 使用Python從零實現多分類SVM
使用Python從零實現多分類SVM
本文將首先簡要概述支持向量機及其訓練和推理方程,然后將其轉換為代碼以開發支持向量機模型。之后然后將其擴展成多分類的場景,并通過使用Sci-kit Learn測試我們的模型來結束。
SVM概述
支持向量機的目標是擬合獲得最大邊緣的超平面(兩個類中最近點的距離)。可以直觀地表明,這樣的超平面(A)比沒有最大化邊際的超平面(B)具有更好的泛化特性和對噪聲的魯棒性。
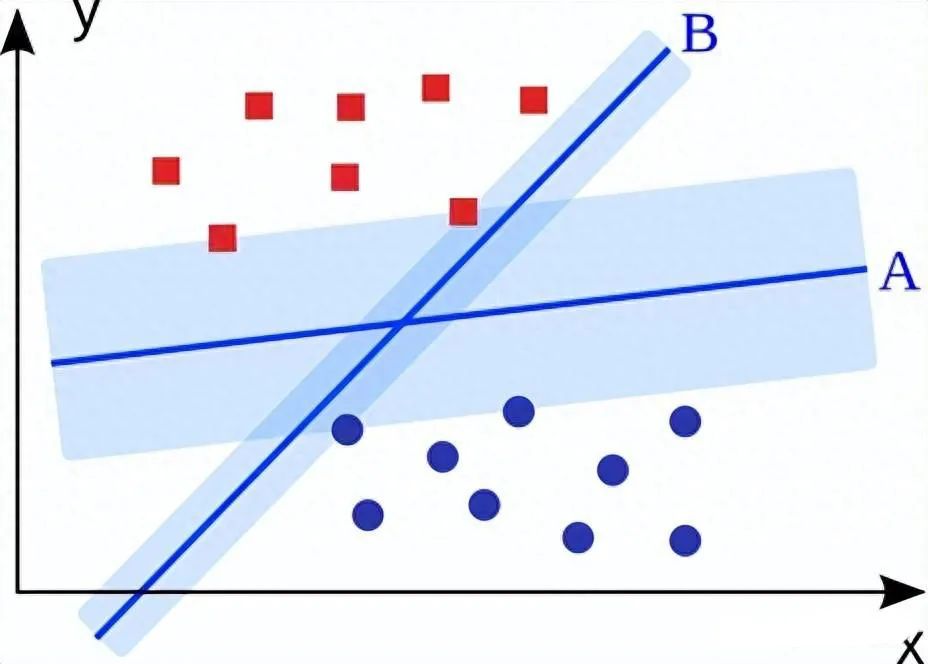 為了實現這一點,SVM通過求解以下優化問題找到超平面的W和b:
為了實現這一點,SVM通過求解以下優化問題找到超平面的W和b:
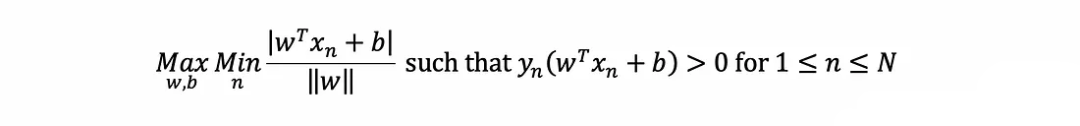 ?
?它試圖找到W,b,使最近點的距離最大化,并正確分類所有內容(如y取±1的約束)。這可以被證明相當于以下優化問題:
?
?它試圖找到W,b,使最近點的距離最大化,并正確分類所有內容(如y取±1的約束)。這可以被證明相當于以下優化問題:
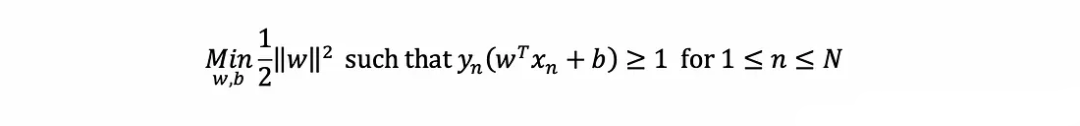 ?可以寫出等價的對偶優化問題
?可以寫出等價的對偶優化問題
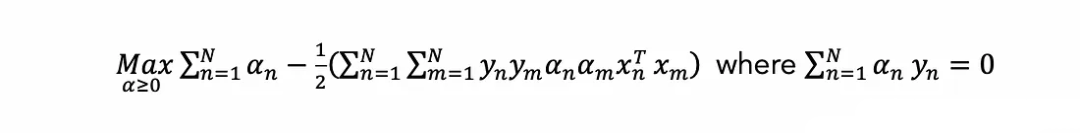 ?
