 如何理解attention中的Q,K,V?
如何理解attention中的Q,K,V?
回答一:作者-不是大叔
我們直接用torch實現一個SelfAttention來說一說: 1.首先定義三個線性變換矩陣,query, key, value:
class BertSelfAttention(nn.Module):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.value=nn.Linear(config.hidden_size,self.all_head_size)#輸入768,輸出768
注意,這里的query, key, value只是一種操作(線性變換)的名稱,實際的Q/K/V是它們三個的輸出
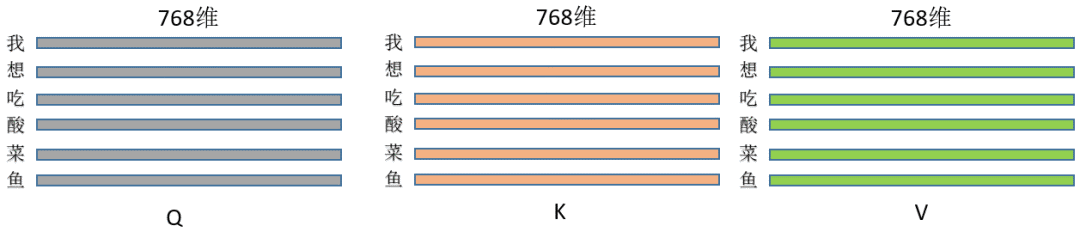
2. 假設三種操作的輸入都是同一個矩陣(暫且先別管為什么輸入是同一個矩陣),這里暫且定為長度為L的句子,每個token的特征維度是768,那么輸入就是(L,768),每一行就是一個字,像這樣:

乘以上面三種操作就得到了Q/K/V,(L, 768)*(768,768) = (L,768),維度其實沒變,即此刻的Q/K/V分別為:
代碼為:
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.value = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
def forward(self,hidden_states): # hidden_states 維度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
3. 然后來實現這個操作:
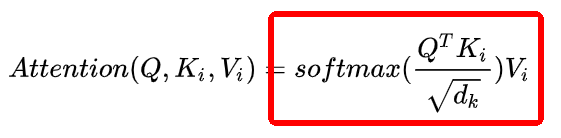
① 首先是Q和K矩陣乘,(L, 768)*(L, 768)的轉置=(L,L),看圖:
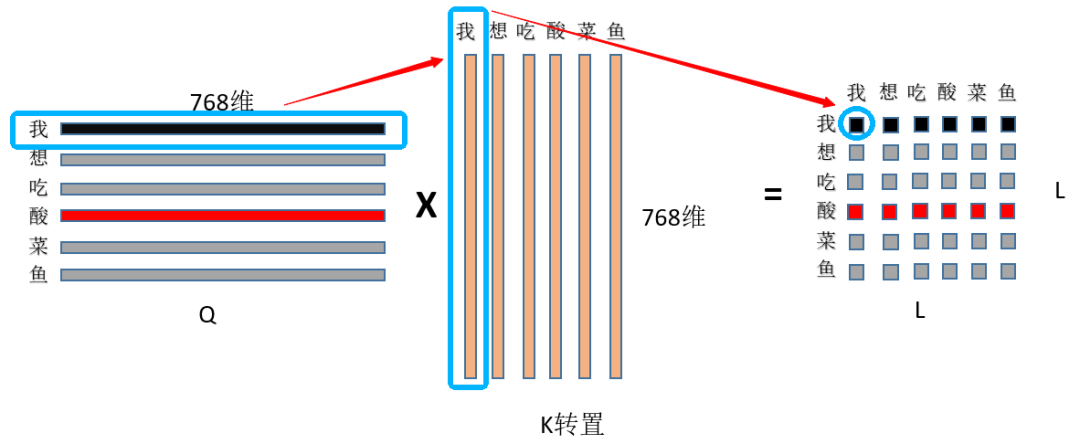
首先用Q的第一行,即“我”字的768特征和K中“我”字的768為特征點乘求和,得到輸出(0,0)位置的數值,這個數值就代表了“我想吃酸菜魚”中“我”字對“我”字的注意力權重,然后顯而易見輸出的第一行就是“我”字對“我想吃酸菜魚”里面每個字的注意力權重;整個結果自然就是“我想吃酸菜魚”里面每個字對其它字(包括自己)的注意力權重(就是一個數值)了~ ② 然后是除以根號dim,這個dim就是768,至于為什么要除以這個數值?主要是為了縮小點積范圍,確保softmax梯度穩定性,具體推導可以看這里:蓮生三十二:Self-attention中dot-product操作為什么要被縮放(https://zhuanlan.zhihu.com/p/149903065),然后就是為什么要softmax,一種解釋是為了保證注意力權重的非負性,同時增加非線性,還有一些工作對去掉softmax進行了實驗,如PaperWeekly:線性Attention的探索:Attention必須有個Softmax嗎?(https://zhuanlan.zhihu.com/p/157490738)
③ 然后就是剛才的注意力權重和V矩陣乘了,如圖:
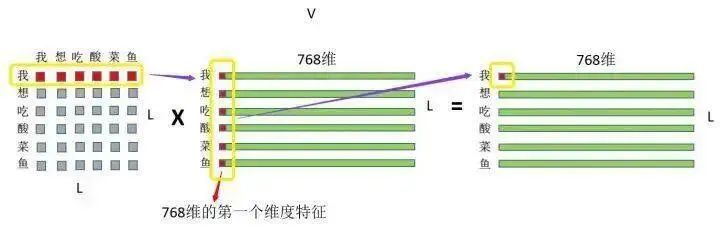
