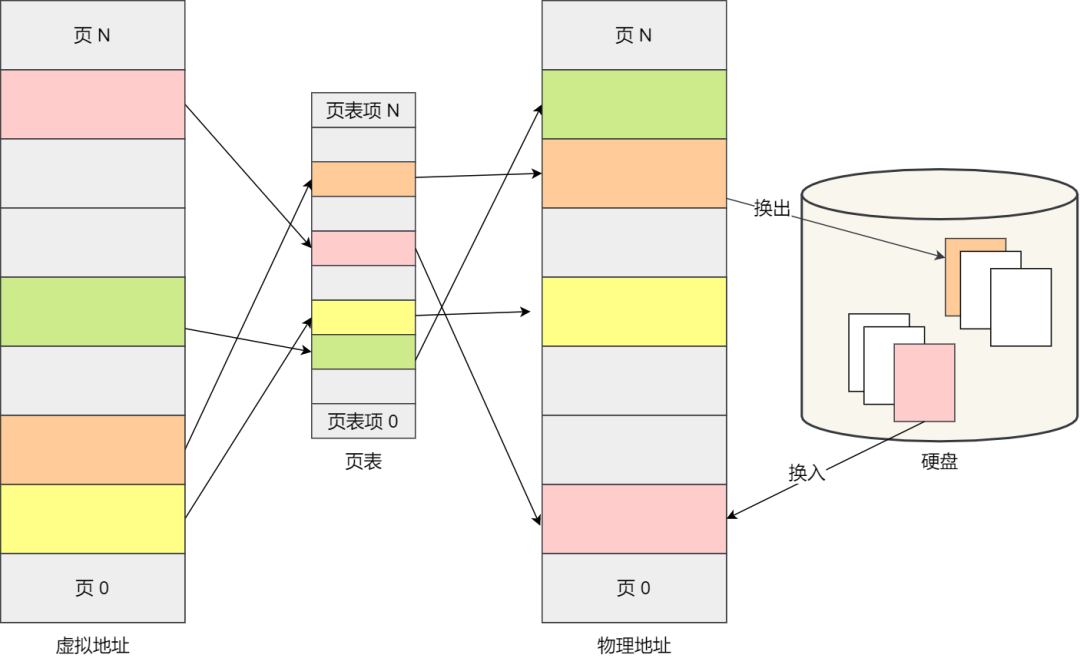
Swap 就是把一塊磁盤空間或者本地文件,當成內存來使用,它包含換出和換入兩個過程:
換出(Swap Out) ,是把進程暫時不用的內存數據存儲到磁盤中,并釋放這些數據占用的內存;
換入(Swap In),是在進程再次訪問這些內存的時候,把它們從磁盤讀到內存中來;
Swap 換入換出的過程如下圖:
使用 Swap 機制優點是,應用程序實際可以使用的內存空間將遠遠超過系統的物理內存。由于硬盤空間的價格遠比內存要低,因此這種方式無疑是經濟實惠的。當然,頻繁地讀寫硬盤,會顯著降低操作系統的運行速率,這也是 Swap 的弊端。
內核態和用戶態的區別是什么?
內核態和用戶態是操作系統中的兩種不同的執行模式。
內核態是操作系統運行在特權級別最高的模式下的狀態,它具有對系統資源的完全控制權。在內核態下,操作系統可以執行特權指令,訪問所有的內存和設備,以及執行關鍵的系統操作。內核態下運行的代碼通常是操作系統內核或驅動程序。
用戶態是應用程序運行的一種模式,它運行在較低的特權級別下。在用戶態下,應用程序只能訪問有限的系統資源,不能直接執行特權指令或訪問內核級別的數據。用戶態下運行的代碼通常是應用程序或用戶進程。
內核態和用戶態的區別在于權限和資源訪問的限制。內核態具有更高的權限和更廣泛的資源訪問能力,而用戶態受到限制,只能訪問有限的資源。操作系統通過將關鍵的操作和資源保護在內核態下來確保系統的安全性和穩定性。用戶程序通過系統調用的方式向操作系統請求服務或資源,并在用戶態下執行,以提供更高的隔離性和安全性。
網絡協議
http常見響應碼有哪些?
