 光電智能計算架構和芯片研究
光電智能計算架構和芯片研究
文章來源:中國物理學會期刊網
原文作者:方璐1,3^吳嘉敏2,3 戴瓊海2,3,
介紹了什么是光電智能計算架構和芯片。
1.引言
當前,人工智能技術的復興正引領著新一代信息技術迅猛發展,由電子驅動的計算處理器在過去十年中發生了巨大的變化,從通用中央處理器(CPU)到定制計算平臺,例如GPU、FPGA和ASIC,以滿足對計算資源無處不在的持續增長的需求。這些硅計算硬件平臺的進步催生了更大規模的訓練和更復雜的模型,極大地促進了人工智能(AI)的復興。我們見證了各種神經計算架構,例如卷積神經網絡(CNN)、遞歸神經網絡(RNN)、脈沖神經網絡(SNN)等,在諸多領域的廣泛應用。
然而傳統電子計算機的架構和性能的發展趨勢已經無法滿足新一代信息技術發展對計算資源的需求。隨著先進光刻工藝的不斷發展,晶體管尺寸已經縮小到10 nm以下,逐漸逼近原子尺寸,這使得芯片的加工難度以及加工成本呈指數式上升。與此同時,隨著晶體管密度的增加,趨勢明顯的漏電流效應加劇了芯片熱功耗,對系統整體散熱能力的需求也不斷上升,已經開始成為限制晶體管密度的另一瓶頸。故而,無論是在硬件實現還是計算架構上,都使得預測晶體管制程的摩爾定律難以維系,新型智能計算架構與芯片研究迫在眉睫。
光具有物理空間最快的傳播速度以及多維度(時間、空間、光譜等)的優勢,這些特性使得光計算成為構建下一代高性能計算的理想范式之一。受益于光計算的顛覆性優勢(高帶寬、高并行、低功耗),相比電子計算,光計算在理論上有望提升6個數量級的能量效率、3個數量級的計算速度。針對如何實現光計算,國際上已經有初步的研究[1,2],一些代表性的技術包括:基于片上光學干涉儀網絡實現任意矩陣變換[3],基于諧振環和諧振腔進行可編程光計算[4],基于衍射連接實現全光神經網絡[5],基于相變材料實現存內光計算[6]等。然而,現階段的光計算仍然面臨算力不足、動態計算困難、訓練效率低下等問題,如何實現大規模、可重構、低功耗的光電計算芯片并支撐人工智能應用仍然面臨原理架構、智能算法、集成工藝等諸多難題。
2.光電智能計算架構和芯片研究
2.1 光電智能計算架構
