") malloc 的實(shí)現(xiàn)原理
malloc 的實(shí)現(xiàn)原理
面試的時(shí)候經(jīng)常會(huì)被問(wèn)到 malloc 的實(shí)現(xiàn)。從操作系統(tǒng)層面來(lái)說(shuō),malloc 確實(shí)是考察面試者對(duì)操作系統(tǒng)底層的存儲(chǔ)管理理解的一個(gè)很好的方式,涉及到虛擬內(nèi)存、分頁(yè)/分段等。下面逐個(gè)細(xì)說(shuō)。
1. 虛擬內(nèi)存
首先需要知道的是程序運(yùn)行起來(lái)的話需要被加載的物理內(nèi)存中,具體到計(jì)算機(jī)硬件就是內(nèi)存條。操作系統(tǒng)啟動(dòng)的時(shí)候先把自己加載到物理內(nèi)存的固定位置(一般為底部),物理內(nèi)存的其他位置就用來(lái)運(yùn)行用戶程序。程序就是一堆指令,程序運(yùn)行可以簡(jiǎn)單抽象為把指令加載到內(nèi)存中,然后 CPU 將指令從內(nèi)存載入執(zhí)行。
- 為什么需要虛擬內(nèi)存?
CPU 對(duì)內(nèi)存的尋址最簡(jiǎn)單的方式就是直接使用物理內(nèi)存地址,這種方式一般叫做物理尋址。早期的 PC 使用物理尋址,而且像數(shù)字信號(hào)處理器、嵌入式微控制器也使用物理尋址。物理尋址的好處是簡(jiǎn)單,壞處也有很多,比如:
不安全:操作系統(tǒng)的地址直接暴露給用戶程序,用戶程序可以破壞操作系統(tǒng)。這種解決方案是采用特殊的硬件保護(hù)。
同時(shí)運(yùn)行多個(gè)程序比較困難:多個(gè)用戶程序如果都直接引用物理地址,很容易互相干擾。那么是不是可以通過(guò)不斷交換物理內(nèi)存和磁盤(pán)來(lái)保證物理內(nèi)存某一時(shí)間自由一個(gè)程序在運(yùn)行呢?當(dāng)時(shí)是可以的,但是這引入很多不必要和復(fù)雜的工作。
用戶程序大小受限:受制于物理內(nèi)存大小。我們現(xiàn)在的錯(cuò)覺(jué)是應(yīng)用程序大小都小于物理內(nèi)存,這主要是因?yàn)楝F(xiàn)在 PC 的物理內(nèi)存都比較大。實(shí)際上只有 1G 物理內(nèi)存的 PC 是可以運(yùn)行 2G 的應(yīng)用程序的。
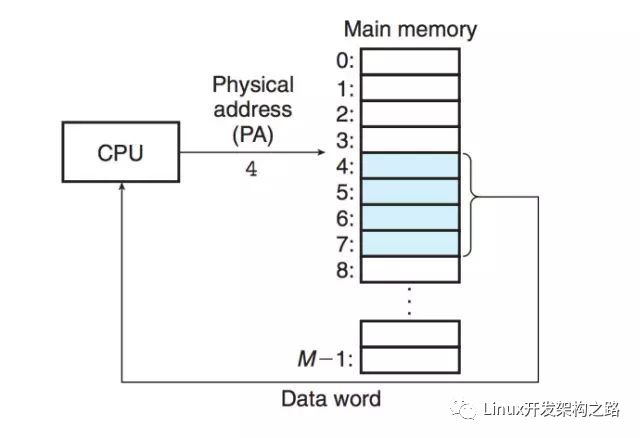
綜合上面各種缺點(diǎn),虛擬內(nèi)存出現(xiàn)了。
- 虛擬內(nèi)存概覽
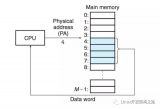
虛擬內(nèi)存的基本思想是:每個(gè)程序擁有獨(dú)立的地址空間(也就是虛擬內(nèi)存地址,或者稱作虛擬地址),互不干擾。地址空間被分割成多個(gè)塊,每一塊稱作一頁(yè)(page),每一頁(yè)有連續(xù)的地址范圍。虛擬地址的頁(yè)被映射到物理內(nèi)存(通過(guò) MMU,Memory Management Unit),但是并不是所有的頁(yè)都必須在內(nèi)存中才能運(yùn)行程序。當(dāng)程序引用到一部分在物理內(nèi)存中的地址空間時(shí),由硬件立刻執(zhí)行必要的映射。當(dāng)程序引用到一部分不在物理內(nèi)存中的地址空間時(shí),由操作系統(tǒng)負(fù)責(zé)將確實(shí)的部分裝入物理內(nèi)存。虛擬地址尋址(也叫做虛擬尋址)的示意圖如下。

3.虛擬內(nèi)存實(shí)現(xiàn)
1.虛擬內(nèi)存大小
一般是和 CPU 字長(zhǎng)相關(guān),比如 32 位對(duì)應(yīng)的虛擬地址空間大小為:0 ~ 2^31。
- MMU