HTTP 狀態碼分為 5 大類:1XX:表示消息狀態碼;2XX:表示成功狀態碼;3XX:表示重定向狀態碼;4XX:表示客戶端錯誤狀態碼;5XX:表示服務端錯誤狀態碼。

五大類 HTTP 狀態碼
其中常見的具體狀態碼有:200:請求成功;301:永久重定向;302:臨時重定向;404:無法找到此頁面;405:請求的方法類型不支持;500:服務器內部出錯。
http各個版本的特性?
HTTP/1.1 相比 HTTP/1.0 性能上的改進:
使用長連接的方式改善了 HTTP/1.0 短連接造成的性能開銷。
支持管道(pipeline)網絡傳輸,只要第一個請求發出去了,不必等其回來,就可以發第二個請求出去,可以減少整體的響應時間。
但 HTTP/1.1 還是有性能瓶頸:
請求 / 響應頭部(Header)未經壓縮就發送,首部信息越多延遲越大。只能壓縮 Body 的部分;
發送冗長的首部。每次互相發送相同的首部造成的浪費較多;
服務器是按請求的順序響應的,如果服務器響應慢,會招致客戶端一直請求不到數據,也就是隊頭阻塞;
沒有請求優先級控制;
請求只能從客戶端開始,服務器只能被動響應。
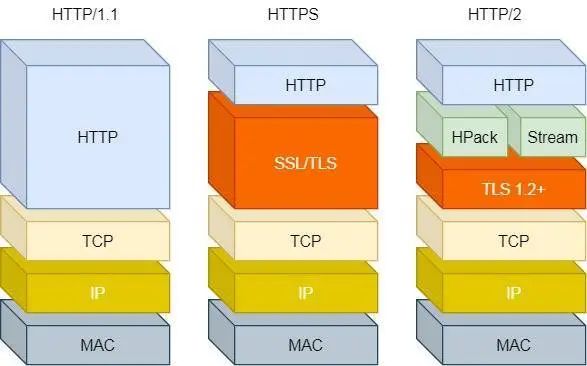
HTT/1 ~ HTTP/2
HTTP/2 相比 HTTP/1.1 性能上的改進:
頭部壓縮
二進制格式
并發傳輸
服務器主動推送資源
1. 頭部壓縮
HTTP/2 會壓縮頭(Header)如果你同時發出多個請求,他們的頭是一樣的或是相似的,那么,協議會幫你消除重復的部分。
這就是所謂的 HPACK 算法:在客戶端和服務器同時維護一張頭信息表,所有字段都會存入這個表,生成一個索引號,以后就不發送同樣字段了,只發送索引號,這樣就提高速度了。
2. 二進制格式
HTTP/2 不再像 HTTP/1.1 里的純文本形式的報文,而是全面采用了二進制格式,頭信息和數據體都是二進制,并且統稱為幀(frame):頭信息幀(Headers Frame)和數據幀(Data Frame)。
