 中國大模型落地應用案例集
中國大模型落地應用案例集
來源| 中國信通院華東分院、數據觀
近日,中國信通院聯合上海人工智能實驗室成立的大模型測試驗證與協同創新中心牽頭,首次面向全國范圍征集全行業優秀應用實踐,并形成《2023大模型落地應用案例集》(以下簡稱“《案例集》”)。
作為首部聚焦落地應用的權威研究成果,《案例集》全面展示了大模型前沿技術和發展成果,推動了大模型為代表的人工智能技術賦能社會經濟高質量發展。經專家組的多輪評審,共52個各自領域的典型大模型技術落地應用成功入選。
2022年底ChatGPT的橫空出世,引爆了國內外大模型的熱情,各行各業的創業者已經集結在十字路口蓄勢待發。
從國內市場來看,目前人工智能(AI)大模型已經在各行各業“落子不斷”。據公開資料不完全統計顯示,國內大模型的發展路徑是“通用+垂直”兩條腿走路,其中垂類大模型落地速度最快。《案例集》顯示,有近65%+的AI大模型是垂直大模型。趨勢已然,大模型技術突破代表了AI發展的一個重要里程碑,下面筆者將梳理中國從業者構建的“底層原創技術-中層基礎模型-上層行業應用”的大模型圖鑒。
PART 1、大模型領域中國學者的技術貢獻
圖注:ResNet的四位作者分別是:何愷明、張祥雨、任少卿、孫劍
2016年,來自微軟亞洲研究院的四位學者提出深度殘差學習(ResNet),解決了深度網絡的梯度傳遞問題。要知道,2015年之前深度學習最多只能訓練20層,ResNet之后,就可以有效地訓練超過百層的深度神經網絡。

2017年Google發布Transformer,它的出現打穩了AI大模型的“地基”,不僅“顛覆”了自然語言處理(NLP)中的機器翻譯任務,而且還提供了一種新的思路來處理圖像數據。
中國學者也圍繞Transformer做了許多改進和完善,例如微軟亞洲研究院聯合西安交通大學推出LONGNET,將Transformer的序列長度擴展10億+;京東探索研究院聯合武漢大學提出全球首個面向遙感任務設計的億級視覺Transformer大模型;阿里達摩院提出新的Transformer結構FMViT,大幅度提升AI模型精度與速度……
在大模型領域細數中國學者貢獻,許多原創性貢獻來自本土。已故的商湯科技創始人湯曉鷗(緬懷)在2023世界人工智能大會上,發表演講時表示:在深度學習的大門上,我們按了18次門鈴,取得了許多跨時代的突破。其中湯曉鷗提到了上海人工智能實驗室領軍科學家林達華,他當時設計的計算機視覺開源算法體系OpenMMLab,目前已經成為國際上最具影響力的視覺算法開源體系。值得一提的是,林達華也是書生大模型體系的重要貢獻者。
京東探索研究院早在2021年年初就展開了大模型體系(超級深度學習)的建設和基礎研究,領導京東建設了中國第一個NVIDIA DGX Superpod天琴alpah-α超算集群。在此基礎上,京東探索研究院的織女模型vega v2 在2022年登頂SuperGLUE榜首,一舉超越同場競技的谷歌、微軟、Meta等業界頂尖企業;2021年研究院開發的大規模視覺模型ViTAE,在ImageNet Real的目標識別和MS COCO的人體姿態估計等權威榜單上均獲得世界第一。

