 大模型對話系統的內功與外功
大模型對話系統的內功與外功
內功和外功,作為諸多武俠小說的兩大流派,有著諸多區別。內功主要是內力,外功主要是拳腳功夫,如熟知的降龍十八掌就是外家的頂峰功夫,任何武功若想發揮最大的威力都離不開內功的精深。內功是道,外功是術,道術結合,東方不敗。作為一個業余的武俠小說愛好者和剛入門的科研愛好者,這次從內功和外功的兩個角度出發,介紹我們我們組在 EMNLP 2023 中的兩個工作,如有不當之處,敬請原諒:
何為內功?
何為內功?按我的理解,要有功法,要運轉多少個小周天,大周天,要有真氣,真氣運轉之后要不變的更多,要不變的質量更好。何為功法?唯有 LLM 是也。何為小周天,大周天?唯有不同的 prompt engieering 或者說不同 path 的 chain-of-thoughts。何為真氣?即為對話歷史,也就是當前的輸入。對話歷史里面蘊藏著很多語義學線索,Mairesse 就研究過從對話歷史中識別出來人物性格特點等,比如性子急的講話就比較急躁,除此之外,其他工作也探索了類似情緒,心理狀態等等不同方面的語義學線索,這些語義學線索在生成個性化回復的時候尤為重要。
正如我們人類在進行對話的時候,不可避免的會考慮對方的性格習慣,當下的情緒和心理狀態等,LLM 在進行對話的時候也需要考慮到這些因素,從而生成更有幫助,更容易被用戶接受的回復。而相較于傳統的 standard prompting 而言,LLM 直接依賴對話歷史進行回復,沒有顯示的建模剛剛提到的隱藏在對話歷史中豐富的用戶信息,我們提出一種新的 CoT 方法,Cue-CoT,把用戶回復生成建模成多階段的推理過程:
O-Cue:One-step inference, 類似于傳統的 CoT,一步直接生成中間推理過程和最終回復。首先我們要求 LLM 推理出來當前對話歷史里面蘊含的不同維度的用戶信息(使用不同的 prompts),然后我們讓 LLM 接著生成最終的回復。(相對復雜的指令和內容臃腫的輸出)
