") 從ID-based到LLM-based:可遷移推薦系統(tǒng)發(fā)展
從ID-based到LLM-based:可遷移推薦系統(tǒng)發(fā)展
 可遷移推薦系統(tǒng)發(fā)展歷程
可遷移推薦系統(tǒng)發(fā)展歷程
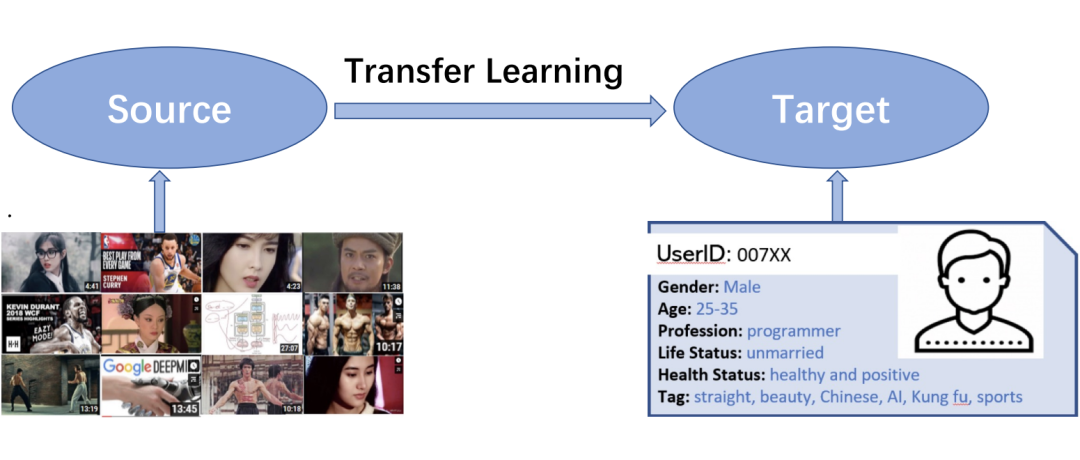
推薦系統(tǒng)的核心目標(biāo)是通過建模用戶的歷史行為預(yù)測(cè)最有可能交互的下一個(gè)目標(biāo)。而這一目標(biāo)在用戶交互記錄較少的情況下尤為困難,即長期困擾推薦系統(tǒng)領(lǐng)域發(fā)展的冷啟動(dòng)問題。在這些新用戶很少并且其交互序列有限的新推薦系統(tǒng)場(chǎng)景中,前期的模型訓(xùn)練往往缺乏足夠的樣本數(shù)據(jù)。對(duì)有限訓(xùn)練數(shù)據(jù)的建模也必然無法獲得用戶滿意的推薦結(jié)果,使得平臺(tái)成長受到很大阻礙。
遷移學(xué)習(xí)是學(xué)術(shù)界和工業(yè)界為了解決這一問題所一直關(guān)注的解決方案。如果可以向新場(chǎng)景中引入預(yù)先訓(xùn)練到的知識(shí)幫助建模用戶序列或加速建模速度,這將極大緩解下游新場(chǎng)景中冷啟動(dòng)問題帶來的巨大成本。
為此,對(duì)可遷移推薦系統(tǒng)的研究幾乎貫穿了推薦系統(tǒng)領(lǐng)域發(fā)展的每一個(gè)階段。從基于物品 ID 和用戶 ID 的矩陣分解時(shí)代,可遷移推薦系統(tǒng)必須基于上下游場(chǎng)景的數(shù)據(jù)覆蓋實(shí)現(xiàn)基于 ID 的推薦系統(tǒng)遷移學(xué)習(xí)。
到近幾年模態(tài)理解技術(shù)發(fā)展迅猛,研究人員逐漸轉(zhuǎn)向利用純模態(tài)信息建模用戶序列,從而實(shí)現(xiàn)在上下游場(chǎng)景沒有數(shù)據(jù)覆蓋的情況下實(shí)現(xiàn)可遷移推薦系統(tǒng)。再到當(dāng)下利用大規(guī)模預(yù)訓(xùn)練語言模型(LLM)完成 ‘one-for-all’ 的推薦系統(tǒng)大模型得到大量關(guān)注。可遷移推薦系統(tǒng)乃至推薦系統(tǒng)大模型的研究已成為推薦系統(tǒng)領(lǐng)域發(fā)展的下一個(gè)方向。

基于ID的可遷移推薦系統(tǒng)