CPU 將虛擬地址發(fā)送給 MMU,然后 MMU 將虛擬地址翻譯成物理地址,再尋址物理內(nèi)存。那么虛擬地址和物理地址具體是怎么映射的呢?完成映射還需要另一個(gè)重要的數(shù)據(jù)結(jié)構(gòu)的參與:頁(yè)表(page table)。頁(yè)表完成虛擬地址和物理地址的映射,MMU 每次翻譯的時(shí)候都需要讀取頁(yè)表。頁(yè)表的一種簡(jiǎn)單表示如下。
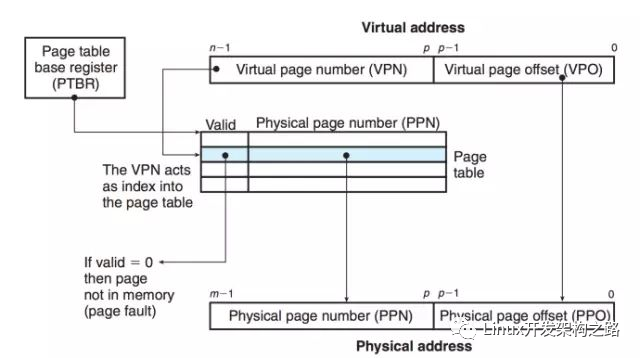
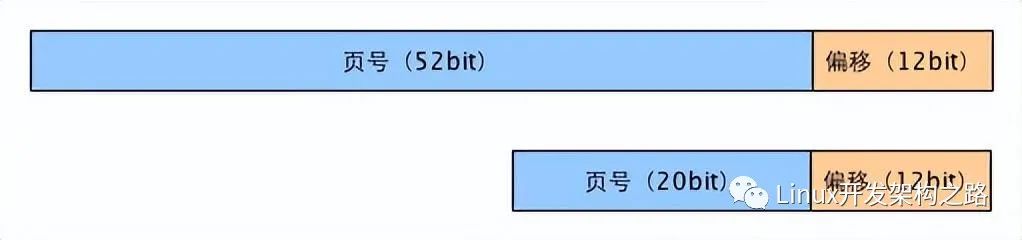
這里頁(yè)大小為 p 位。虛擬內(nèi)存的頁(yè)和物理內(nèi)存的頁(yè)大小一樣。虛擬地址的高 n-p 位,又叫做虛擬頁(yè)號(hào)(Virtual Page Number, VPN),用來(lái)索引物理頁(yè)號(hào)(Physical Page Number,PPN),最后將 PPN 和低 p 位組合在一起就得到了物理地址。
- 頁(yè)表的兩個(gè)問(wèn)題
前面說(shuō)到用 VPN 來(lái)做頁(yè)表索引,也就是說(shuō)頁(yè)表的大小為虛擬地址位數(shù) / 頁(yè)的大小。比如 32 位機(jī)器,頁(yè)大小一般為 4K ,則頁(yè)表項(xiàng)有 2^32 / 2^12 = 2^20 條目。如果機(jī)器字長(zhǎng) 64 位,頁(yè)表項(xiàng)就更多了。那么怎么解決呢?一般有兩種方法:
- 倒排頁(yè)表。物理頁(yè)號(hào)做索引,映射到多個(gè)虛擬地址。通過(guò)虛擬地址查找的時(shí)候就需要通過(guò)虛擬地址的中間幾位來(lái)做索引了。
- 多級(jí)頁(yè)表。以兩級(jí)頁(yè)表為例。一級(jí)頁(yè)表中的每個(gè) PTE (page table entry)映射虛擬地址空間的一個(gè) 4MB 的片,每一片由1024 個(gè)連續(xù)的頁(yè)面組成。一級(jí) PTE 指向二級(jí)頁(yè)表的基址。這樣 32 位地址空間使用 1024 個(gè)一級(jí) PTE 就可以表示。需要的二級(jí)頁(yè)表總條目還是 2^32 / 2^12 = 2^20 個(gè)。這里的關(guān)鍵在于如果一級(jí) PTE i 中的頁(yè)面都未被分配,一級(jí) PTE 就為空。多級(jí)頁(yè)面的一個(gè)簡(jiǎn)單示意圖如下。

多級(jí)頁(yè)表減少內(nèi)存占用的關(guān)鍵在于:
- 如果一級(jí)頁(yè)表中的一個(gè) PTE 為空,那么相應(yīng)的二級(jí)頁(yè)表就根本不會(huì)存在。這是一種巨大的潛在節(jié)約。
- 只有一級(jí)頁(yè)表才需要常駐內(nèi)存。虛擬內(nèi)存系統(tǒng)可以在需要時(shí)創(chuàng)建、頁(yè)面調(diào)入或者調(diào)出二級(jí)頁(yè)表,從而減輕內(nèi)存的壓力。
第二個(gè)問(wèn)題是頁(yè)表是在內(nèi)存中,而 MMU 位于 CPU 芯片中,這樣每次地址翻譯可能都需要先訪問(wèn)一次內(nèi)存中的頁(yè)表(CPU L1,L2,L3 Cache Miss 的時(shí)候訪問(wèn)內(nèi)存),效率非常低下。對(duì)應(yīng)的解決方案是引入頁(yè)表的高速緩存:TLB(Translation Lookaside Buffer)。加入 TLB,整個(gè)虛擬地址翻譯的過(guò)程如下兩圖所示。
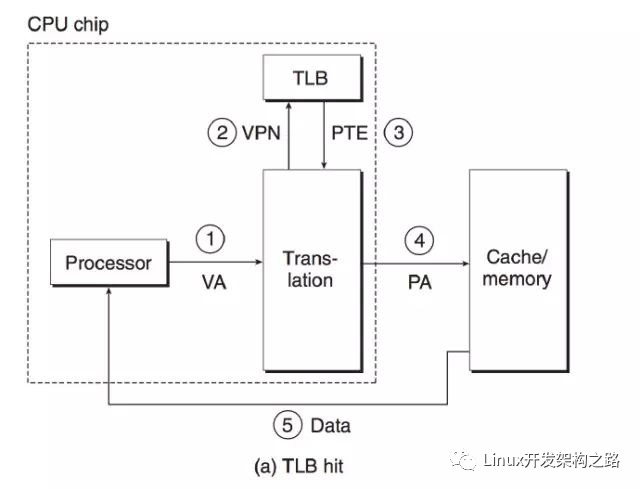

關(guān)于虛擬內(nèi)存還有一些內(nèi)容比如 page fault 處理,這里就不再贅述了。
2. 分段
- 分段概述
前面介紹了分頁(yè)內(nèi)存管理,可以說(shuō)通過(guò)多級(jí)頁(yè)表,TLB 等,分頁(yè)內(nèi)存管理方法已經(jīng)相當(dāng)不錯(cuò)了。那么分頁(yè)有什么缺點(diǎn)呢?
