") 如何使用NVIDIA DeepStream和Edge Impulse快速推進(jìn)計(jì)算機(jī)視覺部署
如何使用NVIDIA DeepStream和Edge Impulse快速推進(jìn)計(jì)算機(jī)視覺部署
基于 AI 的計(jì)算機(jī)視覺(CV)應(yīng)用日益增多,這對(duì)于從視頻流中提取實(shí)時(shí)洞察至關(guān)重要。這項(xiàng)革命性的技術(shù)使作業(yè)人員能夠在沒有大量操作干預(yù)的情況下獲得有價(jià)值的信息,從而為創(chuàng)新和解決問題帶來(lái)了新的可能性。
NVIDIA DeepStream SDK 專門用于那些使用機(jī)器學(xué)習(xí)(ML)從視頻流中提取深入洞察的智能視頻分析(IVA)用例。在 NVIDIA 硬件上運(yùn)行時(shí),它使用 GPU 加速 ML,同時(shí)使用加速硬件實(shí)現(xiàn)預(yù)處理性能的最大化。
本文將探討用于模型開發(fā)的 Edge Impulse 與用于部署的 NVIDIA DeepStream SDK 相結(jié)合的潛力,以便快速創(chuàng)建端到端應(yīng)用。
計(jì)算機(jī)視覺應(yīng)用
在如今的環(huán)境中,快速構(gòu)建復(fù)雜、可擴(kuò)展的 CV 應(yīng)用的能力至關(guān)重要。典型的 CV 應(yīng)用涵蓋了各種用例,包括車輛識(shí)別、流量測(cè)量、檢測(cè)系統(tǒng)、生產(chǎn)線質(zhì)量控制、通過(guò)監(jiān)控加強(qiáng)安全和安保、智能結(jié)賬系統(tǒng)和過(guò)程測(cè)量等。
將機(jī)器智能進(jìn)行集成來(lái)分析業(yè)務(wù)流程中的多媒體流可以帶來(lái)巨大的價(jià)值。憑借無(wú)與倫比的準(zhǔn)確性和可靠性,機(jī)器智能可以幫助精簡(jiǎn)運(yùn)維,從而提高效率。
預(yù)建的 AI 模型有時(shí)并不是合適的解決方案,并且往往需要針對(duì)其未考慮到的特定問題來(lái)進(jìn)行微調(diào)。
構(gòu)建基于 AI 的 CV 應(yīng)用通常需要三種技能:MLOps、CV 應(yīng)用開發(fā)和部署(DevOps)。如果沒有這些專業(yè)技能,項(xiàng)目的投資回報(bào)率和交付時(shí)間都可能面臨風(fēng)險(xiǎn)。
過(guò)去,復(fù)雜的 CV 應(yīng)用需要高度專業(yè)化的開發(fā)人員,因此需要耗費(fèi)較長(zhǎng)的學(xué)習(xí)周期和昂貴的資源。