?這個問題的解決方案產生了一個拉格朗日乘數,我們假設數據集中的每個點的大小為m:(α 1, α 2,…,α _n)。目標函數在α中明顯是二次的,約束是線性的,這意味著它可以很容易地用二次規劃求解。一旦找到解,由對偶的推導可知:
?
?這個問題的解決方案產生了一個拉格朗日乘數,我們假設數據集中的每個點的大小為m:(α 1, α 2,…,α _n)。目標函數在α中明顯是二次的,約束是線性的,這意味著它可以很容易地用二次規劃求解。一旦找到解,由對偶的推導可知:
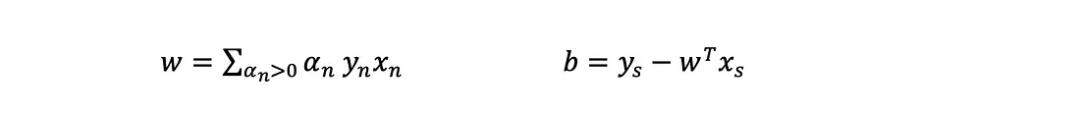 ?
?注意,只有具有α>0的點才定義超平面(對和有貢獻)。這些被稱為支持向量。因此當給定一個新例子x時,返回其預測y=±1的預測方程為:
?
?注意,只有具有α>0的點才定義超平面(對和有貢獻)。這些被稱為支持向量。因此當給定一個新例子x時,返回其預測y=±1的預測方程為:
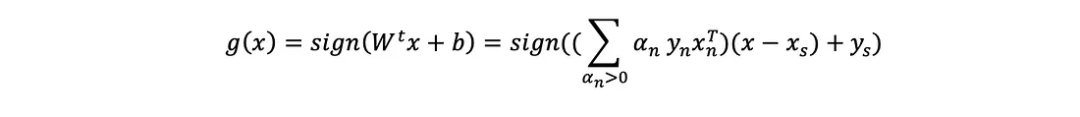 ?
?這種支持向量機的基本形式被稱為硬邊界支持向量機(hard margin SVM),因為它解決的優化問題(如上所述)強制要求訓練中的所有點必須被正確分類。但在實際場景中,可能存在一些噪聲,阻止或限制了完美分離數據的超平面,在這種情況下,優化問題將不返回或返回一個糟糕的解決方案。
?
?這種支持向量機的基本形式被稱為硬邊界支持向量機(hard margin SVM),因為它解決的優化問題(如上所述)強制要求訓練中的所有點必須被正確分類。但在實際場景中,可能存在一些噪聲,阻止或限制了完美分離數據的超平面,在這種情況下,優化問題將不返回或返回一個糟糕的解決方案。
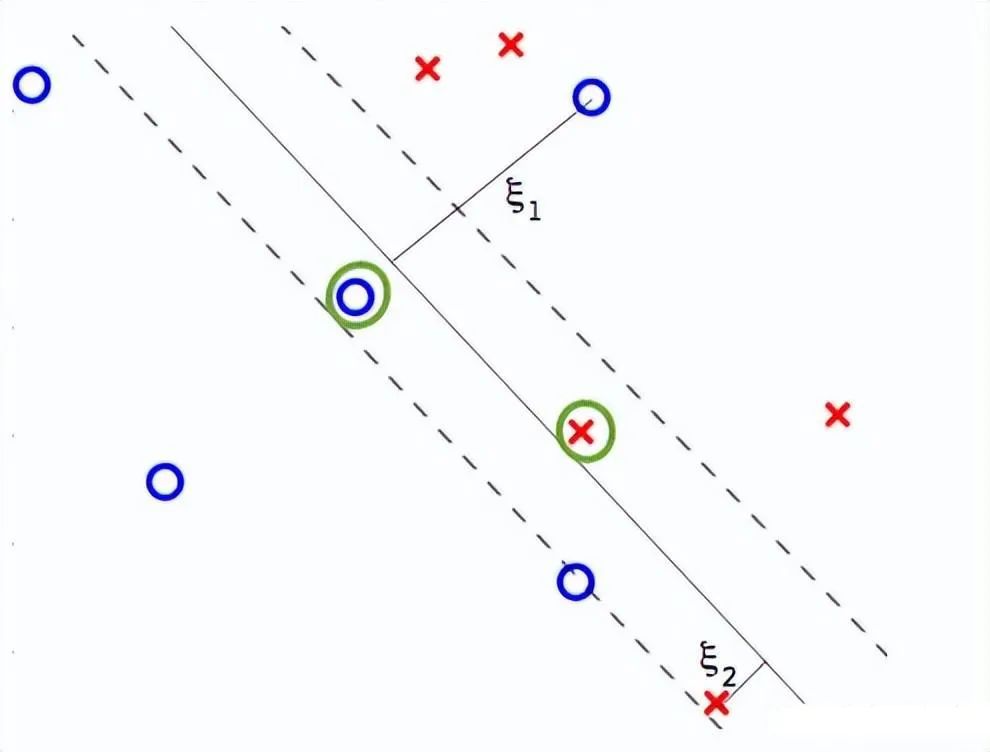 ?