第一階段是矩陣分解時(shí)代,使用 ID embedding 來建模物品的協(xié)同過濾算法是推薦系統(tǒng)的主流范式,并在之后的 15 年間主導(dǎo)了整個(gè)推薦系統(tǒng)社區(qū)。經(jīng)典架構(gòu)包括:雙塔架構(gòu)、CTR 模型、會(huì)話和序列推薦、Graph 網(wǎng)絡(luò)。他們無不采用 ID embedding 來對(duì)物品進(jìn)行建模,整個(gè)推薦系統(tǒng)現(xiàn)有的 SOTA 體系也幾乎都是采用基于 ID 特征的建模手段。
這一階段,可遷移推薦系統(tǒng)自然依靠 ID 實(shí)現(xiàn),而且必須在上下游場(chǎng)景之間有數(shù)據(jù)重疊,即要求不同數(shù)據(jù)集之間存在共同用戶或者物品,例如大公司里存在多個(gè)業(yè)務(wù)場(chǎng)景, 通過老的業(yè)務(wù)引流新的業(yè)務(wù)。這一階段的早期工作有 PeterRec [1](SIGIR2020)、Conure [2](SIGIR2021)和 CLUE [3] (ICDM2021)等。
PeterRec 是推薦系統(tǒng)領(lǐng)域首篇論文明確提出基于自監(jiān)督預(yù)訓(xùn)練(自回歸與 Mask 語言模型)的用戶表征具備通用性,并清晰地呈現(xiàn)出該預(yù)訓(xùn)練的通用表征可用于跨域推薦和用戶畫像預(yù)測(cè),顯著提升性能,其中,采用用戶畫像預(yù)測(cè)評(píng)估用戶表征的通用性被后續(xù)相關(guān)論文廣泛沿用。
同時(shí),PeterRec 提出,通用型用戶模型在下游任務(wù)遷移過程,應(yīng)該做到參數(shù)有效共享(公司往往有上百種用戶畫像要預(yù)測(cè),數(shù)十個(gè)業(yè)務(wù)推薦場(chǎng)景),并引入基于 Adapter 技術(shù),也是推薦系統(tǒng)首次采用 Adapter,通過微調(diào)模型補(bǔ)丁實(shí)現(xiàn)不同任務(wù)有效遷移學(xué)習(xí)。另外,PeterRec 還發(fā)布了一套大規(guī)模的跨域推薦系統(tǒng)數(shù)據(jù)集。
Conure 是推薦系統(tǒng)領(lǐng)域首個(gè)用戶通用表征的終生學(xué)習(xí)(lifelong learning)模型,首次提出一個(gè)模型連續(xù)學(xué)習(xí)和同時(shí)服務(wù)多個(gè)不同的下游任務(wù)。作者提出的‘一人一世界’概念啟發(fā)了當(dāng)下推薦系統(tǒng) one4all 模型的研究。
