 Netfilter 的設計與實現
Netfilter 的設計與實現
Netfilter (配合 iptables)使得用戶空間應用程序可以注冊內核網絡棧在處理數據包時應用的處理規則,實現高效的網絡轉發和過濾。很多常見的主機防火墻程序以及 Kubernetes 的 Service 轉發都是通過 iptables 來實現的。
關于 netfilter 的介紹文章大部分只描述了抽象的概念,實際上其內核代碼的基本實現不算復雜,本文主要參考 Linux 內核 2.6 版本代碼(早期版本較為簡單),與最新的 5.x 版本在實現上可能有較大差異,但基本設計變化不大,不影響理解其原理。
本文假設讀者已對 TCP/IP 協議有基本了解。
Netfilter 的設計與實現
netfilter 的定義是一個工作在 Linux 內核的網絡數據包處理框架,為了徹底理解 netfilter 的工作方式,我們首先需要對數據包在 Linux 內核中的處理路徑建立基本認識。
數據包的內核之旅
數據包在內核中的處理路徑,也就是處理網絡數據包的內核代碼調用鏈,大體上也可按 TCP/IP 模型分為多個層級,以接收一個 IPv4 的 tcp 數據包為例:
- 在物理-網絡設備層,網卡通過 DMA 將接收到的數據包寫入內存中的 ring buffer,經過一系列中斷和調度后,操作系統內核調用 __skb_dequeue 將數據包加入對應設備的處理隊列中,并轉換成 sk_buffer 類型(即 socket buffer - 將在整個內核調用棧中持續作為參數傳遞的基礎數據結構,下文指稱的數據包都可以認為是 sk_buffer),最后調用 netif_receive_skb 函數按協議類型對數據包進行分類,并跳轉到對應的處理函數。如下圖所示:
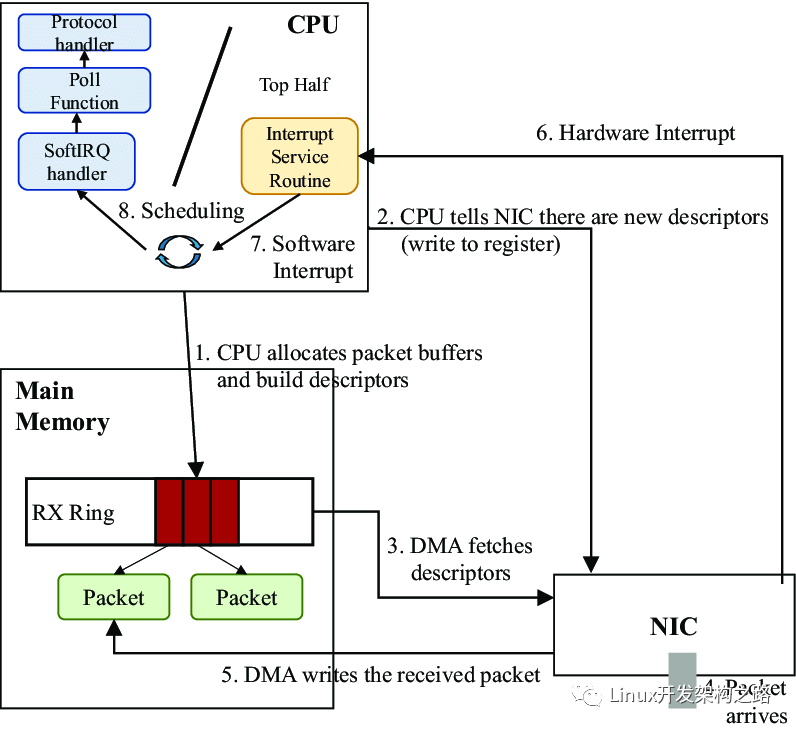
network-path
- 假設該數據包為 IP 協議包,對應的接收包處理函數 ip_rcv 將被調用,數據包處理進入網絡(IP)層。ip_rcv 檢查數據包的 IP 首部并丟棄出錯的包,必要時還會聚合被分片的 IP 包。然后執行 ip_rcv_finish 函數,對數據包進行路由查詢并決定是將數據包交付本機還是轉發其他主機。假設數據包的目的地址是本主機,接著執行的 dst_input 函數將調用 ip_local_deliver 函數。ip_local_deliver 函數中將根據 IP 首部中的協議號判斷載荷數據的協議類型,最后調用對應類型的包處理函數。本例中將調用 TCP 協議對應的 tcp_v4_rcv 函數,之后數據包處理進入傳輸層。
- tcp_v4_rcv 函數同樣讀取數據包的 TCP 首部并計算校驗和,然后在數據包對應的 TCP control buffer 中維護一些必要狀態包括 TCP 序列號以及 SACK 號等。該函數下一步將調用 __tcp_v4_lookup 查詢數據包對應的 socket,如果沒找到或 socket 的連接狀態處于TCP_TIME_WAIT,數據包將被丟棄。如果 socket 處于未加鎖狀態,數據包將通過調用 tcp_prequeue 函數進入 prequeue 隊列,之后數據包將可被用戶態的用戶程序所處理。傳輸層的處理流程超出本文討論范圍,實際上還要復雜很多。
netfilter hooks
接下來我們正式進入主題。netfilter 的首要組成部分是 netfilter hooks。
hook 觸發點
對于不同的協議(IPv4、IPv6 或 ARP 等),Linux 內核網絡棧會在該協議棧數據包處理路徑上的預設位置觸發對應的 hook。在不同協議處理流程中的觸發點位置以及對應的 hook 名稱(藍色矩形外部的黑體字)如下,本文僅重點關注 IPv4 協議:

netfilter-flow
所謂的 hook 實質上是代碼中的枚舉對象(值為從 0 開始遞增的整型):
enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS };
每個 hook 在內核網絡棧中對應特定的觸發點位置,以 IPv4 協議棧為例,有以下 netfilter hooks 定義:

netfilter-hooks-stack
- NF_INET_PRE_ROUTING: 這個 hook 在 IPv4 協議棧的 ip_rcv 函數或 IPv6 協議棧的 ipv6_rcv 函數中執行。所有接收數據包到達的第一個 hook 觸發點(實際上新版本 Linux 增加了 INGRESS hook 作為最早觸發點),在進行路由判斷之前執行。
- NF_INET_LOCAL_IN: 這個 hook 在 IPv4 協議棧的 ip_local_deliver() 函數或 IPv6 協議棧的 ip6_input() 函數中執行。經過路由判斷后,所有目標地址是本機的接收數據包到達此 hook 觸發點。
- NF_INET_FORWARD: 這個 hook 在 IPv4 協議棧的 ip_forward() 函數或 IPv6 協議棧的 ip6_forward() 函數中執行。經過路由判斷后,所有目標地址不是本機的接收數據包到達此 hook 觸發點。
- NF_INET_LOCAL_OUT: 這個 hook 在 IPv4 協議棧的 __ip_local_out() 函數或 IPv6 協議棧的 __ip6_local_out() 函數中執行。所有本機產生的準備發出的數據包,在進入網絡棧后首先到達此 hook 觸發點。
- NF_INET_POST_ROUTING: 這個 hook 在 IPv4 協議棧的 ip_output() 函數或 IPv6 協議棧的 ip6_finish_output2() 函數中執行。本機產生的準備發出的數據包或者轉發的數據包,在經過路由判斷之后, 將到達此 hook 觸發點。
NF_HOOK 宏和 netfilter 向量
所有的觸發點位置統一調用 NF_HOOK 這個宏來觸發 hook:
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct sk_buff *)) { return NF_HOOK_THRESH(pf, hook, skb, in, out, okfn, INT_MIN); }
NF-HOOK 接收的參數如下:
- pf: 數據包的協議族,對 IPv4 來說是 NFPROTO_IPV4。
- hook: 上圖中所示的 netfilter hook 枚舉對象,如 NF_INET_PRE_ROUTING 或 NF_INET_LOCAL_OUT。
- skb: SKB 對象,表示正在被處理的數據包。
- in: 數據包的輸入網絡設備。
- out: 數據包的輸出網絡設備。
- okfn: 一個指向函數的指針,該函數將在該 hook 即將終止時調用,通常傳入數據包處理路徑上的下一個處理函數。
NF-HOOK 的返回值是以下具有特定含義的 netfilter 向量之一:
- NF_ACCEPT: 在處理路徑上正常繼續(實際上是在 NF-HOOK 中最后執行傳入的 okfn)。
- NF_DROP: 丟棄數據包,終止處理。
- NF_STOLEN: 數據包已轉交,終止處理。
- NF_QUEUE: 將數據包入隊后供其他處理。
- NF_REPEAT: 重新調用當前 hook。
回歸到源碼,IPv4 內核網絡棧會在以下代碼模塊中調用 NF_HOOK():

