 kafka基本原理詳解
kafka基本原理詳解
前言
大家好,這里是浩道Linux,主要給大家分享Linux、Python、網絡通信、網絡安全等相關的IT知識平臺。
今天浩道跟大家分享一篇關于kafka相關原理的硬核干貨,可以說即使你沒有接觸過kafka,也可以秒懂,一起看看!
一、Kafka 基礎
消息系統的作用
應該大部份小伙伴都清楚,用機油裝箱舉個例子
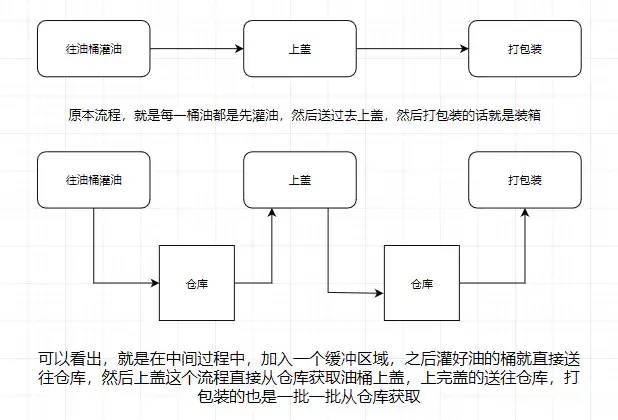
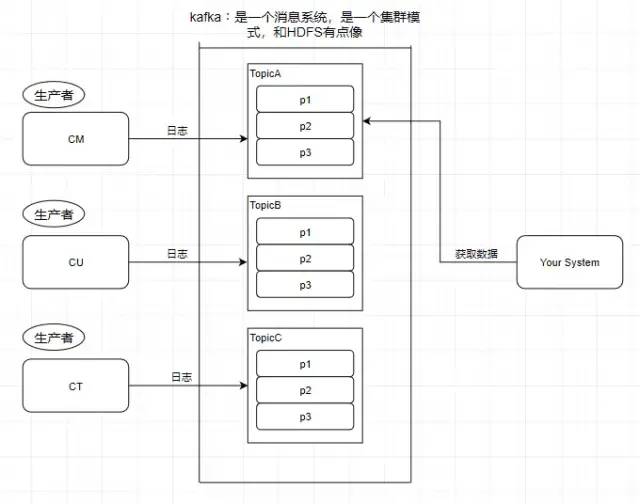
所以消息系統就是如上圖我們所說的倉庫,能在中間過程作為緩存,并且實現解耦合的作用。 引入一個場景,我們知道中國移動,中國聯通,中國電信的日志處理,是交給外包去做大數據分析的,假設現在它們的日志都交給了你做的系統去做用戶畫像分析。
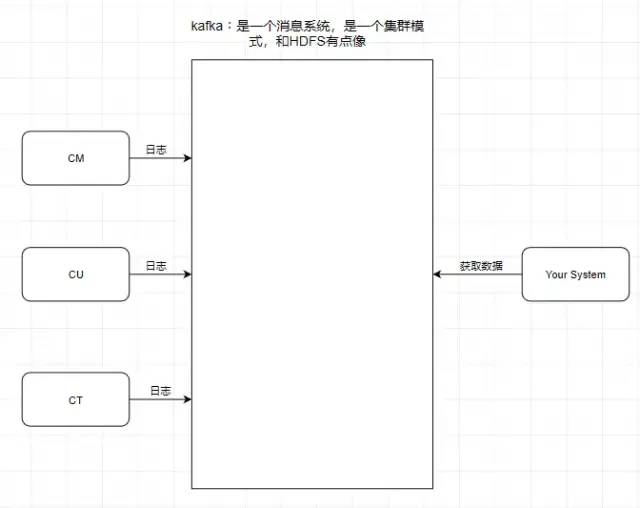
按照剛剛前面提到的消息系統的作用,我們知道了消息系統其實就是一個模擬緩存,且僅僅是起到了緩存的作用而并不是真正的緩存,數據仍然是存儲在磁盤上面而不是內存。
1.Topic 主題
kafka 學習了數據庫里面的設計,在里面設計了topic(主題),這個東西類似于關系型數據庫的表。
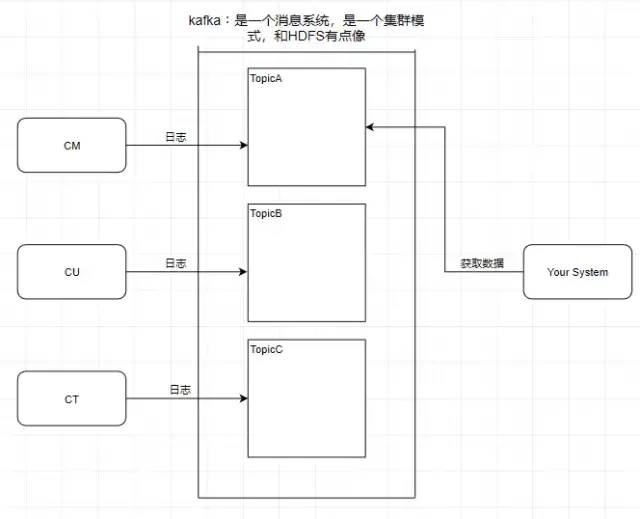
此時我需要獲取中國移動的數據,那就直接監聽 TopicA 即可
2.Partition 分區
kafka還有一個概念叫Partition(分區),分區具體在服務器上面表現起初就是一個目錄,一個主題下面有多個分區,這些分區會存儲到不同的服務器上面,或者說,其實就是在不同的主機上建了不同的目錄。這些分區主要的信息就存在了.log文件里面。跟數據庫里面的分區差不多,是為了提高性能。
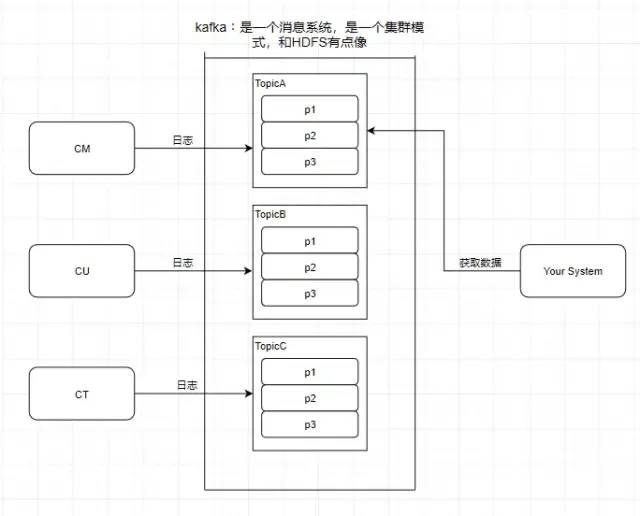
至于為什么提高了性能,很簡單,多個分區多個線程,多個線程并行處理肯定會比單線程好得多