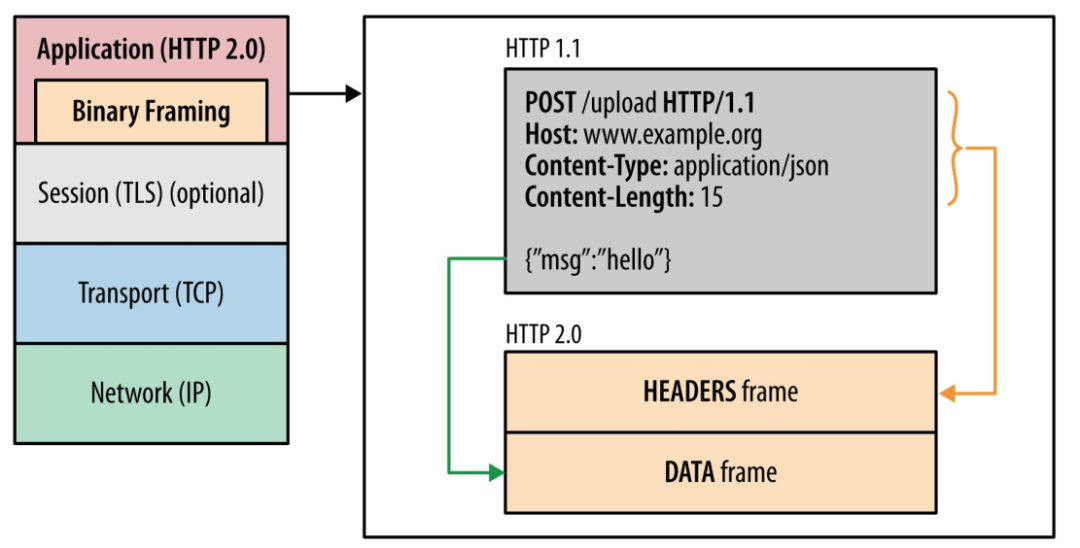
HTTP/1 與 HTTP/2
這樣雖然對人不友好,但是對計算機非常友好,因為計算機只懂二進制,那么收到報文后,無需再將明文的報文轉成二進制,而是直接解析二進制報文,這增加了數據傳輸的效率。
3. 并發傳輸
我們都知道 HTTP/1.1 的實現是基于請求-響應模型的。同一個連接中,HTTP 完成一個事務(請求與響應),才能處理下一個事務,也就是說在發出請求等待響應的過程中,是沒辦法做其他事情的,如果響應遲遲不來,那么后續的請求是無法發送的,也造成了隊頭阻塞的問題。
而 HTTP/2 就很牛逼了,引出了 Stream 概念,多個 Stream 復用在一條 TCP 連接。
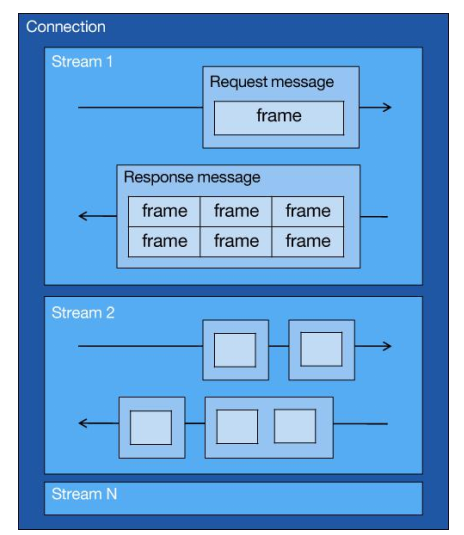
從上圖可以看到,1 個 TCP 連接包含多個 Stream,Stream 里可以包含 1 個或多個 Message,Message 對應 HTTP/1 中的請求或響應,由 HTTP 頭部和包體構成。Message 里包含一條或者多個 Frame,Frame 是 HTTP/2 最小單位,以二進制壓縮格式存放 HTTP/1 中的內容(頭部和包體)。
針對不同的 HTTP 請求用獨一無二的 Stream ID 來區分,接收端可以通過 Stream ID 有序組裝成 HTTP 消息,不同 Stream 的幀是可以亂序發送的,因此可以并發不同的 Stream ,也就是 HTTP/2 可以并行交錯地發送請求和響應。
比如下圖,服務端并行交錯地發送了兩個響應:Stream 1 和 Stream 3,這兩個 Stream 都是跑在一個 TCP 連接上,客戶端收到后,會根據相同的 Stream ID 有序組裝成 HTTP 消息。
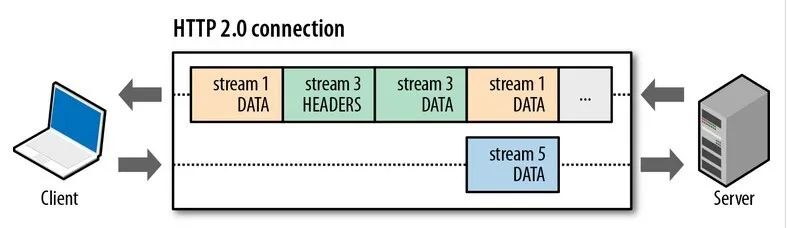
4、服務器推送
HTTP/2 還在一定程度上改善了傳統的「請求 - 應答」工作模式,服務端不再是被動地響應,可以主動向客戶端發送消息。