NF_HOOK
實際調用方式以 net/ipv4/ip_forward.c[1] 對數據包進行轉發的源碼為例,在 ip_forward 函數結尾部分的第 115 行以 NF_INET_FORWARDhook 作為入參調用了 NF_HOOK 宏,并將網絡棧接下來的處理函數 ip_forward_finish 作為 okfn 參數傳入:
int ip_forward(struct sk_buff *skb) { .....(省略部分代碼) if (rt- >rt_flags&RTCF_DOREDIRECT && !opt- >srr && !skb_sec_path(skb)) ip_rt_send_redirect(skb); skb- >priority = rt_tos2priority(iph- >tos); return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, skb, skb- >dev, rt- >dst.dev, ip_forward_finish); .....(省略部分代碼) }
回調函數與優先級
netfilter 的另一組成部分是 hook 的回調函數。內核網絡棧既使用 hook 來代表特定觸發位置,也使用 hook (的整數值)作為數據索引來訪問觸發點對應的回調函數。
內核的其他模塊可以通過 netfilter 提供的 api 向指定的 hook 注冊回調函數,同一 hook 可以注冊多個回調函數,通過注冊時指定的 priority 參數可指定回調函數在執行時的優先級。
注冊 hook 的回調函數時,首先需要定義一個 nf_hook_ops 結構(或由多個該結構組成的數組),其定義如下:
struct nf_hook_ops { struct list_head list; /* User fills in from here down. */ nf_hookfn *hook; struct module *owner; u_int8_t pf; unsigned int hooknum; /* Hooks are ordered in ascending priority. */ int priority; };
在定義中有 3 個重要成員:
- hook: 將要注冊的回調函數,函數參數定義與 NF_HOOK 類似,可通過 okfn參數嵌套其他函數。
- hooknum: 注冊的目標 hook 枚舉值。
- priority: 回調函數的優先級,較小的值優先執行。
定義結構體后可通過 int nf_register_hook(struct nf_hook_ops *reg) 或 int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n); 分別注冊一個或多個回調函數。同一 netfilter hook 下所有的nf_hook_ops 注冊后以 priority 為順序組成一個鏈表結構,注冊過程會根據 priority 從鏈表中找到合適的位置,然后執行鏈表插入操作。
在執行 NF-HOOK 宏觸發指定的 hook 時,將調用 nf_iterate 函數迭代這個 hook 對應的 nf_hook_ops 鏈表,并依次調用每一個 nf_hook_ops 的注冊函數成員 hookfn。示意圖如下:

netfilter-hookfn1
這種鏈式調用回調函數的工作方式,也讓 netfilter hook 被稱為 Chain,下文的 iptables 介紹中尤其體現了這一關聯。
每個回調函數也必須返回一個 netfilter 向量;如果該向量為 NF_ACCEPT,nf_iterate 將會繼續調用下一個 nf_hook_ops 的回調函數,直到所有回調函數調用完畢后返回 NF_ACCEPT;如果該向量為 NF_DROP,將中斷遍歷并直接返回 NF_DROP; 如果該向量為 NF_REPEAT ,將重新執行該回調函數 。nf_iterate 的返回值也將作為 NF-HOOK 的返回值,網絡棧將根據該向量值判斷是否繼續執行處理函數。示意圖如下:

netfilter-hookfn2
netfilter hook 的回調函數機制具有以下特性:
- 回調函數按優先級依次執行,只有上一回調函數返回 NF_ACCEPT 才會繼續執行下一回調函數。
- 任一回調函數都可以中斷該 hook 的回調函數執行鏈,同時要求整個網絡棧中止對數據包的處理。
iptables
基于內核 netfilter 提供的 hook 回調函數機制,netfilter 作者 Rusty Russell 還開發了 iptables,實現在用戶空間管理應用于數據包的自定義規則。
iptbles 分為兩部分:
- 用戶空間的 iptables 命令向用戶提供訪問內核 iptables 模塊的管理界面。
- 內核空間的 iptables 模塊在內存中維護規則表,實現表的創建及注冊。
內核空間模塊
xt_table 的初始化
在內核網絡棧中,iptables 通過 xt_table 結構對眾多的數據包處理規則進行有序管理,一個 xt_table 對應一個規則表,對應的用戶空間概念為 table。不同的規則表有以下特征:
- 對不同的 netfilter hooks 生效。
- 在同一 hook 中檢查不同規則表的優先級不同。
基于規則的最終目的,iptables 默認初始化了 4 個不同的規則表,分別是 raw、 filter、nat 和 mangle。下文以 filter 為例介紹 xt_table的初始化和調用過程。
filter table 的定義如下:
#define FILTER_VALID_HOOKS ((1 < < NF_INET_LOCAL_IN) | (1 < < NF_INET_FORWARD) | (1 < < NF_INET_LOCAL_OUT)) static const struct xt_table packet_filter = { .name = "filter", .valid_hooks = FILTER_VALID_HOOKS, .me = THIS_MODULE, .af = NFPROTO_IPV4, .priority = NF_IP_PRI_FILTER, }; (net/ipv4/netfilter/iptable_filter.c)
在 iptable_filter.c[2] 模塊的初始化函數 iptable_filter_init ****中,調用xt_hook_link 對 xt_table 結構 packet_filter 執行如下初始化過程:
- 通過 .valid_hooks 屬性迭代 xt_table 將生效的每一個 hook,對于 filter 來說是 NF_INET_LOCAL_IN,NF_INET_FORWARD 和 NF_INET_LOCAL_OUT這 3 個 hook。
- 對每一個 hook,使用 xt_table 的 priority 屬性向 hook 注冊一個回調函數。
不同 table 的 priority 值如下:
enum nf_ip_hook_priorities { NF_IP_PRI_RAW = -300, NF_IP_PRI_MANGLE = -150, NF_IP_PRI_NAT_DST = -100, NF_IP_PRI_FILTER = 0, NF_IP_PRI_SECURITY = 50, NF_IP_PRI_NAT_SRC = 100, };
當數據包到達某一 hook 觸發點時,會依次執行不同 table 在該 hook 上注冊的所有回調函數,這些回調函數總是根據上文的 priority 值以固定的相對順序執行:

tables-priority
ipt_do_table()
filter 注冊的 hook 回調函數 iptable_filter_hook[3] 將對 xt_table 結構執行公共的規則檢查函數 ipt_do_table[4]。ipt_do_table 接收 skb、hook 和 xt_table作為參數,對 skb 執行后兩個參數所確定的規則集,返回 netfilter 向量作為回調函數的返回值。
在深入規則執行過程前,需要先了解規則集如何在內存中表示。每一條規則由 3 部分組成:
- 一個 ipt_entry 結構體。通過 .next_offset 指向下一個 ipt_entry 的內存偏移地址。
- 0 個或多個 ipt_entry_match 結構體,每個結構體可以動態的添加額外數據。
- 1 個 ipt_entry_target 結構體, 結構體可以動態的添加額外數據。
ipt_entry 結構體定義如下:
struct ipt_entry { struct ipt_ip ip; unsigned int nfcache; /* ipt_entry + matches 在內存中的大小*/ u_int16_t target_offset; /* ipt_entry + matches + target 在內存中的大小 */ u_int16_t next_offset; /* 跳轉后指向前一規則 */ unsigned int comefrom; /* 數據包計數器 */ struct xt_counters counters; /* 長度為0數組的特殊用法,作為 match 的內存地址 */ unsigned char elems[0]; };
ipt_do_table 首先根據 hook 類型以及 xt_table.private.entries屬性跳轉到對應的規則集內存區域,執行如下過程:

ipt_do_table
- 首先檢查數據包的 IP 首部與第一條規則 ipt_entry 的 .ipt_ip 屬性是否一致,如不匹配根據 next_offset 屬性跳轉到下一條規則。
- 若 IP 首部匹配 ,則開始依次檢查該規則所定義的所有 ipt_entry_match 對象,與對象關聯的匹配函數將被調用,根據調用返回值有返回到回調函數(以及是否丟棄數據包)、跳轉到下一規則或繼續檢查等結果。
- 所有檢查通過后讀取 ipt_entry_target,根據其屬性返回 netfilter 向量到回調函數、繼續下一規則或跳轉到指定內存地址的其他規則,非標準 ipt_entry_target 還會調用被綁定的函數,但只能返回向量值不能跳轉其他規則。
靈活性和更新時延
以上數據結構與執行方式為 iptables 提供了強大的擴展能力,我們可以靈活地自定義每條規則的匹配條件并根據結果執行不同行為,甚至還能在額外的規則集之間棧式跳轉。
由于每條規則長度不等、內部結構復雜,且同一規則集位于連續的內存空間,iptables 使用全量替換的方式來更新規則,這使得我們能夠從用戶空間以原子操作來添加/刪除規則,但非增量式的規則更新會在規則數量級較大時帶來嚴重的性能問題:假如在一個大規模 Kubernetes 集群中使用 iptables 方式實現 Service,當 service 數量較多時,哪怕更新一個 service 也會整體修改 iptables 規則表。全量提交的過程會 kernel lock 進行保護,因此會有很大的更新時延。
用戶空間的 tables、chains 和 rules
用戶空間的 iptables 命令行可以讀取指定表的數據并渲染到終端,添加新的規則(實際上是替換整個 table 的規則表)等。
iptables 主要操作以下幾種對象:
- table:對應內核空間的 xt_table 結構,iptable 的所有操作都對指定的 table 執行,默認為 filter。
- chain:對應指定 table 通過特定 netfilter hook 調用的規則集,此外還可以自定義規則集,然后從 hook 規則集中跳轉過去。
- rule:對應上文中 ipt_entry、ipt_entry_match 和ipt_entry_target,定義了對數據包的匹配規則以及匹配后執行的行為。
- match:具有很強擴展性的自定義匹配規則。
- target:具有很強擴展性的自定義匹配后行為。
基于上文介紹的代碼調用過程流程,chain 和 rule 按如下示意圖執行:

iptables-chains
對于 iptables 具體的用法和指令本文不做詳細介紹。
conntrack
僅僅通過 3、4 層的首部信息對數據包進行過濾是不夠的,有時候還需要進一步考慮連接的狀態。netfilter 通過另一內置模塊 conntrack 進行連接跟蹤(connection tracking),以提供根據連接過濾、地址轉換(NAT)等更進階的網絡過濾功能。由于需要對連接狀態進行判斷,conntrack 在整體機制相同的基礎上,又針對協議特點有單獨的實現。
-
數據包
+關注
關注
0文章
265瀏覽量
24415 -
模型
+關注
關注
1文章
3268瀏覽量
48932 -
應用程序
+關注
關注
37文章
3283瀏覽量
57761 -
netfilter
+關注
關注
0文章
6瀏覽量
7192
發布評論請先 登錄
相關推薦
Linux內核防火墻netfilter的原理和應用
如何去實現netfilter呢
netfilter技術分析及在入侵響應中的應用
基于Netfilter的NAT技術及其應用
基于Netfilter內核態網絡流量分析研究
netfilter技術分析
什么是netfilter?netfilter是什么意思?
Linux網絡防火墻Netfilter的數據包傳輸過濾原理

Iptables的移植步驟
Iptables移植到嵌入式Linux系統

Linux內核中Netfilter的設計與實現
簡述kube-proxy ipvs原理
Netfilter/iptables






 工商網監
工商網監
評論