M-Cue:Multi-step inference,我們逐步的生成我們想要 LLM 輸出的內容。和 O-Cue 一樣,這里第一步我們要求 LLM 推理出來當前對話歷史里面蘊含的不同維度的用戶信息,然后給定對話上下文和第一步生成的中間結果,我們第二步讓 LLM 接著生成最終的回復。(相對簡單的指令和內容清晰的輸出)

這兩種 prompting 的處理方式不同,帶來了 Zero-shot setting 和 One-shot setting(受限于 LLM input limit 和對話長度)的差別。
Zero-shot Setting:在 O-Cue 中,由于單步指令較復雜(不要要進行推理還要進行回復生成,以及生成的格式要求),單步生成內容過多,導致 LLM 無法很好的理解指令;生成內容較短,無論是中間推理結果還是最后回復的長度相對于 M-Cue 都短一點,另外還有一個嚴重的問題是生成內容無法很好的切分,因為一部分 LLM 無法按照要求的格式進行輸出。
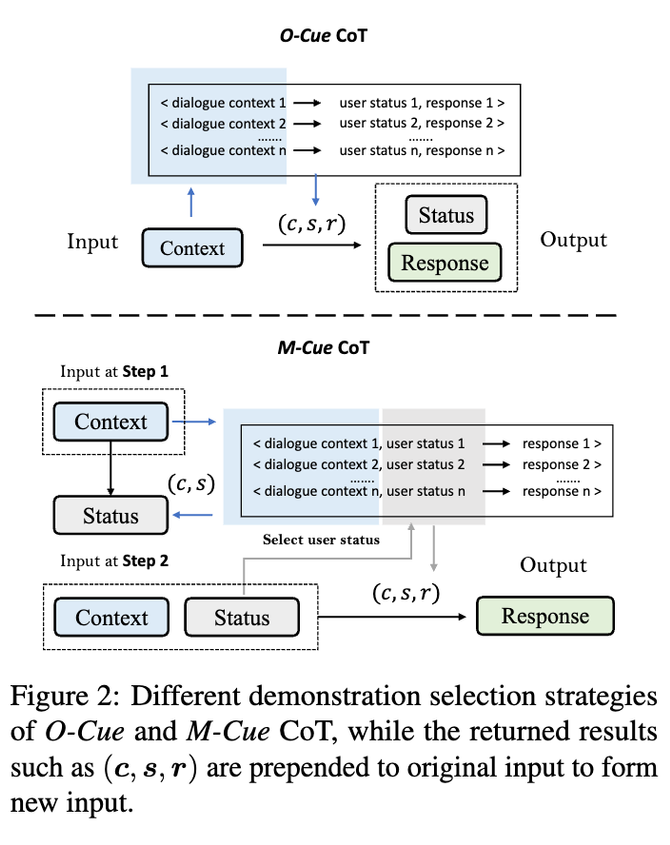
One-shot Setting:在進行 demostration selection 的過程中,也有著很大的區別。O-Cue 只能依賴單一的 input 即當前的對話上下文來作為 query 去 demostration pool 里面進行選擇,而 M-Cue 在每一步都可以根據不同的 input 去作為 query 進行選擇。
總的來說,M-Cue 這種處理方式可以增強整個系統的解釋性和控制性,我們對于中間結果可以進行編輯,比如增加對于當前用戶的其他渠道的數據,或者過濾掉不好或者不正確的推理結果,其次這種中間結果可以作為 demostration selection 的一個標準,從而幫助我們更好的選擇 demostration。