客戶端和服務器雙方都可以建立 Stream, Stream ID 也是有區別的,客戶端建立的 Stream 必須是奇數號,而服務器建立的 Stream 必須是偶數號。
比如下圖,Stream 1 是客戶端向服務端請求的資源,屬于客戶端建立的 Stream,所以該 Stream 的 ID 是奇數(數字 1);Stream 2 和 4 都是服務端主動向客戶端推送的資源,屬于服務端建立的 Stream,所以這兩個 Stream 的 ID 是偶數(數字 2 和 4)。
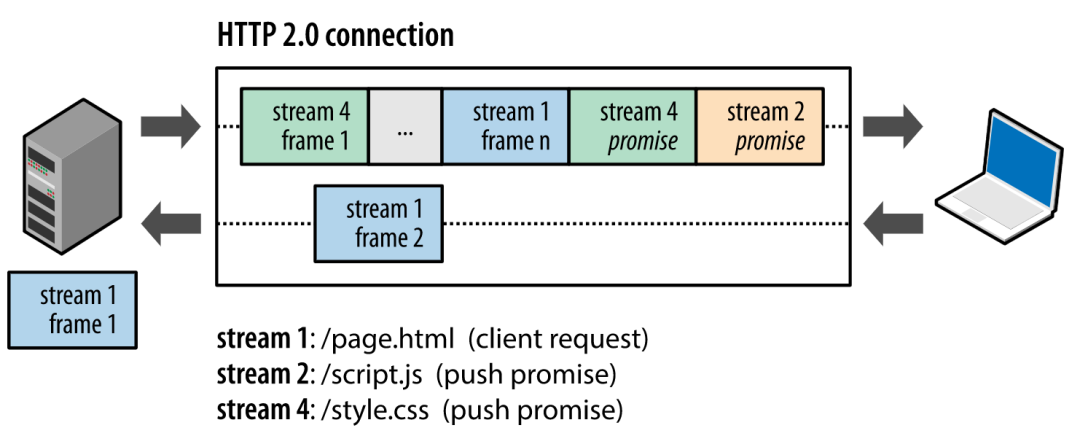
再比如,客戶端通過 HTTP/1.1 請求從服務器那獲取到了 HTML 文件,而 HTML 可能還需要依賴 CSS 來渲染頁面,這時客戶端還要再發起獲取 CSS 文件的請求,需要兩次消息往返,如下圖左邊部分:
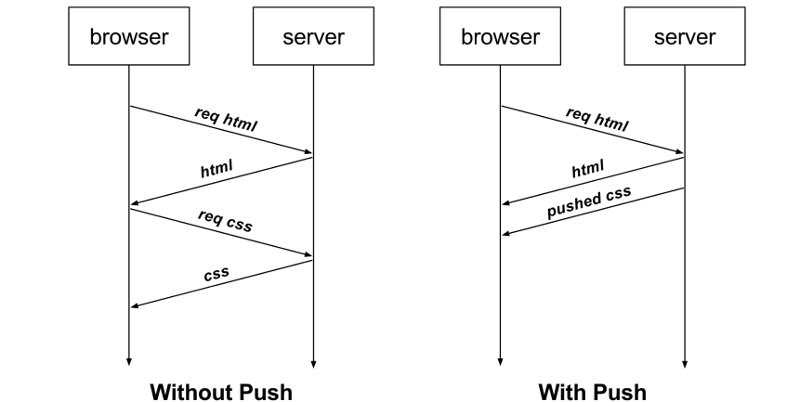
如上圖右邊部分,在 HTTP/2 中,客戶端在訪問 HTML 時,服務器可以直接主動推送 CSS 文件,減少了消息傳遞的次數。
tcp擁塞控制介紹一下
在網絡出現擁堵時,如果繼續發送大量數據包,可能會導致數據包時延、丟失等,這時 TCP 就會重傳數據,但是一重傳就會導致網絡的負擔更重,于是會導致更大的延遲以及更多的丟包,這個情況就會進入惡性循環被不斷地放大....
所以,TCP 不能忽略網絡上發生的事,它被設計成一個無私的協議,當網絡發送擁塞時,TCP 會自我犧牲,降低發送的數據量。
于是,就有了擁塞控制,控制的目的就是避免「發送方」的數據填滿整個網絡。
為了在「發送方」調節所要發送數據的量,定義了一個叫做「擁塞窗口」的概念。
擁塞控制主要是四個算法:
慢啟動
擁塞避免
擁塞發生
快速恢復
慢啟動
TCP 在剛建立連接完成后,首先是有個慢啟動的過程,這個慢啟動的意思就是一點一點的提高發送數據包的數量,如果一上來就發大量的數據,這不是給網絡添堵嗎?