Topic 和 partition 像是 HBASE 里的 table 和 region 的概念,table 只是一個邏輯上的概念,真正存儲數據的是 region,這些 region 會分布式地存儲在各個服務器上面,對應于kafka,也是一樣,Topic 也是邏輯概念,而 partition 就是分布式存儲單元。
這個設計是保證了海量數據處理的基礎。我們可以對比一下,如果 HDFS 沒有 block 的設計,一個 100T 的文件也只能單獨放在一個服務器上面,那就直接占滿整個服務器了,引入 block后,大文件可以分散存儲在不同的服務器上。
注意:
分區會有單點故障問題,所以我們會為每個分區設置副本數
分區的編號是從0開始的
3.Producer - 生產者
往消息系統里面發送數據的就是生產者
4.Consumer - 消費者
從 kafka 里讀取數據的就是消費者
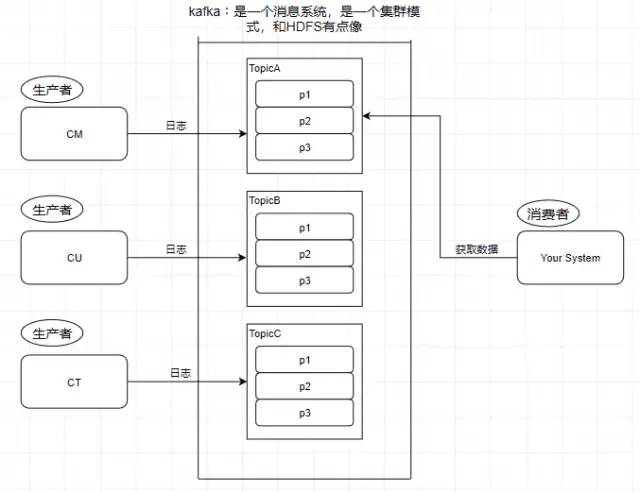
5.Message - 消息
kafka 里面的我們處理的數據叫做消息
二、kafka的集群架構
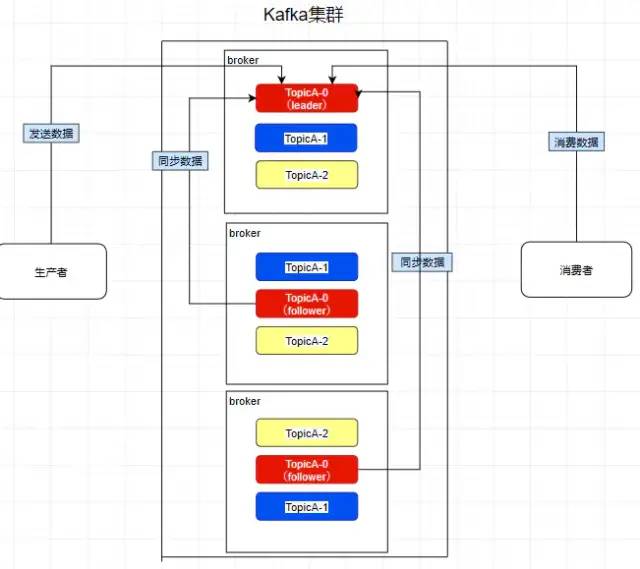
創建一個 TopicA 的主題,3個分區分別存儲在不同的服務器,也就是 broker 下面。Topic 是一個邏輯上的概念,并不能直接在圖中把 Topic 的相關單元畫出
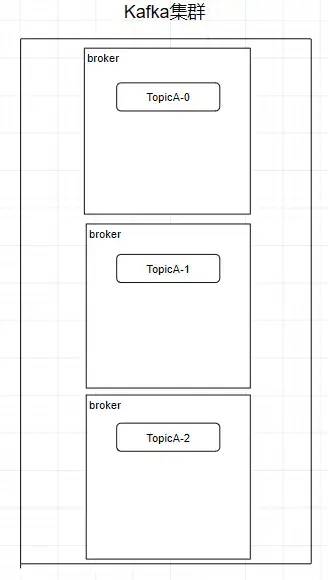
需要注意:kafka在0.8版本以前是沒有副本機制的,所以在面對服務器宕機的突發情況時會丟失數據,所以盡量避免使用這個版本之前的kafka
Replica - 副本
kafka 中的 partition 為了保證數據安全,所以每個 partition 可以設置多個副本。 此時我們對分區 0,1,2 分別設置 3 個副本(其實設置兩個副本是比較合適的)