?軟邊界支持向量機(soft margin SVM)通過引入C常數(用戶給定的超參數)來適應優化問題,該常數控制它應該有多“硬”。特別地,它將原優化問題修改為:
?
?軟邊界支持向量機(soft margin SVM)通過引入C常數(用戶給定的超參數)來適應優化問題,該常數控制它應該有多“硬”。特別地,它將原優化問題修改為:
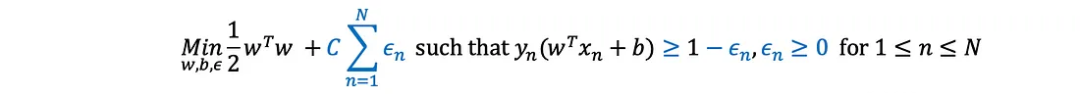 ?
?它允許每個點產生一些錯誤λ(例如,在超平面的錯誤一側),并且通過將它們在目標函數中的總和加權C來減少它們。當C趨于無窮時(一般情況下肯定不會),它就等于硬邊界。與此同時,較小的C將允許更多的“違規行為”(以換取更大的支持;例如,更小的w (w)。
可以證明,等價對偶問題只有在約束每個點的α≤C時才會發生變化。
?
?它允許每個點產生一些錯誤λ(例如,在超平面的錯誤一側),并且通過將它們在目標函數中的總和加權C來減少它們。當C趨于無窮時(一般情況下肯定不會),它就等于硬邊界。與此同時,較小的C將允許更多的“違規行為”(以換取更大的支持;例如,更小的w (w)。
可以證明,等價對偶問題只有在約束每個點的α≤C時才會發生變化。
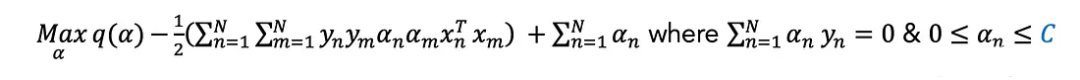 ?
?由于允許違例,支持向量(帶有α>0的點)不再都在邊界的邊緣。任何錯誤的支持向量都具有α=C,而非支持向量(α=0)不能發生錯誤。我們稱潛在錯誤(α=C)的支持向量為“非錯誤編劇支持向量”和其他純粹的支持向量(沒有違規;“邊界支持向量”(0<α
?
?由于允許違例,支持向量(帶有α>0的點)不再都在邊界的邊緣。任何錯誤的支持向量都具有α=C,而非支持向量(α=0)不能發生錯誤。我們稱潛在錯誤(α=C)的支持向量為“非錯誤編劇支持向量”和其他純粹的支持向量(沒有違規;“邊界支持向量”(0<α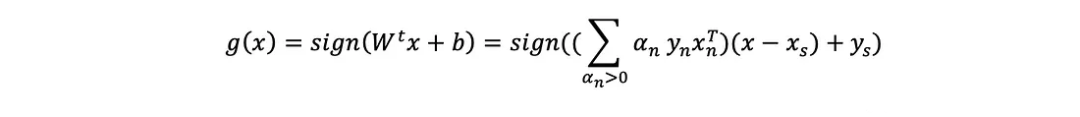 ?
?現在(x?,y?)必須是一個沒有違規的支持向量,因為方程假設它在邊界的邊緣。軟邊界支持向量機擴展了硬邊界支持向量機來處理噪聲,但通常由于噪聲以外的因素,例如自然非線性,數據不能被超平面分離。軟邊界支持向量機可以用于這樣的情況,但是最優解決方案的超平面,它允許的誤差遠遠超過現實中可以容忍的誤差。
?