- 共享困難:通過(guò)共享頁(yè)面來(lái)實(shí)現(xiàn)共享當(dāng)然是可以的。這里的問(wèn)題在于我們要保證頁(yè)面上只包含可以共享的內(nèi)容并不是一件容易的事兒,因?yàn)檫M(jìn)程空間是直接映射到頁(yè)面上的。這樣一個(gè)頁(yè)面上很可能包含不能共享的內(nèi)容(比如既包含代碼又包含數(shù)據(jù),代碼可以共享,而數(shù)據(jù)不能共享)。早期的 PDP-11 實(shí)現(xiàn)的一種解決方法是為指令和數(shù)據(jù)設(shè)置分離的地址空間,分別稱為 I 空間和 D 空間(其實(shí)這已經(jīng)和分段很像了)。
- 程序地址空間受限于虛擬地址:我們將程序全部映射到一個(gè)統(tǒng)一的虛擬地址的問(wèn)題在于不好擴(kuò)張。不如我們程序的地址按先代碼放在一起,然后把數(shù)據(jù)放在一起,然后再放 XXX,這樣其中某一部分的空間擴(kuò)張起來(lái)都會(huì)影響到相鄰的空間,非常不方便。
上面的問(wèn)題一個(gè)比較直觀的解決方法是提供多個(gè)獨(dú)立的地址空間,也就是段(segment)。每個(gè)段的長(zhǎng)度視具體的段不同而不同,而且是可以在運(yùn)行期動(dòng)態(tài)改變的。因?yàn)槊總€(gè)段都構(gòu)成了一個(gè)獨(dú)立的地址空間,所以它們可以獨(dú)立的增長(zhǎng)或者減小而不會(huì)影響到其他的段。如果一個(gè)段比較大,把它整個(gè)保存到內(nèi)存中可能很不方便甚至是不可能的,因此可以對(duì)段采用分頁(yè)管理,只有那些真正需要的頁(yè)面才會(huì)被調(diào)入內(nèi)存。
采用分段和分頁(yè)結(jié)合的方式管理內(nèi)存,一個(gè)地址由兩個(gè)部分組成:段和段內(nèi)地址。段內(nèi)地址又進(jìn)一步分為頁(yè)號(hào)和頁(yè)偏移。在進(jìn)行內(nèi)存訪問(wèn)時(shí),過(guò)程如下:
- 根據(jù)段號(hào)找到段描述符(存放段基址)。
- 檢查該段的頁(yè)表是否在內(nèi)存中。如果在,則找到它的位置,如果不在,則產(chǎn)生段錯(cuò)誤。
- 檢查所請(qǐng)求的虛擬頁(yè)面的頁(yè)表項(xiàng),如果該頁(yè)面不在內(nèi)存中則產(chǎn)生缺頁(yè)中斷,如果在內(nèi)存中就從頁(yè)表項(xiàng)中取出這個(gè)頁(yè)面在內(nèi)存中的起始地址。
- 將頁(yè)面起始地址和偏移量進(jìn)行拼接得到物理地址,然后完成讀寫(xiě)。
- 進(jìn)程的段
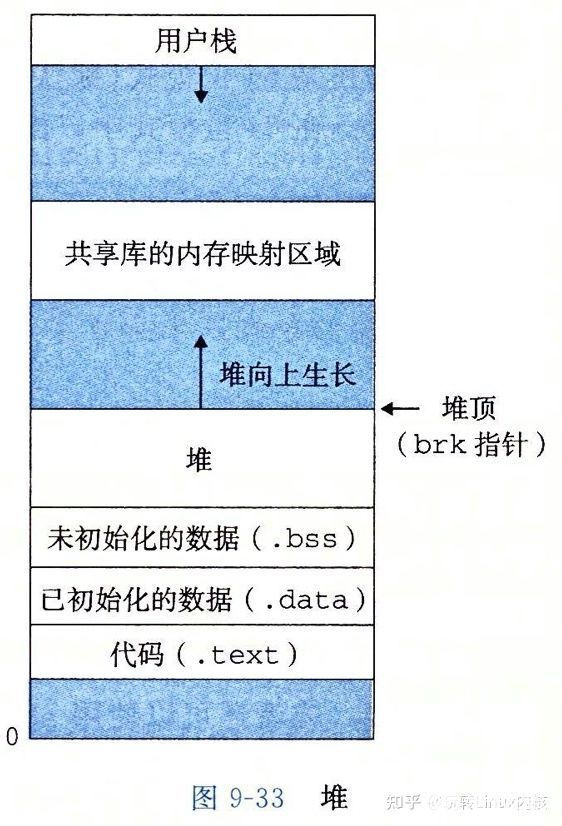
每個(gè) Linux 程序都有一個(gè)運(yùn)行時(shí)內(nèi)存映像,也就是各個(gè)段的布局,簡(jiǎn)單如下圖所示。

注意上圖只是一個(gè)相對(duì)位置圖,實(shí)際上這些段并不是相鄰的。主要的段包括只讀代碼段、讀寫(xiě)段、運(yùn)行時(shí)堆、用戶棧。在分配棧、堆段運(yùn)行時(shí)地址的時(shí)候,鏈接器會(huì)使用空間地址空間布局隨機(jī)化(ASLR),但是相對(duì)位置不會(huì)變。上圖中 .data 等是對(duì)應(yīng)進(jìn)程中的不同數(shù)據(jù)的 section ,或者叫做節(jié)。簡(jiǎn)介如下。
- .text: 已編譯程序的機(jī)器代碼。
- .rodata: 只讀數(shù)據(jù)。
- .data: 已初始化的全局和靜態(tài)變量。局部變量保存在棧上。
- .bss: 未初始化的全局和靜態(tài)變量,以及所有被初始化為 0 的全局或者靜態(tài)變量。在目標(biāo)文件中這個(gè)節(jié)不占據(jù)實(shí)際的空間,它僅僅是一個(gè)占位符。
3. malloc 實(shí)現(xiàn)
- 堆內(nèi)存管理
我們常說(shuō)的 malloc 函數(shù)是 glibc 提供的庫(kù)函數(shù)。glibc 的內(nèi)存管理使用的方法是 ptmalloc,除此之后還有很多其他內(nèi)存管理方案,比如 tcmalloc (golang 使用的就是 tcmalloc)。
ptmalloc 對(duì)于申請(qǐng)內(nèi)存小于 128KB 時(shí),分配是在堆段,使用系統(tǒng)調(diào)用 brk() 或者 sbrk()。如果大于 128 KB 的話,分配在映射區(qū),使用系統(tǒng)調(diào)用 mmap()。
- brk, sbrk
在堆段申請(qǐng)的話,使用系統(tǒng)調(diào)用 brk 或者 sbrk。
int brk(const void *addr);
void *sbrk(intptr_t incr);
brk 將 brk 指針?lè)胖玫街付ǖ刂诽帲晒Ψ祷?0,否則返回 -1。sbrk 將 brk 指針向后移動(dòng)指定字節(jié),返回依賴于系統(tǒng)實(shí)現(xiàn),或者返回移動(dòng)前的 brk 位置,或者返回移動(dòng)后的 brk 位置。下面使用 sbrk 實(shí)現(xiàn)一個(gè)巨簡(jiǎn)單的 malloc。
void *p = sbrk(0);
void *request = sbrk(size);
if (request == (void*) -1) {
return NULL; // sbrk failed.