注意力權重 x VALUE矩陣 = 最終結果 首先是“我”這個字對“我想吃酸菜魚”這句話里面每個字的注意力權重,和V中“我想吃酸菜魚”里面每個字的第一維特征進行相乘再求和,這個過程其實就相當于用每個字的權重對每個字的特征進行加權求和,然后再用“我”這個字對對“我想吃酸菜魚”這句話里面每個字的注意力權重和V中“我想吃酸菜魚”里面每個字的第二維特征進行相乘再求和,依次類推~最終也就得到了(L,768)的結果矩陣,和輸入保持一致~
整個過程在草稿紙上畫一畫簡單的矩陣乘就出來了,一目了然~最后上代碼:
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
self.value = nn.Linear(config.hidden_size, self.all_head_size) # 輸入768, 輸出768
def forward(self,hidden_states): # hidden_states 維度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
attention_scores = torch.matmul(Q, K.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.Softmax(dim=-1)(attention_scores)
out = torch.matmul(attention_probs, V)
return out
4. 為什么叫自注意力網絡?因為可以看到Q/K/V都是通過同一句話的輸入算出來的,按照上面的流程也就是一句話內每個字對其它字(包括自己)的權重分配;那如果不是自注意力呢?簡單來說,Q來自于句A,K、V來自于句B即可~ 5. 注意,K/V中,如果同時替換任意兩個字的位置,對最終的結果是不會有影響的,至于為什么,可以自己在草稿紙上畫一畫矩陣乘;也就是說注意力機制是沒有位置信息的,不像CNN/RNN/LSTM;這也是為什么要引入位置embeding的原因。 02
回答二:作者-到處挖坑蔣玉成
其實直接用邱錫鵬老師PPT里的一張圖就可以直觀理解——假設D是輸入序列的內容,完全忽略線性變換的話可以近似認為Q=K=V=D(所以叫做Self-Attention,因為這是輸入的序列對它自己的注意力),于是序列中的每一個元素經過Self-Attention之后的表示就可以這樣展現:
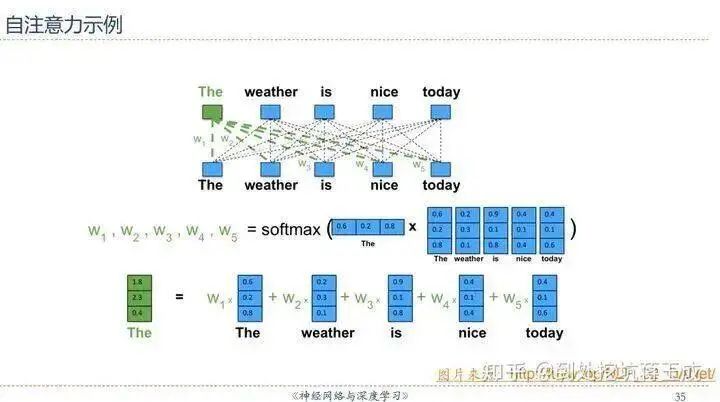
也就是說,The這個詞的表示,實際上是整個序列加權求和的結果——權重從哪來?點積之后Softmax得到——這里Softmax(QK)就是求權重的體現。我們知道,向量點積的值可以表征詞與詞之間的相似性,而此處的“整個序列”包括The這個詞自己(再一次強調這是Self-Attention),所以最后輸出的詞的表示,其“主要成分”就主要地包含它自身和跟它相似的詞的表示,其他無關的詞的表示對應的權重就會比較低。 03
回答三:作者-渠梁
首先附上鏈接:張俊林:深度學習中的注意力模型(2017版)(https://zhuanlan.zhihu.com/p/37601161) 。這個幾乎是我讀到過的講解Attention最為透徹的篇章之一了。 Q(Querry)代表查詢值,對應Decoder的H(t-1)狀態。這里要正確理解H(t-1),想要解碼出t時刻的輸出,你送入Decoder的必然有前一時刻計算出的隱狀態。好了,所謂查詢,就是你要拿著這個Decoder中的H(t-1)去和Encoder中各個時刻的隱狀態[H(1), H(2), ... , H(T)](也就是各個Key)去比,也就是二者計算相似度(對應于文獻中的各種energy函數)。