?現在(x?,y?)必須是一個沒有違規的支持向量,因為方程假設它在邊界的邊緣。軟邊界支持向量機擴展了硬邊界支持向量機來處理噪聲,但通常由于噪聲以外的因素,例如自然非線性,數據不能被超平面分離。軟邊界支持向量機可以用于這樣的情況,但是最優解決方案的超平面,它允許的誤差遠遠超過現實中可以容忍的誤差。
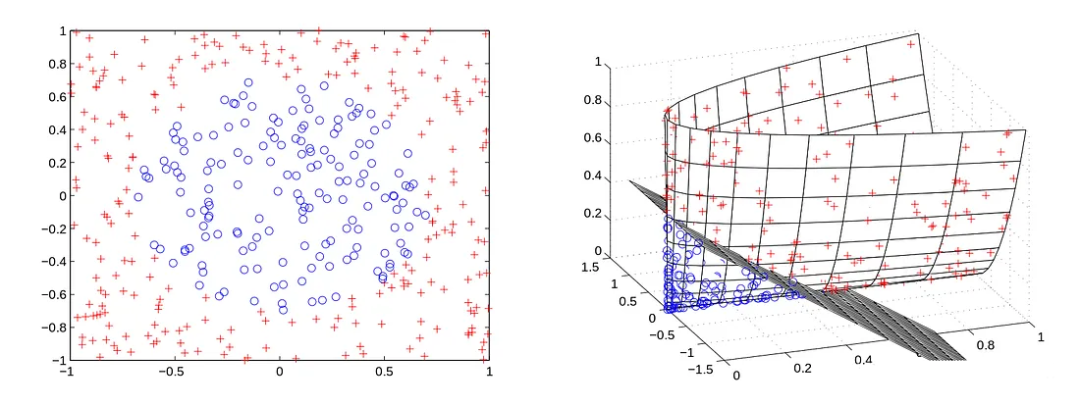 ?
?例如,在左邊的例子中,無論C的設置如何,軟邊界支持向量機都找不到線性超平面。但是可以通過某種轉換函數z=Φ(x)將數據集中的每個點x映射到更高的維度,從而使數據在新的高維空間中更加線性(或完全線性)。這相當于用z替換x得到:
?
?例如,在左邊的例子中,無論C的設置如何,軟邊界支持向量機都找不到線性超平面。但是可以通過某種轉換函數z=Φ(x)將數據集中的每個點x映射到更高的維度,從而使數據在新的高維空間中更加線性(或完全線性)。這相當于用z替換x得到:
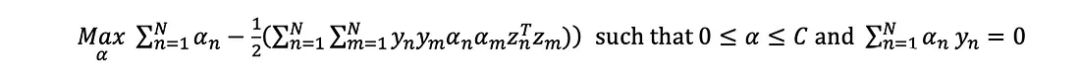 ?
?在現實中,特別是當Φ轉換為非常高維的空間時,計算z可能需要很長時間。所以就出現了核函數。它用一個數學函數(稱為核函數)的等效計算來取代z,并且更快(例如,對z進行代數簡化)。例如,這里有一些流行的核函數(每個都對應于一些轉換Φ到更高維度空間):
?
?在現實中,特別是當Φ轉換為非常高維的空間時,計算z可能需要很長時間。所以就出現了核函數。它用一個數學函數(稱為核函數)的等效計算來取代z,并且更快(例如,對z進行代數簡化)。例如,這里有一些流行的核函數(每個都對應于一些轉換Φ到更高維度空間):
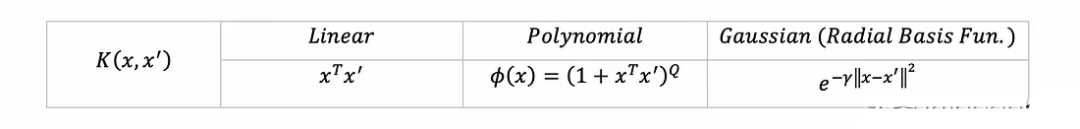 ?
?這樣,對偶優化問題就變成:
?
?這樣,對偶優化問題就變成:
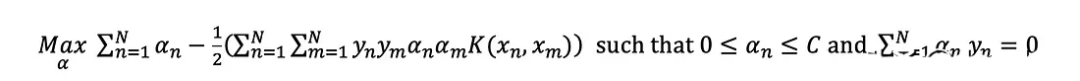 ?
?直觀地,推理方程(經過代數處理后)為:
?
?直觀地,推理方程(經過代數處理后)為:
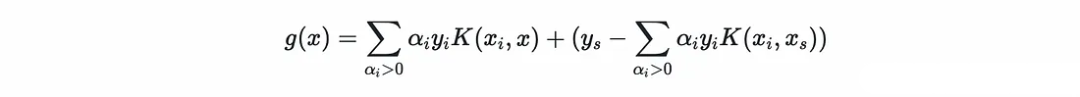 ?
?上面所有方程的完整推導,有很多相關的文章了,我們就不詳細介紹了。
?