} else {
assert(p == request); // Not thread safe.
return p;
}
}
- mmap
linux 系統(tǒng)調(diào)用 mmap 將一個(gè)文件或者其它對(duì)象映射進(jìn)內(nèi)存。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
mmap 的 flags 可選多種參數(shù),當(dāng)選擇 MAP_ANONYMOUS 時(shí),不需要傳入文件描述符,malloc 使用的就是 MAP_ANONYMOUS 模式。mmap 申請(qǐng)的內(nèi)存在操作系統(tǒng)的映射區(qū)。比如 32 位系統(tǒng),映射區(qū)從 3G 虛擬地址粗向下生長(zhǎng),但是因?yàn)槌绦虻钠渌我矔?huì)占用空間(比如代碼段必須以特定的地址開(kāi)始),所以并不能申請(qǐng) 3G 的大小。
- malloc 和物理內(nèi)存有關(guān)系嗎?
可以說(shuō)沒(méi)關(guān)系,malloc 申請(qǐng)的地址是線性地址,申請(qǐng)的時(shí)候并沒(méi)有進(jìn)行映射。訪問(wèn)到的時(shí)候觸發(fā)缺頁(yè)異常,這個(gè)時(shí)候才會(huì)進(jìn)行物理地址映射。
- ptmalloc
Malloc實(shí)現(xiàn)原理:
因?yàn)閎rk、sbrk、mmap都屬于系統(tǒng)調(diào)用,若每次申請(qǐng)內(nèi)存,都調(diào)用這三個(gè),那么每次都會(huì)產(chǎn)生系統(tǒng)調(diào)用,影響性能;其次,這樣申請(qǐng)的內(nèi)存容易產(chǎn)生碎片,因?yàn)槎咽菑牡偷刂返礁叩刂罚绻叩刂返膬?nèi)存沒(méi)有被釋放,低地址的內(nèi)存就不能被回收。
所以malloc采用的是內(nèi)存池的管理方式(ptmalloc),Ptmalloc 采用邊界標(biāo)記法將內(nèi)存劃分成很多塊,從而對(duì)內(nèi)存的分配與回收進(jìn)行管理。為了內(nèi)存分配函數(shù)malloc的高效性,ptmalloc會(huì)預(yù)先向操作系統(tǒng)申請(qǐng)一塊內(nèi)存供用戶使用,當(dāng)我們申請(qǐng)和釋放內(nèi)存的時(shí)候,ptmalloc會(huì)將這些內(nèi)存管理起來(lái),并通過(guò)一些策略來(lái)判斷是否將其回收給操作系統(tǒng)。這樣做的最大好處就是,使用戶申請(qǐng)和釋放內(nèi)存的時(shí)候更加高效,避免產(chǎn)生過(guò)多的內(nèi)存碎片。
chunk 內(nèi)存塊的基本組織單元
在 ptmalloc 的實(shí)現(xiàn)源碼中定義結(jié)構(gòu)體 malloc_chunk 來(lái)描述這些塊。malloc_chunk 定義如下:
2. INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
3. INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
4.
5. struct malloc_chunk* fd; /* double links -- used only if free. */
6. struct malloc_chunk* bk;
7.
8. /* Only used for large blocks: pointer to next larger size. */
9. struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
10. struct malloc_chunk* bk_nextsize;
11.};
chunk 的定義相當(dāng)簡(jiǎn)單明了,對(duì)各個(gè)域做一下簡(jiǎn)單介紹 :
prev_size: 如果前一個(gè) chunk 是空閑的,該域表示前一個(gè) chunk 的大小,如果前一個(gè) chunk 不空閑,該域無(wú)意義。
size :當(dāng)前 chunk 的大小,并且記錄了當(dāng)前 chunk 和前一個(gè) chunk 的一些屬性,包括前一個(gè) chunk 是否在使用中,當(dāng)前 chunk 是否是通過(guò) mmap 獲得的內(nèi)存,當(dāng)前 chunk 是否屬于非主分配區(qū)。
fd 和 bk :指針 fd 和 bk 只有當(dāng)該 chunk 塊空閑時(shí)才存在,其作用是用于將對(duì)應(yīng)的空閑 chunk 塊加入到空閑chunk 塊鏈表中統(tǒng)一管理,如果該 chunk 塊被分配給應(yīng)用程序使用,那么這兩個(gè)指針也就沒(méi)有用(該 chunk 塊已經(jīng)從空閑鏈中拆出)了,所以也當(dāng)作應(yīng)用程序的使用空間,而不至于浪費(fèi)。
