 磁盤中RocketMQ構建的索引結構
磁盤中RocketMQ構建的索引結構
消息系統中隨機索引的特點
Cloud Native
RocketMQ 廣泛使用于各類業務場景中,在實際生產場景中,用戶通常會選擇消息 ID 或者特定的業務 Key(例如學號,訂單號)來查詢和定位特定的一批消息,進而定位分布式系統中的復雜問題。傳統方案下,消息索引的存儲是基于數據庫系統或者基于本地文件系統實現的,受限于磁盤容量,很難滿足海量數據的寫入訴求。 在云原生場景下,對象存儲能夠為用戶提供彈性和按量付費的能力,有效降低存儲成本,但對隨機讀寫的支持不夠友好。RocketMQ 的隊列模型中寫入的數據是按時間近似有序的,對于隨機索引熱數據實現了 non-stop write 的特性,同時支持冷熱分離,使用異步歸整的方式冷數據轉移到更廉價存儲系統中。
磁盤中 RocketMQ 構建的索引結構
Cloud Native
索引是一種以空間換時間的支持快速存儲和查找的高效數據結構。我們來看看 RocketMQ 的索引文件的結構設計。RocketMQ 的索引文件文件結構采用三段式結構基于頭插法的 HashTable 設計的。該索引文件存儲結構具有查詢速度快、占用空間小、易于維護等特點,但是隨著數據量的增加,本地索引文件數量也會不斷增加。
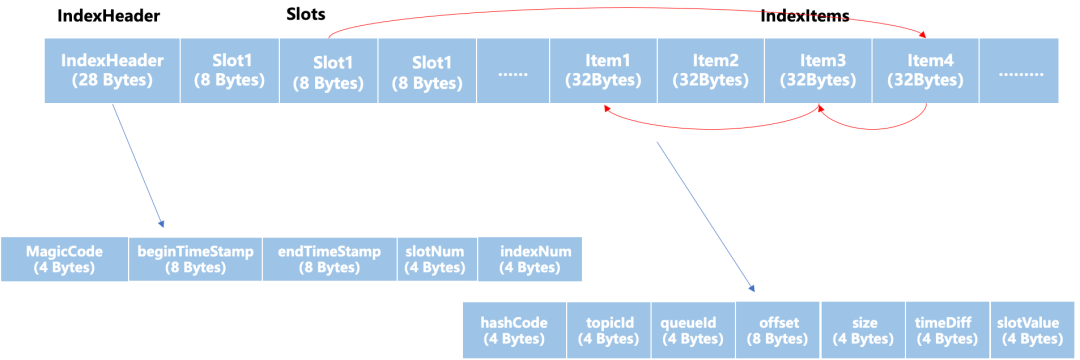
分別為:索引頭部(IndexHeader),索引槽(Slots),索引條目(IndexItems)。

索引文件結構
Hash 沖突的索引通過單向鏈表進行連接,索引條目采取文件末尾追加寫入的方式提升寫入性能: 1. 索引頭部(IndexHeader)包含了該索引文件的元數據信息,其中包括了 MagicCode 用來判斷文件的起始位置。開始時間戳(startTimeStamp)和結束時間戳(endTimeStamp)表示了索引存儲的時間區間范圍。然后還包括了該文件已經使用的索引槽數量(hashSlotCount)和已經存儲的索引數量(indexCount)。 2. 索引槽(Slots)為固定數量,其中存儲了產生哈希沖突的索引索引的頭節點所在的位置,通過哈希映射得到哈希值,然后哈希值對索引槽(Slots)數量進行取余得到索引具體的槽的位置,可以看作鏈表的頭節點。 3. 索引條目(IndexItems)存儲了每個索引具體存儲的數據,消息隊列發送的消息最后都存儲在一個特定topic的一個隊列的一個叫做 CommitLog 的文件中,因此每個索引條目都包含了 topicId,QueueId,Offset,Size 等信息來定位到實際消息在 CommitLog 中的存儲位置。