圖注:(上)2022年京東探索研究院發表論文《Self-Evolution Learning for Discriminative Language Model Pretraining》,提出自我進化學習方法,為vega v2大模型的設計提供核心思想;
(下)2021年京東探索研究院發表論文《ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias》,嘗試將 CNN和transformer相結合。
因此,國內公司的 AI 大模型研發雖然比國外公司晚,但是發展卻異常地迅速,其內在邏輯便是:本土企業和學者對深度學習技術的深入理解與創新。在大模型的底層技術已經固定的時代,他們靠著持續的探索和努力才能構建出秀麗的“上層建筑”。
在OpenAI發布ChatGPT之前,國內的一些企業就已經押注AI大模型技術:例如2021 年 4 月,華為云聯合循環智能發布盤古超大規模預訓練語言模型,參數規模達 1 000 億;2021 年 6 月,北京智源人工智能研究院發布了超大規模智能模型“悟道 2.0”,參數規模達到 1.75 萬億;2021 年 12 月,百度推出 ERNIE 3.0 Titan 模型,參數規模達 2 600 億,同期,阿里巴巴達摩院的 M6 模型參數達到 10 萬億,將大模型參數直接提升了一個量級。
到2023年,大模型繼續火熱,國內的AI大模型團隊已逐漸拓展到視覺、決策領域,甚至用于解決蛋白質預測、航天等領域的重大科學問題,阿里、京東、oppo等大廠都有相應的成果。
PART 2、大模型應用拐點已至
圖靈獎獲得者Yann LeCun說過:AI大模型的技術都是公開的,算不上底層技術上的創新,如果你愿意一探究竟的話,可以發現它背后沒有任何秘密可言。但借著這些“過時”的技術,在中國擁有龐大的人才基數和數據集的情況下,可以發展出更適合本土環境和語境的大模型。那么如何形象理解大模型?前科技部長王志剛從高維度表示,大模型,就是大數據、大算力、強算法。形象一些:大模型事實上就是算法、數據、算力上的有效結合。傳統巨頭在大模型領域的技術投入普遍都是在積極防御,而中國企業在非常積極地推動向應用中的落地。目前,業界除了把AI大模型商業落地模式統分為 toB 和 toC之外,在市場劃分上則遵循通用與垂直兩大路徑,兩者在參數級別、應用場景等方面差異正在顯性化。通用大模型往往是指具備處理多種不同類型任務的AI模型,這些模型通常是通過大規模的數據訓練而成,能夠在多個領域和應用中表現出良好的效能。大家耳熟能詳的幾個通用大模型均來財力雄厚的企業:
1. 書生浦語開源大模型:由上海人工智能實驗室研發,涵蓋 70 億參數的輕量級版本 InternLM-7B,以及 200 億參數的中量級版本和 InternLM-20B,以及完整的開源工具鏈體系。InternLM-7B 在包含 40 個評測集的全維度評測中展現出卓越且平衡的性能,它在兩個被廣泛采用的基準 MMLU 和 CEval 上分別取得了 50.8 和 52.8 的高分,開源一度刷新了 7B 量級模型的紀錄。