Edge Impulse 與 NVIDIA DeepStream SDK 的組合提供了一個(gè)用戶友好的互補(bǔ)解決方案堆棧,可幫助開發(fā)人員快速創(chuàng)建 IVA 解決方案。您可以針對(duì)特定用例輕松自定義應(yīng)用,將 NVIDIA 硬件直接集成到您的解決方案中。
DeepStream 可免費(fèi)使用,Edge Impulse 則提供了一個(gè)免費(fèi)層,適合許多 ML 模型構(gòu)建用例。
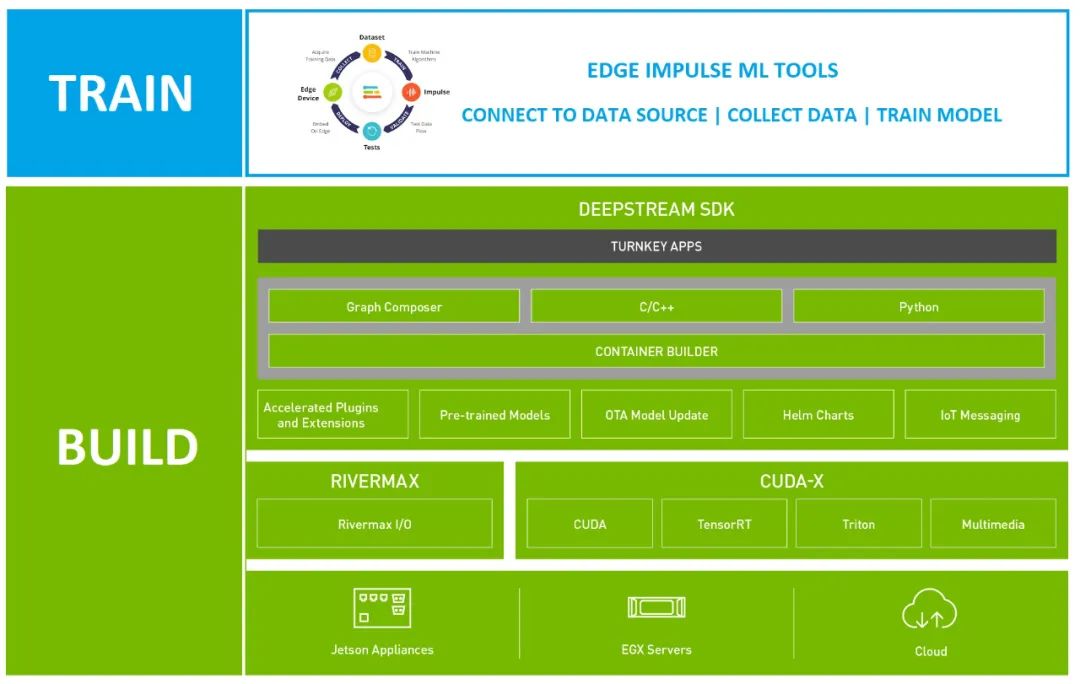
圖 1. Edge Impulse 和 NVIDIADeepStream SDK 解決方案堆棧
使用 NVIDIA DeepStream
構(gòu)建 CV 應(yīng)用
Deepstream SDK 是 NVIDIA Metropolis 的一個(gè)組件,旨在支持大規(guī)模的視頻分析。您可以快速、輕松地創(chuàng)建可直接部署在 NVIDIA 硬件設(shè)備上的生產(chǎn)就緒 CV 管線。
DeepStream 應(yīng)用的構(gòu)建方法如下:
從命令行進(jìn)行構(gòu)建
使用 Graph Composer 以可視化的方式進(jìn)行構(gòu)建
使用 DeepStream 參考應(yīng)用和配置文件進(jìn)行構(gòu)建,無(wú)需代碼
使用 C++ 或 Python 代碼進(jìn)行進(jìn)一步自定義
如果您不是開發(fā)人員,可以使用前三種方法中的任何一種,不到一小時(shí)就能搭建好管線,并與訓(xùn)練好的 ML 模型一起運(yùn)行。如果您需要更多自定義功能,可以使用現(xiàn)有模板來(lái)構(gòu)建一個(gè)自定義編碼的解決方案。
部署 CV 應(yīng)用
在創(chuàng)建管線后,您可以直接將其部署到 NVIDIA 硬件設(shè)備上,如邊緣設(shè)備(如 NVIDIA Jetson Nano)、高性能計(jì)算(HPC)和云部署,以及混合部署等。
您可以將應(yīng)用部署在 NVIDIA 邊緣硬件上在本地運(yùn)行,并直接連接視頻源,以減少延遲。如果您需要處理復(fù)雜的管線或容納超出 NVIDIA 邊緣設(shè)備能力的多個(gè)視頻源,可以將相同的管線部署到您首選的 IaaS 供應(yīng)商的 NVIDIA 云實(shí)例上。
您也可以采用混合部署的方法,將管線部署到 NVIDIA 邊緣設(shè)備上,然后使用 NVIDIA Triton 推理服務(wù)器遠(yuǎn)程執(zhí)行推理。
Triton 能夠遠(yuǎn)程執(zhí)行模型,接收來(lái)自客戶端的輸入幀并返回結(jié)果。Triton 可使用 NVIDIA GPU,也可在 x86 上執(zhí)行推理,并支持并發(fā)和動(dòng)態(tài)批處理。Triton 還支持大多數(shù)常用的框架,包括 TensorFlow 和 PyTorch。