CLUE 認(rèn)為 PeterRec 與 Conure 算法在學(xué)習(xí)用戶表征時(shí),采用自回歸或者 mask 機(jī)制都是基于物品粒度的預(yù)測(cè),而最優(yōu)的用戶表征顯然應(yīng)該是對(duì)完整的用戶序列進(jìn)行建模和訓(xùn)練,因此結(jié)合對(duì)比學(xué)習(xí),獲得了更優(yōu)的結(jié)果。
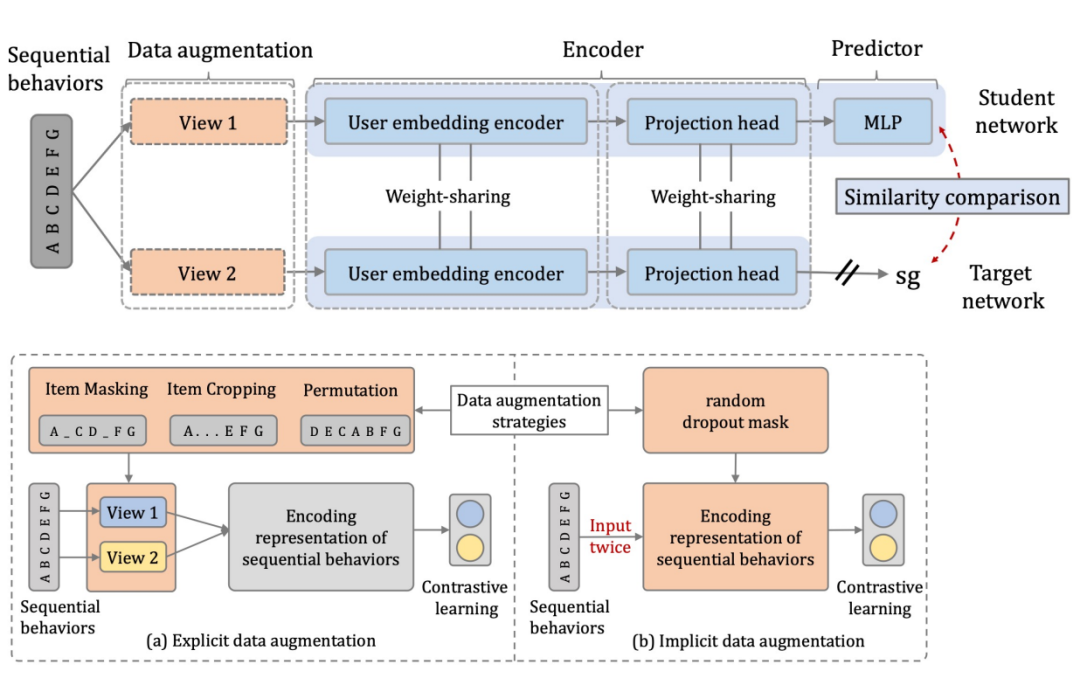
這期間有一些同時(shí)期或者 future work,包括阿里的 Star 模型(One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction),以及 ShopperBERT 模型 (One4all User Representation for Recommender Systems in E-commerce)。

基于模態(tài)信息的可遷移推薦系統(tǒng)
以上工作基于共享(用戶或者物品)ID 方式實(shí)現(xiàn)領(lǐng)域之間的遷移性和跨域推薦,比較適用于公司內(nèi)部不同業(yè)務(wù)之間, 而現(xiàn)實(shí)中不同推薦系統(tǒng)很難共享用戶與 item 的 ID 信息,使得跨平臺(tái)推薦這一類研究具有明顯的局限性。
相比之下,深度學(xué)習(xí)的其他社區(qū),如自然語言處理(NLP)與計(jì)算機(jī)視覺(CV)領(lǐng)域近幾年已經(jīng)涌現(xiàn)出一系列有影響力的通用型大模型,又稱基礎(chǔ)模型(foundation model),如 BERT、GPT、Vision Transformer 等。相比推薦系統(tǒng) ID 特征,NLP 與 CV 任務(wù)基于多模態(tài)文本與圖像像素特征,可以較好的實(shí)現(xiàn)模型在不同任務(wù)之間的復(fù)用與遷移。
替換 ID 特征、基于模態(tài)內(nèi)容實(shí)現(xiàn)不同系統(tǒng)與平臺(tái)之間的遷移是該階段的主流方向。這一階段的代表性工作有 TransRec [4]、MoRec [5](SIGIR2023)、AdapterRec [6](WSDM2024)、NineRec [7] 等。另外,同時(shí)期的工作還有人大趙鑫老師團(tuán)隊(duì) UnisRec 以及張永峰老師團(tuán)隊(duì)的 P5。
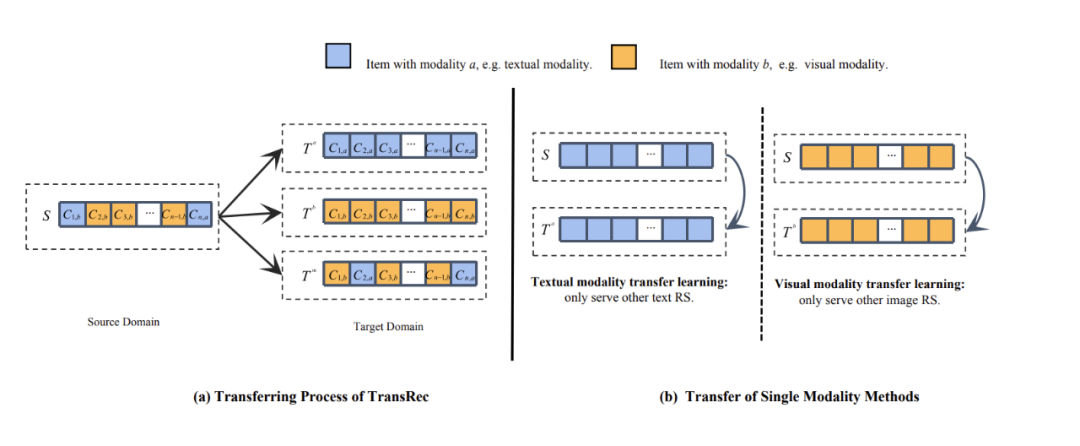