2. 昆侖萬維天工大模型:“天工”是一個 AI 搜索引擎,一個對話式 AI 助手。“天工”擁有強大的自然語言處理和智能交互能力,能夠實現個性化 AI 搜索、智能問答、聊天互動、文本生成、編寫代碼、語言翻譯等多種應用場景并且具有豐富的知識儲備,涵蓋科學、技術、文化、藝術、歷史等領域。
3. 通義千問 2.0:由阿里云研發的超大規模的語言模型,具備多輪對話、文案創作、邏輯推理、多模態理解、多語言支持等功能。通義千問 2.0 在復雜指令理解、文學創作、通用數學、知識記憶、幻覺抵御等能力上均比上代有顯著提升。
4. MiniMax-abab:由科技創業公司MiniMax研發。據悉,“Max-abab”是文本、語音、視覺三模態的千億參數大語言模型,在中、英文服務領域均已超過GPT-3.5 的水平。今年8月份,“MiniMax-abab”大模型通過了國家首批大模型服務備案,面向社會公眾提供服務。
5. 言犀基礎大模型:由京東科技研發,該模型融合了70%的通用數據和30%的數智供應鏈原生數據,具有更高的產業屬性。
6. 百靈語言大模型:由螞蟻集團基于Transfromer架構研發。該模型基于萬億級Token語料訓練而成,支持窗口長度達32K,在主流推理類榜單中排名前列。據悉,螞蟻百靈大模型已完成備案,基于百靈大模型的多款產品已陸續完成內測,正陸續向公眾開放。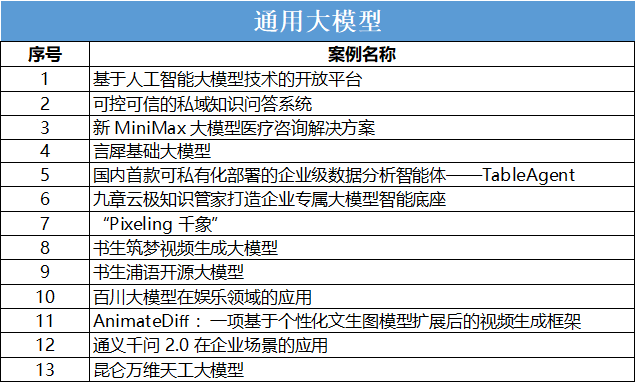
這些通用大模型包含千億甚至萬億參數,覆蓋自然語言處理、圖像識別、語音識別等方面的任務,已在知識問答、醫療咨詢、娛樂領域、視頻生成等數十個行業場景領域,展現出廣闊的落地應用潛力。與通用大模型相比,垂類大模型參數量相對較小。但是因為有一些行業的核心數據和業務系統的生產數據參與,所以在相應行業解決問題更為高效、直接。從《案例集》來看,在金融、教育、醫療等領域,已經有不少公司發布了相應產品。
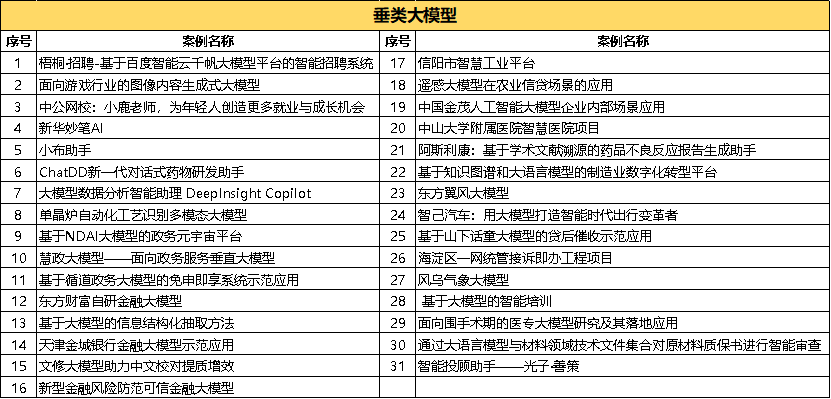
根據《案例集》入選案例的應用場景,垂類大模型更針對于企業級應用場景的垂直性和專業性要求,而在模型部署層面,更少的模型參數、訓練數據意味著更少的成本,因此垂直應用領域有望實現“萬模齊發”。《案例集》公布的名單,也恰恰驗證了目前垂類大模型發展的一些趨勢:
1. 加注端側、邊緣側應用。輕量化參數能讓手機助手接入AI大模型能力。目前已有案例包括OPPO的小布助手、華為的智能助手小藝等等。
2. 更傾向于“解決方案”式的交付方式。由于垂類大模型接受了大量特定領域的數據和知識,因此可以基于領域知識生成更具深度的解決方案。例如ChatDD 新一代對話式藥物研發助手,面向游戲行業的圖像內容生成式大模型等等。
3. 大模型開始向多模態領域發展。多模態意味著豐富的數據形式,包含視覺、聽覺和時序信息。對于大模型模型來說,這意味著可以從多模態中提取和學習更多維度的信息。類似于《案例集》中的單晶爐自動化工藝識別多模態模型,相信未來將會出現更多。