DeepStream 通過(guò)名為 Gst-nvinferserver 的 Gst-nvinfer 推理插件支持 Triton。通過(guò)使用該插件,您可以在 DeepStream 應(yīng)用中使用 Triton 實(shí)例。
IVA 應(yīng)用的好壞取決于構(gòu)建時(shí)所使用的 ML 模型。雖然有許多預(yù)構(gòu)建模型可以使用,但用例往往需要自定義模型和 MLOps 工作流。因此需要有一個(gè)易于使用的 MLOps 平臺(tái)來(lái)實(shí)現(xiàn)快速部署,尤其在與 DeepStream 快速應(yīng)用開發(fā)相結(jié)合時(shí)。
用于機(jī)器學(xué)習(xí)的 Edge Impulse
Edge Impulse 提供了一套功能強(qiáng)大的 ML 模型構(gòu)建工具,這些模型可以直接部署到 NVIDIA 目標(biāo)上并導(dǎo)入進(jìn) DeepStream 應(yīng)用中。通過(guò)無(wú)縫集成 NVIDIA 硬件加速和 DeepStream SDK,Edge Impulse 能夠幫助您快速擴(kuò)展項(xiàng)目。
Edge Impulse 在整個(gè)過(guò)程中為各級(jí)開發(fā)人員提供指導(dǎo)。經(jīng)驗(yàn)豐富的 ML 專業(yè)人員將享受到從不同來(lái)源導(dǎo)入數(shù)據(jù)的便捷性和端到端模型構(gòu)建流程。您還可以將自定義模型與自定義學(xué)習(xí)塊功能集成在一起,為 MLOps 減輕繁重的工作。
如果您是機(jī)器學(xué)習(xí)新手,Edge Impulse 流程會(huì)在您使用該環(huán)境時(shí)指導(dǎo)構(gòu)建基本模型。可以在 DeepStream 中使用的基本模型類型包括 YOLO 對(duì)象檢測(cè)和分類。
您還可以改造專為 tinyML 目標(biāo)構(gòu)建的模型,使其適用于邊緣用例和功能更強(qiáng)大的 NVIDIA 硬件。許多邊緣 AI 用例涉及復(fù)雜的應(yīng)用,需要更強(qiáng)大的計(jì)算資源。NVIDIA 硬件可以幫助解決與受限設(shè)備的局限性相關(guān)的挑戰(zhàn)。
您可以使用 Edge Impulse 從頭開始創(chuàng)建自己的模型,Edge Impulse 還集成了 NVIDIA TAO 工具套件,可以使用 Computer Vision Model Zoo 中的一百多個(gè)預(yù)訓(xùn)練模型。Edge Impulse 是 TAO 的補(bǔ)充,可用于將這些模型調(diào)整為自定義應(yīng)用,這對(duì)企業(yè)用戶來(lái)說(shuō)是一個(gè)很好的出發(fā)點(diǎn)。