針對光電智能計算面臨的規模與重構難題,清華大學研究團隊提出了可重構衍射智能計算架構,構建了可重構衍射智能計算處理器(DPU)(圖1(a))[7]。DPU對光學衍射物理現象進行建模,通過大規模的光學互聯,構建高復雜度的光學神經網絡(圖1(b))。此外,DPU充分挖掘了光的波粒二象性,控制光波傳播的波前分布,實現光神經網絡權重的調整,采用光電效應來實現人工神經元,解決大規模光電非線性激活函數這一理論難題。通過高通量可編程的光電器件結合電子計算的靈活特性,實現了高速數據調控以及大規模網絡結構和參數的編程。DPU計算架構中,光計算模塊幾乎承擔了所有的計算操作。因此,運行同樣的神經網絡,光電計算系統與特斯拉V100圖形處理器(GPU)相比,計算速度提高了8倍,系統能效提升超過一個數量級,核心模塊計算能效可以提升4個數量級。
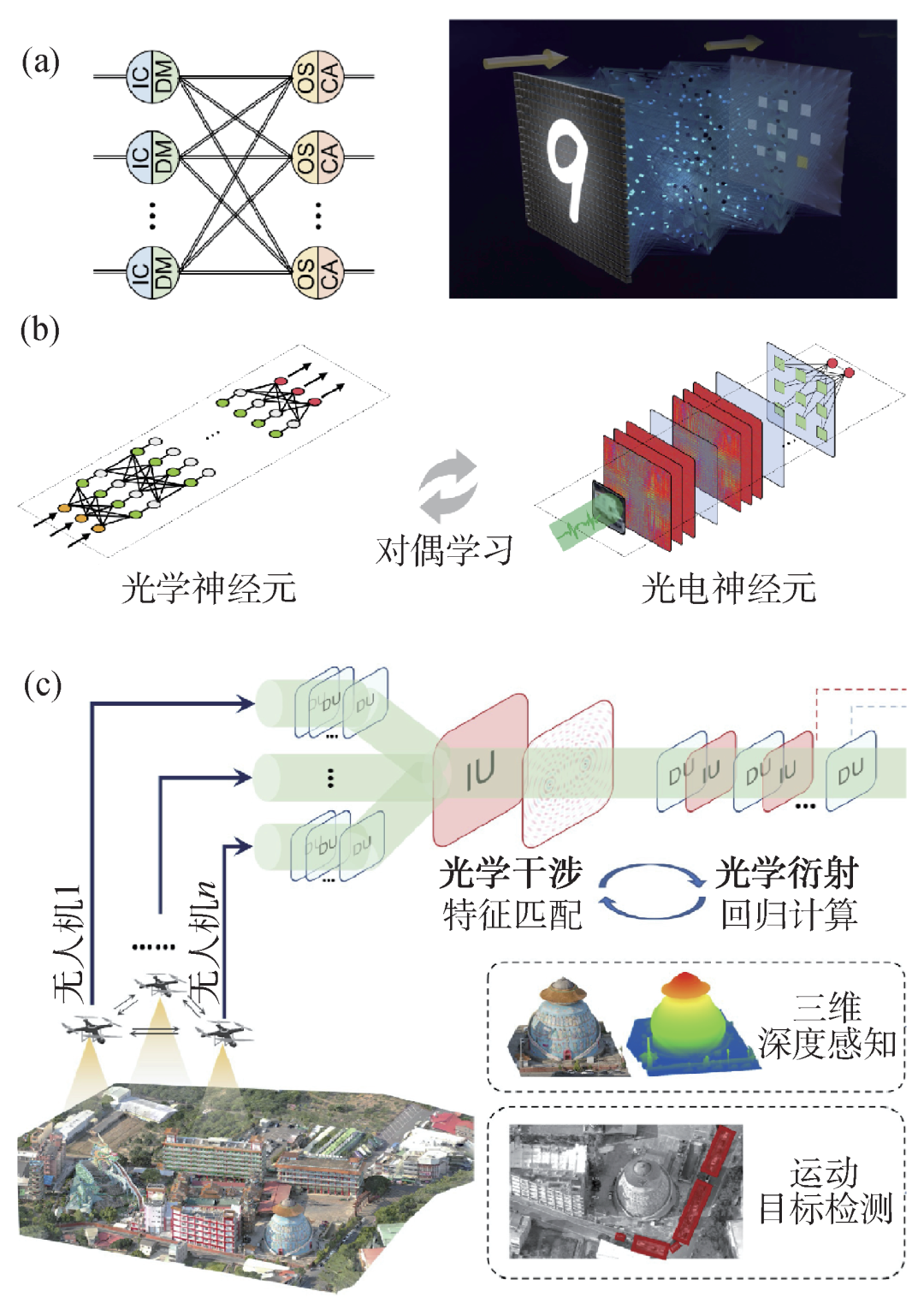
圖1 大規模多通道光電智能計算架構和訓練方法 (a)可重構智能計算處理器;(b)大規模光學神經網絡訓練;(c)多通道光電神經網絡示意圖
研究團隊進一步對光學干涉與衍射進行聯合建模,提出了多通道光電神經網絡的新架構Monet(multi-channel optical neural NETworks)[8],將多個光學通道的光場信息進行融合計算,實現了基于光電智能計算的高維光場信息調制解耦(圖1(c))。其中,編碼投影干涉計算單元(IU),通過相位和偏振的編碼調制以及通道間的光學干涉,實現特征匹配、加權求和等多通道光學基本計算。IU和衍射計算單元(DU)的交替級聯,實現了光場信息的多通道可重構智能計算。Monet架構突破了現有光電神經網絡結構簡單、通道受限等瓶頸,為構建大規模光電神經網絡、探索復雜光場智能感算提供了理論與架構支撐。
目前光電智能計算在高速圖像處理方面有突出表現,但現有架構難以挖掘高速動態光場的時間維度特性,動態計算受制于電子內存讀寫的瓶頸,難以滿足面向超快動態現象開展實時智能分析的現實需求。研究團隊提出了空時域智能光計算架構[9],刻畫多維光場傳播模型,建立空時域光計算表征,在空間和時序維度上同時完成連續光計算(圖2(a))。研究團隊還提出了空間復用和光譜復用的智能計算模型(圖2(b)),匹配空時域光計算維度,建立時序矩陣乘加計算模型,實現了三維空時域智能光計算。空時域光計算的空間和時序計算操作均在光學模擬域完成,突破了數字內存讀寫的掣肘,將動態機器視覺處理的速度提升了3個數量級(達到納秒量級)。