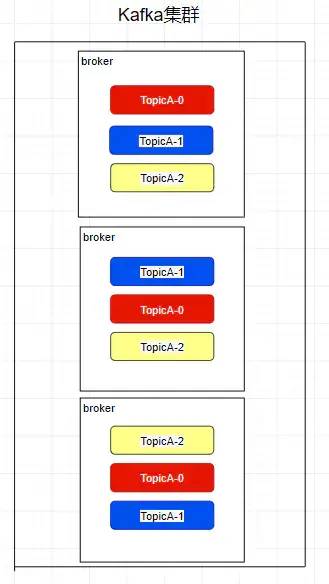
而且其實每個副本都是有角色之分的,它們會選取一個副本作為 leader,而其余的作為follower,我們的生產者在發送數據的時候,是直接發送到 leader partition 里面,然后follower partition 會去 leader 那里自行同步數據,消費者消費數據的時候,也是從leader那去消費數據的。
Consumer Group - 消費者組
我們在消費數據時會在代碼里面指定一個 group.id,這個 id 代表的是消費組的名字,而且這個 group.id 就算不設置,系統也會默認設置。
conf.setProperty("group.id","tellYourDream")
我們所熟知的一些消息系統一般來說會這樣設計,就是只要有一個消費者去消費了消息系統里面的數據,那么其余所有的消費者都不能再去消費這個數據。可是 kafka 并不是這樣,比如現在 consumerA 去消費了一個 topicA 里面的數據。
consumerA:
group.id = a
consumerB:
group.id = a
consumerC:
group.id = b
consumerD:
group.id = b
再讓 consumerB 也去消費 TopicA 的數據,它是消費不到了,但是我們在 consumerC中重新指定一個另外的 group.id,consumerC 是可以消費到 topicA 的數據的。而consumerD 也是消費不到的,所以在 kafka 中,不同組可有唯一的一個消費者去消費同一主題的數據。 所以消費者組就是讓多個消費者并行消費信息而存在的,而且它們不會消費到同一個消息,如下,consumerA,B,C是不會互相干擾的
consumer group:a
consumerA
consumerB
consumerC
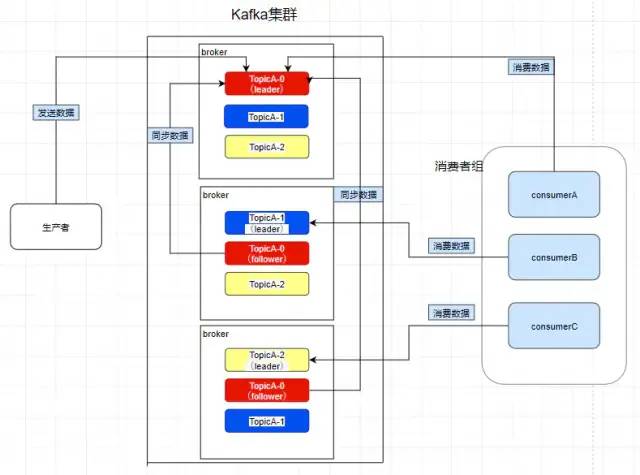