?上面所有方程的完整推導,有很多相關的文章了,我們就不詳細介紹了。
Python實現
對于實現,我們將使用下面這些庫:
import numpy as np # for basic operations over arrays
from scipy.spatial import distance # to compute the Gaussian kernel
import cvxopt # to solve the dual opt. problem
import copy # to copy numpy arrays
定義核和SVM超參數,我們將實現常見的三個核函數:
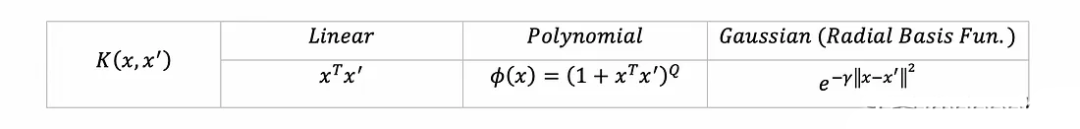 ?
?
class SVM:
linear = lambda x, x? , c=0: x @ x?.T
polynomial = lambda x, x? , Q=5: (1 + x @ x?.T)**Q
rbf = lambda x, x?, γ=10: np.exp(-γ*distance.cdist(x, x?,'sqeuclidean'))
kernel_funs = {'linear': linear, 'polynomial': polynomial, 'rbf': rbf}
為了與其他核保持一致,線性核采用了一個額外的無用的超參數。kernel_funs接受核函數名稱的字符串,并返回相應的內核函數。
繼續定義構造函數:
class SVM:
linear = lambda x, x? , c=0: x @ x?.T
polynomial = lambda x, x? , Q=5: (1 + x @ x?.T)**Q
rbf = lambda x, x?, γ=10: np.exp(-γ*distance.cdist(x, x?,'sqeuclidean'))
kernel_funs = {'linear': linear, 'polynomial': polynomial, 'rbf': rbf}
def __init__(self, kernel='rbf', C=1, k=2):
# set the hyperparameters
self.kernel_str = kernel
self.kernel = SVM.kernel_funs[kernel]
self.C = C # regularization parameter
self.k = k # kernel parameter
# training data and support vectors (set later)
self.X, y = None, None
self.αs = None
# for multi-class classification (set later)
self.multiclass = False
self.clfs = []
SVM有三個主要的超參數,核(我們存儲給定的字符串和相應的核函數),正則化參數C和核超參數(傳遞給核函數);它表示多項式核的Q和RBF核的γ。
為了兼容sklearn的形式,我們需要使用fit和predict函數來擴展這個類,定義以下函數,并在稍后將其用作裝飾器:
擬合SVM對應于通過求解對偶優化問題找到每個點的支持向量α:
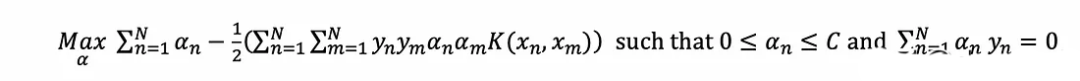 ?
?設α為可變列向量(α?α?…α _n);y為標簽(y?α?…y_N)常數列向量;K為常數矩陣,其中K[n,m]計算核在(x, x)處的值。點積、外積和二次型分別基于索引的等價表達式:
?
?設α為可變列向量(α?α?…α _n);y為標簽(y?α?…y_N)常數列向量;K為常數矩陣,其中K[n,m]計算核在(x, x)處的值。點積、外積和二次型分別基于索引的等價表達式:
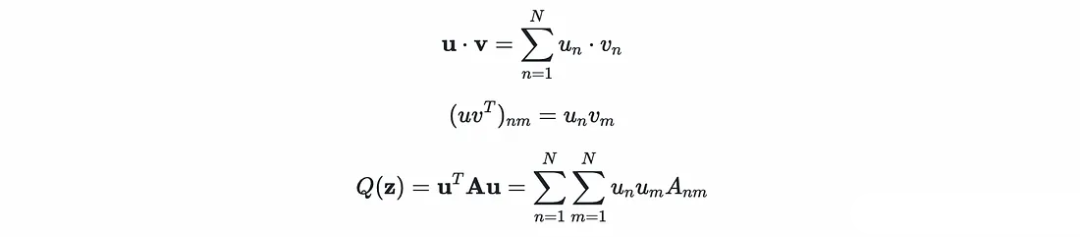 ?
?可以將對偶優化問題寫成矩陣形式如下:
?
?可以將對偶優化問題寫成矩陣形式如下:
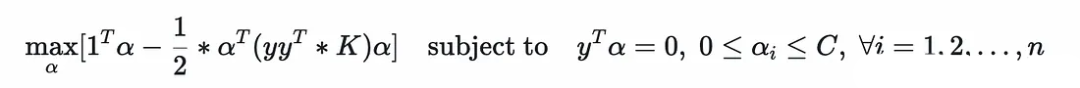 ?
?這是一個二次規劃,CVXOPT的文檔中解釋如下:
?