TransRec 是首個(gè)研究混合模態(tài)遷移的推薦系統(tǒng)模型,也是首次考慮圖像像素的遷移學(xué)習(xí)模型。TransRec 采用端到端訓(xùn)練方式,而不是直接抽取離線 item 多模態(tài)表征。
與基于 ID 的序列推薦模型比較,經(jīng)過 finetune 的 TransRec 可以有效提升推薦結(jié)果。TransRec 證實(shí)了大規(guī)模數(shù)據(jù)上利用混合模態(tài)信息預(yù)訓(xùn)練可以有效學(xué)習(xí)用戶和物品的關(guān)系,并且可以遷移到下游推薦任務(wù),實(shí)現(xiàn)通用推薦,論文還研究了 scaling effect 效果,并會(huì)發(fā)布多套多模態(tài)數(shù)據(jù)集。與 TransRec 同時(shí)期的工作是人大趙鑫老師團(tuán)隊(duì) UnisRec,UnisRec 主要聚焦 text 模態(tài)。
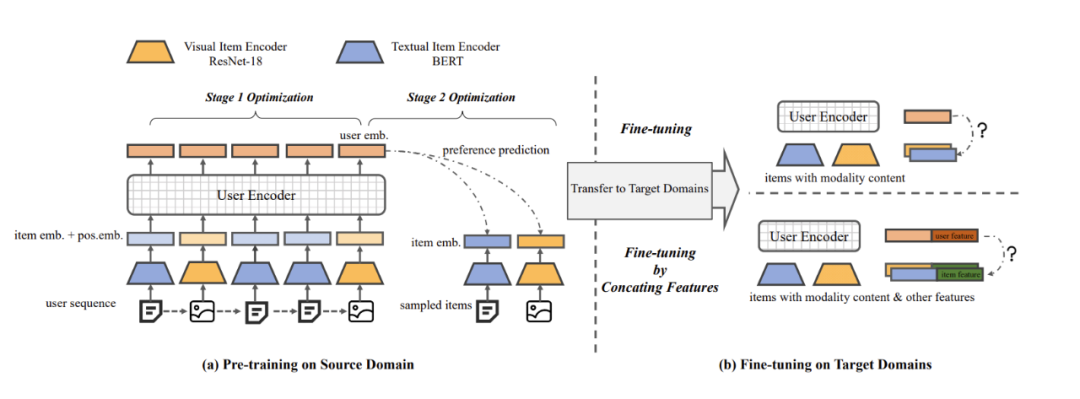
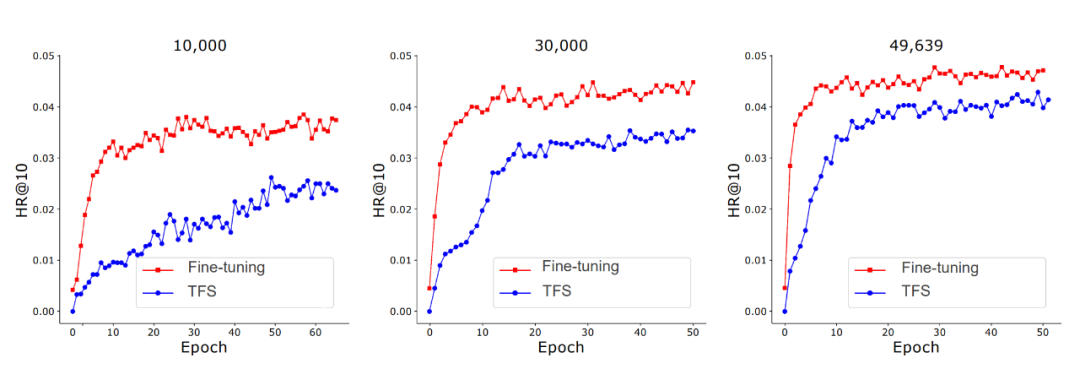
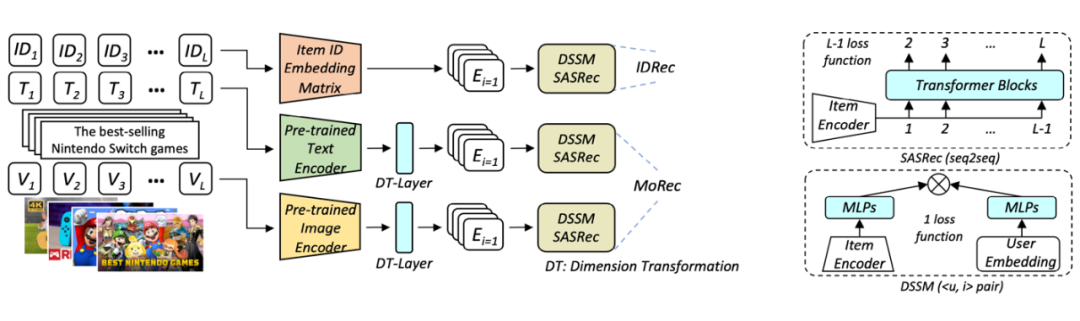
MoRec 首次系統(tǒng)性回答了使用最先進(jìn)的模態(tài)編碼器表征物品(MoRec)是否能取代經(jīng)典的 itemID embedding 范式(DRec)這一問題。論文基于 MoRec 與 IDRec 的公平比較展開:如果在冷熱場(chǎng)景下 MoRec 都能打敗 IDRec,那么推薦系統(tǒng)將有望迎來經(jīng)典范式的變革。這一觀點(diǎn)來自于 MoRec 完全基于物品的模態(tài)信息,此類內(nèi)容信息天生具有遷移能力,論文通過扎實(shí)的實(shí)驗(yàn)系統(tǒng)性證明了 MoRec 有潛力實(shí)現(xiàn)通用大模型。
結(jié)論 1:對(duì)于時(shí)序推薦架構(gòu) SASRec,在常規(guī)場(chǎng)景(既有熱 item 也有一部分冷 item),MoRec 在文本上明顯優(yōu)于 IDRec,而在圖片上則和 IDRec 效果相當(dāng)。在冷啟動(dòng)場(chǎng)景,MoRec 大幅優(yōu)于 IDRec,在熱門商品推薦場(chǎng)景,MoRec 和 IDRec 效果相當(dāng)。
結(jié)論 2:MoRec 為推薦系統(tǒng)和 NLP、CV 等多模態(tài)社區(qū)建立了聯(lián)系,而且一般來說,可以很好的繼承 NLP 和 CV 領(lǐng)域的最新進(jìn)展。