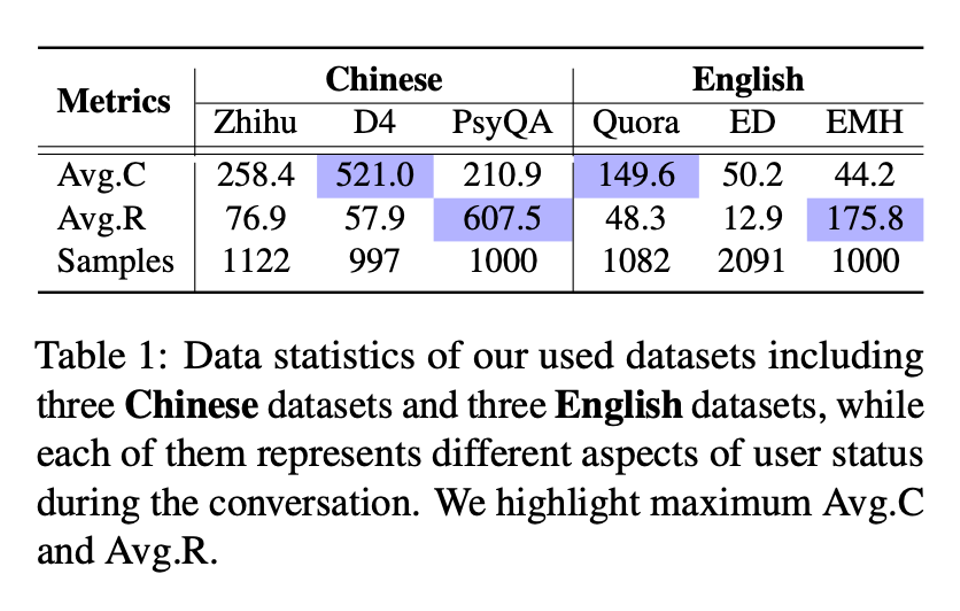
我們在 5 個中英文 LLM,6 個數據集(中文:Zhihu,D4,PsyQA;英文:Quora,ED,EMH)上將我們提出的 O-Cue 和 M-Cue 與傳統的 standard prompting 進行了對比,這里具體的分析可以參考原文,總體來說我們發現:
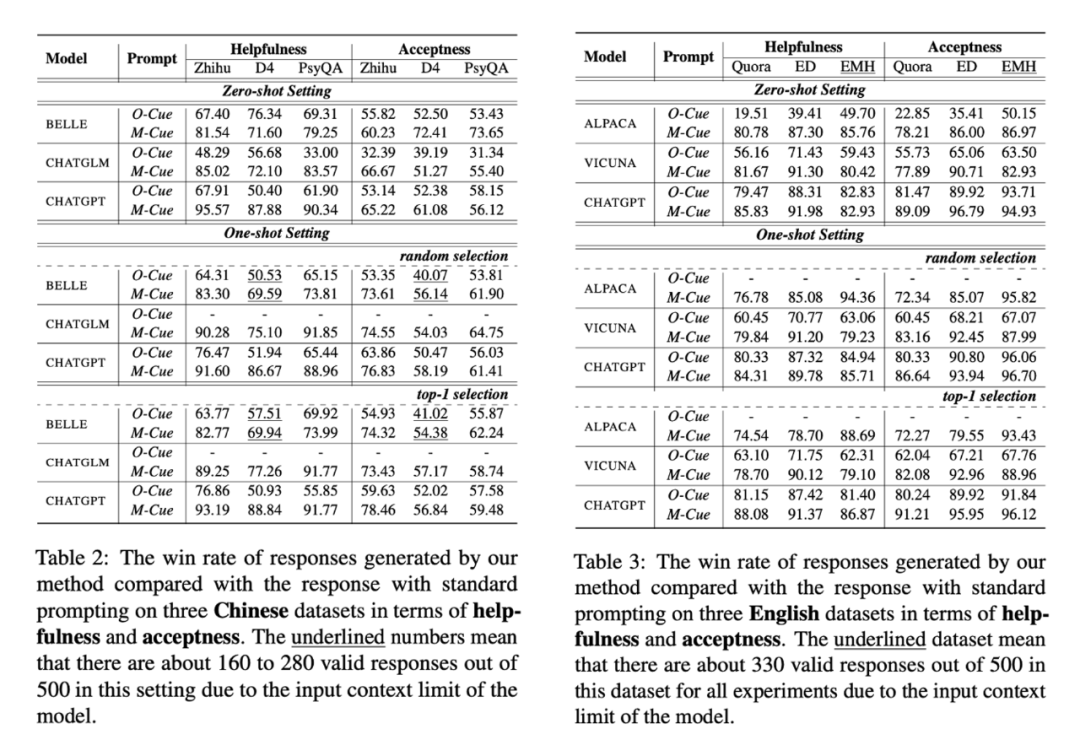
整體來說:大部分情況下 Cue-Cot 都能夠取得比 standard prompting 更好的效果(win rates 超過 50%),其中受益于相對簡單的指令和多步推理的輸出,M-Cue 比 O-Cue 能夠實現更高的 win rate。此外我們發現中文大模型上 acceptability 的 win rates 比 helpfulness 低,而英文大模型上剛好相反,我們猜測可能是由于中文大模型在根據當前用戶的情感,性格等因素生成更容易被用戶接受的回復的能力略弱,而僅僅考慮了 helpfulness 這個維度。
中文大模型:我們發現 ChatGLM 在 O-Cue 的情況下是三個模型當中最差的,然后我們檢查了對應的輸出,我們發現 ChatGLM 基本上忽視了給定的指令而直接進行對話;或者沒有按照指令要求輸出對應的格式,這可能歸結為其不同的訓練方式。但是在 M-Cue 的情況下所有的大模型都能很好的跟隨指令,這種情況下由于 D4 的對話上下文是最長的,導致其效果是三個數據集中最差的。
英文大模型:在 O-Cue 的情況下 Alpaca 也出現了類似 ChatGLM 的問題,即不能很好的跟隨指令,此外英文大模型在較長的對話輸入等場景下也表現不佳。整體來說 ChatGPT 和 Vicuna 的指令跟隨能力更強,相較于 Alpaca 而言都傾向于生成較長的回復。
