 騰訊云把向量數據庫“卷”到哪一步了?
騰訊云把向量數據庫“卷”到哪一步了?
“不是我不明白,這世界變化快”,崔健在20世紀寫下的這句歌詞,放在剛剛過去的2023年,也同樣適用。技術風向的變化之快,讓不少人感到驚訝,向量數據庫這一年的潮起潮落,就是一個典型的例子。
2023年初大模型、生成式 AI的起飛,也帶來了向量數據庫的火爆,投融資項目爆發式增長,傳統數據庫廠商和公有云廠商都推出了相關產品。然而一年狂飆之后,市場又開始退潮,前不久全球最著名的 AI 項目之一AutoGPT 宣布,不再使用向量數據庫。
向量數據庫真的是AI革命中的組成部分嗎?這一市場有哪些參與者?騰訊云為代表的公有云廠商,又在這場技術創新中發揮了什么作用?
向量數據庫,剛剛開始
新技術的火爆,必然會伴隨炒作和泡沫,但向量作為大模型理解世界的數據形式,向量數據庫作為AI革命重要基建的位置,長期來看,是不會動搖的。
為什么這么說?
向量數據庫并不是一種特別新的數據庫技術,在AI領域已經應用了七八年,谷歌在2015年就宣布使用RankBrain語義檢索來處理搜索任務。如果說數據庫是數據的“硬盤”,那么,向量數據庫就是更適合AI體質的“硬盤”。
其“AI原生”的體質,具體表現在幾個方面:
1.更高的效率。AI算法,要從圖像、音頻和文本等海量的非結構化數據中學習,提取出以向量為表示形式的“特征”,以便模型能夠理解和處理。因此,向量數據庫比傳統基于索引的數據庫有明顯優勢。
2.更低的成本。大模型要從一種新技術轉化為產業價值,必須達到合理的投入產出比,而向量數據庫可以有效減少存儲和計算成本。一個公開數據是,通過騰訊云向量數據庫,QQ音樂人均聽歌時長提升3.2%、騰訊視頻有效曝光人均時長提升1.74%、QQ瀏覽器成本降低37.9%,就在于檢索效率、運行穩定性、運營效率、推薦算法等,有了較大的提升。
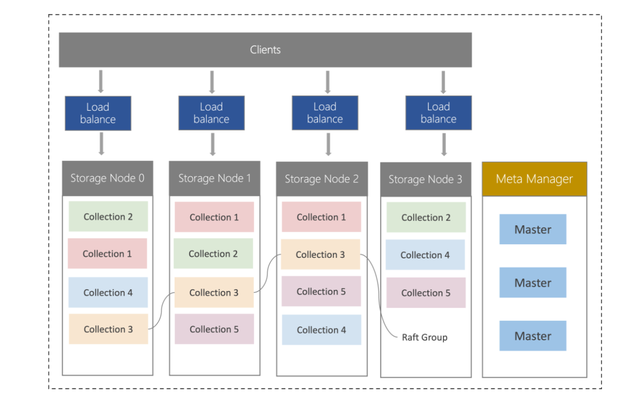
(騰訊云數據庫產品架構)
3.更強的數據安全。有個企業直言:我沉淀了幾十年的內部數據,是我的的核心競爭力,讓我無償去公開給大模型做訓練,我肯定不愿意。想做大模型,還要確保數據的隱私安全,就必須與數據庫產品做好配合,這給向量數據庫的本地部署帶來了廣闊的需求。
4.更大的擴展性。隨著大模型走向行業應用,垂直領域的AI用例不斷增多,洶涌的數據洪潮和存算任務,會帶來大量向量搜索的需求。而向量數據庫嵌入向量的長度不受限制,具有良好的擴展性,可以根據AI用例和模型而變化,更好地處理大規模數據集。
所以說,除非大模型技術,在短期內發生顛覆性改變,否則落地應用還是需要向量檢索和向量數據庫。而作為大模型技術標桿的OpenAI最近也透露:我們可能已經非常接近實現通用人工智能(AGI),應該以通用人工智能的實現為前提進行創業和技術開發。
由此可以肯定,向量數據庫市場必然還會迎來一輪增長。年底趨于冷靜,只是2023年熱情過度高漲的適當回調。
兩股新勢力,云是方向
從引爆到飽和,向量數據庫市場的發展速度迅猛,也吸引了“群雄逐鹿”。
傳統數據庫廠商不必多說,既有相應的能力建設,也有一定的客戶基礎,推出相關產品是必然。一些在AI領域積淀已久的科技大廠,如谷歌、微軟、Meta、百度等大廠,都有向量數據庫的技術積累,也都可以向外輸出相關能力和產品。這些我們都比較熟悉了。
而上一年狂飆突進的兩股新勢力,成為市場上的黑馬,分別是創業公司和公有云。
以上半年爆火的AI創業新秀Pinecone為代表。Pinecone是閉源的領跑者,憑借良好的開箱即用的產品體驗,獲得了非常大的增長,B輪估值達到7.5億美元。其他競爭者大多建立在開源項目的基礎上。
總體來說,這些創業“獨角獸”的向量數據庫公司,固然新銳,但長期盈利能力還有待驗證。原因是,其客戶大多是嘗鮮、實驗性質。
一般來說,企業需要先將非結構化的私密數據,進行一個小的模型,進行向量化,產生一個向量的矩陣,再存儲到向量數據庫里,來供大模型學習和檢索。這個過程涉及大量的工程化,會耗費企業許多開發人員、時間成本,一開始可能會因為AI大模型很火而對向量數據庫產生興趣,但能否真正在業務中落地還是個未知數,因此,長期付費意愿還有較大的不確定性。