結(jié)論 3:工業(yè)界流行的 Two-stage 離線特征提取推薦方式會(huì)導(dǎo)致 MoRec 性能顯著下降(特別是對(duì)于視覺推薦),這在實(shí)踐中不應(yīng)該被忽視。同時(shí),盡管多模態(tài)領(lǐng)域的預(yù)訓(xùn)練模型在近年來取得了革命性的成功,但其表征還沒有做到通用性和泛化性,至少對(duì)于推薦系統(tǒng)是這樣(MoRec 論文也被 Google DeepMind 團(tuán)隊(duì)邀請(qǐng)給了一個(gè) talk,Google researcher 對(duì)該工作評(píng)價(jià)非常高)。受此啟發(fā),近期已經(jīng)出現(xiàn)很多相關(guān)工作。
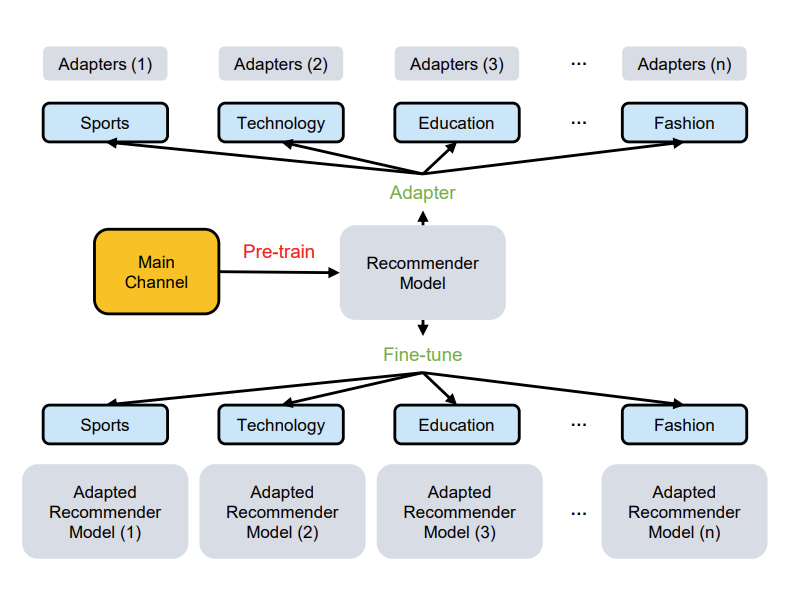
AdapterRec 首次系統(tǒng)性討論了基于模態(tài)信息的高效遷移方法。論文評(píng)估了基于適配器(Adapter)的模型補(bǔ)丁。與以往工作在下游遷移時(shí)微調(diào)全部參數(shù)不同,AdapterRec 在遷移時(shí)在模型網(wǎng)絡(luò)中插入并僅微調(diào)適配器網(wǎng)絡(luò)。論文在大規(guī)模文本、圖片模態(tài)數(shù)據(jù)上進(jìn)行了豐富的驗(yàn)證實(shí)驗(yàn)。
結(jié)果表明,基于文本、圖片模態(tài)的適配器都可以實(shí)現(xiàn)良好的遷移效果。基于文本模態(tài)時(shí),適配器技術(shù)可以在微調(diào)極少量參數(shù)的計(jì)算成本下實(shí)現(xiàn)與微調(diào)全部參數(shù)相近的遷移結(jié)果。AdapterRec 證實(shí)了基于適配器技術(shù)的高效遷移方法是實(shí)現(xiàn)通用推薦系統(tǒng)大模型的重要環(huán)節(jié)。
NineRec 提出了迄今為止推薦系統(tǒng)領(lǐng)域規(guī)模最大最多樣的多模態(tài)遷移學(xué)習(xí)數(shù)據(jù)集。論文延續(xù) MoRec 與 IDRec 公平比較的原則,系統(tǒng)性評(píng)估了 MoRec 的遷移能力并給出詳見的指導(dǎo)建議與評(píng)估平臺(tái)。NineRec 提供了一套大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)集和九個(gè)下游場(chǎng)景數(shù)據(jù)集,其中僅預(yù)訓(xùn)練數(shù)據(jù)集就包含 200 萬用戶、14 萬物品以及近 2500 萬條交互記錄信息。