fd_nextsize 和 bk_nextsize: 當(dāng)當(dāng)前的 chunk 存在于 large bins 中時(shí), large bins 中的空閑 chunk 是按照大小排序的,但同一個(gè)大小的 chunk 可能有多個(gè),增加了這兩個(gè)字段可以加快遍歷空閑 chunk ,并查找滿足需要的空閑 chunk , fd_nextsize 指向下一個(gè)比當(dāng)前 chunk 大小大的第一個(gè)空閑 chunk , bk_nextszie 指向前一個(gè)比當(dāng)前 chunk 大小小的第一個(gè)空閑 chunk 。如果該 chunk 塊被分配給應(yīng)用程序使用,那么這兩個(gè)指針也就沒(méi)有用(該chunk 塊已經(jīng)從 size 鏈中拆出)了,所以也當(dāng)作應(yīng)用程序的使用空間,而不至于浪費(fèi)。
chunk的結(jié)構(gòu)
chunk的結(jié)構(gòu)可以分為使用中的chunk和空閑的chunk。使用中的chunk和空閑的chunk數(shù)據(jù)結(jié)構(gòu)基本項(xiàng)同,但是會(huì)有一些設(shè)計(jì)上的小技巧,巧妙的節(jié)省了內(nèi)存。
使用中的chunk:
說(shuō)明:
1、 chunk指針指向chunk開(kāi)始的地址;mem指針指向用戶內(nèi)存塊開(kāi)始的地址。
2、 p=0時(shí),表示前一個(gè)chunk為空閑,prev_size才有效
3、p=1時(shí),表示前一個(gè)chunk正在使用,prev_size無(wú)效 p主要用于內(nèi)存塊的合并操作;ptmalloc 分配的第一個(gè)塊總是將p設(shè)為1, 以防止程序引用到不存在的區(qū)域
4、M=1 為mmap映射區(qū)域分配;M=0為heap區(qū)域分配
5、 A=0 為主分配區(qū)分配;A=1 為非主分配區(qū)分配。
空閑的chunk:

說(shuō)明:
1、當(dāng)chunk空閑時(shí),其M狀態(tài)是不存在的,只有AP狀態(tài),
2、原本是用戶數(shù)據(jù)區(qū)的地方存儲(chǔ)了四個(gè)指針,
指針fd指向后一個(gè)空閑的chunk,而bk指向前一個(gè)空閑的chunk,malloc通過(guò)這兩個(gè)指針將大小相近的chunk連成一個(gè)雙向鏈表。
在large bin中的空閑chunk,還有兩個(gè)指針,fd_nextsize和bk_nextsize,用于加快在large bin中查找最近匹配的空閑chunk。不同的chunk鏈表又是通過(guò)bins或者fastbins來(lái)組織的。
空閑鏈表bins
當(dāng)用戶使用free函數(shù)釋放掉的內(nèi)存,ptmalloc并不會(huì)馬上交還給操作系統(tǒng),而是被ptmalloc本身的空閑鏈表bins管理起來(lái)了,這樣當(dāng)下次進(jìn)程需要malloc一塊內(nèi)存的時(shí)候,ptmalloc就會(huì)從空閑的bins上尋找一塊合適大小的內(nèi)存塊分配給用戶使用。這樣的好處可以避免頻繁的系統(tǒng)調(diào)用,降低內(nèi)存分配的開(kāi)銷。
malloc將相似大小的chunk用雙向鏈表鏈接起來(lái),這樣一個(gè)鏈表被稱為一個(gè)bin。ptmalloc一共維護(hù)了128bin。每個(gè)bins都維護(hù)了大小相近的雙向鏈表的chunk。基于chunk的大小,有下列幾種可用bins:
1、Fast bin
2、Unsorted bin
3、Small bin
4、Large bin
保存這些bin的數(shù)據(jù)結(jié)構(gòu)為:
fastbinsY:這個(gè)數(shù)組用以保存fast bins。
bins:這個(gè)數(shù)組用以保存unsorted、small以及l(fā)arge bins,共計(jì)可容納126個(gè):
當(dāng)用戶調(diào)用malloc的時(shí)候,能很快找到用戶需要分配的內(nèi)存大小是否在維護(hù)的bin上,如果在某一個(gè)bin上,就可以通過(guò)雙向鏈表去查找合適的chunk內(nèi)存塊給用戶使用。
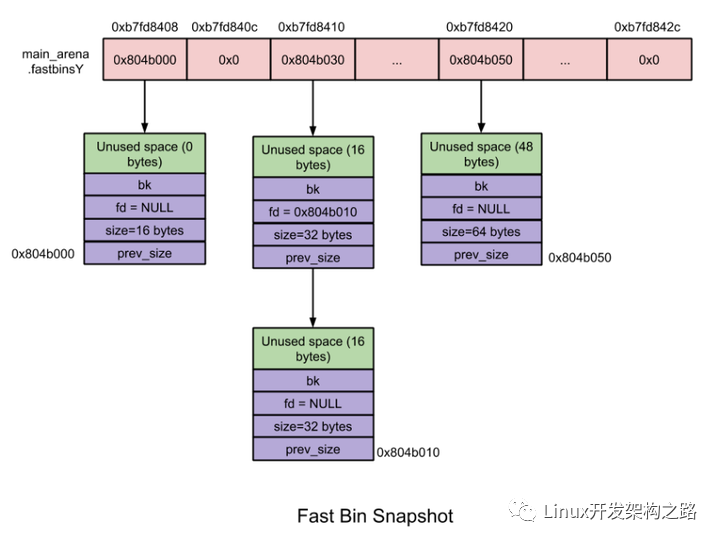
- fast bins。
程序在運(yùn)行時(shí)會(huì)經(jīng)常需要申請(qǐng)和釋放一些較小的內(nèi)存空間。當(dāng)分配器合并了相鄰的幾個(gè)小的 chunk 之后,也許馬上就會(huì)有另一個(gè)小塊內(nèi)存的請(qǐng)求,這樣分配器又需要從大的空閑內(nèi)存中切分出一塊,這樣無(wú)疑是比較低效的,故而,malloc 中在分配過(guò)程中引入了 fast bins,
fast bins是bins的高速緩沖區(qū),大約有10個(gè)定長(zhǎng)隊(duì)列。每個(gè)fast bin都記錄著一條free chunk的單鏈表(稱為binlist ,采用單鏈表是出于fast bin中鏈表中部的chunk不會(huì)被摘除的特點(diǎn)),增刪chunk都發(fā)生在鏈表的前端。fast bins 記錄著大小以8字節(jié)遞增的bin鏈表。
當(dāng)用戶釋放一塊不大于max_fast(默認(rèn)值64B)的chunk的時(shí)候,會(huì)默認(rèn)會(huì)被放到fast bins上。當(dāng)需要給用戶分配的 chunk 小于或等于 max_fast 時(shí),malloc 首先會(huì)到fast bins上尋找是否有合適的chunk,
除非特定情況,兩個(gè)毗連的空閑chunk并不會(huì)被合并成一個(gè)空閑chunk。不合并可能會(huì)導(dǎo)致碎片化問(wèn)題,但是卻可以大大加速釋放的過(guò)程!