注:以上實驗結果均基于 2023 年 5 月左右的模型表現。
以上均是方法層面的直接對比,我們額外進行了模型層面的對比。將 ChatGPT 作為錨點,我們評估了現有模型的相對表現。
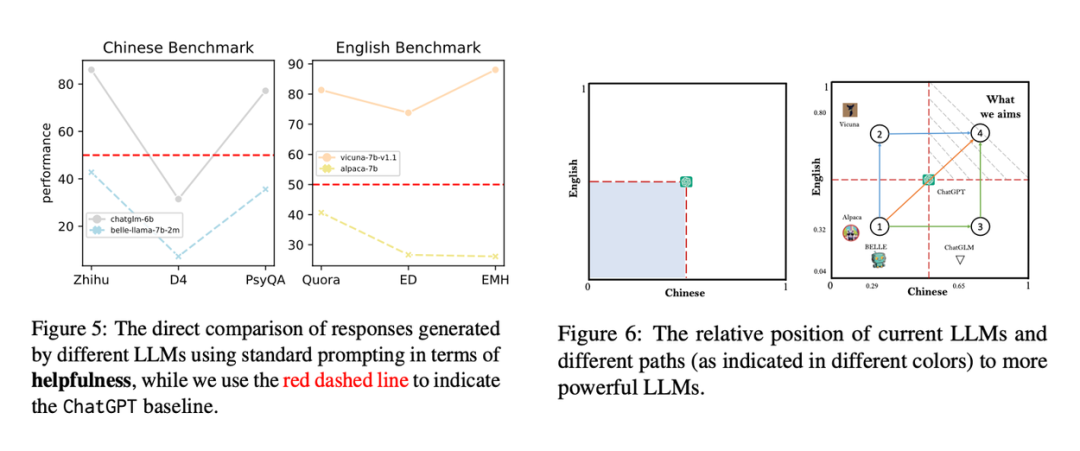
我們將中文和英文分別作為兩個坐標軸,以 ChatGPT 為中間點將第一象限分為四個不同的區域,區域一代表中英文均比 ChatGPT 差;區域二代表英文比 ChatGPT 好,但是中文較差;區域三代表中文比 ChatGPT 好,但是英文較差;區域四代表中英文均比 ChatGPT 好。我們發現目前在區域四還是沒有出現任何一個模型,我們設想了三種不同的路徑來幫助我們得到區域四的模型。
路徑一:直接不斷外推現有的 ChatGPT 的能力,如圖中橙色所示,OpenAI 可能是這條路線。
路徑二:由當前中文模型進一步的在英文語料上進行訓練,如 ChatGLM 或者其他中文模型。
路徑三:由當前英文模型進一步的在中文語料上進行訓練,如 LLaMA 系列的中文版本,Vicuna 和 Alpaca 的中文版本。
我們看到其實目前來說路徑三里面的模型是最多的,路徑一可能是最難的,路徑二一方面是現有的中文模型的基座能力還沒有達到上限;另一方面其英文能力可能也不是主流大模型玩家在乎的;還有一種可能是英文能力即使拉上去,可能也干不過 SOTA :)
很多只需要當前的對話歷史作為輸入,從而得到最終的答案的對話任務,如回復多樣性,回復選擇,對話信息抽取,對話摘要等等,都屬于內功。內功練得好,外功就用的越溜,因為在這個過程中,真氣沒有流失,要不壓縮之后進一步提純,質量變得更好了,比如從非結構化數據變成結構化數據;要不信息量得到增強,如情感分析等。這兩種不同的處理導致的結果都是變的更加適配下游任務了。
何為外功?