論文設(shè)計(jì)大規(guī)模實(shí)驗(yàn)評(píng)估了多種經(jīng)典推薦架構(gòu)(SASRec,BERT4Rec,NextItNet,GRU4Rec)與物品編碼器(BERT,Roberta,OPT,ResNet,Swin Transformer)的遷移表現(xiàn),并驗(yàn)證了端到端遷移(End-to-End)與兩階段遷移(Two-stage)對(duì)于遷移推薦的影響。實(shí)驗(yàn)結(jié)果表明,利用端到端訓(xùn)練技術(shù)可以極大程度上激發(fā)模態(tài)信息的潛能,僅使用經(jīng)典框架如 SASRec 即可超越近期同類型可遷移推薦模型。
論文還驗(yàn)證了基于純模態(tài)信息的 zero-shot 遷移能力。NineRec 為基于模態(tài)的推薦系統(tǒng)遷移學(xué)習(xí)和推薦大模型發(fā)展提供了全新的平臺(tái)和基準(zhǔn)。NineRec(只有文本和圖片模態(tài))之后,團(tuán)隊(duì)聯(lián)合發(fā)布了 MicroLens [11] 數(shù)據(jù)集,是當(dāng)前最大的短視頻推薦數(shù)據(jù)集包含原始短視頻,是其他相關(guān)數(shù)據(jù)集規(guī)模的數(shù)千倍,用戶量達(dá)到 3000 萬,點(diǎn)擊行為達(dá)到 10 億,可以用于訓(xùn)練推薦系統(tǒng)大模型。NineRec 與 MicroLens 算力和數(shù)據(jù)集收集費(fèi)用都超過百萬人民幣。
 基于LLM的可遷移推薦系統(tǒng)
基于LLM的可遷移推薦系統(tǒng)
當(dāng)下人工智能領(lǐng)域進(jìn)入大模型時(shí)代,越來越多的通用大模型在各個(gè)領(lǐng)域被提出,極大的促進(jìn)了 AI 社區(qū)的發(fā)展。然而大模型技術(shù)在推薦系統(tǒng)領(lǐng)域應(yīng)用還處于早期階段。諸多問題并沒有得到很好的回答,如利用大語言模型理解推薦任務(wù)是否能大幅超越原有的 ID 范式?是否越大規(guī)模參數(shù)的大模型網(wǎng)絡(luò)可以帶來通用推薦表征?回答這些問題是推動(dòng)推薦系統(tǒng)社區(qū)進(jìn)入大模型時(shí)代的敲門磚,受到了越來越多科研團(tuán)隊(duì)的關(guān)注。