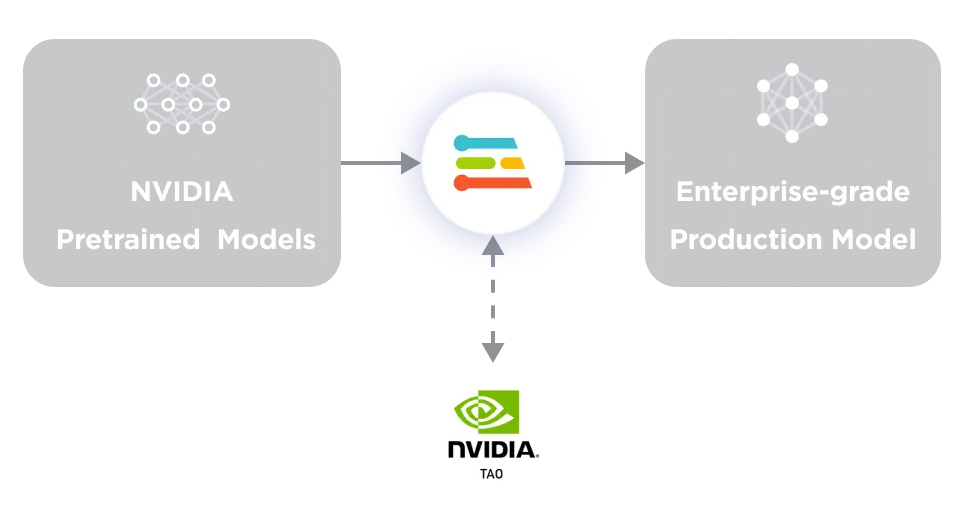
圖 2. NVIDIA TAO 與
Edge Impulse Enterprise 相結(jié)合
使用 Edge Impulse 構(gòu)建
適用于 DeepStream 的模型
在構(gòu)建完模型后,將該模型部署到 DeepStream 中。從 Edge Impulse 導(dǎo)出模型文件并將其導(dǎo)入到 DeepStream 項(xiàng)目中。然后按照配置步驟操作,確保您的 Edge Impulse 模型能與 DeepStream 配合使用。該流程一般包括四個(gè)步驟(圖 3)。

圖 3. 將模型文件從 Edge Impulse
部署到 NVIDIA DeepStream 的四個(gè)步驟
第 1 步:
在 Edge Impulse 中構(gòu)建模型
首先在 Edge Impulse Studio 中構(gòu)建 YOLO 或圖像分類模型。DeepStream 推理 Gst-nvinfer 插件要求輸入層的張量為 NCHW 格式。請(qǐng)務(wù)必選擇 Jetson Nano 作為目標(biāo),并使用 FP32 權(quán)重。
第 2 步:
從 Edge Impulse 導(dǎo)出模型
Edge Impulse 可以從 Edge Impulse Studio 的儀表盤頁(yè)面中導(dǎo)出模型。YOLOv5 可以導(dǎo)出為帶有 NCHW 輸入層的 ONNX,以便與 DeepStream 一起使用。
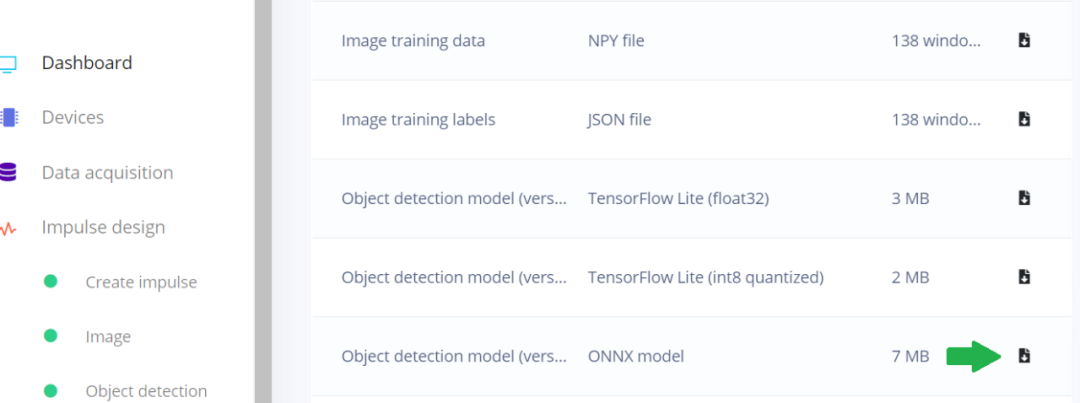
圖 4. Edge Impulse Studio 儀表盤
顯示如何導(dǎo)出為 ONNX 模型
DeepStream 中的 IVA 管線通常由一個(gè)主要推理(PGIE)步驟組成,該步驟使用邊界框坐標(biāo)執(zhí)行對(duì)象檢測(cè)。相關(guān)的對(duì)象類別會(huì)傳遞給二級(jí)推理步驟(SGIE),后者會(huì)對(duì)每個(gè)對(duì)象進(jìn)行分類。每個(gè)步驟都以 Gst-nvinfer 插件實(shí)例的形式實(shí)現(xiàn)。
第 3 步:
將模型轉(zhuǎn)換成與 DeepStream
兼容的 ONNX 格式
在將 YOLO 與 DeepStream 結(jié)合使用時(shí),需要使用一個(gè)自定義輸出層解析器來(lái)從輸出層中提取邊界框和對(duì)象類別,然后將其傳遞給下一個(gè)插件。有關(guān)自定義 YOLO 輸出解析器的詳細(xì)信息,請(qǐng)參見如何使用自定義 YOLO 模型:
https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_custom_YOLO.html
Edge Impulse 使用的 YOLOv5 是一種更新、性能更強(qiáng)大的模型,其輸出張量格式與 YOLOv3 略有不同。YOLOv3 有三個(gè)輸出層,分別負(fù)責(zé)檢測(cè)不同尺度的物體,而 YOLOv5 只有一個(gè)輸出層,使用錨框來(lái)處理各種尺寸的物體。
DeepStream 基于專門用于多媒體用例的 GStreamer。NVIDIA 在 GStreamer 管線中添加了支持深度學(xué)習(xí)的功能,包括額外的 ML 相關(guān)元數(shù)據(jù),這些元數(shù)據(jù)通過(guò) Gst-Buffer 在管線中傳遞,并通過(guò) Gst-Buffer 封裝在 NvDsBatchMeta 結(jié)構(gòu)中。
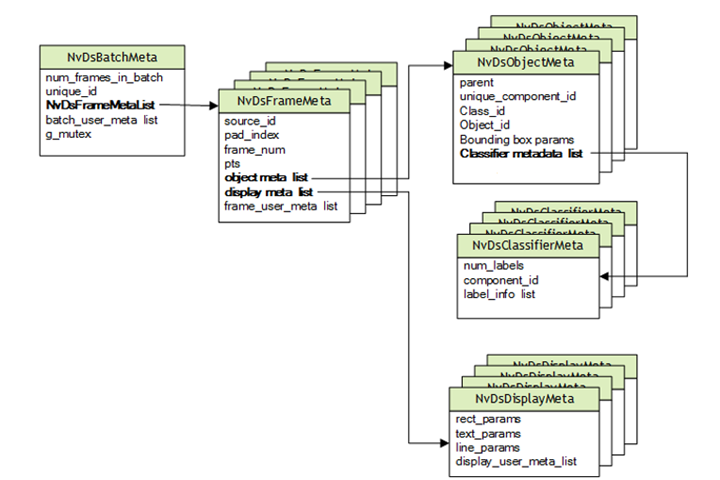
圖 5. DeepStream 元數(shù)據(jù)層次
YOLO 的輸出張量不同于 DeepStream 所需的邊界框數(shù)據(jù),這些邊界框數(shù)據(jù)保存在 NvDsObjectMeta 中。為了將 YOLO 與 DeepStream 結(jié)合使用,就需要一個(gè)自定義輸出解析器來(lái)轉(zhuǎn)換 YOLO 輸出,以滿足 NvDsObjectMeta 在運(yùn)行時(shí)的要求。NVIDIA 提供了一個(gè)通過(guò) YOLOv3 運(yùn)行的示例插件。
Edge Impulse 使用 YOLOv5。YOLOv3 和 YOLOv5 在輸出層之間的差異使得 YOLOv3 插件不適合與 YOLOv5 一起使用(圖 6)。
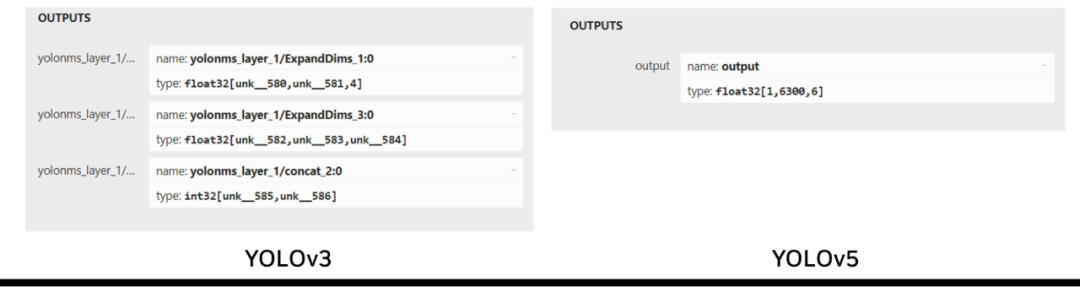
圖 6. YOLOv3 和 YOLOv5 輸出張量結(jié)構(gòu)的比較
要使用在 Edge Impulse 中訓(xùn)練的 YOLOv5 模型,必須創(chuàng)建一個(gè)自定義的 YOLOv5 輸出解析器來(lái)處理單個(gè)輸出張量。可以使用的一種實(shí)現(xiàn)方式是與 Edge Impulse ONNX 格式導(dǎo)出模型一起工作的第三方輸出解析器。
對(duì)于圖像分類模型,需要將 Edge Impulse 以 NHWC 格式提供的默認(rèn) TFLite Float32 及其輸入層轉(zhuǎn)換為 NCHW 格式。