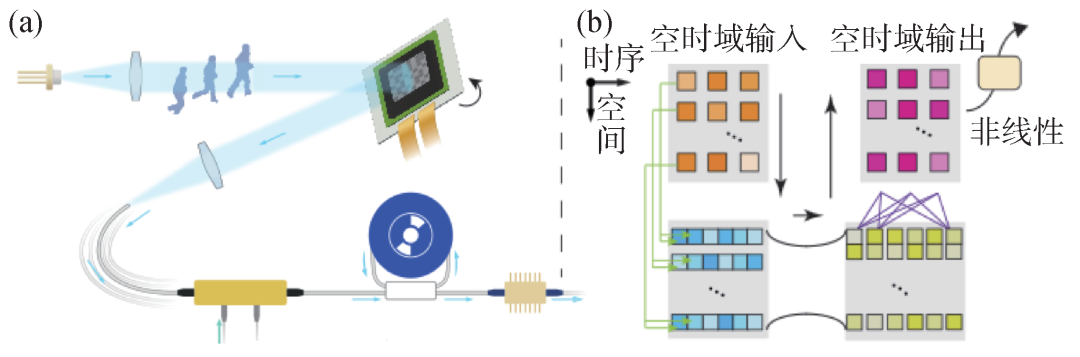
圖2 空時域動態光計算 (a)空時域動態光計算系統示意圖;(b)空時域動態光計算模型
現有光電神經網絡學習架構僅能支撐小規模訓練,其網絡容量和特征捕獲能力不足以有效處理ImageNet等大型復雜數據集。為了解決大規模光電神經網絡中優化速度慢、資源消耗高、收斂效果差等問題,研究團隊提出了面向大規模光電智能計算的“光學—人工雙神經元學習架構DANTE(DuAl-Neuron opTical-artificial lEarning)[10]。其中光學神經元精準建模光場計算過程,人工神經元以輕量映射函數建立跳躍連接,助力梯度傳播,全局人工神經元與局部光學神經元以交替學習的機制進行迭代優化,在確保學習有效性的同時,大大降低了訓練的時空復雜度,使得訓練更大更深的光電神經網絡成為可能。DANTE突破了大規模光電神經網絡物e理建模復雜、參數優化困難等桎梏,網絡規模提升一至兩個數量級,訓練學習速度提升2個數量級。
2.2 全模擬光電智能計算芯片
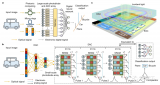
在上述系列新架構的基礎上,研究團隊研制了國際首個全模擬光電智能計算芯片ACCEL(圖3)[11,12],在一枚芯片上突破性地實現了大規模計算單元集成、光計算與電子信號計算的高效接口。其核心思想是通過全模擬的光電計算方式來降低對大規模光電二極管陣列和高功耗模擬數字轉換器(ADC)陣列的依賴,實現光學和電子計算的高效集成。ACCEL的工作原理涉及兩個主要模塊,即光學模擬計算(OAC)和電子模擬計算(EAC)。OAC通過多層衍射光學計算模塊,以光速提取高分辨率圖像的特征,降低圖像維度并減少光電轉換需求。EAC包括一個32×32的光電二極管陣列,作為非線性激活器,將光學信號轉換為模擬電子信號,實現類似二進制加權的全連接神經網絡。ACCEL芯片以全模擬方式進行計算,適用于廣泛的應用,并與數字神經網絡兼容。
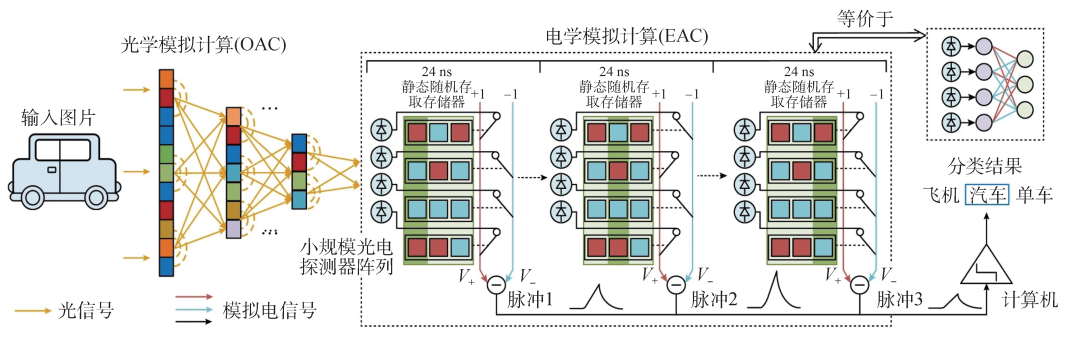
圖3 全模擬光電智能計算芯片(ACCEL)工作原理圖