IndexItem
索引文件數據格式轉換 Compact
Cloud Native
在 RocketMQ 中,由于索引模塊是一個寫多讀極少零更新的結構,因此為了降低系統整體的平均操作代價,單次讀有一些讀放大的開銷是可以接受的。假設消息索引寫入時間開銷需要 t1,平均每條消息索引在經過 t2 之后被查詢,格式轉換時間開銷為 t_compact,通常 t_compact 遠遠小于 t2,因此 t_compact 可以在 t2 時間內異步完成,格式轉換前消息索引查詢時間為 t_before,格式轉換后的消息索引平均查詢時間開銷為 t_after,格式轉換后消息索引平均查詢時間開銷小于格式轉換后查詢時間開銷 t_before < t_after,那么不進行格式轉換數據存儲查詢時間開銷大于進行了格式轉換后存儲查詢時間開銷 。
t1 + t2 + t_before > t1 + t2 + t_after。
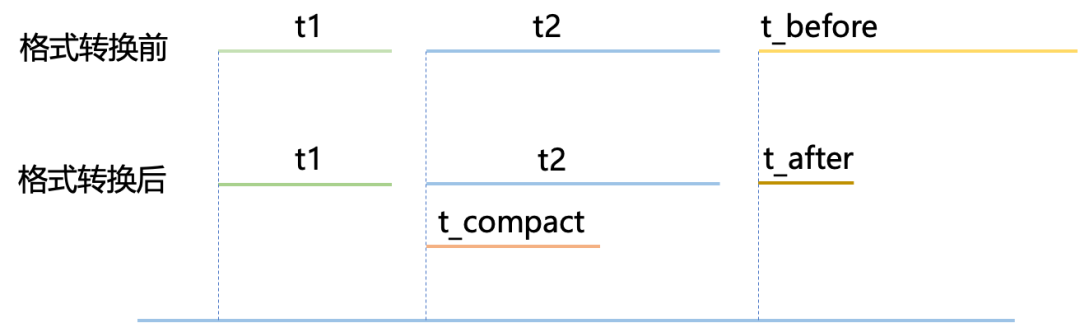
時間軸 RocketMQ 索引文件使用基于頭插法實現的開鏈的 HashTable,在索引寫入時可以順序寫入。然而,在進行指定 key 查詢時,由于使用的是單向鏈表,對 key 進行 hash 到指定 slot 并獲取到鏈表頭節點,然后根據鏈表頭節點遍歷單向鏈表屬于隨機 IO 查詢,對象存儲類似于機械硬盤的特性,讀取 20 Bytes 和讀取數 KB 時間幾乎相同,多次隨機 IO 會造成較大的時間開銷,因此在較多 Hash 沖突時可能存在嚴重的數據讀放大問題。 為了減少對象存儲文件的隨機查詢訪問次數,多級存儲異步對索引文件數據格式轉換,格式轉換后的索引文件可以一次性取回大塊數據,可以極大的減少對對象存儲文件的 IO 訪問次數。 具體地,隨機索引異步重排機制包括以下步驟:
1. 將本地索引文件按照映射后的 slot 槽為單位進行分組,每組包含一定數量的索引項。
2. 對相同的組按照順序寫入新的索引文件,同一個槽對應的組的索引項在物理地址空間上是連續的數組。
3. 在需要查詢時,根據要查詢的 key 的 hash 值,映射到指定的槽,然后槽的位置存儲了數組的首地址,通過遍歷數組,確定需要查詢索引。 通過這種方式,可以大大減少在對象存儲中進行的隨機查詢操作,從而提高查詢效率,降低時間開銷。同時,由于本地索引文件需要進行格式轉換和分組,因此也需要一定的計算和存儲資源。