慢啟動的算法記住一個規則就行:當發送方每收到一個 ACK,擁塞窗口 cwnd 的大小就會加 1。
這里假定擁塞窗口 cwnd 和發送窗口 swnd 相等,下面舉個栗子:
連接建立完成后,一開始初始化 cwnd = 1,表示可以傳一個 MSS 大小的數據。
當收到一個 ACK 確認應答后,cwnd 增加 1,于是一次能夠發送 2 個
當收到 2 個的 ACK 確認應答后, cwnd 增加 2,于是就可以比之前多發2 個,所以這一次能夠發送 4 個
當這 4 個的 ACK 確認到來的時候,每個確認 cwnd 增加 1, 4 個確認 cwnd 增加 4,于是就可以比之前多發 4 個,所以這一次能夠發送 8 個。
慢啟動算法的變化過程如下圖:
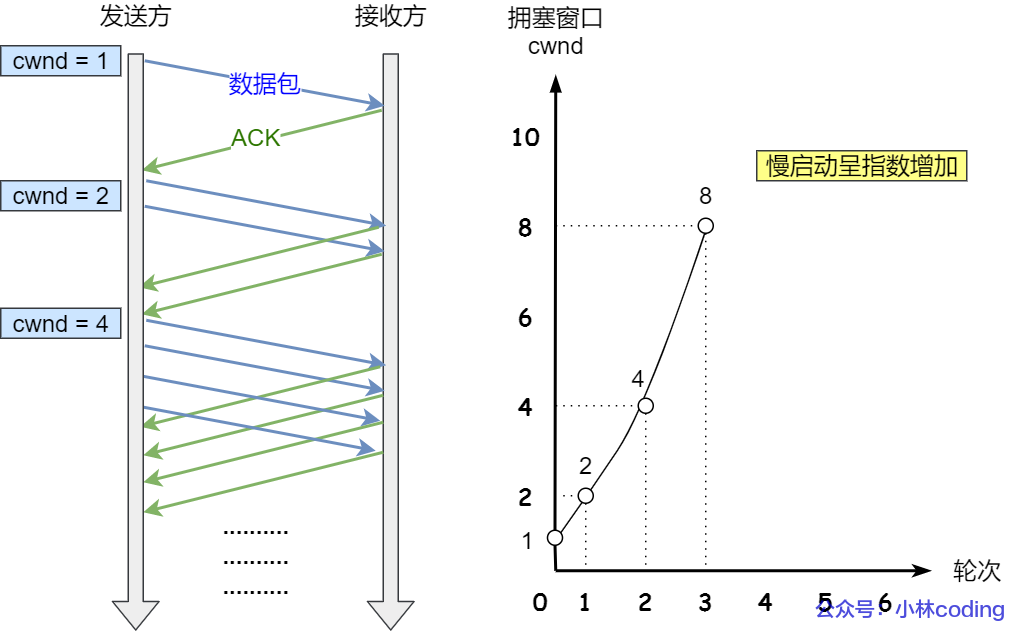
慢啟動算法
可以看出慢啟動算法,發包的個數是指數性的增長。
那慢啟動漲到什么時候是個頭呢?