?這是一個二次規劃,CVXOPT的文檔中解釋如下:
 ?
?可以只使用(P,q)或(P,q,G,h)或(P,q,G,h, A, b)等等來調用它(任何未給出的都將由默認值設置,例如1)。
對于(P, q, G, h, A, b)的值,我們的例子可以做以下比較:
?
?可以只使用(P,q)或(P,q,G,h)或(P,q,G,h, A, b)等等來調用它(任何未給出的都將由默認值設置,例如1)。
對于(P, q, G, h, A, b)的值,我們的例子可以做以下比較:
 ?
?為了便于比較,將第一個重寫如下:
?
?為了便于比較,將第一個重寫如下:
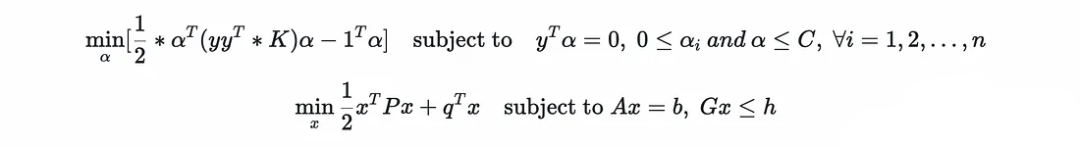 ?
?現在很明顯(0≤α等價于-α≤0):
?
?現在很明顯(0≤α等價于-α≤0):
 ?
?我們就可以寫出如下的fit函數:
?
?我們就可以寫出如下的fit函數:
@SVMClass
def fit(self, X, y, eval_train=False):
# if more than two unique labels, call the multiclass version
if len(np.unique(y)) > 2:
self.multiclass = True
return self.multi_fit(X, y, eval_train)
# if labels given in {0,1} change it to {-1,1}
if set(np.unique(y)) == {0, 1}: y[y == 0] = -1
# ensure y is a Nx1 column vector (needed by CVXOPT)
self.y = y.reshape(-1, 1).astype(np.double) # Has to be a column vector
self.X = X
N = X.shape[0] # Number of points
# compute the kernel over all possible pairs of (x, x') in the data
# by Numpy's vectorization this yields the matrix K
self.K = self.kernel(X, X, self.k)
### Set up optimization parameters
# For 1/2 x^T P x + q^T x
P = cvxopt.matrix(self.y @ self.y.T * self.K)
q = cvxopt.matrix(-np.ones((N, 1)))
# For Ax = b
A = cvxopt.matrix(self.y.T)
b = cvxopt.matrix(np.zeros(1))
# For Gx <= h
G = cvxopt.matrix(np.vstack((-np.identity(N),
np.identity(N))))
h = cvxopt.matrix(np.vstack((np.zeros((N,1)),
np.ones((N,1)) * self.C)))
# Solve
cvxopt.solvers.options['show_progress'] = False
sol = cvxopt.solvers.qp(P, q, G, h, A, b)
self.αs = np.array(sol["x"]) # our solution
# a Boolean array that flags points which are support vectors
self.is_sv = ((self.αs-1e-3 > 0)&(self.αs <= self.C)).squeeze()
# an index of some margin support vector
self.margin_sv = np.argmax((0 < self.αs-1e-3)&(self.αs < self.C-1e-3))
if eval_train:
print(f"Finished training with accuracy{self.evaluate(X, y)}")
我們確保這是一個二進制問題,并且二進制標簽按照支持向量機(±1)的假設設置,并且y是一個維數為(N,1)的列向量。然后求解求解(α?α?…α _n) 的優化問題。
使用(α?α?…α _n) _來獲得在與支持向量對應的任何索引處為1的標志數組,然后可以通過僅對支持向量和(x?,y?)的邊界支持向量的索引求和來應用預測方程。我們確實假設非支持向量可能不完全具有α=0,如果它的α≤1e-3,那么這是近似為零(CVXOPT結果可能不是最終精確的)。同樣假設非邊際支持向量可能不完全具有α=C。
下面就是預測的方法,預測方程為:
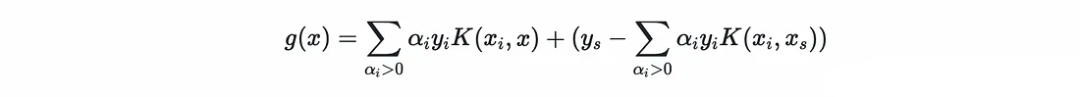 ?
?