如圖,因為前面提到過了消費者會直接和leader建立聯系,所以它們分別消費了三個leader,所以一個分區不會讓消費者組里面的多個消費者去消費,但是在消費者不飽和的情況下,一個消費者是可以去消費多個分區的數據的。
Controller
熟知一個規律:在大數據分布式文件系統里面,95%的都是主從式的架構,個別是對等式的架構,比如 ElasticSearch。 kafka也是主從式的架構,主節點就叫controller,其余的為從節點,controller是需要和zookeeper 進行配合管理整個kafka集群。
kafka和zookeeper如何配合工作
kafka嚴重依賴于zookeeper集群(所以之前的zookeeper文章還是有點用的)。所有的broker在啟動的時候都會往zookeeper進行注冊,目的就是選舉出一個controller,這個選舉過程非常簡單粗暴,就是一個誰先誰當的過程,不涉及什么算法問題。 那成為controller之后要做啥呢,它會監聽zookeeper里面的多個目錄,例如有一個目錄/brokers/,其他從節點往這個目錄上注冊(就是往這個目錄上創建屬于自己的子目錄而已)自己,這時命名規則一般是它們的id編號,比如/brokers/0,1,2 注冊時各個節點必定會暴露自己的主機名,端口號等等的信息,此時controller就要去讀取注冊上來的從節點的數據(通過監聽機制),生成集群的元數據信息,之后把這些信息都分發給其他的服務器,讓其他服務器能感知到集群中其它成員的存在。 此時模擬一個場景,我們創建一個主題(其實就是在zookeeper上/topics/topicA這樣創建一個目錄而已),kafka會把分區方案生成在這個目錄中,此時controller就監聽到了這一改變,它會去同步這個目錄的元信息,然后同樣下放給它的從節點,通過這個方法讓整個集群都得知這個分區方案,此時從節點就各自創建好目錄等待創建分區副本即可。這也是整個集群的管理機制。
加餐時間
1.Kafka性能好在什么地方?