ACCEL通過數值模擬和實驗驗證,在低光條件下展現出優異的穩健性。對于輸入光強的降低,ACCEL通過模擬噪聲對輸出進行精準校準,可以成功應對多種干擾。在可重構方面,同一OAC在不同任務中均取得了顯著效果。通過OAC對多個數據集的聯合訓練,ACCEL在不同領域的應用中取得了出色的泛化性能,為實際工業檢測等場景提供了關鍵的靈活性。與現有高性能芯片相比,ACCEL芯片的算力(單位時間的運算次數)提升了3000倍,系統級能效(單位能量可進行的運算數)提升了400萬余倍。對于10類MNIST分類和3類ImageNet分類,ACCEL各達到9.49×103 TOPS/W和7.48×104 TOPS/W (1 TOPS/W表示在1 W功耗的情況下,處理器可以進行1012次操作)的系統能效,展示了其在能效方面的優越性。ACCEL作為一種全新的光電神經網絡,通過其獨特的設計和卓越的性能,在人工智能硬件領域嶄露頭角。其在圖像分類、視頻判斷和低光條件下的穩健性等方面的優異表現,為未來神經網絡研究和應用開辟了新的前景。
3.總結
光電智能計算作為一種新興計算范式,將為后摩爾時代的人工智能高效訓練和推理帶來新的契機。光子智能芯片的研究將極大促進人工智能的發展,為大規模數據的高效智能處理、大場景多對象光場智能感算、高速低功耗智能無人系統、超高速科學研究等奠定基礎,具有廣闊的應用前景。
-
處理器
+關注
關注
68文章
19404瀏覽量
230768 -
芯片
+關注
關注
456文章
51154瀏覽量
426212 -
神經網絡
+關注
關注
42文章
4779瀏覽量
101040 -
人工智能
+關注
關注
1794文章
47642瀏覽量
239625
原文標題:光電智能計算
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
光電倍增管中子直照響應實驗研究
CPU、架構、指令集與芯片的關系與區別
集成光電智能探測器SOC研究
基于云計算的架構模型研究
自主研發的多核智能計算架構研究 解析
達爾文芯片建立引領未來的新型計算機體系架構
芯片架構計算任務改變對計算架構的需求

清華大學開發出超高速光電計算芯片,性能是商用芯片的3000倍!





 工商網監
工商網監
評論