4. “通用+垂直”模型互相融通的態勢。隨著AI技術的發展,不同類型的模型之間的界限變得越來越模糊。例如,一些通用模型開始整合垂直領域的知識,而一些垂直模型也開始利用通用模型的技術來增強其功能。例如百川大模型在娛樂領域的應用。
PART 3、搶灘大模型未來:構建生態
對于AI大模型這種劃時代的超級機遇而言,勝負不在于做出一個爆款應用,賺到幾億盈利,而在于,是否抓到了大時代的方向。
換句話說,當下的大模型競爭早已超過了技術的范疇,更多是一種生態層面的比拼,具體表現在有多少應用、有多少插件、有多少開發者以及用戶等。誰能夠率先圍繞大模型構建生態,或者說誰率先融入生態,誰就能成為領先者。
大模型要想像電力一樣輸送給千行百業和千家萬戶,必然需要一個體系化的產業生態,構建這個生態需要一系列相互關聯的因素,包括技術發展、應用場景、數據管理、倫理與法律問題、以及社會影響等。
在生態建構的路徑上,目前企業可分為兩派。一派將大模型接入原有的產品線,做升級和優化;另一派試圖以大模型產品為中心,建構新一代的“超級應用”。而有些企業試圖跳過這兩種路徑,多方面融入AI大模型生態。從《案例集》公布的大模型服務類案例,我們可以看到有些中國企業做了以下嘗試:
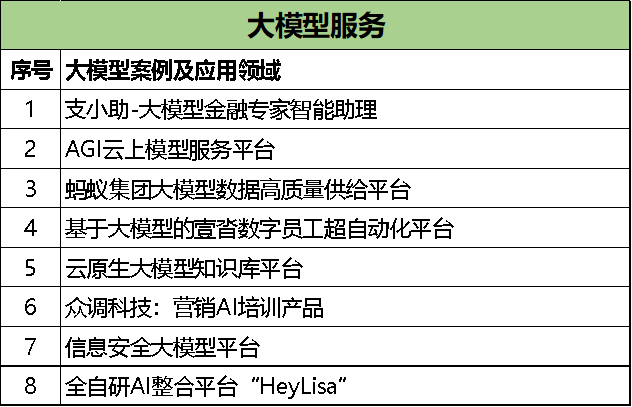
例如螞蟻集團實現了一個大模型數據高效高質量供給平臺,不僅可降低數據獲取和使用成本,且保證來源合規,并能夠有效提升數據質量、過濾風險數據保障訓練安全;優刻得開發的AGI云上模型服務平臺,能提供數據標準化整合、安全合規、提供算力等服務;上海道客研發的云原生大模型知識庫平臺能夠幫助解決信息孤島,以及定制個性化的私人語料庫;泡泡瑪特的AI 整合平臺集成多個知名AI大模型,為用戶提供一站式 AI服務……這些大模型服務工具,在一定程度上能有效地解決“幻覺”、“道德”、“性能”、“數據合規”等當前AI大模型遇到的問題。更重要的是借助這些服務,可以建設規范可控的自主工具鏈,幫助AI企業探索“大而強”的通用模型,助力公司研發“小而美”的垂直行業模型,從而構建基礎大模型和專業小模型交互共生、迭代進化的良好生態。
-
人工智能
+關注
關注
1794文章
47642瀏覽量
239651 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
7945 -
大模型
+關注
關注
2文章
2541瀏覽量
3022
發布評論請先 登錄
相關推薦
海辰儲能蒞臨中國大唐交流拜訪

微軟終止中國大陸個人Azure OpenAI服務,為國內大模型帶來機遇
云天勵飛邊緣AI推動大模型規模化應用落地
中國大陸芯片設備支出領跑全球
德國大陸集團考慮分拆汽車部門上市
西井科技成功入選《2024大模型典型示范應用案例集》

如何理解機器學習中的訓練集、驗證集和測試集
云天勵飛加速推動大模型行業落地
美國蘋果公司將增加在中國大陸的投資
數勢聯動百川,發布首批大模型聯合解決方案,推動中國大模型價值落地





 工商網監
工商網監
評論