那何為外功?外功由內力驅使,借助外力,如刀槍劍戟,即為不同的工具。功法,運轉路徑,真氣,也是缺一不可。唯一不同的是這時候需要使用不同的刀法,劍法,即為不同工具的使用方法。那何時,何地使用工具,使用哪一個工具呢?這就是我們另外一個工作 SAFARI 所要探索的問題。
開放域對話系統往往需要很多的外部知識,比如用戶的 persona,和 wikipedia 上的 document,以及其他的一些我們設計出來的一些幫助我們生成更好回復的數據庫等等。這些不同的外部知識,比如 persona 和 document,其實就是不同的 conceptual tool [1]。
很多時候,不是每一輪對話都需要這些外部知識,也不是一下子就需要使用所有的外部知識,更復雜的是有時候這些知識庫之間存在依賴,比如我們傾向于見人說人話,見鬼說鬼話,這就是根據不同人的 persona 使用了不同的 document 的結果,所以這里的 document 就是依賴于對話者的 persona 的。而之前的開放域對話系統大部分都是針對單一知識來源,要不是 persona 要不是 document 要不是其他的,也有一部分工作是考慮了多個外部知識的復合作用,但是不加區分的對于對話中的每一輪都使用所有知識,這無疑會帶來額外的消耗和不必要的浪費。
在本篇工作中,我們首先構造了一個數據集,建模了 persona 和 document 之間的依賴關系,其中 persona 的維度包括了年齡,性別,民族,愛好等 12 個維度,基本涵蓋了當下個性化對話的大部分需求,然后我們按照不同的 persona description 提供了對應的 document,包括 5 個不同的 knowledge sentences。
舉個例子,persona description 包括有:我今年 16 歲,那對應的 document 里面包括的知識可能是 16 歲是未成年人,16 歲無法喝酒 等等。一條簡單的 persona 描述背后可能隱藏著非常多的常識知識和世界知識,退一步說,即使 persona 和 document 之間沒有直接的聯系,我們在做 document selection 的時候其實還是受到 persona 或者 memory 等因素隱性的影響,參考《There Are a Thousand Hamlets in a Thousand People’s Eyes: Enhancing Knowledge-grounded Dialogue with Personal Memory》[2]。
總的來說,我們首先構建了將近 3k 多條多輪對話,在一個多輪對話包括三個不同的場景:1)不使用任何外部知識;2)僅使用 persona knowledge source;3)既使用 persona 又使用 documents(這里 persona 和 document 存在依賴關系)。