@SVMClass
def predict(self, X_t):
if self.multiclass: return self.multi_predict(X_t)
# compute (x?, y?)
x?, y? = self.X[self.margin_sv, np.newaxis], self.y[self.margin_sv]
# find support vectors
αs, y, X= self.αs[self.is_sv], self.y[self.is_sv], self.X[self.is_sv]
# compute the second term
b = y? - np.sum(αs * y * self.kernel(X, x?, self.k), axis=0)
# compute the score
score = np.sum(αs * y * self.kernel(X, X_t, self.k), axis=0) + b
return np.sign(score).astype(int), score
我們還可以實現一個評估方法來計算精度(在上面的fit中使用)。
@SVMClass
def evaluate(self, X,y):
outputs, _ = self.predict(X)
accuracy = np.sum(outputs == y) / len(y)
return round(accuracy, 2)
最后測試我們的完整代碼:
from sklearn.datasets import make_classification
import numpy as np
# Load the dataset
np.random.seed(1)
X, y = make_classification(n_samples=2500, n_features=5,
n_redundant=0, n_informative=5,
n_classes=2, class_sep=0.3)
# Test Implemented SVM
svm = SVM(kernel='rbf', k=1)
svm.fit(X, y, eval_train=True)
y_pred, _ = svm.predict(X)
print(f"Accuracy: {np.sum(y==y_pred)/y.shape[0]}") #0.9108
# Test with Scikit
from sklearn.svm import SVC
clf = SVC(kernel='rbf', C=1, gamma=1)
clf.fit(X, y)
y_pred = clf.predict(X)
print(f"Accuracy: {sum(y==y_pred)/y.shape[0]}") #0.9108
多分類SVM
我們都知道SVM的目標是二元分類,如果要將模型推廣到多類則需要為每個類訓練一個二元SVM分類器,然后對每個類進行循環,并將屬于它的點重新標記為+1,并將所有其他類的點重新標記為-1。 當給定k個類時,訓練的結果是k個分類器,其中第i個分類器在數據上進行訓練,第i個分類器被標記為+1,所有其他分類器被標記為-1。
@SVMClass
def multi_fit(self, X, y, eval_train=False):
self.k = len(np.unique(y)) # number of classes
# for each pair of classes
for i in range(self.k):
# get the data for the pair
Xs, Ys = X, copy.copy(y)
# change the labels to -1 and 1
Ys[Ys!=i], Ys[Ys==i] = -1, +1
# fit the classifier
clf = SVM(kernel=self.kernel_str, C=self.C, k=self.k)
clf.fit(Xs, Ys)
# save the classifier
self.clfs.append(clf)
if eval_train:
print(f"Finished training with accuracy {self.evaluate(X, y)}")
然后,為了對新示例執行預測,我們選擇相應分類器最自信(得分最高)的類。
@SVMClass
def multi_predict(self, X):
# get the predictions from all classifiers
N = X.shape[0]
preds = np.zeros((N, self.k))
for i, clf in enumerate(self.clfs):
_, preds[:, i] = clf.predict(X)
# get the argmax and the corresponding score
return np.argmax(preds, axis=1), np.max(preds, axis=1)
完整測試代碼:
from sklearn.datasets import make_classification
import numpy as np
# Load the dataset
np.random.seed(1)
X, y = make_classification(n_samples=500, n_features=2,
n_redundant=0, n_informative=2,
n_classes=4, n_clusters_per_class=1,
class_sep=0.3)
# Test SVM
svm = SVM(kernel='rbf', k=4)
svm.fit(X, y, eval_train=True)
y_pred = svm.predict(X)
print(f"Accuracy: {np.sum(y==y_pred)/y.shape[0]}") # 0.65
# Test with Scikit
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
clf = OneVsRestClassifier(SVC(kernel='rbf', C=1, gamma=4)).fit(X, y)
y_pred = clf.predict(X)
print(f"Accuracy: {sum(y==y_pred)/y.shape[0]}") # 0.65
繪制每個決策區域的圖示,得到以下圖:
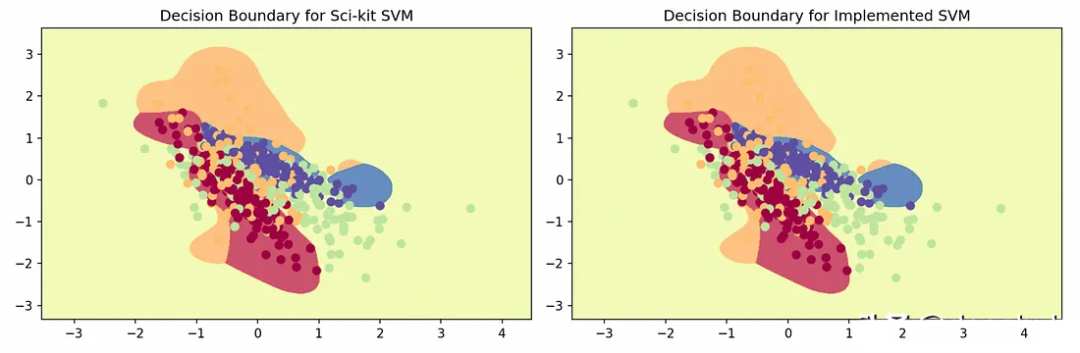 ?