有一個叫慢啟動門限 ssthresh (slow start threshold)狀態變量。
當 cwnd < ssthresh 時,使用慢啟動算法。
當 cwnd >= ssthresh 時,就會使用「擁塞避免算法」。
擁塞避免
當擁塞窗口 cwnd 「超過」慢啟動門限 ssthresh 就會進入擁塞避免算法。
一般來說 ssthresh 的大小是 65535 字節。
那么進入擁塞避免算法后,它的規則是:每當收到一個 ACK 時,cwnd 增加 1/cwnd。
接上前面的慢啟動的栗子,現假定 ssthresh 為 8:
當 8 個 ACK 應答確認到來時,每個確認增加 1/8,8 個 ACK 確認 cwnd 一共增加 1,于是這一次能夠發送 9 個 MSS 大小的數據,變成了線性增長。
擁塞避免算法的變化過程如下圖:
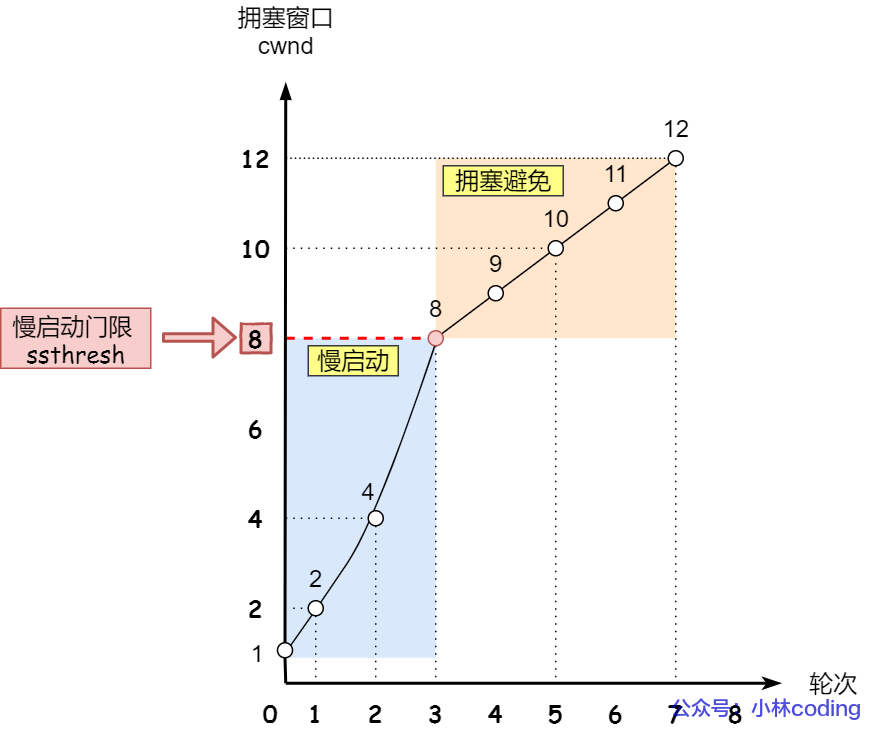
擁塞避免
所以,我們可以發現,擁塞避免算法就是將原本慢啟動算法的指數增長變成了線性增長,還是增長階段,但是增長速度緩慢了一些。
就這么一直增長著后,網絡就會慢慢進入了擁塞的狀況了,于是就會出現丟包現象,這時就需要對丟失的數據包進行重傳。
當觸發了重傳機制,也就進入了「擁塞發生算法」。
擁塞發生
當網絡出現擁塞,也就是會發生數據包重傳,重傳機制主要有兩種:
超時重傳
快速重傳
當發生了「超時重傳」,則就會使用擁塞發生算法。
這個時候,ssthresh 和 cwnd 的值會發生變化:
ssthresh 設為 cwnd/2,
cwnd 重置為 1 (是恢復為 cwnd 初始化值,我這里假定 cwnd 初始化值 1)
擁塞發生算法的變化如下圖:
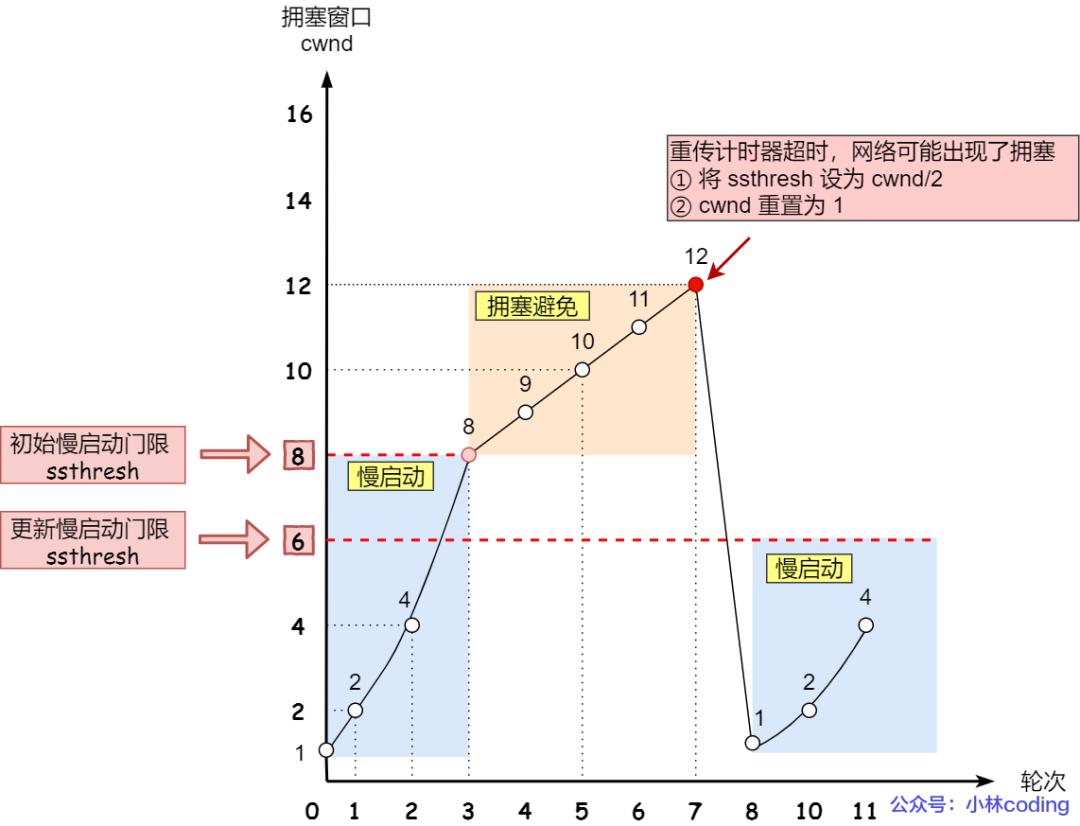
擁塞發送 —— 超時重傳