最后算出來的結果用Softmax歸一化,這個算出來的權重就是帶有注意力機制的權重,其實在翻譯任務中,Key和Value是相等的。在Transformer的實現源碼中,Key和Value的初始值也是相等的。有了這個權重之后,就可以用這個權重對Value進行加權求和,生成的這個新的向量就是帶有注意力機制的語義向量 Context vector,而這個語義向量會權衡Target與Source的token與token的關系,從而實現解碼輸出時,與Source中“真正有決定意義”的token關聯。 姑且畫蛇添足的再說幾句:
首先,Attention機制是由Encoder-Decoder架構而來,且最初是用于完成NLP領域中的翻譯(Translation)任務。那么輸入輸出就是非常明顯的 Source-Target的對應關系,經典的Seq2Seq結構是從Encoder生成出一個語義向量(Contextvector)而不再變化,然后將這個語義向量送入Decoder配合解碼輸出。這種方法的最大問題就是這個語義向量,我們是希望它一成不變好呢?還是它最好能配合Decoder動態調整自己,來使Target中的某些token與Source中的真正“有決定意義”的token關聯起來好呢? 這就是為什么會有Attention機制的原因。說到底,Attention機制就是想生成會動態變化的語義向量來配合解碼輸出。而新貴 Self-Attention則是為了解決Target與Source各自內部token與token的關系。在Transformer中,這兩種注意力機制得到了有機的統一,釋放出了異常驚人的潛力。
審核編輯:黃飛
-
函數
+關注
關注
3文章
4338瀏覽量
62749 -
深度學習
+關注
關注
73文章
5507瀏覽量
121291
原文標題:【深度學習】如何理解attention中的Q,K,V?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么要有attention機制,Attention原理
50 V、100 mA PNP 電阻器晶體管;R1 = 22kΩ,R2 = 22kΩ-PDTA124ET-Q

50 V、100 mA PNP/PNP 電阻配備雙晶體管;R1 = 47kΩ,R2 = 47kΩ-PUMB2-Q
50V,100mA NPN/NPN 電阻配備雙晶體管;R1=47kΩ,R2=47kΩ-PUMH2-Q
50V,500mA NPN 電阻器晶體管;R1=2.2kΩ,R2=10kΩ-PDTD123YT-Q
NPN 500 mA、50 V 電阻晶體管;R1=1kΩ,R2=10kΩ-PDTD113ZT-Q
50V,100mA NPN 電阻器晶體管;R1=10kΩ,R2=47kΩ-PDTC114YT-Q
PNP 500 mA、50 V 電阻晶體管;R1=2.2kΩ,R2=10kΩ-PDTB123YT-Q
500 mA、50 V NPN 電阻器晶體管;R1=4.7kΩ,R2=4.7kΩ-PDTD143ET-Q
50V,100mA NPN/NPN 電阻器晶體管;R1=10kΩ,R2=10kΩ-PUMH11-Q
50V,100mA NPN 電阻器晶體管;R1=10kΩ,R2=10kΩ-PDTC114ET-Q
50V,100mA NPN/PNP 電阻配備雙晶體管;R1=10kΩ,R2=47kΩ-PUMD9-Q
簡述深度學習中的Attention機制
理解KV cache的作用及優化方法






 工商網監
工商網監
評論