分配時(shí),binlist中被檢索的第一個(gè)chunk將被摘除并返回給用戶。free掉的chunk將被添加在索引到的binlist的前端。
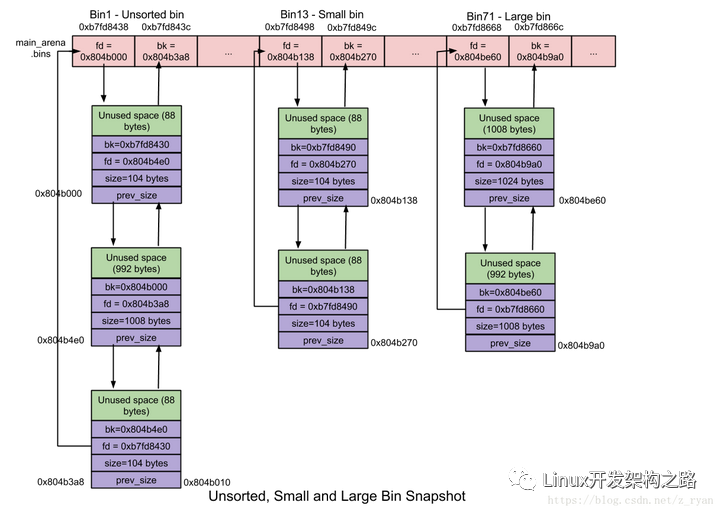
- unsorted bin。
unsorted bin 的隊(duì)列使用 bins 數(shù)組的第一個(gè),是bins的一個(gè)緩沖區(qū),加快分配的速度。當(dāng)用戶釋放的內(nèi)存大于max_fast或者fast bins合并后的chunk都會(huì)首先進(jìn)入unsorted bin上。chunk大小 – 無(wú)尺寸限制,任何大小chunk都可以添加進(jìn)這里。這種途徑給予 ‘glibc malloc’ 第二次機(jī)會(huì)以重新使用最近free掉的chunk,這樣尋找合適bin的時(shí)間開(kāi)銷就被抹掉了,因此內(nèi)存的分配和釋放會(huì)更快一些。
用戶malloc時(shí),如果在 fast bins 中沒(méi)有找到合適的 chunk,則malloc 會(huì)先在 unsorted bin 中查找合適的空閑 chunk,如果沒(méi)有合適的bin,ptmalloc會(huì)將unsorted bin上的chunk放入bins上,然后到bins上查找合適的空閑chunk。
- small bins
大小小于512字節(jié)的chunk被稱為small chunk,而保存small chunks的bin被稱為small bin。數(shù)組從2開(kāi)始編號(hào),前64個(gè)bin為small bins,small bin每個(gè)bin之間相差8個(gè)字節(jié),同一個(gè)small bin中的chunk具有相同大小。
每個(gè)small bin都包括一個(gè)空閑區(qū)塊的雙向循環(huán)鏈表(也稱binlist)。free掉的chunk添加在鏈表的前端,而所需chunk則從鏈表后端摘除。
兩個(gè)毗連的空閑chunk會(huì)被合并成一個(gè)空閑chunk。合并消除了碎片化的影響但是減慢了free的速度。
分配時(shí),當(dāng)samll bin非空后,相應(yīng)的bin會(huì)摘除binlist中最后一個(gè)chunk并返回給用戶。在free一個(gè)chunk的時(shí)候,檢查其前或其后的chunk是否空閑,若是則合并,也即把它們從所屬的鏈表中摘除并合并成一個(gè)新的chunk,新chunk會(huì)添加在unsorted bin鏈表的前端。
4.large bins
大小大于等于512字節(jié)的chunk被稱為large chunk,而保存large chunks的bin被稱為large bin,位于small bins后面。large bins中的每一個(gè)bin分別包含了一個(gè)給定范圍內(nèi)的chunk,其中的chunk按大小遞減排序,大小相同則按照最近使用時(shí)間排列。
兩個(gè)毗連的空閑chunk會(huì)被合并成一個(gè)空閑chunk。
分配時(shí),遵循原則“smallest-first , best-fit”,從頂部遍歷到底部以找到一個(gè)大小最接近用戶需求的chunk。一旦找到,相應(yīng)chunk就會(huì)分成兩塊User chunk(用戶請(qǐng)求大小)返回給用戶。
Remainder chunk(剩余大小添加到unsorted bin。free時(shí)和small bin 類似。
并不是所有chunk都按照上面的方式來(lái)組織,有三種列外情況。top chunk,mmaped chunk 和last remainder chunk
- Top chunk
top chunk相當(dāng)于分配區(qū)的頂部空閑內(nèi)存,當(dāng)bins上都不能滿足內(nèi)存分配要求的時(shí)候,就會(huì)來(lái)top chunk上分配。
當(dāng)top chunk大小比用戶所請(qǐng)求大小還大的時(shí)候,top chunk會(huì)分為兩個(gè)部分:User chunk(用戶請(qǐng)求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成為新的top chunk。
當(dāng)top chunk大小小于用戶所請(qǐng)求的大小時(shí),top chunk就通過(guò)sbrk(main arena)或mmap(thread arena)系統(tǒng)調(diào)用來(lái)擴(kuò)容。
- mmaped chunk
當(dāng)分配的內(nèi)存非常大(大于分配閥值,默認(rèn)128K)的時(shí)候,需要被mmap映射,則會(huì)放到mmaped chunk上,當(dāng)釋放mmaped chunk上的內(nèi)存的時(shí)候會(huì)直接交還給操作系統(tǒng)。
3、Last remainder chunk
Last remainder chunk是另外一種特殊的chunk,就像top chunk和mmaped chunk一樣,不會(huì)在任何bins中找到這種chunk。當(dāng)需要分配一個(gè)small chunk,但在small bins中找不到合適的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成兩個(gè)chunk,其中一個(gè)chunk返回給用戶,另一個(gè)chunk變成新的last remainder chunk。
sbrk與mmap
在堆區(qū)中, start_brk 指向 heap 的開(kāi)始,而 brk 指向 heap 的頂部。可以使用系統(tǒng)調(diào)用 brk()和 sbrk()來(lái)增 加標(biāo)識(shí) heap 頂部的 brk 值,從而線性的增加分配給用戶的 heap 空間。在使 malloc 之前,brk 的值等于 start_brk,也就是說(shuō) heap 大小為 0。