這里主要介紹 P5 [8] 和 GPT4Rec [9],P5 是采用 LM 作為推薦 backbone,而 GPT4Rec 則是極限地評(píng)估 1750 億的 item encoder 表能能力, 后續(xù)工作也非常多(例如基于 prompt,基于chain of thought,基于 ChatGPT 等),例如同時(shí)期的工作還有 Google 的 LLM for rating prediction [10],與 GPT4Rec 類似,都是采用遷移模型評(píng)估性能極限,一個(gè)專注 top-n item 推薦,一個(gè)專注 rating prediction。
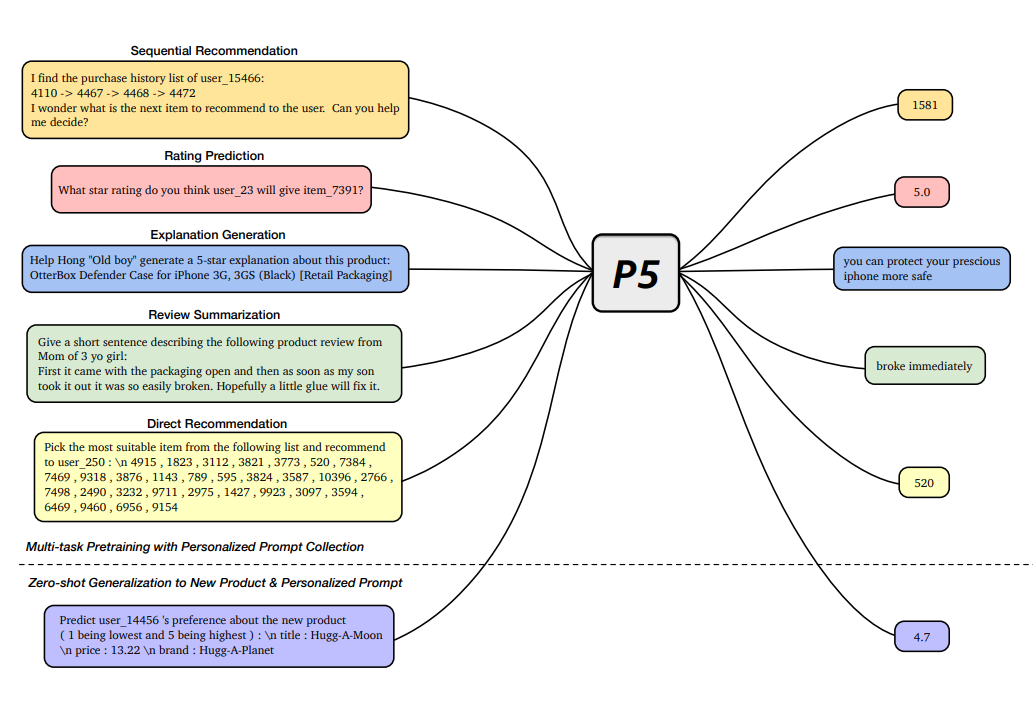
P5 提出了一種基于文本模態(tài)的多任務(wù)大模型框架,將多種經(jīng)典推薦任務(wù)轉(zhuǎn)化為統(tǒng)一的自然語言理解任務(wù),包括序列推薦、評(píng)分預(yù)測(cè)、推薦理由、摘要以及直接推薦等多種任務(wù)。模型設(shè)計(jì)上,P5 通過基于提示(prompt)的自然語言格式來構(gòu)建任務(wù),將這些相關(guān)的推薦任務(wù)統(tǒng)一為序列到序列(seq-to-seq)框架中進(jìn)行學(xué)習(xí)。數(shù)據(jù)方面,P5 將各種可用數(shù)據(jù),例如用戶信息、物品元數(shù)據(jù)、用戶評(píng)論以及用戶與物品的互動(dòng)數(shù)據(jù)轉(zhuǎn)化為自然語言序列。豐富的訓(xùn)練數(shù)據(jù)產(chǎn)生了滿足個(gè)性化推薦需求的語義信息。
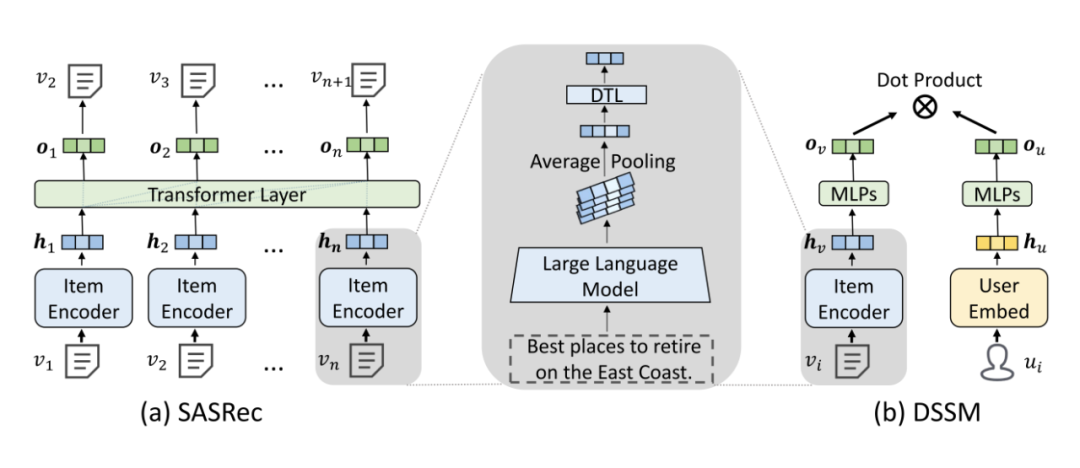
GPT4Rec 首次探索了使用百億規(guī)模大語言模型作為物品編碼器。論文提出并回答了幾個(gè)關(guān)鍵性的問題:1)基于文本的協(xié)同過濾推薦算法(TCF)的性能隨著物品編碼器參數(shù)量不斷增加表現(xiàn)如何?是否在千億規(guī)模能達(dá)到上限?2)超大參數(shù)的 LLM,如 175B 參數(shù) GPT-3,是否能產(chǎn)生通用的 item 表征?3)基于公平比較,裝配了 175B 參數(shù)量的 LLM 的推薦系統(tǒng)算法能否打敗基于 ID 的經(jīng)典算法;4)基于 LLM 的 TCF 算法距離推薦系統(tǒng)通用大模型還有多遠(yuǎn)?