格式轉換前
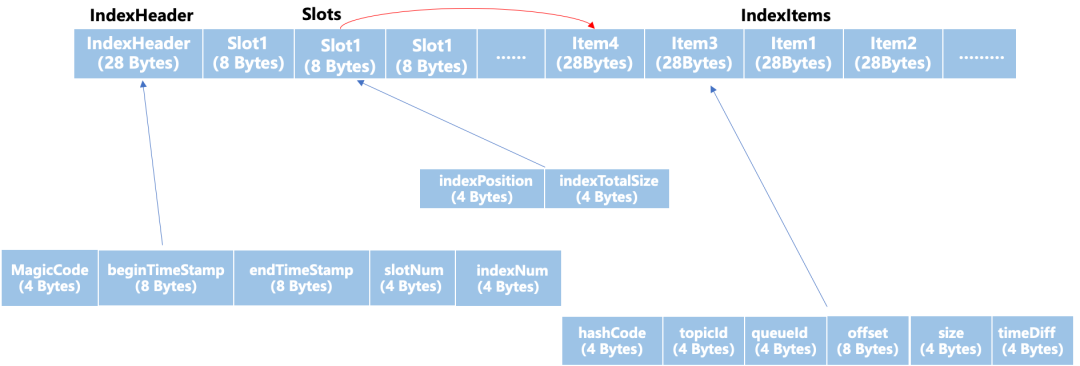
格式轉換后 重排后的索引文件,將物理地址不連續的鏈表重新排列成了物理地址連續的數組,每個 SlotItem 的 8 個字節,前 4 個字節用來記錄數組的首地址,后 4 個字節用于記錄數組的長度。這樣的格式轉換有以下幾個好處。
這樣后續對索引的讀取從鏈表的隨機 IO 變成了數組順序 IO。降低了隨機 IO 帶來的時間開銷。
可以利用空間局部性,增加內存 pageCache 的緩存命中率。
單個索引文件的狀態變化
Cloud Native

單個索引文件生命周期
單個索引文件的容量是有限的。當有許多索引進行寫入時,一個索引文件達到了能夠存儲的最大索引數量后,需要新建一個索引文件,繼續寫入。因此一個文件從創建到銷毀都會經歷新建文件,Compact 文件,上傳成為對象存儲文件,過期銷毀等階段。
當一個“正在寫入文件”狀態的索引文件完全寫滿后,需要將其標記為“Compact文件”狀態。Compact 文件狀態意味著該文件已經不再需要被寫入并且已經 Compact 完成,但是仍然需要被保留以便后續上傳到對象存儲。此時,可以通過將該文件上傳到對象存儲系統進行存儲,并將其標記為“對象存儲文件”狀態。因此也對應了文件的三種狀態,unsealed, compacted, upload。
多個索引文件存儲模型
Cloud Native
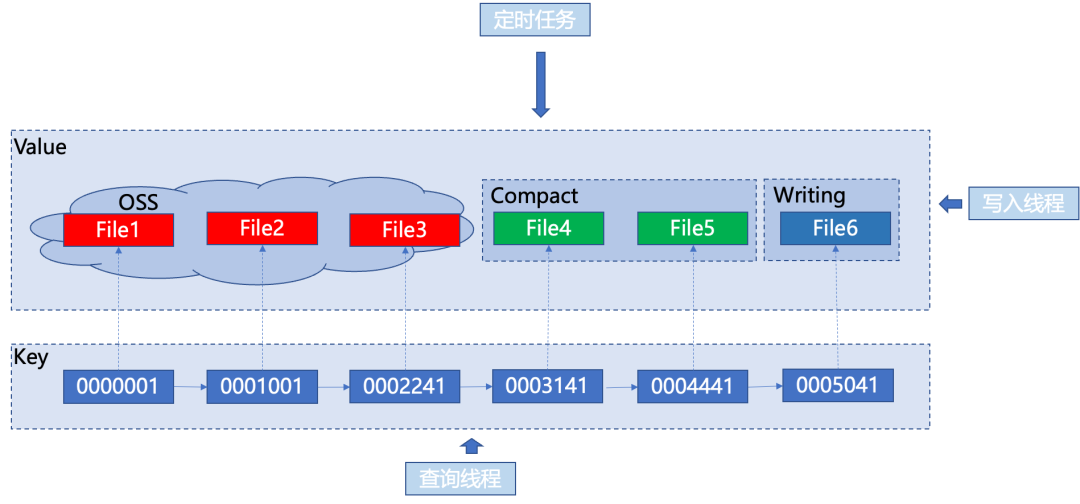
為了實現 Non-Stop Write 的特性,提高索引的寫入性能,設計劃分了三種不同的線程進行相互協作。他們分別為寫入線程,索引查詢線程和后臺定時任務線程。他們各自負責不同的任務,并且通過讀寫鎖來保證并發條件下正確性。消息隊列是一個按時間近似有序的存儲系統,不同的索引文件存儲了不同時間段的索引,因此可以按照時間的近似有序性來管理多個文件。采用跳表數據結構進行管理,可以很方便的支持快速的定位查找和區間查詢。
1. 寫入線程
是非阻塞的,它的職責是將索引寫入到隊列尾部的處于正在寫入狀態的文件。當一個文件寫滿后,該線程會自動在隊列尾部新建一個文件,并切換到下一個文件進行寫入。為了提高寫入效率,該線程在將索引寫入文件時還負責將索引緩存在內存中,當緩存達到一定數量后再將其批量寫入到文件中,以減少磁盤 IO 次數。