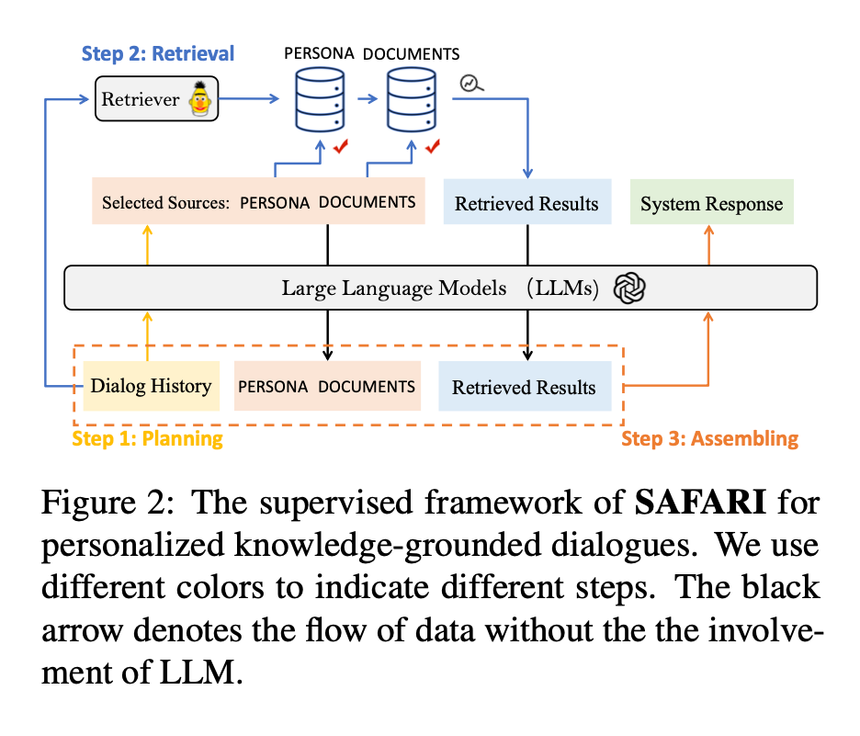
為了同時建模這三種場景,我們提出一個框架 SAFARI,將外部知識選擇和回復生成進行解耦。具體來說我們將整個對話回復生成解耦成三個任務,1)Planning:規劃是否需要使用知識,何時使用知識,以及多種知識庫之間的調用順序;2)Retrieval:使用外部的 retriever 對上一步規劃使用的知識庫按順序抽取對應的 Top-n 的輔助文檔;3)Assembling:將對話上下文和中間抽取到的輔助文檔拼接在一起進行最終的回復生成。
我們同時研究了在 supervised 和 unsupervised 兩種設定下 SAFARI 的實現方式,并且評估了三種不同 LLM 的表現(BELLE,ChatGLM 和 ChatGPT)。

Supervised SAFARI:我們將整個過程建模成一個序列生成任務,整體思想類似于 ReWOO+ToolkenGPT 的結合體,但是限于匿名期,我們沒有及時的披露。
具體來說,我們將不同的 source(不使用任何 source 視為 NULL)作為 special tokens 加入到大模型的詞表里面,然后要求大模型輸出一個 source 序列,代表不同 source 一個調用順序,如下圖所示,然后我們將對應 source 的 ground-truth 輔助文檔和對話上下文,輸出的 source 作為輸入,要求大模型輸出最終的模型,以這種形式,我們只需要將 loss 加在 source 訓練和最終的回復上即可進行端到端的訓練。推理的時候需要進行兩步推理,和以上介紹的類似,不再贅述。
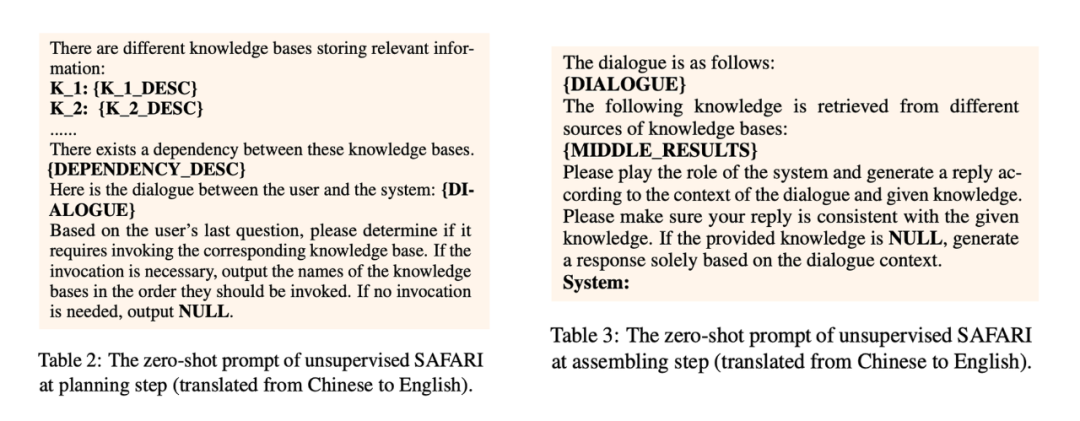
Unsupervised SAFARI:給定一些 demostrations,我們直接使用 prompt 來要求大模型輸出我們需要的內容,比如第一步要求大模型直接輸出 source 序列,第二步根據對話上下文和中間輔助文檔生成對應的回復。prompt 如圖所示:
我們詳細對比了不同的大模型在兩種設定下的表現,首先我們看 planning 的表現,如下圖所示,整體而言經過訓練的大模型能夠取得比 unsupervised 更好的效果(LoRA 微調),但是在 NULL 和 Persona 的效果仍然不是很理想,這可能和我們的數據分布比較相關。
在 unsupervised 的設定下,我們發現 zero-shot 情況下 BELLE 和 ChatGLM 通常表現出過度自信(大部分都選擇不使用任何知識),而 ChatGPT 就好很多,但是也仍然無法理解多個 source 之間存在 dependency 的情況,很多 cases 下僅僅選擇使用 Documents,In-context learning 無法帶來明顯的增益,這一方面是由于我們使用的是隨機選擇的 3 個案例作為 demostrations,另一方面 in-context learning 在解決大模型的 uncertainy 上似乎也不是一個有效方案 [3]。