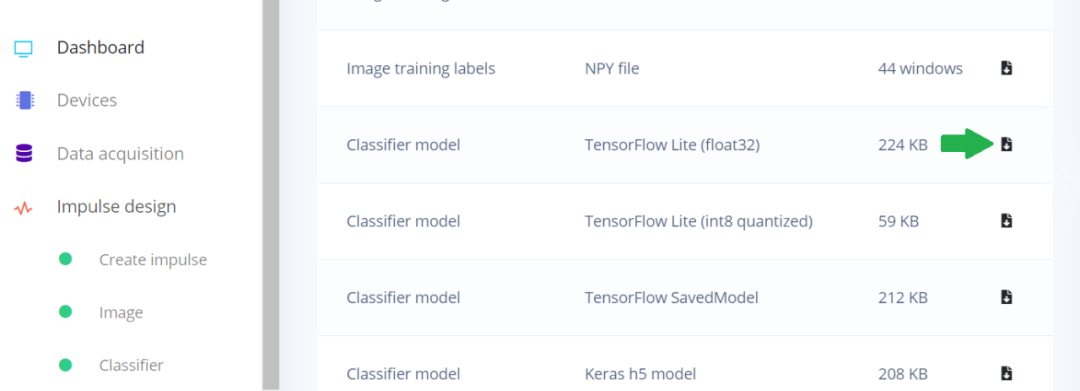
圖 7. Edge Impulse Studio 儀表盤
顯示 TFLight Float32 的位置
使用以下 tf2onnx 命令即可輕松實(shí)現(xiàn):
python -m tf2onnx.convert --inputs-as-nchw serving_default_x:0 --opset 13 --tflite MODELFILE --output OUTPUT.ONNX
MODELFILE 是輸入文件,OUTPUT.ONNX 是輸出文件,Edge Impulse 生成的輸入層名稱被指定為 serving_default_x:0。因此,該輸入層經(jīng)過(guò)轉(zhuǎn)換后符合 DeepStream 的要求。

圖 8. Edge Impulse 默認(rèn)輸入層形狀
與 DeepStream Gst-nvinfer 插件比較
第 4 步:
創(chuàng)建推理插件配置文件
DeepStream 要求為 Gst-nvinfer 插件的每個(gè)實(shí)例創(chuàng)建純文本配置文件,以指定運(yùn)行時(shí)要求,其中包括 ONNX 模型文件或生成的 TRT 引擎文件,以及包含標(biāo)簽名稱的文本文件。圖 9 顯示了使用 Edge Impulse YOLOv5 和分類模型所需的最小參數(shù)集。

圖 9. 使用 Edge Impulse 所創(chuàng)建的模型
的 Gst-nvinfer 插件配置參數(shù)
請(qǐng)注意,雖然為了便于說(shuō)明,注釋與參數(shù)并列顯示,但所有配置參數(shù)都應(yīng)另起一行。
process-mode參數(shù)可用于指定插件是一級(jí)還是二級(jí)。請(qǐng)注意,在指定 ONNX 文件后,DeepStream 會(huì)使用 trtexec 生成 NVIDIA TensorRT 在 NVIDIA GPU 上執(zhí)行的 TensorRT 引擎。
創(chuàng)建該引擎后,使用model-engine-file參數(shù)指定該引擎。可以注釋掉 model-file參數(shù),以防止在每次運(yùn)行時(shí)都重新創(chuàng)建引擎,從而節(jié)省啟動(dòng)時(shí)間。
根據(jù) model-color-mode(模型是 RGB 還是灰度)的不同,該參數(shù)必須分別設(shè)置為 0 或 2。這將與 Edge Impulse Studio 中設(shè)置的顏色深度相對(duì)應(yīng)。
上例展示了如何將該模型用作主推理插件。通過(guò)設(shè)置 process-mode屬性,也可以將該模型用作第二階段分類器:
process-mode=2 #SGIE