ptmalloc 在開(kāi)始時(shí),若請(qǐng)求的空間小于 mmap 分配閾值(mmap threshold,默認(rèn)值為 128KB)時(shí),主分配區(qū)會(huì)調(diào)用 sbrk()增加一塊大小為 (128 KB + chunk_size) align 4KB 的空間作為 heap。非主分配區(qū)會(huì)調(diào)用 mmap 映射一塊大小為 HEAP_MAX_SIZE(32 位系統(tǒng)上默認(rèn)為 1MB,64 位系統(tǒng)上默認(rèn)為 64MB)的空間作為 sub-heap。這就是前面所說(shuō)的 ptmalloc 所維護(hù)的分配空間;
當(dāng)用戶請(qǐng)求內(nèi)存分配時(shí),首先會(huì)在這個(gè)區(qū)域內(nèi)找一塊合適的 chunk 給用戶。當(dāng)用戶釋放了 heap 中的 chunk 時(shí),ptmalloc 又會(huì)使用 fastbins 和 bins 來(lái)組織空閑 chunk。以備用戶的下一次分配。
若需要分配的 chunk 大小小于 mmap分配閾值,而 heap 空間又不夠,則此時(shí)主分配區(qū)會(huì)通過(guò) sbrk()調(diào)用來(lái)增加 heap 大小,非主分配區(qū)會(huì)調(diào)用 mmap 映射一塊新的 sub-heap,也就是增加 top chunk 的大小,每次 heap 增加的值都會(huì)對(duì)齊到 4KB。當(dāng)用戶的請(qǐng)求超過(guò) mmap 分配閾值,并且主分配區(qū)使用 sbrk()分配失敗的時(shí)候,或是非主分配區(qū)在 top chunk 中不能分配到需要的內(nèi)存時(shí),ptmalloc 會(huì)嘗試使用 mmap()直接映射一塊內(nèi)存到進(jìn)程內(nèi)存空間。使用 mmap()直接映射的 chunk 在釋放時(shí)直接解除映射,而不再屬于進(jìn)程的內(nèi)存空間。任何對(duì)該內(nèi)存的訪問(wèn)都會(huì)產(chǎn)生段錯(cuò)誤。而在 heap 中或是 sub-heap 中分配的空間則可能會(huì)留在進(jìn)程內(nèi)存空間內(nèi),還可以再次引用(當(dāng)然是很危險(xiǎn)的)。
內(nèi)存分配malloc流程
獲取分配區(qū)的鎖,防止多線程沖突。
計(jì)算出實(shí)際需要分配的內(nèi)存的chunk實(shí)際大小。
判斷chunk的大小,如果小于max_fast(64B),則嘗試去fast bins上取適合的chunk,如果有則分配結(jié)束。否則,下一步;
判斷chunk大小是否小于512B,如果是,則從small bins上去查找chunk,如果有合適的,則分配結(jié)束。否則下一步;
ptmalloc首先會(huì)遍歷fast bins中的chunk,將相鄰的chunk進(jìn)行合并,并鏈接到unsorted bin中然后遍歷 unsorted bins。如果unsorted bins上只有一個(gè)chunk并且大于待分配的chunk,則進(jìn)行切割,并且剩余的chunk繼續(xù)扔回unsorted bins;如果unsorted bins上有大小和待分配chunk相等的,則返回,并從unsorted bins刪除;如果unsorted bins中的某一chunk大小 屬于small bins的范圍,則放入small bins的頭部;如果unsorted bins中的某一chunk大小 屬于large bins的范圍,則找到合適的位置放入。若未分配成功,轉(zhuǎn)入下一步;
從large bins中查找找到合適的chunk之后,然后進(jìn)行切割,一部分分配給用戶,剩下的放入unsorted bin中。
如果搜索fast bins和bins都沒(méi)有找到合適的chunk,那么就需要操作top chunk來(lái)進(jìn)行分配了
當(dāng)top chunk大小比用戶所請(qǐng)求大小還大的時(shí)候,top chunk會(huì)分為兩個(gè)部分:User chunk(用戶請(qǐng)求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成為新的top chunk。
當(dāng)top chunk大小小于用戶所請(qǐng)求的大小時(shí),top chunk就通過(guò)sbrk(main arena)或mmap(thread arena)系統(tǒng)調(diào)用來(lái)擴(kuò)容。
到了這一步,說(shuō)明 top chunk 也不能滿足分配要求,所以,于是就有了兩個(gè)選擇: 如 果是主分配區(qū),調(diào)用 sbrk(),增加 top chunk 大小;如果是非主分配區(qū),調(diào)用 mmap 來(lái)分配一個(gè)新的 sub-heap,增加 top chunk 大小;或者使用 mmap()來(lái)直接分配。在 這里,需要依靠 chunk 的大小來(lái)決定到底使用哪種方法。判斷所需分配的 chunk 大小是否大于等于 mmap 分配閾值,如果是的話,則轉(zhuǎn)下一步,調(diào)用 mmap 分配, 否則跳到第 10 步,增加 top chunk 的大小。
使用 mmap 系統(tǒng)調(diào)用為程序的內(nèi)存空間映射一塊 chunk_size align 4kB 大小的空間。然后將內(nèi)存指針?lè)祷亟o用戶。
判斷是否為第一次調(diào)用 malloc,若是主分配區(qū),則需要進(jìn)行一次初始化工作,分配 一塊大小為(chunk_size + 128KB) align 4KB 大小的空間作為初始的 heap。若已經(jīng)初 始化過(guò)了,主分配區(qū)則調(diào)用 sbrk()增加 heap 空間,分主分配區(qū)則在 top chunk 中切 割出一個(gè) chunk,使之滿足分配需求,并將內(nèi)存指針?lè)祷亟o用戶。
簡(jiǎn)而言之:獲取分配區(qū)(arena)并加鎖–> fast bin –> unsorted bin –> small bin –> large bin –> top chunk –> 擴(kuò)展堆
內(nèi)存回收流程
獲取分配區(qū)的鎖,保證線程安全。
如果free的是空指針,則返回,什么都不做。