2. 索引查詢線程
可以查詢處于不同狀態的索引文件具體查詢策略如下:
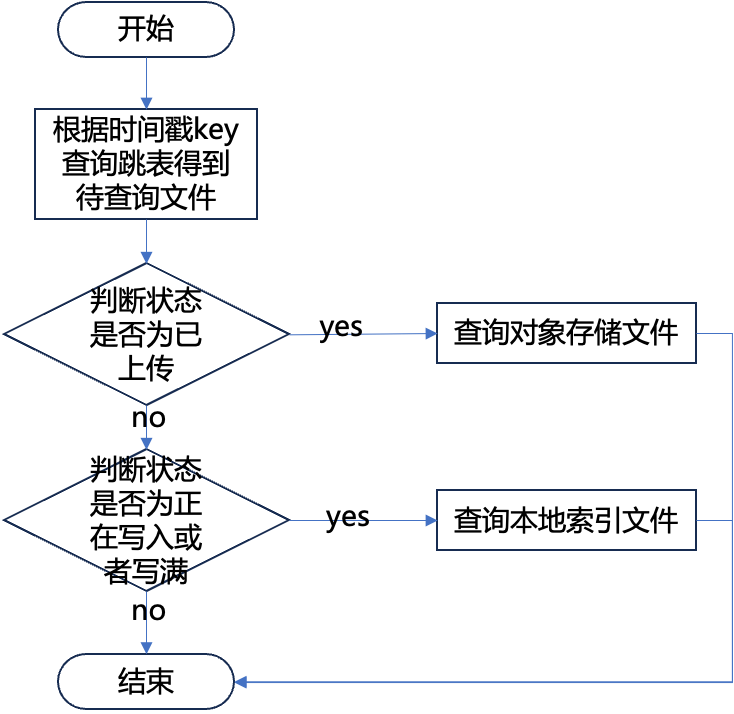
對于處于正在寫入狀態的文件,查詢線程需要等待寫入線程將索引寫入完成后才能進行查詢;對于已經寫滿的文件,查詢線程可以直接對其進行查詢;對于已經 Compact 的文件,查詢線程也直接從本地文件進行查詢。
對于上傳到對象存儲的文件,可以直接從對象存儲中讀取其數據,對 Compact 后格式的索引文件進行查詢。
3. 后臺定時任務線程
主要負責對正在處于寫入狀態的文件并且已經寫滿的文件進行 Compact 操作。在進行 Compact 操作時,該線程需要先獲取對應文件的讀寫鎖,以避免其他線程對該文件的并發訪問。Compact 完成后切換該文件的狀態為 Compact 完成,然后需要將 Compact 過的文件上傳到對象存儲成為對象存儲文件,上傳完將文件狀態切換成已上傳狀態。在上傳過程中,該線程需要釋放對該文件的讀寫鎖。
系統層次設計
Cloud Native
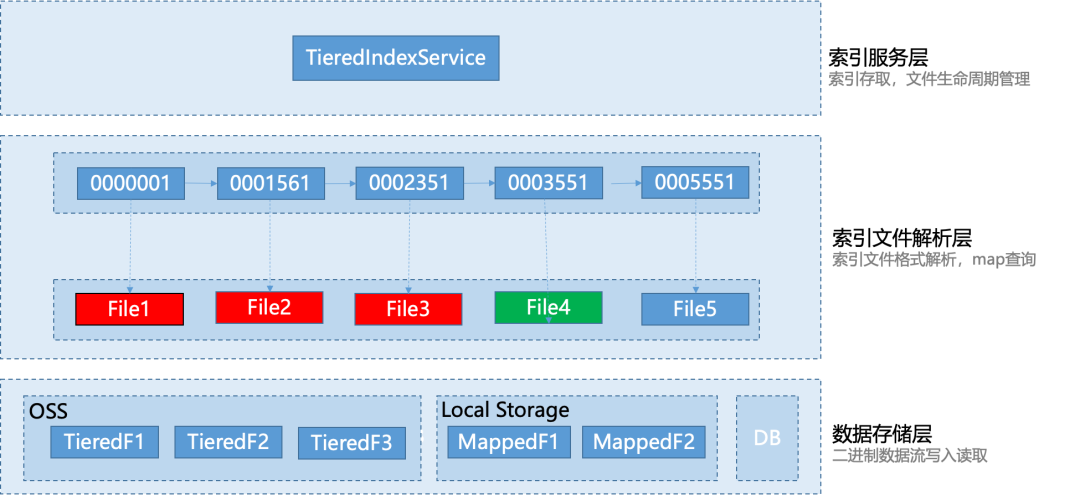
為了提高系統的可擴展性和方便編寫單元測試,整個索引服務采用了層次設計的思想,自頂向下,分別設計了索引服務層、索引文件解析層和數據存儲層。不同的層負責處理不同的任務,層與層之間解耦合,上層只依賴下層提供的服務。
索引服務層:該層為 RocketMQ 提供消息索引服務,它的職責是負責消息索引的存儲和查詢,同時負責索引文件的生命周期管理,包括創建索引文件、Compact 文件、上傳文件,銷毀文件等。
索引文件解析層:該層主要針對單個處于不同狀態的索引文件進行格式解析,同時提供單個文件的 KV 查詢和存儲服務。具體而言,該層負責讀取索引文件中的數據,并將其解析為可讀格式,以供上層調用。
數據存儲層:該層負責二進制流數據的寫入和讀取,支持不同類型的存儲方式,包括對象存儲、本地磁盤文件、或者數據庫文件等。具體而言,該層將數據存儲在本地磁盤或對象存儲中或數據庫文件。在讀取數據時,該層負責從本地磁盤或對象存儲中獲取數據,并將其轉換為二進制流數據返回給調用方。
通過采用層次設計的思想,將整個索引服務劃分為三個不同的層次,使得系統具有良好的可擴展性和可維護性,方便后續升級和維護。同時,各層次之間解耦合,職責明確,方便進行單元測試和維護。
高可用的系統宕機恢復流程設計