?可以看到,我們的實現與Sci-kit Learn結果相當,說明在算法實現上沒有問題。注意:SVM默認支持OVR(沒有如上所示的顯式調用),它是特定于SVM的進一步優化。
?
?可以看到,我們的實現與Sci-kit Learn結果相當,說明在算法實現上沒有問題。注意:SVM默認支持OVR(沒有如上所示的顯式調用),它是特定于SVM的進一步優化。
總結
我們使用Python實現了支持向量機(SVM)學習算法,并且包括了軟邊界和常用的三個核函數。我們還將SVM擴展到多分類的場景,并使用Sci-kit Learn驗證了我們的實現。希望通過本文你可以更好的了解SVM。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
算法
+關注
關注
23文章
4613瀏覽量
92945 -
向量機
+關注
關注
0文章
166瀏覽量
20882 -
SVM
+關注
關注
0文章
154瀏覽量
32479 -
python
+關注
關注
56文章
4797瀏覽量
84718
原文標題:使用Python從零實現多分類SVM
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在stm32上實現svm實時訓練與分類
目標在stm32上實現svm實時訓練與分類,特征向量為10維向量,分類結果為多目標分類; 1.代碼分解與抽取 libsvm源代碼文件有5個:
發表于 08-17 06:24
集成學習的多分類器動態組合方法
為了提高數據的分類性能,提出一種集成學習的多分類器動態組合方法(DEA)。該方法在多個UCI標準數據集上進行測試,并與文中使用的基于Adaboost算法訓練出的各個成員分類器的分類
發表于 04-08 08:58
?19次下載
基于SVM的兩級指紋分類研究
利用SVM(Support Vector Machine)解決二類分類問題的優勢,設計了一個粗細兩級指紋分類體器,提出并實現了一種新型的指紋分類
發表于 07-16 14:55
?23次下載
基于GA-SVM的帶鋼表面缺陷模式識別
本文采用遺傳算法(GA)對支持向量機(SVM)分類器進行參數優化,并將其應用于帶鋼表面缺陷分類的模式分類。實驗數據來源于UCI標準數據集,采用10折交叉驗證法進行
發表于 01-04 17:03
?8次下載
采用SVM的網頁分類方法研究
中,成功地將非線性可分問題轉化為線性可分的問題,并且在特征空間中構造線性函數,實現對文本的自動分類。SVM將非線性問題轉化成線性可分問題,巧妙地解決維災難和過學習現象。特征選擇是整個分類
發表于 11-08 11:42
?3次下載
多分類孿生支持向量機研究進展
孿生支持向量機因其簡單的模型、快速的訓練速度和優秀的性能而受到廣泛關注.該算法最初是為解決二分類問題而提出的。不能直接用于解決現實生活中普遍存在的多分類問題.近來,學者們致力于將二分類孿生支持向量機
發表于 12-19 11:32
?0次下載
支持向量機多分類的眼電輔助肌電的人機交互
針對單一肌電信號在控制系統中正確識別率不高問題,設計并實現了一種基于支持向量機( SVM)多分類的眼電(EOG)輔助肌電(EMG)的人機交互(HCI)系統。該系統采用改進小波包算法和閾值法分別
發表于 01-26 17:24
?1次下載
SVM分類器實驗的資料和工程文件資料免費下載
一、實驗目的 1、掌握線性主持向量機(SVM)分類器。 2、掌握基于高斯核的SVM分類器。 3、掌握基于拉普拉斯核的SVM
發表于 06-17 08:00
?0次下載
可檢測網絡入侵的IL-SVM-KNN分類器
為滿足入侵檢測的實時性和準確性要求,通過結合支持向量機(SVM)和K最近鄰(KNN)算法設ⅡL-SM-KNN分類器,并采用平衡k維樹作為數據結構提升執行速度。訓練階段應用增量學習思想并考慮知識庫
發表于 04-29 15:55
?7次下載

cifar10數據集介紹 knn和svm的圖像分類系統案例
摘要:本文使用CIFAR-10數據集設計實現了基于k近鄰(knn)和支持向量機(svm)的圖像分類系統。首先介紹了CIFAR-10數據集及其特征,然后分析實現了兩種
發表于 07-18 15:23
?4次下載





 工商網監
工商網監
評論