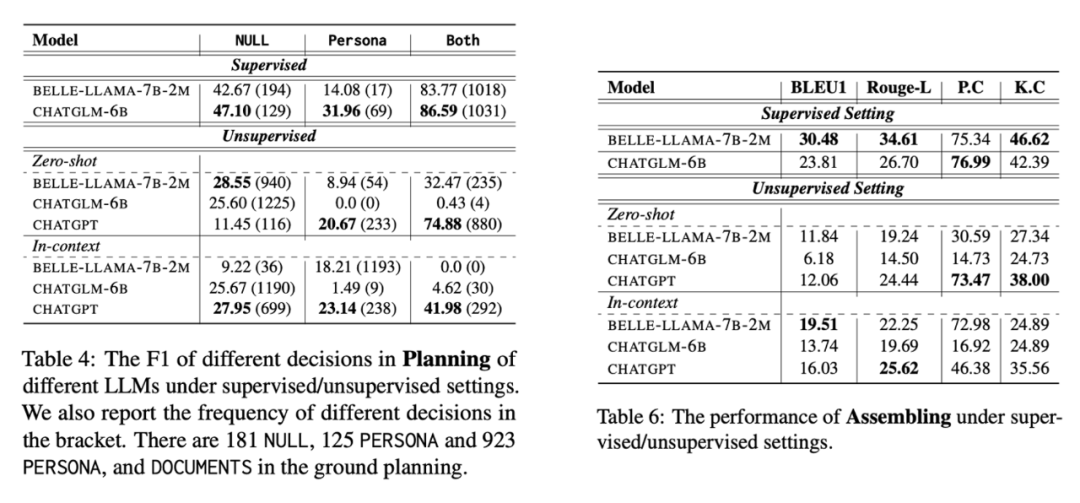
然后我們看 Assmbling 的表現,由于這里的 Assemling 非常依賴上面的 planning 的結果,所以需要結合起來進行分析。經過訓練的模型往往能取得更好的效果,尤其是在 BLEU1 和 RougeL上,然后在 unsupervised 下,Zero-shot ChatGPT 的效果都是最好的,而 In-context learning 的時候 BELLE 是最好的,這是由于 In-context learning 的 BELLE 在進行 planning 的時候選擇了大量的 Persona,所以導致會使用更多的輔助文檔,相較于 In-context ChatGPT 而言,從而取得更好的效果。
其他消融分析和實驗結果可以參考原文,我們還對比了不同的 source 策略的效果,比如無腦選擇使用所有 source,無腦使用 Persona 等等。我們相信 SAFARI 框架還有這巨大的潛力等待挖掘,也可以用來處理現實生活中更加復雜的場景,但受限于時間和 benchmark 的缺乏,我們沒有做更進一步的驗證,我們也歡迎感興趣的同學或者老師一起合作交流。
寫在最后
本文探討了一種以內外的視角去看待大模型時代下的對話系統,我們也關注內外合并,并做了簡單的初步探索,歡迎大家關注我們的下一篇文章。總的來說,我們認為對話上下文中蘊含的豐富的內部信息 + 外部知識調用將會是未來 LLM-based 對話系統的重要研究方向,尤其是在與不同的 Source,不同的 Task 上的交互從而帶來的不同應用場景和設計。Stay Tuned!!
-
數據集
+關注
關注
4文章
1209瀏覽量
24792 -
大模型
+關注
關注
2文章
2541瀏覽量
3019 -
LLM
+關注
關注
0文章
298瀏覽量
366
原文標題:武俠小說視角:大模型對話系統的內功與外功
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
吳鑒鷹大侃單片機系列之俠客行__論內功&外功
吳鑒鷹大侃單片機系列之俠客行__論內功&外功
嵌入式軟件工程師的內功修煉
人機交互的核心對話系統
基于分層編碼的深度增強學習對話生成
如何成為一名對話系統工程師
強化學習應用中對話系統的用戶模擬器
對話系統最原始的實現方式 檢索式對話
CRSLab對話推薦系統開源庫 相關代碼和對應論文目前已經開源


NLP中基于聯合知識的任務導向型對話系統HyKnow
對話文本數據是培養大模型的智能與交流之源
對話文本數據的珍貴貢獻:訓練大模型賦予智能與情感理解
源2.0適配FastChat框架,企業快速本地化部署大模型對話平臺






 工商網監
工商網監
評論