① 順序寫
操作系統每次從磁盤讀寫數據的時候,需要先尋址,也就是先要找到數據在磁盤上的物理位置,然后再進行數據讀寫,如果是機械硬盤,尋址就需要較長的時間。 kafka的設計中,數據其實是存儲在磁盤上面,一般來說,會把數據存儲在內存上面性能才會好。但是kafka用的是順序寫,追加數據是追加到末尾,磁盤順序寫的性能極高,在磁盤個數一定,轉數達到一定的情況下,基本和內存速度一致隨機寫的話是在文件的某個位置修改數據,性能會較低。
② 零拷貝
先來看看非零拷貝的情況
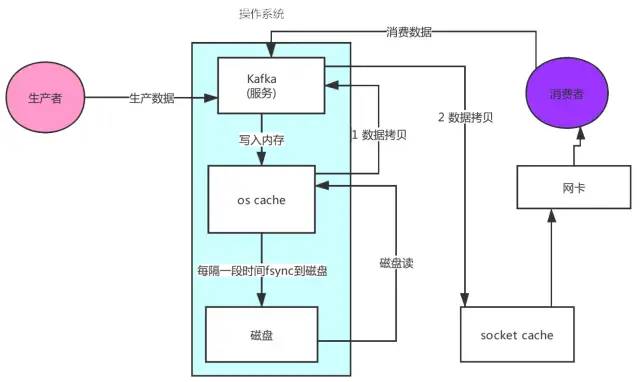
可以看到數據的拷貝從內存拷貝到 kafka 服務進程那塊,又拷貝到socket緩存那塊,整個過程耗費的時間比較高,kafka 利用了 Linux 的 sendFile 技術(NIO),省去了進程切換和一次數據拷貝,讓性能變得更好。
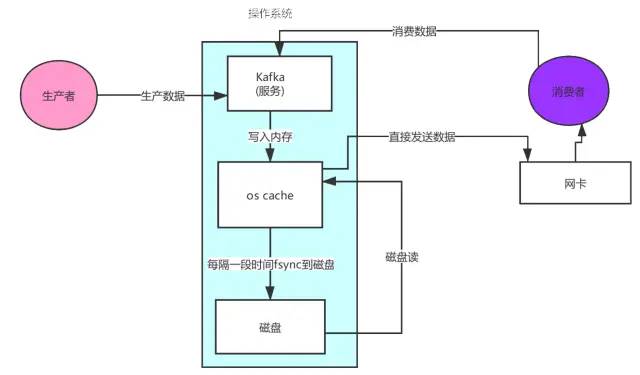
2.日志分段存儲
Kafka規定了一個分區內的.log文件最大為1G,做這個限制目的是為了方便把.log加載到內存去操作
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex 00000000000005367851.index 00000000000005367851.log 00000000000005367851.timeindex 00000000000009936472.index 00000000000009936472.log 00000000000009936472.timeindex
3.Kafka的網絡設計
kafka的網絡設計和Kafka的調優有關,這也是為什么它能支持高并發的原因
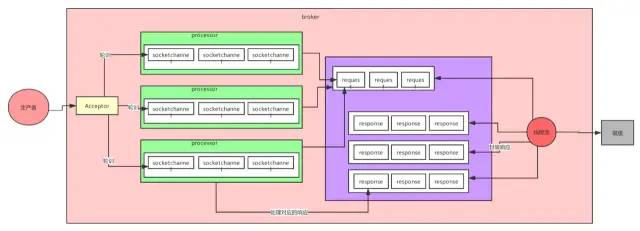
首先客戶端發送請求全部會先發送給一個Acceptor,broker里面會存在3個線程(默認是3個),這3個線程都是叫做processor,Acceptor不會對客戶端的請求做任何的處理,直接封裝成一個個socketChannel發送給這些processor形成一個隊列,發送的方式是輪詢,就是先給第一個processor發送,然后再給第二個,第三個,然后又回到第一個。消費者線程去消費這些socketChannel時,會獲取一個個request請求,這些request請求中就會伴隨著數據。 線程池里面默認有8個線程,這些線程是用來處理request的,解析請求,如果request是寫請求,就寫到磁盤里。讀的話返回結果。processor會從response中讀取響應數據,然后再返回給客戶端。這就是Kafka的網絡三層架構。 所以如果我們需要對kafka進行增強調優,增加processor并增加線程池里面的處理線程,就可以達到效果。request和response那一塊部分其實就是起到了一個緩存的效果,是考慮到processor們生成請求太快,線程數不夠不能及時處理的問題。 所以這就是一個加強版的reactor網絡線程模型。
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11380瀏覽量
211364 -
python
+關注
關注
56文章
4813瀏覽量
85319 -
kafka
+關注
關注
0文章
52瀏覽量
5270
原文標題:對 Kafka 陌生的,可以看看這篇!
文章出處:【微信號:浩道linux,微信公眾號:浩道linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論