接著,就重新開始慢啟動,慢啟動是會突然減少數據流的。這真是一旦「超時重傳」,馬上回到解放前。但是這種方式太激進了,反應也很強烈,會造成網絡卡頓。
還有更好的方式,前面我們講過「快速重傳算法」。當接收方發現丟了一個中間包的時候,發送三次前一個包的 ACK,于是發送端就會快速地重傳,不必等待超時再重傳。
TCP 認為這種情況不嚴重,因為大部分沒丟,只丟了一小部分,則 ssthresh 和 cwnd 變化如下:
cwnd = cwnd/2 ,也就是設置為原來的一半;
ssthresh = cwnd;
進入快速恢復算法
快速恢復
快速重傳和快速恢復算法一般同時使用,快速恢復算法是認為,你還能收到 3 個重復 ACK 說明網絡也不那么糟糕,所以沒有必要像 RTO 超時那么強烈。
正如前面所說,進入快速恢復之前,cwnd 和 ssthresh 已被更新了:
cwnd = cwnd/2 ,也就是設置為原來的一半;
ssthresh = cwnd;
然后,進入快速恢復算法如下:
擁塞窗口 cwnd = ssthresh + 3 ( 3 的意思是確認有 3 個數據包被收到了);
重傳丟失的數據包;
如果再收到重復的 ACK,那么 cwnd 增加 1;
如果收到新數據的 ACK 后,把 cwnd 設置為第一步中的 ssthresh 的值,原因是該 ACK 確認了新的數據,說明從 duplicated ACK 時的數據都已收到,該恢復過程已經結束,可以回到恢復之前的狀態了,也即再次進入擁塞避免狀態;
快速恢復算法的變化過程如下圖:
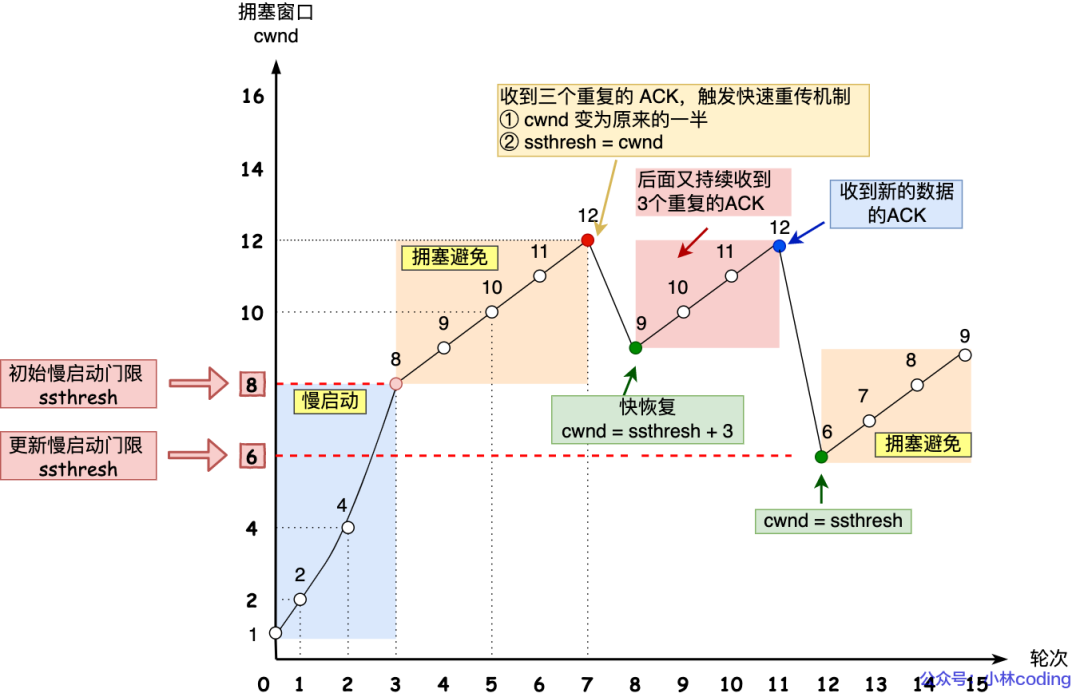
快速重傳和快速恢復
也就是沒有像「超時重傳」一夜回到解放前,而是還在比較高的值,后續呈線性增長。
哪些會影響窗口大小?
TCP窗口大小受到多個因素的影響,包括以下幾個方面:
接收方窗口大小:接收方的窗口大小決定了發送方可以發送的數據量。如果接收方窗口較小,發送方需要等待確認后才能繼續發送數據,從而限制了發送速率。