實(shí)驗(yàn)結(jié)果表明:
1. 175B 的參數(shù) LM 可能還沒有達(dá)到其性能上限,通過觀察到 LLM 的參數(shù)量從 13B 到 175B 時(shí),TCF 模型的性能還沒有收斂。這一現(xiàn)象表明將來使用更多參數(shù)的 LLM 用作文本編碼器是有帶來更高的推薦準(zhǔn)確性的潛力的;
2. 即使是由極其龐大的 LM(如 GPT-3)學(xué)習(xí)到的物品表示,也未必能形成一個(gè)通用的表征。在相應(yīng)的推薦系統(tǒng)數(shù)據(jù)集微調(diào)仍然對(duì)于獲得 SOTA 仍然是必要的,至少對(duì)文本推薦任務(wù)來說是如此;
3. 即使采用 175B 和微調(diào)的 66B 的語言模型,當(dāng)使用 DSSM 作為推薦骨架時(shí),TCF 仍然很大程度的劣于 IDRec,但是對(duì)于序列推薦模型,LLM 即便采用凍住的表征,也基本可以跟 IDRec 相媲美;
4. 雖然裝配了 175B 參數(shù)量 LLM 的 TCF 模型的表現(xiàn)優(yōu)于隨機(jī)采樣的 item 的推薦,甚至達(dá)到了 6-40 倍的提升。但與在推薦數(shù)據(jù)上重新訓(xùn)練的 TCF 模型相比,它們?nèi)匀挥芯薮蟮牟罹唷?/span>另外,論文發(fā)現(xiàn):
5. ChatGPT 在典型的推薦系統(tǒng)場(chǎng)景與 TCF 相比表現(xiàn)存在較大的差距,文章猜測(cè)需要更加精細(xì)的 prompt,ChatGPT 才有可能用于某些真實(shí)推薦場(chǎng)景。
 總結(jié)
總結(jié)
目前推薦系統(tǒng)社區(qū)內(nèi),基于模態(tài)內(nèi)容的大模型研究仍處于起步階段:
1. 基于傳統(tǒng)的 ID 的推薦算法難以解決模態(tài)場(chǎng)景問題;
2. 已有的基于模態(tài)內(nèi)容的跨域推薦系統(tǒng)文獻(xiàn)通用性較低;
3. 非端到端的聯(lián)合訓(xùn)練提取的特征可能存在粒度尺度不匹配等問題,通常只能生成次優(yōu)的推薦水平;
4. 社區(qū)缺少包含模態(tài)內(nèi)容的可用于遷移學(xué)習(xí)研究的大規(guī)模公開數(shù)據(jù)集,缺少基準(zhǔn)和排行榜(leaderboard);
5. 已有文獻(xiàn)中的推薦系統(tǒng)大模型參數(shù)量和訓(xùn)練數(shù)據(jù)太小(相對(duì)于 NLP 與 CV 領(lǐng)域),缺少開源的推薦系統(tǒng)大模型預(yù)訓(xùn)練參數(shù)。

參考文獻(xiàn)
?[1] Parameter-efficient transfer from sequential behaviors for user modeling and recommendation (SIGIR2020)
[2] One Person, One Model, One World: Learning Continual User Representation without Forgetting (SIGIR2021)
[3] Learning transferable user representations with sequential behaviors via contrastive pre-training (ICDM2021)
[4] TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback. Arxiv2022/06
[5] Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited (SIGIR2023)
[6] Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights (WSDM2024)
[7] NineRec: A Suite of Transfer Learning Datasets for ModalityBased Recommender Systems. Arxiv2023/09
[8] Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) (Recsys2022)
[9] Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. Arxiv2023/05
[10] Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. Arxiv2023/05
[11] A Content-Driven Micro-Video Recommendation Dataset at Scale. Arxiv2023/09
參考技術(shù)貼:
1)https://zhuanlan.zhihu.com/p/624557649 機(jī)器學(xué)習(xí)心得(八):推薦系統(tǒng)是不是即將迎來預(yù)訓(xùn)練時(shí)代?
2)https://zhuanlan.zhihu.com/p/633839409 SIGIR2023 | ID vs 模態(tài): 推薦系統(tǒng)ID范式有望被顛覆?
3)https://zhuanlan.zhihu.com/p/642797247 推薦系統(tǒng)范式之爭,LLM vs. ID?
4)https://zhuanlan.zhihu.com/p/437671278 推薦系統(tǒng)通用用戶表征預(yù)訓(xùn)練研究進(jìn)展
5)https://zhuanlan.zhihu.com/p/661836095 推薦系統(tǒng)何去何從(Google DeepMind受邀報(bào)告)
6)https://zhuanlan.zhihu.com/p/661954235 推薦系統(tǒng)預(yù)訓(xùn)練大模型范式發(fā)展
原文標(biāo)題:從ID-based到LLM-based:可遷移推薦系統(tǒng)發(fā)展
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2913文章
44915瀏覽量
376170
原文標(biāo)題:從ID-based到LLM-based:可遷移推薦系統(tǒng)發(fā)展
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是LLM?LLM在自然語言處理中的應(yīng)用
LLM技術(shù)對(duì)人工智能發(fā)展的影響
NY8B062F 14 I/O+12-通道ADC 8位EPROM-Based單片機(jī)手冊(cè)
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸

從 MSP430? MCU 到 MSPM0 MCU 的遷移指南

從STM32到基于Arm的MSPM0的遷移指南
從遷移到基于Arm STM32的MSPMO指南
將軟件從8位(字節(jié))可尋址CPU遷移至C28x CPU
從Renesas RL78到基于Arm的MSPM0的遷移指南
什么是LLM?LLM的工作原理和結(jié)構(gòu)
大語言模型(LLM)快速理解

ARM-based相比ARM cortex有何優(yōu)勢(shì)?
李未可科技正式推出WAKE-AI多模態(tài)AI大模型

FPGA-Based DPU網(wǎng)卡的發(fā)展和應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論