圖 9 中的示例還顯示了兩階段管線所需的最小配置文件,其中 YOLO 模型會(huì)首先檢測(cè)對(duì)象,然后在第二階段分類器中對(duì)它們單獨(dú)分類。對(duì)于 YOLO 模型,可以編輯默認(rèn)的 YOLO 標(biāo)簽文件,并根據(jù) YOLO 標(biāo)準(zhǔn)格式,將標(biāo)簽替換為自定義模型的標(biāo)簽,每個(gè)標(biāo)簽另起一行。
在分類模型中,標(biāo)簽用分號(hào)分隔。在運(yùn)行期間,將根據(jù)這些文件對(duì)模型進(jìn)行相應(yīng)的索引,并顯示您指定的文本。
DeepStream 可通過(guò)引用管線中嵌入這些設(shè)置的配置文件來(lái)使用。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5072瀏覽量
103521 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1700瀏覽量
46074 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
132912 -
python
+關(guān)注
關(guān)注
56文章
4807瀏覽量
84940
原文標(biāo)題:使用 NVIDIA DeepStream 和 Edge Impulse 快速推進(jìn)計(jì)算機(jī)視覺部署
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是計(jì)算機(jī)視覺?計(jì)算機(jī)視覺的三種方法

機(jī)器視覺與計(jì)算機(jī)視覺的關(guān)系簡(jiǎn)述
深度學(xué)習(xí)與傳統(tǒng)計(jì)算機(jī)視覺簡(jiǎn)介
基于OpenCV的計(jì)算機(jī)視覺技術(shù)實(shí)現(xiàn)

計(jì)算機(jī)視覺講義
計(jì)算機(jī)視覺與機(jī)器視覺區(qū)別
計(jì)算機(jī)視覺的發(fā)展歷史_計(jì)算機(jī)視覺的應(yīng)用方向
計(jì)算機(jī)視覺常用算法_計(jì)算機(jī)視覺有哪些分類
計(jì)算機(jī)視覺入門指南
NVIDIA DeepStream SDK是什么 有哪些特性
計(jì)算機(jī)視覺的基礎(chǔ)概念和現(xiàn)實(shí)應(yīng)用
NVIDIA 攜手微軟打造大規(guī)模云端 AI 計(jì)算機(jī)
使用Edge Impulse和Nvidia Jetson的面罩檢測(cè)器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論