帶寬和延遲:網絡的帶寬和延遲會對TCP窗口大小產生影響。較高的帶寬和較低的延遲通常可以支持較大的窗口大小,從而實現更高的數據傳輸速率。
擁塞控制:TCP的擁塞控制機制會根據網絡擁塞程度調整窗口大小。當網絡出現擁塞時,TCP會減小窗口大小以降低發送速率,從而避免擁塞的進一步惡化。
路由器和網絡設備:路由器和其他網絡設備的緩沖區大小也會對TCP窗口大小產生影響。如果緩沖區較小,可能導致數據包丟失或延遲增加,從而限制了窗口大小。
操作系統和應用程序:操作系統和應用程序也可以對TCP窗口大小進行配置和調整。通過調整操作系統的參數或應用程序的設置,可以影響TCP窗口大小的默認值和動態調整的行為。
因此,TCP窗口大小受到接收方窗口大小、帶寬和延遲、擁塞控制、網絡設備、操作系統和應用程序等多個因素的綜合影響。
審核編輯:劉清
-
TCP
+關注
關注
8文章
1377瀏覽量
79194 -
多線程
+關注
關注
0文章
278瀏覽量
20052 -
MMU
+關注
關注
0文章
91瀏覽量
18336 -
中斷函數
+關注
關注
0文章
13瀏覽量
5313 -
虛擬內存
+關注
關注
0文章
77瀏覽量
8076
原文標題:騰訊一面:32 位 4GB 系統,訪問 2GB 數據,虛擬內存會發生什么?
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Micron推出2GB和4GB的DDR3-2133內存芯片
余承東:2GB內存版榮耀3C一月正式開賣
Linux虛擬內存和物理內存的深刻分析
STM32F446xC/E內存映射4GB還是4.096GB?
索尼新旗艦曝光!證實升為4GB內存 或將MWC大會發布
性能升級!小米6官方確認:4GB升級6GB內存
紫光DDR3 4GB*2 1600內存詳細評測






 工商網監
工商網監
評論