Cloud Native
由于索引文件有不同的狀態,通過跳表的數據結構進行管理和維護,在系統宕機狀態下,需要對處于不同狀態的索引文件進行恢復。為此,我們采用了分類分文件夾進行管理,通過文件夾名稱來對不同狀態的索引文件進行管理和記錄。
在進行宕機恢復時,我們采用了以下流程設計:
1. 在系統重新啟動后,讀取存儲在系統中的文件夾名稱列表,該列表中包含了所有處于不同狀態的索引文件所對應的文件夾名稱。
2. 通過文件夾名稱列表,依次讀取每個文件夾下的索引文件,并將這些索引文件加載到內存中,重新構建跳表。
3. 根據文件夾名稱以及其對應的索引文件,恢復當前文件所處的狀態。例如,如果文件夾名稱為 “writing”,則表示該文件夾下的索引文件正處于寫入狀態,需要根據寫入狀態進行相應的處理。
與其他系統的對比
Cloud Native
Rocksdb 是基于 Google LevelDB 研發的高性能 kv 持久化存儲引擎。RocksDB 使用 Log-Structured Merge(LSM)trees 作為基本的數據存儲結構。當數據寫入 RocksDB 的時候,首先會寫入到內存中的 MemTable 并持久化道磁盤上的 Write-Ahead-Log (WAL) 文件上。
每當 MemTable 緩存數據量達到預設值,MemTable 與 WAL 將會轉為不可變狀態,同時分配新的 MemTable 與 WAL 用于后續寫入,接著對不可變 MemTable 中相同 key 進行 (merge),LSM tree 有多個層級 (Level),每個層級由多個 SSTable 組成,最新的 SSTable 都會放置在最底層,下層的 SSTable 通過異步壓縮(Compaction)操作創建。
每層的 SSTable 總大小由配置參數決定,當 L 層數據大小超出預設值,會選擇 L 層的 SSTable 與 L+1 層的SSTable 重疊部分合并,通過重復這一過程優化數據的讀性能,但 Compaction 這個動作會帶來較大的讀寫放大。
MySQL InnoDB 是一種事務型存儲引擎。它提供了高性能、高可靠性和高并發性的特性,底層采用 B+ 樹進行實現,數據文件本身就是索引文件。為了解決宕機時數據丟失的問題,InnoDB 采用了 RedoLog 同步記錄寫行為。因為 RedoLog 是順序寫入,因此寫入的效率很高,數據將會先寫入緩存和 RedoLog 中。 最后數據會異步再從 RedoLog 寫入 B+ 樹中。由于 B+ 樹的層次結構導致能夠支持的索引數量是有上限的,例如單表超過數億級別的記錄時就會產生顯著的性能下降。同時 B+ 樹葉子結點的分裂與合并也會帶來較多的讀寫開銷。