另一股“新勢力”:公有云廠商,也是向量數據庫的積極參與者。
不是所有企業都有能力自建大模型所需要的基礎設施,通過MaaS(模型即服務)業務來訓練應用大模型,是更靈活的選擇。
此外,上云用數賦智是大勢所趨,很多政企客戶往往會選擇公有云或行業云來滿足其業務需求,將數據遷移到云上,對云數據庫的關注度和接受度上升,而這些用戶在探索大模型時,會傾向于以整體解決方案的形式來交付,這就給了云廠商參與游戲的機會,同時也要求云廠商提供向量數據庫的全棧支持。
以騰訊云為代表,騰訊云的AI 原生(AI Native)向量數據庫Tencent Cloud VectorDB是國內首個從接入層、計算層、到存儲層提供全生命周期AI化的向量數據庫。
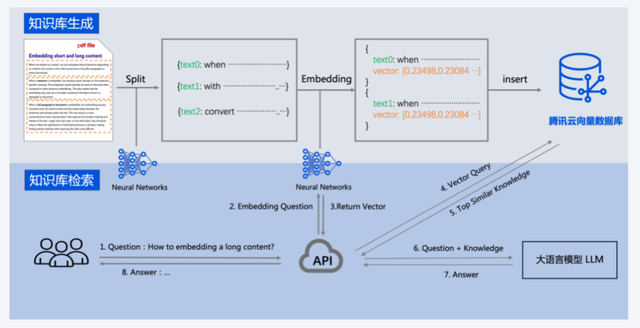
除了產品之外,騰訊云提供了全面AI化解決方案,覆蓋接入層、計算層、存儲層,使用戶在使用向量數據庫的全生命周期,都能應用到AI能力。有數據顯示,企業原先接入一個大模型需要花1個月左右時間,使用騰訊云向量數據庫后,3天時間即可完成,極大降低了企業的接入成本。
此外,騰訊龐大的業務集群及智能化應用,為騰訊云向量數據庫提供了絕佳的練兵場。騰訊集團每日處理千億次檢索的向量引擎(OLAMA),讓騰訊云向量數據庫的基本功能和性能得到了更加充分地檢驗與優化,從而淬煉出了很多讓人眼前一亮的新能力。
以騰訊視頻的應用為例,視頻庫中的圖片、音頻、標題文本等內容使用騰訊云向量數據庫,月均完成的檢索和計算量高達200億次,有效滿足了版權保護、原創識別、相似性檢索等場景需求。
風物長宜放眼量,AI技術還在快速變化之中,AI Native的騰訊云在這一市場領域的競爭力還會進一步擴大。
接下來,向量數據庫卷什么?
不難看到,市面上并不缺少向量數據庫產品,缺少的是商業模式。
據東北證券預測,到 2030 年,全球向量數據庫市場規模有望達到 500 億美元,國內向量數據庫市場規模有望超過600億人民幣。想要吃到這塊巨大的蛋糕,僅僅形成技術趨勢是遠遠不夠的,成熟的產品化才能說服用戶、兌現商業價值。
目前來看,以騰訊云為代表的云廠商有幾重特殊優勢,或許會讓向量數據庫加速走向商業成功:
1.多元化部署。垂直行業大模型,數據都是私有機密的,客戶一般不愿意放到公有云上,騰訊云提供私有部署、分布式、混合云等多種方案,打消疑慮。背后需要混合多云的云基礎設施。
2.一體化AI方案。向量數據庫的火爆,本質是AI需求,而AI Native時代的數據工程,還有許多復雜問題尚待解決,騰訊云提供一體化的AI解決方案,從底層算力集群、Maas模型平臺到全棧工具鏈,通過軟硬件協同優化AI開發成本,是企業和開發者所期待的。
3.產業服務能力。AI技術革命方興未艾,行業熱情高漲,但大多處于嘗試探索期,需要結合自身業務、AI應用、IT設施等多種因素試錯并迭代,這個過程中,隨叫隨到、幫助客戶及時解決問題的ToB服務能力,也是非常看重的。深耕產業互聯網的騰訊云,確實是企業在這場AI技術革命中可靠的伙伴。
開放、全面、貼心,才能支持企業用好向量數據庫、大模型等基礎設施,弄潮AI。
被大模型“帶飛”的向量數據庫,才剛剛開始,將在騰訊云上長出商業成功的羽翼,飛向更廣闊的天地。
-
AI
+關注
關注
87文章
31490瀏覽量
269907 -
數據庫
+關注
關注
7文章
3845瀏覽量
64594 -
騰訊云
+關注
關注
0文章
215瀏覽量
16831 -
AI算法
+關注
關注
0文章
252瀏覽量
12318 -
算力
+關注
關注
1文章
1012瀏覽量
14911 -
大模型
+關注
關注
2文章
2541瀏覽量
3024
發布評論請先 登錄
相關推薦
云數據庫和云服務器哪個便宜一些?
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

一文詳解企業上云數據庫是干嘛的
阿里云與中興通訊達成開源數據庫合作,助推國產數據庫發展
華為云多模數據庫 GeminiDB 架構與應用實踐直播問答實錄
搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫





 工商網監
工商網監
評論