判斷當(dāng)前chunk是否是mmap映射區(qū)域映射的內(nèi)存,如果是,則直接munmap()釋放這塊內(nèi)存。前面的已使用chunk的數(shù)據(jù)結(jié)構(gòu)中,我們可以看到有M來(lái)標(biāo)識(shí)是否是mmap映射的內(nèi)存。
判斷chunk是否與top chunk相鄰,如果相鄰,則直接和top chunk合并(和top chunk相鄰相當(dāng)于和分配區(qū)中的空閑內(nèi)存塊相鄰)。轉(zhuǎn)到步驟8
如果chunk的大小大于max_fast(64b),則放入unsorted bin,并且檢查是否有合并,有合并情況并且和top chunk相鄰,則轉(zhuǎn)到步驟8;沒(méi)有合并情況則free。
如果chunk的大小小于 max_fast(64b),則直接放入fast bin,fast bin并沒(méi)有改變chunk的狀態(tài)。沒(méi)有合并情況,則free;有合并情況,轉(zhuǎn)到步驟7
在fast bin,如果當(dāng)前chunk的下一個(gè)chunk也是空閑的,則將這兩個(gè)chunk合并,放入unsorted bin上面。合并后的大小如果大于64B,會(huì)觸發(fā)進(jìn)行fast bins的合并操作,fast bins中的chunk將被遍歷,并與相鄰的空閑chunk進(jìn)行合并,合并后的chunk會(huì)被放到unsorted bin中,fast bin會(huì)變?yōu)榭铡:喜⒑蟮腸hunk和topchunk相鄰,則會(huì)合并到topchunk中。轉(zhuǎn)到步驟8
判斷top chunk的大小是否大于mmap收縮閾值(默認(rèn)為128KB),如果是的話,對(duì)于主分配區(qū),則會(huì)試圖歸還top chunk中的一部分給操作系統(tǒng)。free結(jié)束。
使用注意事項(xiàng)
為了避免Glibc內(nèi)存暴增,需要注意:
- 后分配的內(nèi)存先釋放,因?yàn)閜tmalloc收縮內(nèi)存是從top chunk開(kāi)始,如果與top chunk相鄰的chunk不能釋放,top chunk以下的chunk都無(wú)法釋放。
2. Ptmalloc不適合用于管理長(zhǎng)生命周期的內(nèi)存,特別是持續(xù)不定期分配和釋放長(zhǎng)生命周期的內(nèi)存,這將導(dǎo)致ptmalloc內(nèi)存暴增。
- 不要關(guān)閉 ptmalloc 的 mmap 分配閾值動(dòng)態(tài)調(diào)整機(jī)制,因?yàn)檫@種機(jī)制保證了短生命周期的 內(nèi)存分配盡量從 ptmalloc 緩存的內(nèi)存 chunk 中分配,更高效,浪費(fèi)更少的內(nèi)存。
- 多線程分階段執(zhí)行的程序不適合用ptmalloc,這種程序的內(nèi)存更適合用內(nèi)存池管理
- 盡量減少程序的線程數(shù)量和避免頻繁分配/釋放內(nèi)存。頻繁分配,會(huì)導(dǎo)致鎖的競(jìng)爭(zhēng),最終導(dǎo)致非主分配區(qū)增加,內(nèi)存碎片增高,并且性能降低。
- 防止內(nèi)存泄露,ptmalloc對(duì)內(nèi)存泄露是相當(dāng)敏感的,根據(jù)它的內(nèi)存收縮機(jī)制,如果與top chunk相鄰的那個(gè)chunk沒(méi)有回收,將導(dǎo)致top chunk一下很多的空閑內(nèi)存都無(wú)法返回給操作系統(tǒng)。
- 防止程序分配過(guò)多的內(nèi)存,或是由于glibc內(nèi)存暴增,導(dǎo)致系統(tǒng)內(nèi)存耗盡,程序因?yàn)镺OM被系統(tǒng)殺掉。預(yù)估程序可以使用的最大物理內(nèi)存的大小,配置系統(tǒng)的/proc/sys/vm/overcommit_memory ,/proc/sys/vm/overcommit_ratio,以及使用ulimit -v限制程序能使用的虛擬內(nèi)存的大小,防止程序因OOM被殺死掉。
-
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4353瀏覽量
86070 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
6889瀏覽量
123605 -
虛擬內(nèi)存
+關(guān)注
關(guān)注
0文章
77瀏覽量
8076 -
malloc
+關(guān)注
關(guān)注
0文章
53瀏覽量
75
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
當(dāng)你malloc(0)時(shí)會(huì)發(fā)生什么
淺談 malloc 函數(shù)在單片機(jī)上的應(yīng)用

為什么需要虛擬內(nèi)存?虛擬內(nèi)存的概念與實(shí)現(xiàn)
用malloc和calloc功能來(lái)實(shí)現(xiàn)DAQ,在調(diào)試模式下調(diào)用calloc和malloc函數(shù)時(shí)似乎卡住了,為什么?
#硬聲創(chuàng)作季 12C語(yǔ)言最新標(biāo)準(zhǔn)化學(xué)習(xí)課程2 利用malloc實(shí)現(xiàn)簡(jiǎn)易版本動(dòng)態(tài)數(shù)組
如何實(shí)現(xiàn)malloc的內(nèi)部算法?
RTThread的Libc里的newlib的malloc適配實(shí)現(xiàn)的原理是什么?
通過(guò)實(shí)現(xiàn)一個(gè)簡(jiǎn)單的malloc來(lái)描述malloc背后的機(jī)制

在嵌入式設(shè)備中使用Malloc Hook的試驗(yàn)
分享可應(yīng)用于單片機(jī)的內(nèi)存管理模塊mem_malloc


malloc和free簡(jiǎn)介及實(shí)現(xiàn)方式說(shuō)明
如何在單片機(jī)中使用malloc函數(shù)

malloc跟free的源碼分析
如何實(shí)現(xiàn)一個(gè)malloc





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論