RocketMQ 本身是一個寫多讀少零更新并且按時間近似有序的存儲系統。因此 RocketMQ 可以按照時間簡單高效地進行冷熱分離存儲。也支持異步的文件格式轉換來降低系統整體時間開銷。
還有待改進的地方
Cloud Native
當前的索引設計簡單可靠,但還有一些設計上的不足之處。例如:當前通常消息隊列通過 key 查詢消息時,還會有一個 maxCount 參數,由于對不同的索引文件查詢時并發的,當前系統的實現存在缺陷,可能需要查詢完所有的索引文件,然后對結果進行匯總,判斷是否達到 maxCount 參數指定的索引數量。
當存在較多的索引文件時,這樣可能存在潛在的大量查詢帶來多余的時間開銷。因此一個合理的解決方式是我們需要一個多線程全局的計數器,當滿足 maxCount 時,可以停止對后續多余的索引文件進行查詢。這里涉及到多線程訪問時可能出現的線程安全問題。
本消息隊列多級存儲索引模塊提供 kv 數據查詢和存儲,可以對索引條目(indexItem)進行重新設計,可以使本系統遷移到其他系統,為其他系統提供索引服務。只需要新增一個類將 indexItem 作為父類繼承,重寫相關函數,添加自定義字段,就可以實現對其他系統提供索引服務。
審核編輯:湯梓紅
-
模塊
+關注
關注
7文章
2731瀏覽量
47663 -
磁盤
+關注
關注
1文章
380瀏覽量
25245 -
文件
+關注
關注
1文章
570瀏覽量
24803 -
分布式系統
+關注
關注
0文章
146瀏覽量
19285
原文標題:RocketMQ中冷熱分離的隨機索引模塊詳解
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于R*-tree的時空數據庫索引VC-tree
基于分段哈希碼的倒排索引樹結構
基于圖形數據庫構建可持久化索引的方法
基于KD樹和R樹的多維索引結構

展望Apache RocketMQ5.0 | 談RocketMQ的過去、現在和未來
開源軟件-RocketMQ Externals Apache RocketMQ的擴展項目

MySQL為什么選擇B+樹作為索引結構?
RocketMQ和RabbitMQ的區別
磁盤I/O是怎么工作的





 工商網監
工商網監
評論